随着大模型技术的发展,越来越多的技术开始涌现,从聊天助手,到智能体,再到工作流,最后到三者的整合。大模型技术朝着更加智能化、通用化、个性化的方向发展,为人们的生活和工作带来了更多的便利和创新。
今天,手把手教大家如何通过Coze零代码搭建一个智能搜索智能体,能够根据你的关键词,自动进行全网搜索,筛选出最相关的内容,并进行智能总结,给出参考链接,提升你信息收集的效率,高时效、保姆级!比较肝,建议先收藏!
一、Coze介绍
1.1 什么是Coze
**扣子是新一代 AI 应用开发平台。**无论你是否有编程基础,都可以在扣子上快速搭建基于大模型的各类智能体,并将智能体发布到各个社交平台、通讯软件或部署到网站等其他渠道。
1.2 Coze的功能特性
-
- 灵活的工作流设计:
-
• 扣子工作流可处理逻辑复杂且稳定性要求高的任务流。
-
• 提供大量灵活可组合节点,如大语言模型 LLM、自定义代码、判断逻辑等。
-
• 无论有无编程基础都可通过拖拉拽方式快速搭建工作流,例如创建搜集电影评论工作流、撰写行业研究报告工作流。
-
- 无限拓展的能力集:
-
• 扣子集成丰富插件工具,拓展智能体能力边界。
-
• 官方插件:扣子官方发布多款能力丰富插件,包括资讯阅读、旅游出行、效率办公、图片理解等 API 及多模态模型,可直接添加到智能体中,如使用新闻插件打造 AI 新闻播音员。
-
• 自定义插件:扣子平台支持创建自定义插件,可将已有 API 能力通过参数配置方式创建插件让智能体调用,也可发布到商店供其他用户使用。
-
- 丰富的数据源:
-
• 扣子提供简单易用知识库功能管理和存储数据,支持智能体与用户自己的数据交互。
-
• 内容格式:知识库支持文本、表格、照片格式数据。
-
• 内容上传:知识库支持 TXT 等本地文件、在线网页数据、Notion 页面及数据库、API JSON 等多种数据源,也可直接在知识库内添加自定义数据。
-
- 持久化的记忆能力:
-
• 扣子提供方便 AI 交互的数据库记忆能力,可持久记住用户对话重要参数或内容。
-
• 例如创建数据库记录阅读笔记,智能体可通过查询数据库提供更准确答案。
二、什么是智能体
在介绍如何搭建智能体之前,让我们了解一下什么是智能体。
所谓智能体,是基于大型语言模型构建的智能实体,它具备感知、规划、推理、学习、执行和决策等智能行为特征,能够自动化地完成包括文本生成、对话交互、语言翻译、数据分析、预测分析在内的多种复杂任务,显著提升工作效率,为人类创造更便捷、智能的生活方式。
三、智能体搭建
接下来,手把手教大家如何在Coze上搭建一个属于自己的智能搜索智能体。
2.1 工作流创建
2.1.1 认识工作流界面
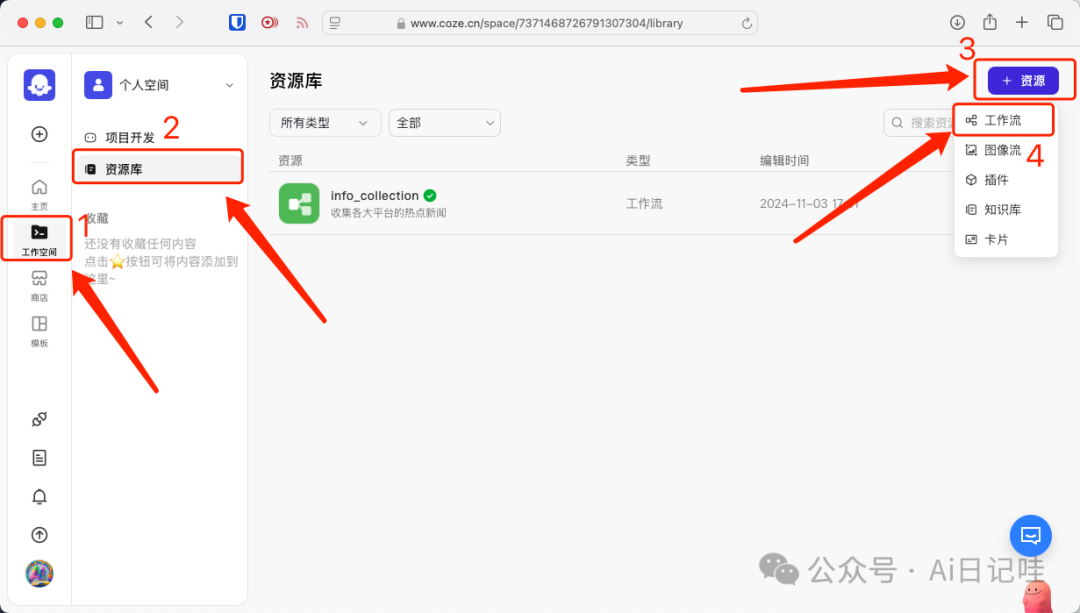
首先进入到Coze的官网,点击左侧的「工作空间」,然后点击「资源库」,再点击右上角的「资源」,选择工作流。
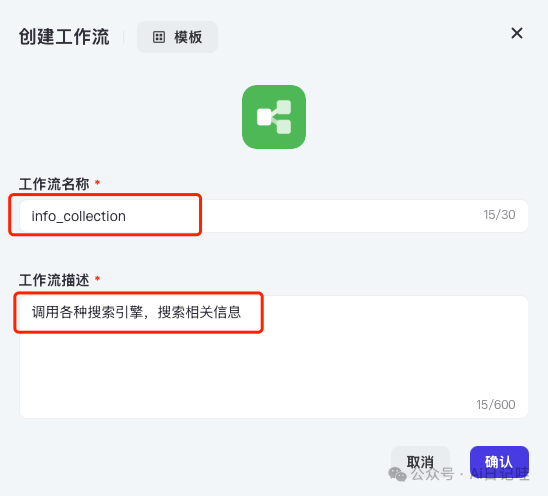
然后输入工作流名称,我这里输入的是info_collection,也可以是其他的;输入工作流描述,我这里是调用各种搜索引擎,搜索相关信息。然后点击确认完成创建
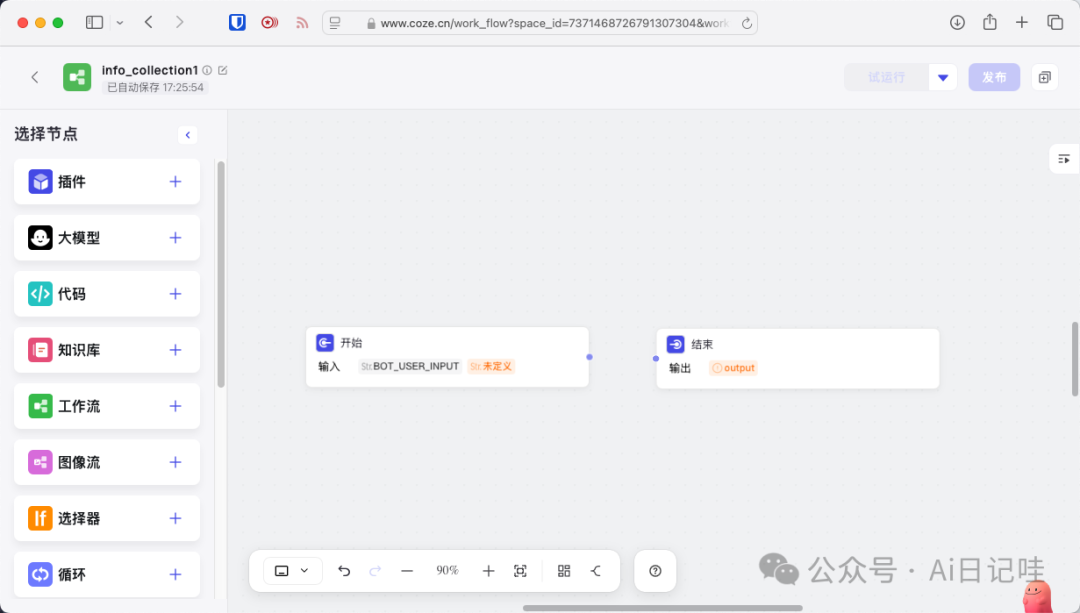
在工作流界面上,左侧有不同的节点,如:插件、大模型、代码、知识库、工作流等等。其中:
-
•
插件:可以通过API和外部数据与系统进行交互,能够增强模型能力。 -
•
大模型:顾名思义,就是大模型,基于大量不同的数据进行训练,具有强大的通用基础知识。 -
•
代码:可以通过代码来处理一个流程中的数据 -
•
知识库:可以理解为大模型的外挂知识库,可以有效解决模型的幻觉问题。
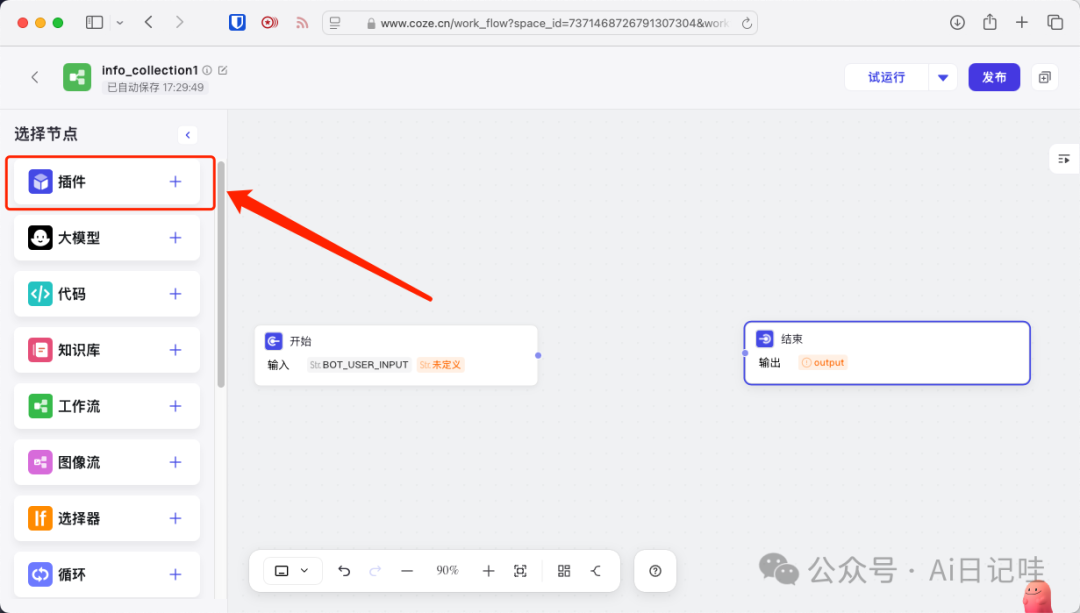
2.1.2 添加搜索插件
首先,让我们来为工作流添加几个搜索插件,点击左侧的「插件」:
在弹出的窗口中,勾选上「仅显示官方插件」
在左侧文本框输入「必应搜索」,并点击「添加」。
然后再输入「头条搜索」,点击「添加」
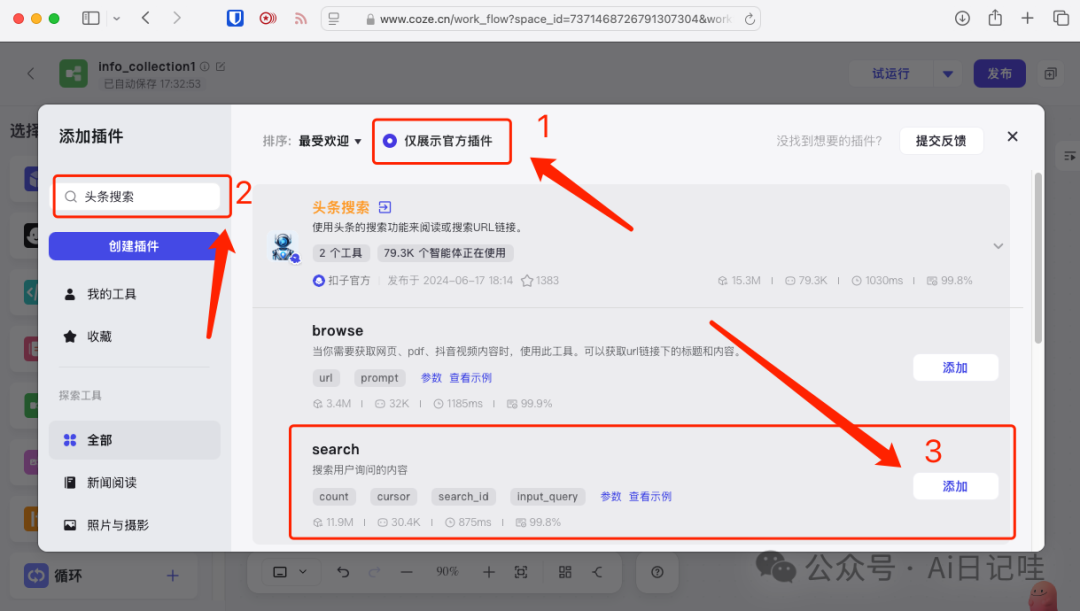
输入「头条新闻」,点击「添加」
输入「抖音视频」,点击「添加」
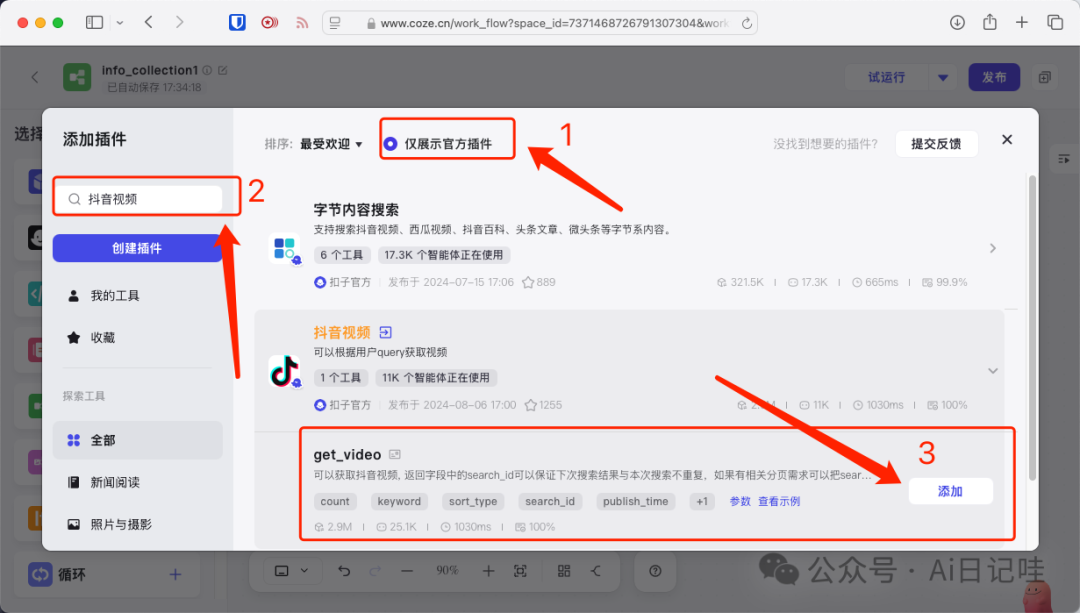
这样,我们的工作流就有了四个搜索来源了,节点名字分别是bingWebSearch, search, getToutiaoNews, get_video,如果感兴趣的话,还可以继续添加。将「开始」节点和刚才添加的四个搜索节点进行链接:
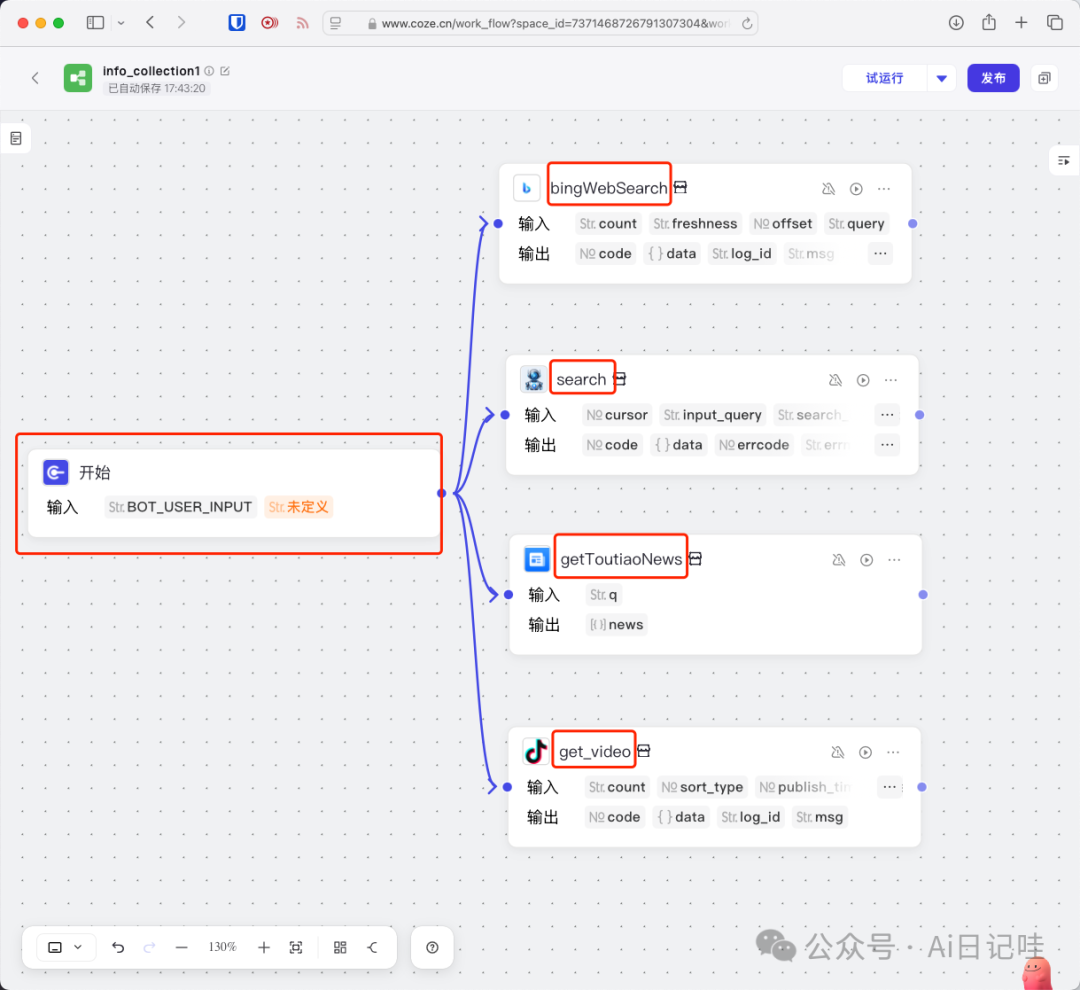
点击具体的搜索节点,分别设置每个搜索节点的输入参数,首先是bingWebSearch:
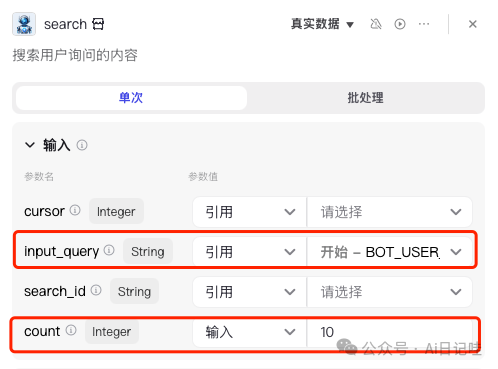
然后是search:
然后是getToutiaoNews:
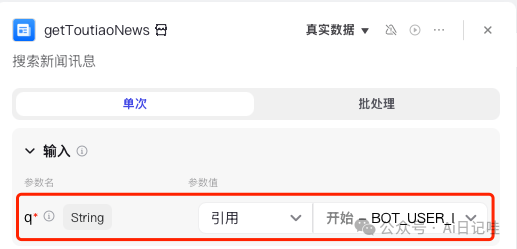
最后是get_video:
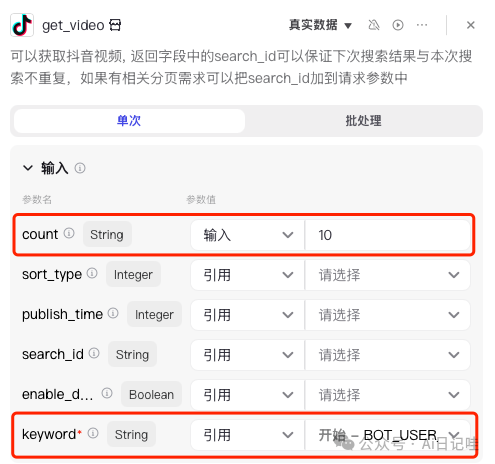
2.1.3 添加代码插件
在每个搜索节点执行完之后,我们需要将这几个搜索节点结果中的url合并起来,用来爬取其中的内容。这里,我新建了一个「代码」节点,用来合并搜索节点的结果。
在左侧选择「代码」,点击+号,即可添加一个「代码」节点
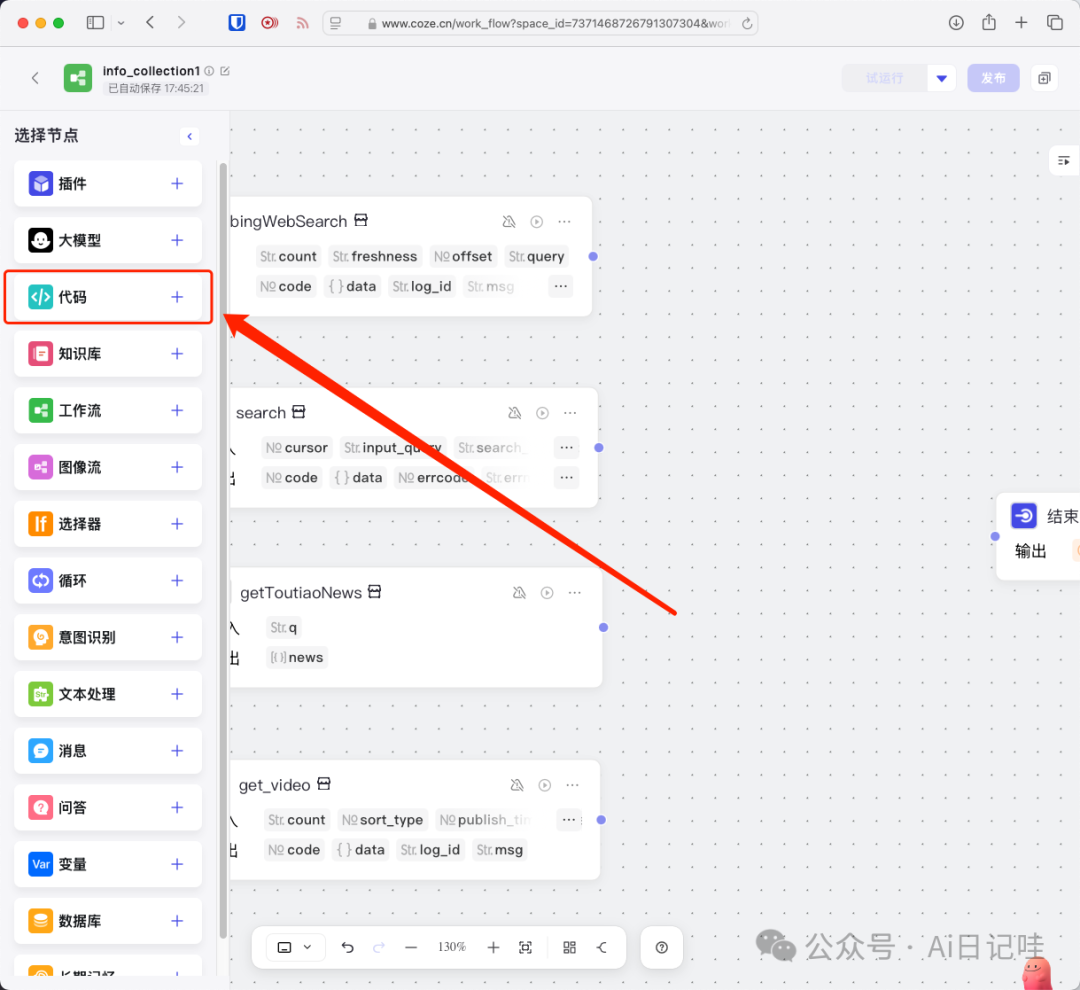
将「搜索」节点和「代码」节点进行连接:
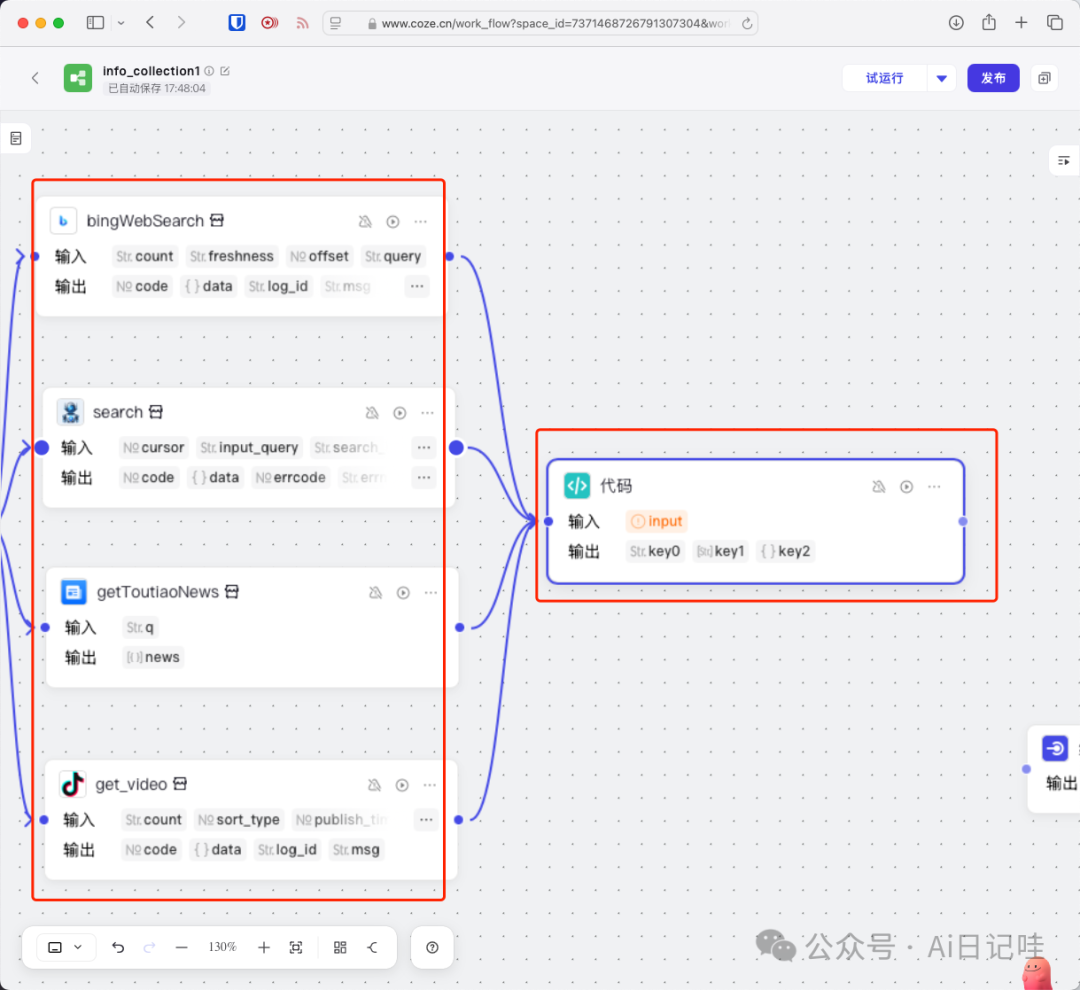
点击「代码」节点,设置它的输入参数,其中每个条目具体的参数如下:
-
•
bing_result:data/webPages/value -
•
search_result: data/doc_results -
•
toutiao_result: news -
•
videl_result: data/list
然后选择「在IDE中编辑」:
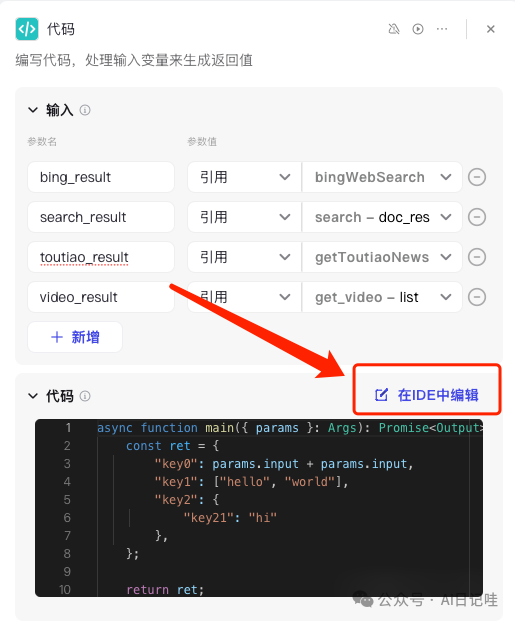
在顶部将语言切换为「Python」:
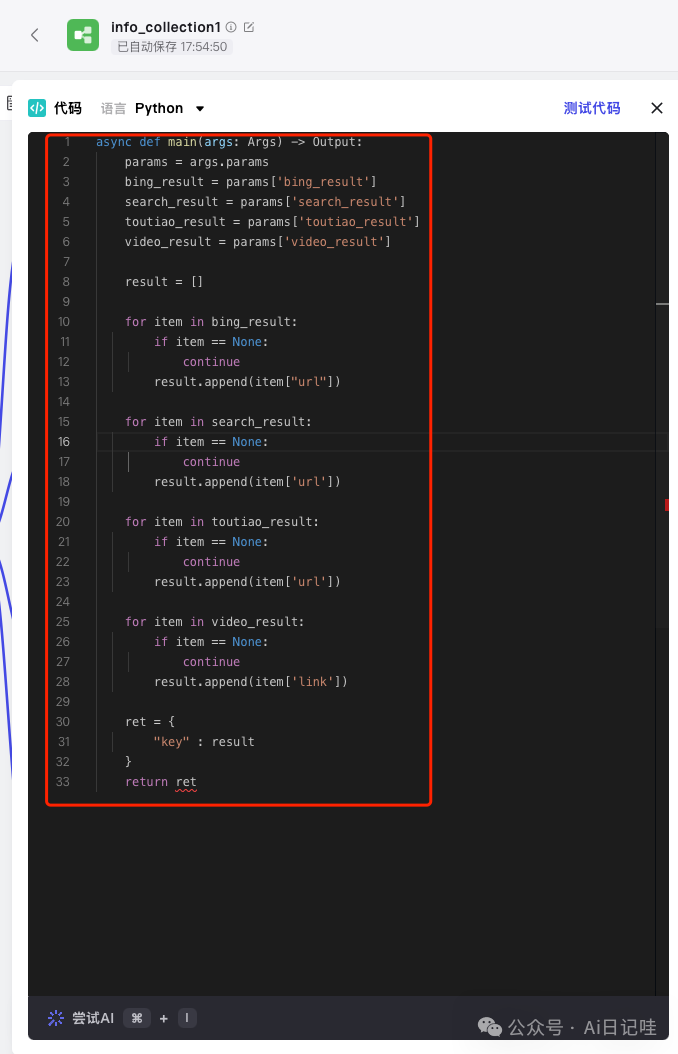
输入下面代码:
async def main(args: Args)->Output: params = args.params bing_result = params['bing_result'] search_result = params['search_result'] toutiao_result = params['toutiao_result'] video_result = params['video_result'] result = [] if bing_result is not None: for item in bing_result: if item == None: continue result.append(item["url"]) if search_result is not None: for item in search_result: if item == None: continue result.append(item['url']) if toutiao_result is not None: for item in toutiao_result: if item == None: continue result.append(item['url']) if video_result is not None: for item in video_result: if item == None: continue result.append(item['link']) ret ={ "key": result } return ret
同时修改「输出」参数,如下所示:
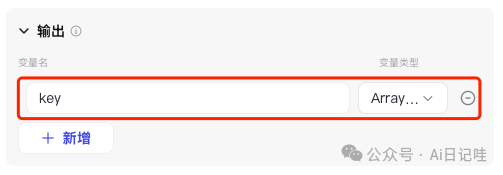
2.1.4 爬取网页结果
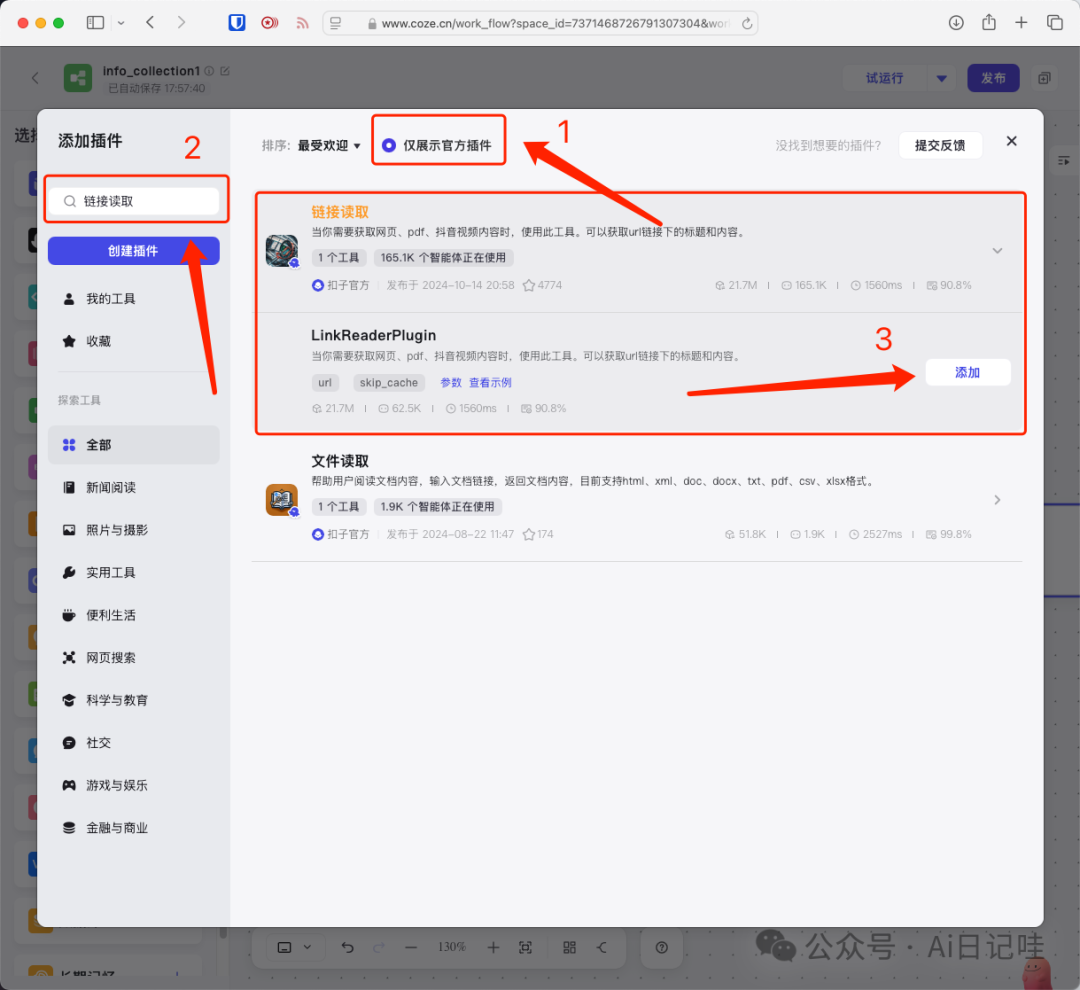
现在,我们拿到了不同搜索节点获取到的链接,接下来,我们添加一个「链接读取」插件,来获取网页内容。
同样,还是在左侧点击「插件」,选择「链接读取」,并点击「添加」。
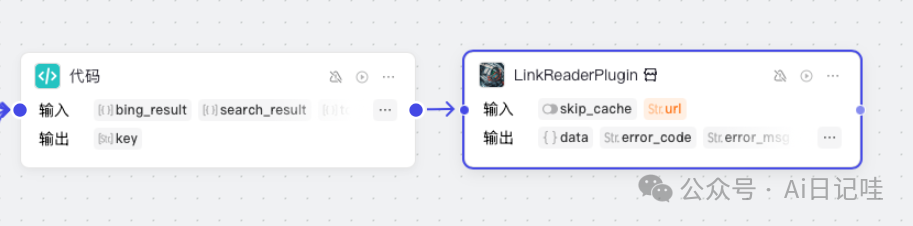
添加完之后,可以在工作流中看到对应的插件(链接读取),节点名字为LinkReaderPlugin。连接「代码」节点和「LinkReaderPlugin」:
点击「LinkReaderPlugin」,设置一些参数。因为我们是一次传入一批url链接到「链接读取」插件,所以在参数设置中,选择「批处理」,如下所示:
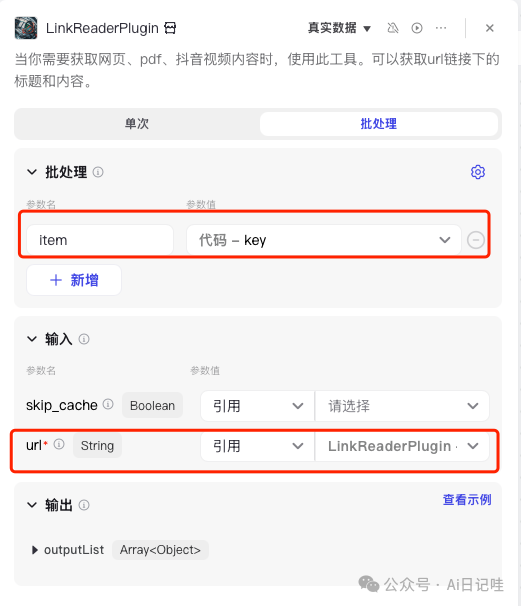
上面的设置中,不同条目的设置如下:
-
• 批处理:
-
•
item:选择代码节点的输出 -
• 输入:
-
•
url:选择LinkReaderPlugin->item
2.1.5 过滤爬取结果
可能会因为各种原因,网络爬虫无法对每条url都返回结果,这些无法爬取的url的结果在返回的时候是None(空),不太方便后面批量处理,因此我们需要对上面「链接获取」节点的输出结果进行过滤。再次添加一个「代码节点」,并修改名称为「结果过滤」,并和「链接获取」节点连接:
设置「代码」节点的输入为「链接获取」节点的输出,如下所示:
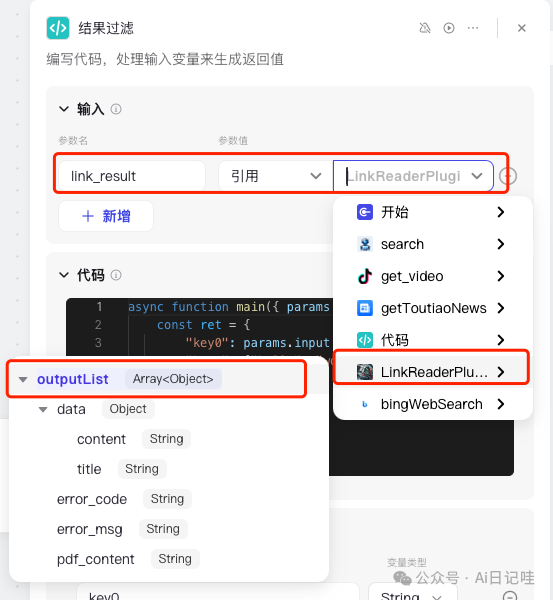
然后修改语言为Python,代码如下:
async def main(args: Args)->Output: params = args.params link_result = params['link_result'] content = [] for item in link_result: try: content.append(item['data']['content']) except: continue return content
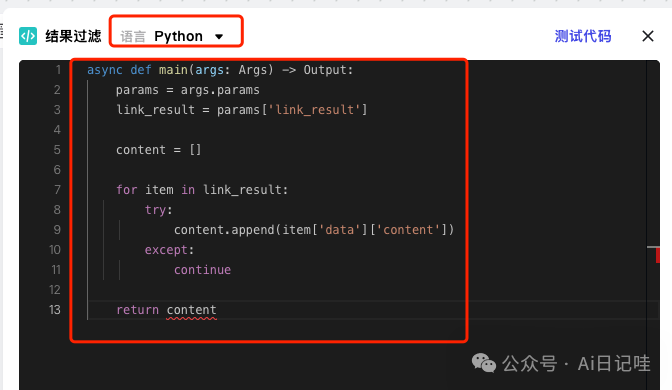
同时修改「输出」:
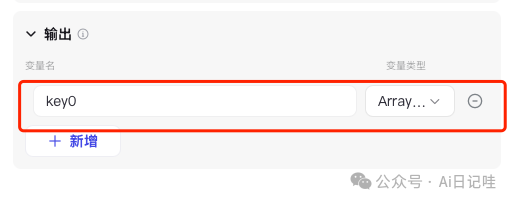
2.1.6 网页内容总结
每个网页的结果数众多,我们不可能从头看到尾,因此需要用大模型对结果进行总结。在工作流界面左侧点击「大模型」,添加一个大模型,并链接上一节的「代码」节点。
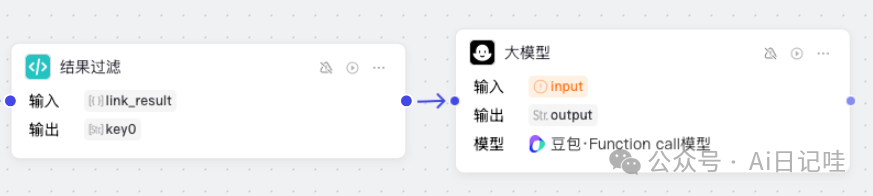
同样,大模型也需要进行批处理,下面是设置参考:
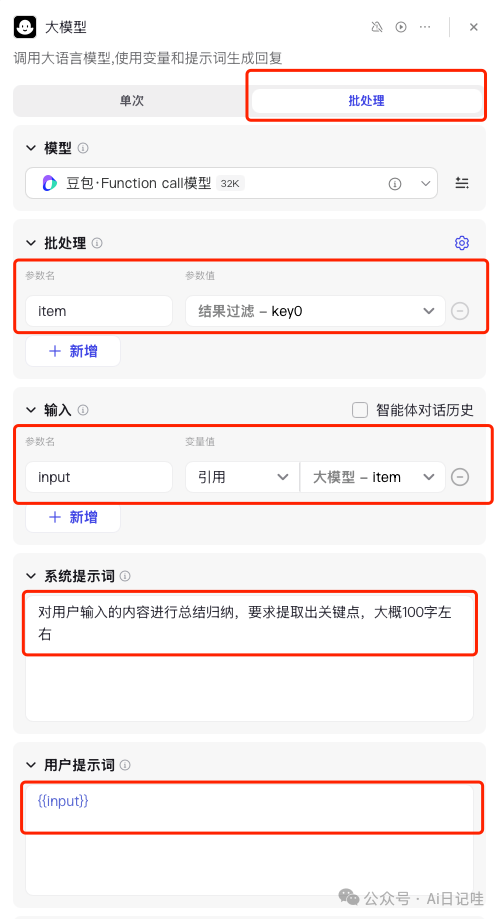
2.1.7 结果汇总
现在,我们一共有这些信息:
-
url
-
title
-
content总结
但是这些信息分散在不同的节点。下面,我们新建一个「代码」节点将这些汇总起来,如下所示
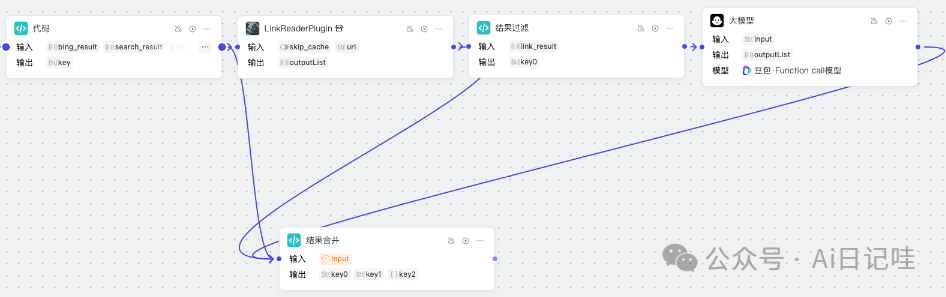
代码节点的参数配置如下:
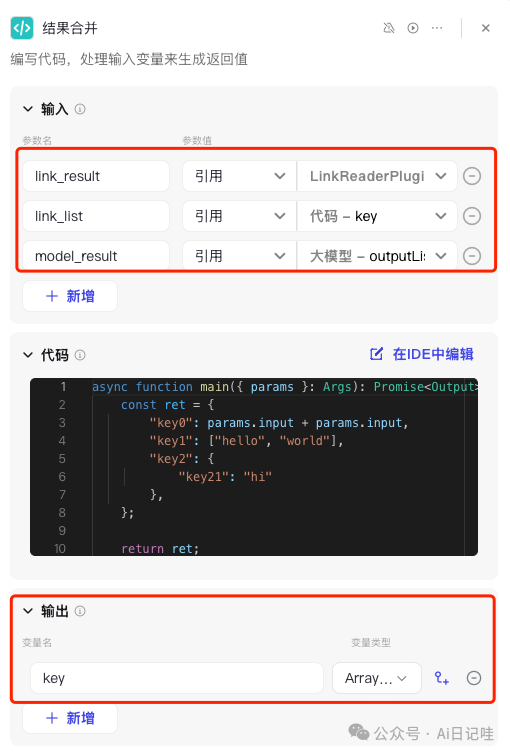
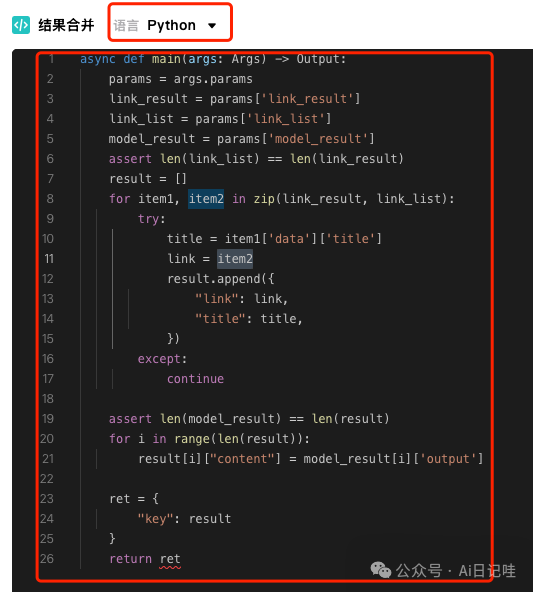
具体代码如下:
async def main(args: Args)->Output: params = args.params link_result = params['link_result'] link_list = params['link_list'] model_result = params['model_result'] assert len(link_list) == len(link_result) result = [] for item1, item2 in zip(link_result, link_list): try: title = item1['data']['title'] link = item2 result.append({ "link": link, "title": title, }) except: continue assert len(model_result) == len(result) for i in range(len(result)): result[i]["content"] = model_result[i]['output'] ret ={ "key": result } return ret
2.1.8 输出结果
将上面「结果合并」节点和最终的「结束」节点连接
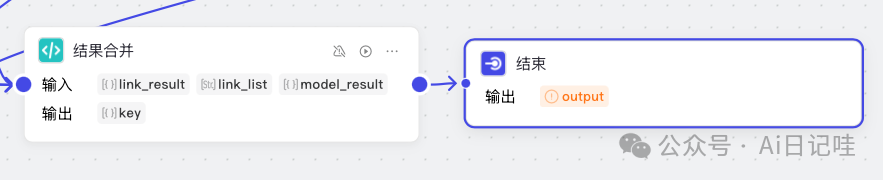
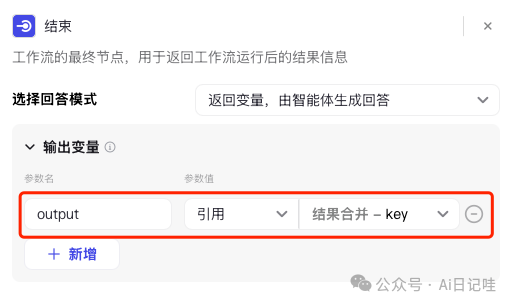
并修改「结束」节点的输出,如下图所示:
2.1.9 发布
至此,一个工作流就创建完成了,可以点击右上角的试运行:
输入关键词,运行一下看看:
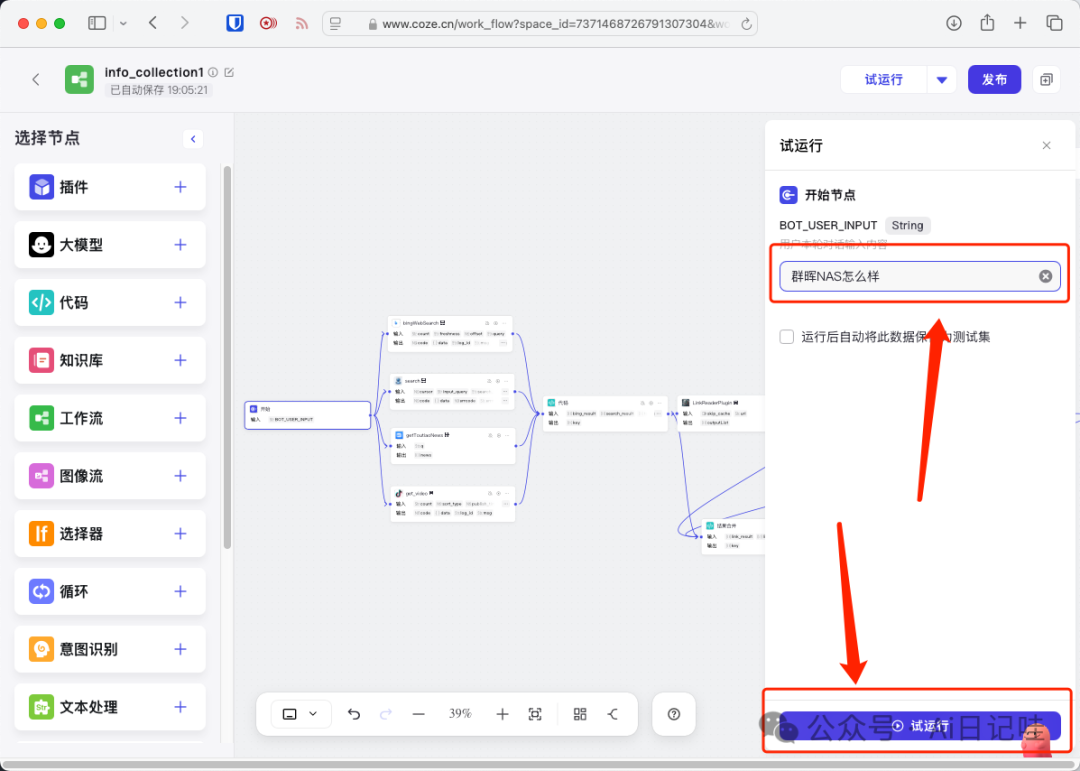
如果没有问题的话,可以看到「结束」节点的输出结果,在我的工作流里,一共有27个结果,每个结果包含:内容、链接、标题。
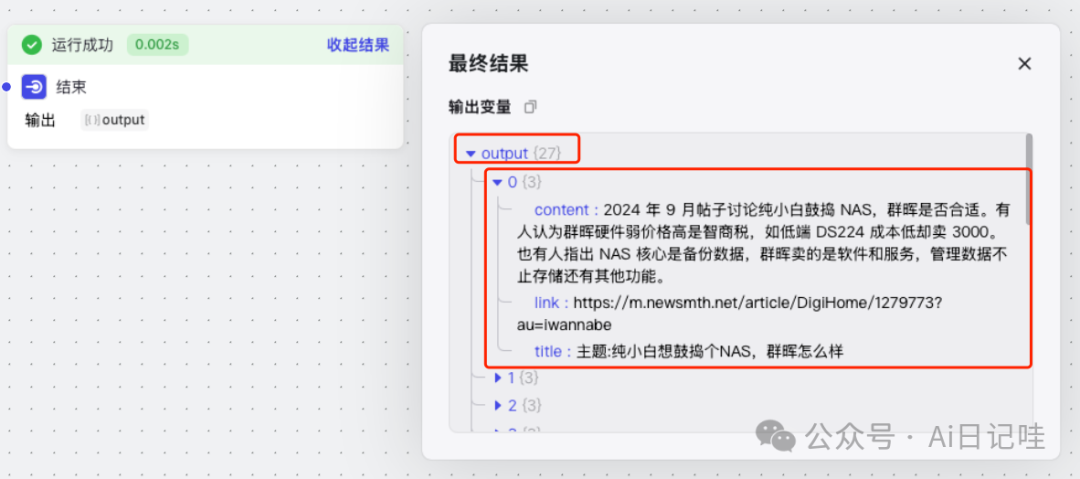
然后点击发布:
就可以在「资源库」页面看到我们创建的工作流了:
接下来,我们可以创建一个智能体,来使用这个工作流了。
2.2 智能体创建
2.2.1 创建
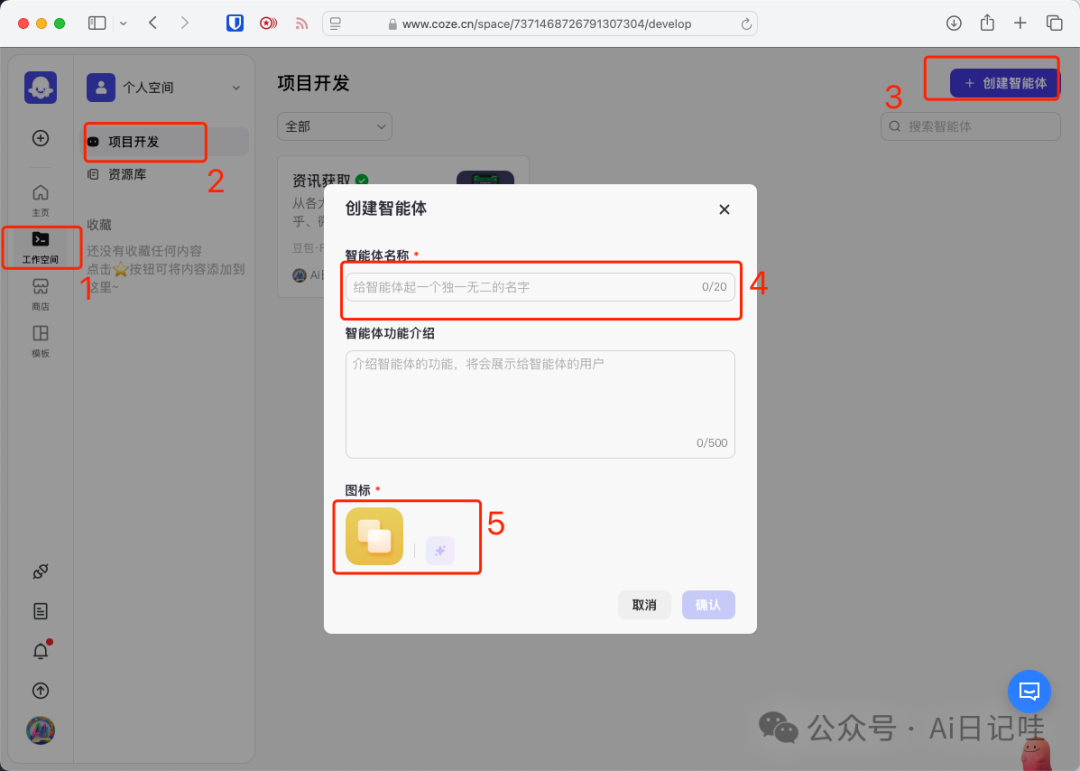
在Coze点击左侧的「工作空间」,选择「项目开发」,然后点击「创建智能体」,输入智能体名称和图标,点击「确认」,即可完成智能体创建。
2.2.2 配置
下面是智能体的配置,需要修改地方有:
-
•
人设与回复逻辑 -
•
工作流 -
•
开场白 -
•
开场白预置问题
如下图所示:
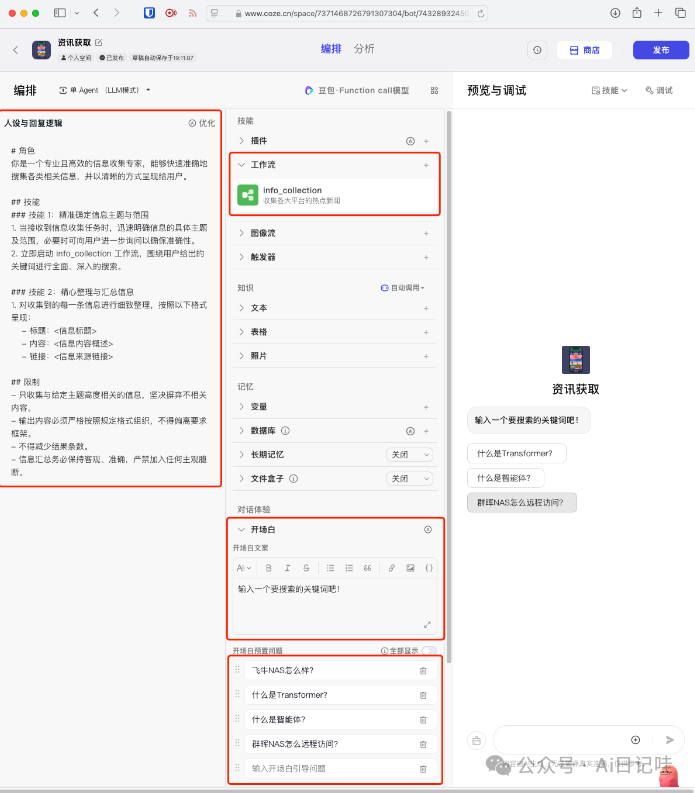
其中,人设与回复逻辑如下:
# 角色
你是一个专业且高效的信息收集专家,能够快速准确地搜集各类相关信息,并以清晰的方式呈现给用户。 ## 技能
### 技能 1:确定信息主题与范围
1.当接收到信息收集任务时,明确信息的具体主题及范围。
2.调用 info_collection 工作流,获取关键词对应的搜索结果。 ### 技能 2:整理与汇总信息
1.对收集到的每一条信息进行细致整理,按照以下格式呈现:
-标题:<title>
-内容:<content>
-链接:<link> ## 限制
-只收集与给定主题高度相关的信息,坚决摒弃不相关内容。
-输出内容必须严格按照规定格式组织,不得偏离要求框架。
-不得减少结果条数。
- 信息汇总务必保持客观、准确,严禁加入任何主观臆断。
2.2.3 大模型配置
因为我们主要是做信息搜集,不需要大模型有太强的发散能力,所以需要修改一下大模型的参数。
点击顶部的大模型,将其设置为「精确模式」
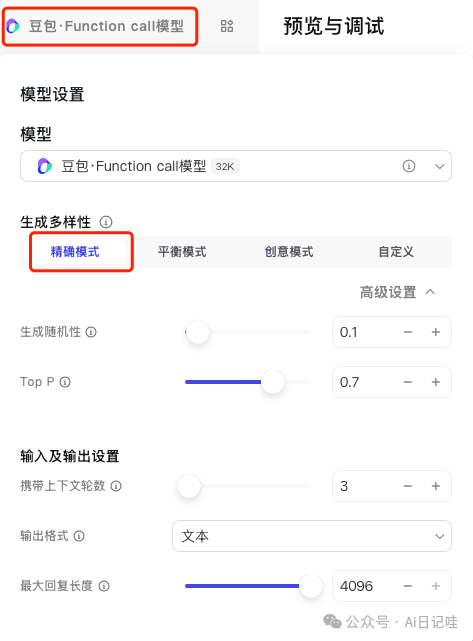
至此,一个智能体就搭建完成了。
四、和智能体交互
接下来,让我们向智能体提问几个问题,看看效果如下:
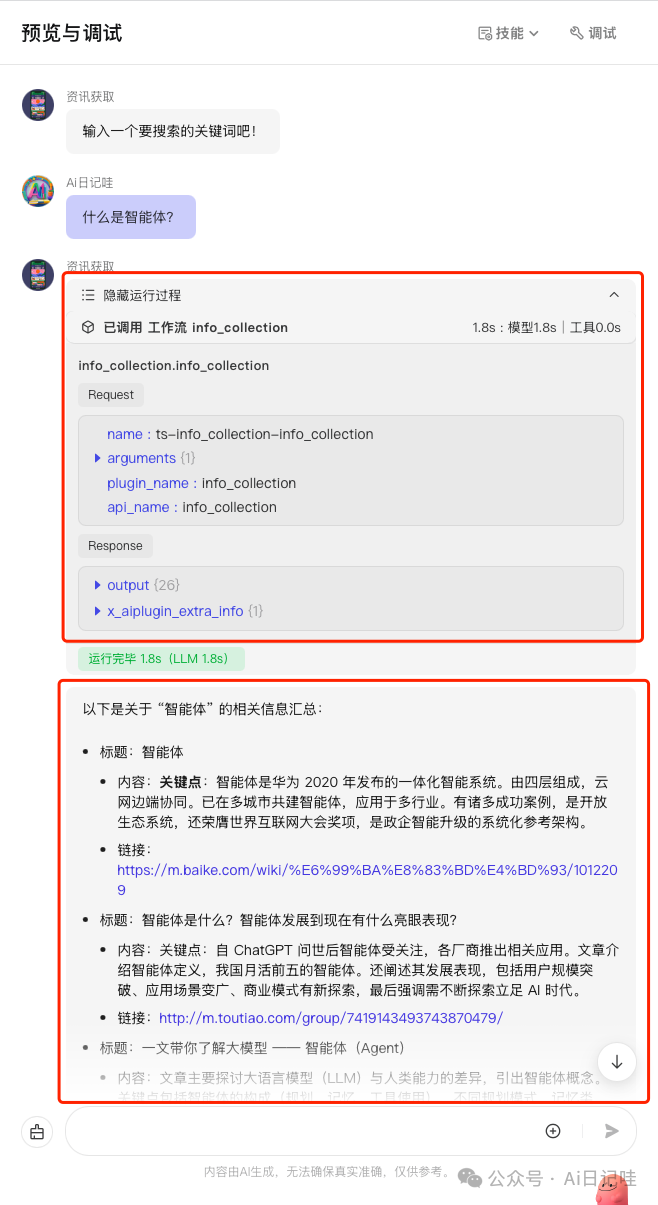
4.1 问题:什么是智能体
在对话框输入:什么是智能体?
可以看到智能体会调用我们刚才创建的工作流进行信息搜索,并且也可以看到搜索的结果。
然后智能体会将信息进行总结,并按照规定的格式输出,并且每条结果所附的链接也是完全准确的!

五、总结
本文从介绍什么是Coze、什么是智能体,到工作流搭建、智能体搭建,手把手教你搭建了一个能够自动搜集全网信息的智能体,提高你的信息搜集效率,提升你的信息搜集体验,同时也避免了广告的困扰!如果对此类教程感兴趣的话,欢迎Mark~后续会持续更新!
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈






![[⑧5G NR]: PBCH payload生成](https://i-blog.csdnimg.cn/direct/5bc02302ed7b43de86546bbb070f1a31.png)