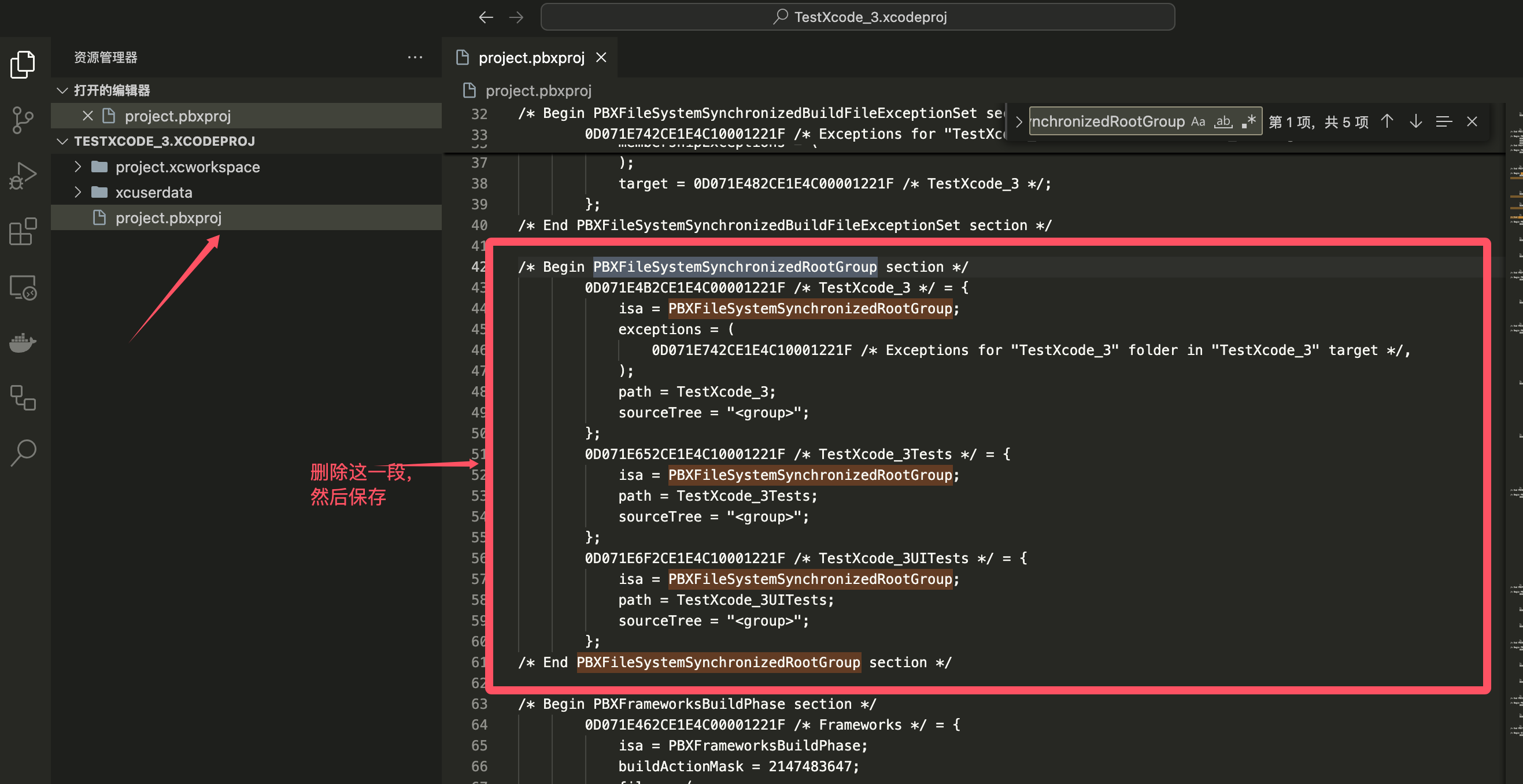
在前面的文章中,我们详细探讨了TensorFlow在实际应用中的高级功能和技术细节。本篇将继续深入探讨一些前沿话题,包括但不限于分布式训练、混合精度训练、神经架构搜索(NAS)、模型微调以及在实际项目中的最佳实践等,帮助读者掌握更多高级技能。
1. 分布式训练
1.1 多GPU训练
当数据集或模型规模过大时,单个GPU可能无法满足训练需求。这时可以使用多GPU进行分布式训练。
import tensorflow as tf
from tensorflow.keras import layersstrategy = tf.distribute.MirroredStrategy()with strategy.scope():# 创建模型model = tf.keras.Sequential([layers.Dense(64, activation='relu', input_shape=(10,)),layers.Dense(64, activation='relu'),layers.Dense(10, activation='softmax')])# 编译模型model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(x_train, y_train, epochs=5)
1.2 多机多卡训练
对于更大规模的数据集和更复杂的模型,可以利用多台机器上的多个GPU进行训练。
resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu='')
tf.config.experimental_connect_to_cluster(resolver)
tf.tpu.experimental.initialize_tpu_system(resolver)
strategy = tf.distribute.TPUStrategy(resolver)with strategy.scope():# 创建模型model = tf.keras.Sequential([layers.Dense(64, activation='relu', input_shape=(10,)),layers.Dense(64, activation='relu'),layers.Dense(10, activation='softmax')])# 编译模型model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(x_train, y_train, epochs=5)
2. 混合精度训练
2.1 FP16 vs FP32
混合精度训练通过使用FP16(半精度浮点数)代替传统的FP32(单精度浮点数),可以显著加快训练速度并减少内存占用。
policy = tf.keras.mixed_precision.Policy('mixed_float16')
tf.keras.mixed_precision.set_global_policy(policy)# 创建模型
model = tf.keras.Sequential([layers.Dense(64, activation='relu', input_shape=(10,)),layers.Dense(64, activation='relu'),layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(x_train, y_train, epochs=5)
3. 神经架构搜索(NAS)
3.1 自动寻找最佳架构
神经架构搜索(Neural Architecture Search, NAS)是一种自动化方法,用于寻找最适合特定任务的模型架构。
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import regularizers
from tensorflow.keras import backend as K
from tensorflow.keras import lossesclass NASModel(tf.keras.Model):def __init__(self, num_classes):super(NASModel, self).__init__()self.conv1 = layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))self.pool1 = layers.MaxPooling2D(pool_size=(2, 2))self.flatten = layers.Flatten()self.dense1 = layers.Dense(128, activation='relu')self.dense2 = layers.Dense(num_classes, activation='softmax')def call(self, inputs):x = self.conv1(inputs)x = self.pool1(x)x = self.flatten(x)x = self.dense1(x)return self.dense2(x)# 创建 NAS 模型
model = NASModel(num_classes=10)# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(x_train, y_train, epochs=5)# 评估模型
score = model.evaluate(x_test, y_test)
print("NAS Model accuracy:", score[1])
4. 模型微调
4.1 微调预训练模型
微调(Fine-tuning)是指在已有预训练模型的基础上,针对特定任务进行进一步训练,以获得更好的性能。
from tensorflow.keras.applications import MobileNetV2# 加载预训练模型
pre_trained_model = MobileNetV2(input_shape=(150, 150, 3),include_top=False,weights='imagenet')# 冻结所有层
for layer in pre_trained_model.layers:layer.trainable = False# 构建新模型
model = tf.keras.Sequential([pre_trained_model,layers.GlobalAveragePooling2D(),layers.Dense(1, activation='sigmoid')
])# 编译模型
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=0.0001),loss='binary_crossentropy',metrics=['accuracy'])# 训练模型
history = model.fit(x_train, y_train, epochs=5)# 解冻部分层
for layer in pre_trained_model.layers[-20:]:layer.trainable = True# 重新编译模型
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=0.0001),loss='binary_crossentropy',metrics=['accuracy'])# 继续训练
history_fine_tuning = model.fit(x_train, y_train, epochs=5)
5. 实际项目中的最佳实践
5.1 代码复用与模块化
在实际项目中,代码复用和模块化是提升开发效率的重要手段。通过将常用组件封装成函数或类,可以减少重复工作。
class CustomLayer(tf.keras.layers.Layer):def __init__(self, units=32):super(CustomLayer, self).__init__()self.units = unitsdef build(self, input_shape):self.kernel = self.add_weight(shape=(input_shape[-1], self.units),initializer='uniform',trainable=True)def call(self, inputs):return tf.matmul(inputs, self.kernel)# 使用自定义层构建模型
model = tf.keras.Sequential([CustomLayer(64),layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(x_train, y_train, epochs=5)
5.2 持续集成与持续部署(CI/CD)
持续集成(Continuous Integration)和持续部署(Continuous Deployment)是现代软件工程中的重要实践,可以确保代码的质量和及时发布。
# 使用 GitHub Actions 配置 CI/CD
name: TensorFlow CI/CD Pipelineon:push:branches: [ master ]pull_request:branches: [ master ]jobs:build:runs-on: ubuntu-lateststeps:- uses: actions/checkout@v2- name: Set up Python 3.7uses: actions/setup-python@v1with:python-version: 3.7- name: Install dependenciesrun: |python -m pip install --upgrade pippip install tensorflow- name: Lint with flake8run: |pip install flake8flake8 .- name: Test with pytestrun: |pip install pytestpytest tests/
6. 高级主题
6.1 可解释性与公平性
在部署模型之前,确保模型的可解释性和公平性是非常重要的,尤其是在涉及敏感数据的应用场景中。
import shap# 使用 SHAP 解释模型
explainer = shap.Explainer(model)
shap_values = explainer(x_test)# 可视化 SHAP 值
shap.summary_plot(shap_values, x_test)# 检查模型公平性
from aif360.datasets import AdultDataset
from aif360.metrics import ClassificationMetricprivileged_groups = [{'sex': 1}]
unprivileged_groups = [{'sex': 0}]dataset = AdultDataset(protected_attribute_names=['sex'], categorical_features=[], label_names=['income-per-year'])predictions = model.predict(x_test)
classification_metric = ClassificationMetric(dataset, predictions, unprivileged_groups=unprivileged_groups, privileged_groups=privileged_groups)
print("Statistical parity difference:", classification_metric.statistical_parity_difference())
6.2 模型安全性
模型安全性是确保模型在实际部署中不会被恶意攻击所影响的关键因素。
import tensorflow as tf
from cleverhans.tf2.attacks import fast_gradient_method# 创建对抗样本
adv_x = fast_gradient_method(model, x_test, eps=0.01, clip_min=0., clip_max=1.)# 评估对抗样本的影响
score_adv = model.evaluate(adv_x, y_test)
print("Adversarial accuracy:", score_adv[1])
7. 模型的生命周期管理
7.1 版本控制与回滚
在模型的生命周期管理中,版本控制和回滚机制可以确保在出现问题时快速恢复到先前的状态。
import mlflow# 初始化 MLflow
mlflow.tensorflow.autolog()# 创建实验
mlflow.set_experiment("my-experiment")# 记录模型
with mlflow.start_run():model.fit(x_train, y_train, epochs=5)model.evaluate(x_test, y_test)# 查看实验结果
mlflow.ui.open_ui()
7.2 模型监控与告警
在模型上线后,持续监控模型的表现并通过告警系统及时发现问题是非常重要的。
import tensorflow as tf
from tensorflow.keras import layers# 创建模型
model = tf.keras.Sequential([layers.Dense(64, activation='relu', input_shape=(10,)),layers.Dense(64, activation='relu'),layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 使用 TensorBoard 监控模型
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")# 训练模型
model.fit(x_train, y_train, epochs=5, callbacks=[tensorboard_callback])# 启动 TensorBoard
!tensorboard --logdir logs
8. 结论
通过本篇的学习,你已经掌握了TensorFlow在实际应用中的更多高级功能和技术细节。从分布式训练、混合精度训练、神经架构搜索、模型微调,到实际项目中的最佳实践、高级主题如可解释性与公平性、模型安全性,再到模型的生命周期管理,每一步都展示了如何利用TensorFlow的强大功能来解决复杂的问题。