梯度下降是机器学习中广泛应用的优化算法,像线性回归和逻辑回归以及神经网络的早期实现,现在有一些其他的优化算法,为了最小化成本函数,甚至比梯度下降的效果更好,这种算法可以用来帮助训练神经网络,比梯度下降快得多。
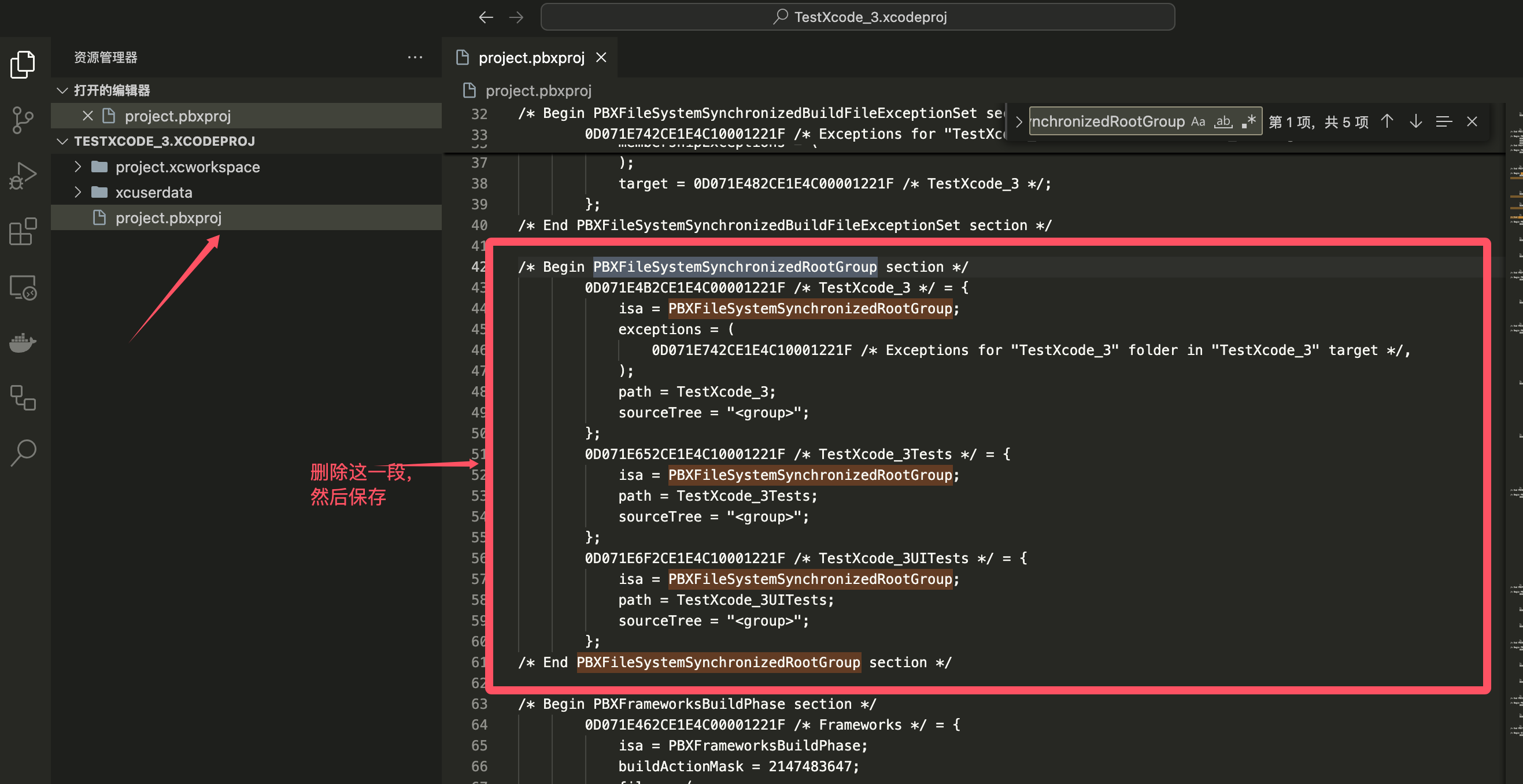
回想一下,这是梯度下降一步的表达式,在本例中,用包含这些椭圆的等高线图绘制了成本函数j,所以这个成本函数的最小值在这些椭圆的中心,现在要从最小值开始梯度下降,一步梯度下降,如果alpha很小,它可能会带你朝那个方向走一点,然后再走一步,梯度下降的每一步都是朝着同一个方向,那么为什么不让alpha变大,能不能有一个自动增加alpha的算法,只是让它迈出更大的步伐,更快的达到最低限度,有一种叫做Adam算法的算法可以做到,如果它看到学习率太小,我们应该提高学习率,同样的费用函数,如果我们有一个相对较大的学习率,那么也许一个梯度下降的步骤就到达最低限度,如果看到梯度下降,这是来回振荡,Adam算法可以自动的做到这一点,以更小的学习率,然后向成本函数的最小值走一条更平滑的路径,所以取决于梯度下降是如何进行的,有时希望有更高的学习速度,有时希望学习速度更小。

所以Adam算法可以自动调整学习速率,它不使用单一的全局学习速率,所以如果你有参数W1到W10和b,那么实际上它有11个学习速率参数。

Adam算法背后的直觉是如果一个参数,Wj或B似乎一直朝着大致相同的方向移动,但如果它似乎一直朝着大致相同的方向移动,让我们提高该参数的学习速率,我们朝那个方向走快点,反过来说,如果一个参数不停地来回振荡,可以对这个参数稍微减少一点alpha。

在代码中,这是如何实现的?
模型和以前一摸一样,编译的方式,这个模型和以前的很相似,除了我们现在向编译函数添加一个额外的参数,即我们指定要使用的优化器是TF.Keras.优化器,.Adam优化器,所以Adam优化算法确实需要一些默认的初始学习速率,在这个例子中,初始学习率是10的-3,但是你在实践中使用Adam算法时,值得尝试这个首字母的几个值,此默认全局学习速率,尝试一些较大和较小的值,看看什么能给你最快的学习性能,通过Adam算法,可以自动调整学习速度,使其更加精确。

这就是Adam优化算法,它通常比梯度下降工作得快得多,它已经成为一个事实上的标准。