代码,以及测试方案使用的是沐神的代码
github的代码:
1. 环境搭建
首先是安装torch
这是我的pytorch版本
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
使用pip指令安装transformers
transformers 这个包是一个预训练好的模型的大全集,可以从里面下载各种训练好的模型。
pip install transformers
安装好后发现连不上Hugging face
先安装 huggingface_hub
pip install -U huggingface_hub
安装完成后在代码中运行,下面的代码,就可以切换到国内的源,下载模型
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
除此以外,还有一种办法可以一劳永逸的改
在虚拟环境的 “…/huggingface_hub”中找到:constants.py文件
# 将原来的默认网址修改为镜像网址
# _HF_DEFAULT_ENDPOINT = "https://huggingface.co"
_HF_DEFAULT_ENDPOINT = "https://hf-mirror.com"
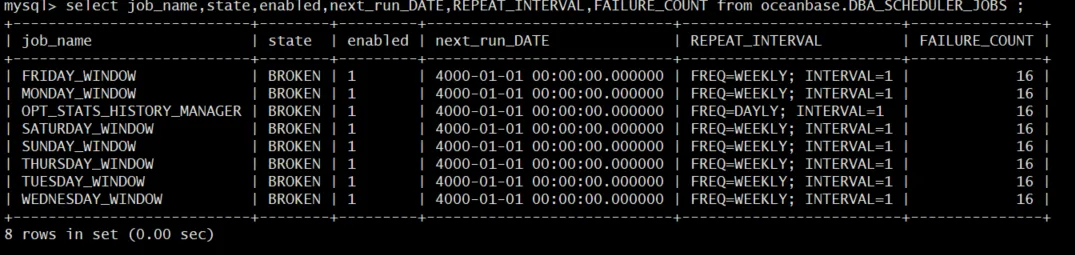
张量测试结果
4090D 显卡测试结果,可以看到在float32的时候,4090 没有比3090TI好太多。
float 16 可以看到有,明显的提升,感觉后面可以尽量16的方式去算,会更加能体现出优势

3090TI的算力结果

这个是官方公布的算力,从自测的值和官方的值相比,FP16算力小了一半。
| Model | Memory (GB) | Memory Bandwidth (GB/sec) | FP32 TFLOPS | FP16 TFLOPS |
|---|---|---|---|---|
| A100 | 80 | 2039 | 19.5 | 312 |
| V100 | 16 | 900 | 15.7 | 125 |
| A6000 | 48 | 768 | 38 | 150 |
| RTX 3090 TI | 24 | 1008 | 40 | 160 |
BERT不同batch size
3090TI,显卡的参数

4090D 显卡的参数

在大的batch size下整体有较大的提升,小batch size 反而效率降低了。是否为核心加多,核心的调度增加了额外开销,单个核心反而不如之前的了。
遇到的问题
BertLayer import 报错
不知道沐神用的哪个版本的transformers ,但是我发现我装的最新版本的没有这个,但在文件中还有这个函数。所以需要自己添加一下申明,应该就可以使用了。
在__init__.py 这个文件中有两处需要修改,添加完成后,就可以在代码中引用这些部分了
- 在1544行附近,添加BertLayer 这个部分。
- 在6433行的位置,添加BertLayer 这个部分。