1. 引言
持续学习是智能的关键方面。它指的是从非平稳数据流中增量学习的能力,对于在非平稳世界中运作的自然或人工智能体来说是一项重要技能。人类是优秀的持续学习者,能够在不损害先前学习技能的情况下增量学习新技能,并能够将新信息与先前获得的知识整合和对比。
然而,深度神经网络虽然在其他方面可以与人类智能相媲美,但几乎完全缺乏这种持续学习的能力。最引人注目的是,当这些网络被训练学习新事物时,它们倾向于"灾难性地"忘记之前学到的东西。
深度神经网络无法持续学习有重要的实际意义:
-
深度学习模型需要长时间在大量数据上训练才能获得强大性能,但如果有新的相关数据可用,仅在新数据上快速更新网络是行不通的。
-
即使在新旧数据上一起继续联合训练,通常也无法获得令人满意的结果。
-
业界实践中往往会定期在所有数据上从头重新训练整个网络,尽管这会带来巨大的计算成本。
因此,为深度学习开发成功的持续学习方法可能会带来显著的效率提升,并大幅减少所需资源。此外,持续学习还可以用于纠正错误或偏差,以及边缘设备的实时在线学习等应用场景。
2. 持续学习问题
2.1 灾难性遗忘
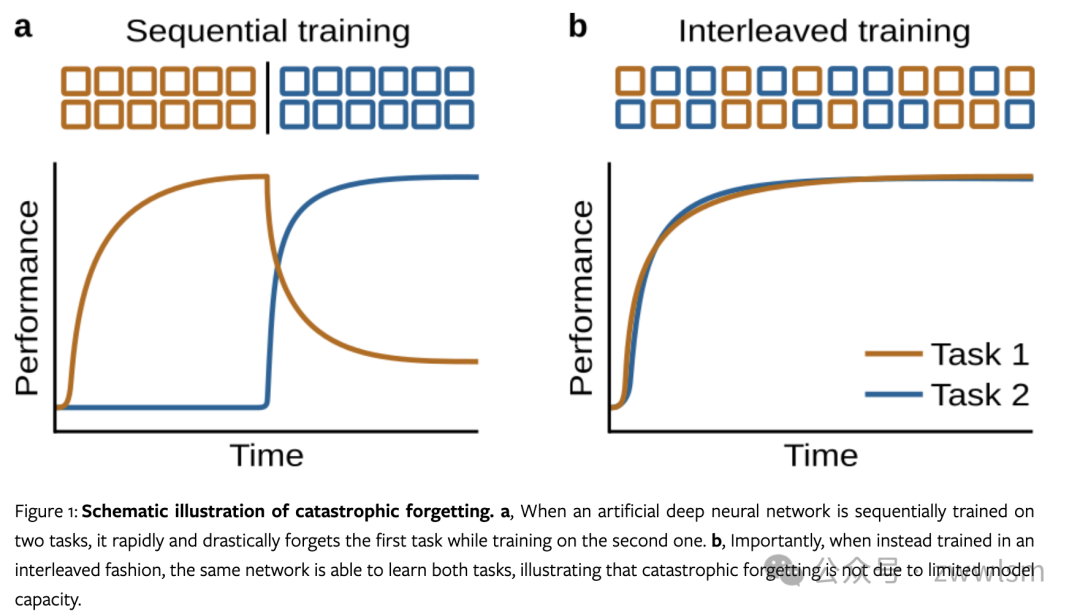
灾难性遗忘是指人工神经网络在学习新信息时倾向于快速且剧烈地忘记先前学习的信息。下面是一个简单的示例代码,展示了灾难性遗忘现象:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neural_network import MLPClassifier# 生成两个简单的二分类数据集
np.random.seed(0)
X1 = np.random.randn(100, 2)
y1 = (X1[:, 0] + X1[:, 1] > 0).astype(int)
X2 = np.random.randn(100, 2) + 3
y2 = (X2[:, 0] - X2[:, 1] > 0).astype(int)# 创建并训练神经网络
model = MLPClassifier(hidden_layer_sizes=(10,), max_iter=1000)# 训练任务1
model.fit(X1, y1)
accuracy1_before = model.score(X1, y1)# 训练任务2
model.fit(X2, y2)
accuracy1_after = model.score(X1, y1)
accuracy2 = model.score(X2, y2)print(f"Task 1 accuracy before Task 2: {accuracy1_before:.2f}")
print(f"Task 1 accuracy after Task 2: {accuracy1_after:.2f}")
print(f"Task 2 accuracy: {accuracy2:.2f}")
这个示例展示了一个简单的神经网络在连续学习两个任务时的灾难性遗忘现象。在学习第二个任务后,模型在第一个任务上的性能显著下降。

2.2 持续学习的其他重要特征
除了避免灾难性遗忘,成功的持续学习方法还应具备以下特征:
-
适应性
-
利用任务相似性
-
与任务无关
-
噪声容忍
-
资源效率和可持续性
下表总结了这些特征及其重要性:
| 特征 | 描述 | 重要性 |
|---|---|---|
| 适应性 | 快速适应新情况或环境 | 对于实时应用至关重要 |
| 利用任务相似性 | 在相关任务之间实现正迁移 | 提高学习效率和泛化能力 |
| 与任务无关 | 不依赖于任务标识符 | 更接近真实世界的学习场景 |
| 噪声容忍 | 处理原始、嘈杂的数据 | 增强模型在实际应用中的鲁棒性 |
| 资源效率 | 高效使用计算和存储资源 | 使持续学习在实践中可行 |
2.3 基于任务与无任务持续学习

基于任务的持续学习假设存在一组离散的任务,而无任务持续学习允许任务之间的渐进过渡和任务重复。以下是一个简化的示例,展示了这两种方法的区别:
import numpy as npdef generate_data(task, n_samples=100):if task == 0:return np.random.randn(n_samples, 2), (np.random.randn(n_samples) > 0).astype(int)else:return np.random.randn(n_samples, 2) + 2, (np.random.randn(n_samples) > 0).astype(int)# 基于任务的持续学习
for task in [0, 1]:X, y = generate_data(task)# 训练模型...# 无任务持续学习
for t in range(1000):task_prob = min(1, t / 500) # 任务概率随时间变化task = np.random.choice([0, 1], p=[1-task_prob, task_prob])X, y = generate_data(task, n_samples=1)# 训练模型...
2.4 三种持续学习场景
van de Ven和Tolias (2018) 区分了三种持续学习场景:任务增量学习 (Task-IL)、领域增量学习 (Domain-IL) 和类增量学习 (Class-IL)。这些场景的主要区别在于测试时是否提供任务身份以及是否必须推断任务身份。
首先,让我们解释一下"任务身份"的概念:任务身份是指在持续学习过程中,明确指示当前数据属于哪个特定任务或上下文的信息。例如,在一个图像分类问题中,任务身份可能指示当前图像是来自动物识别任务还是交通标志识别任务。
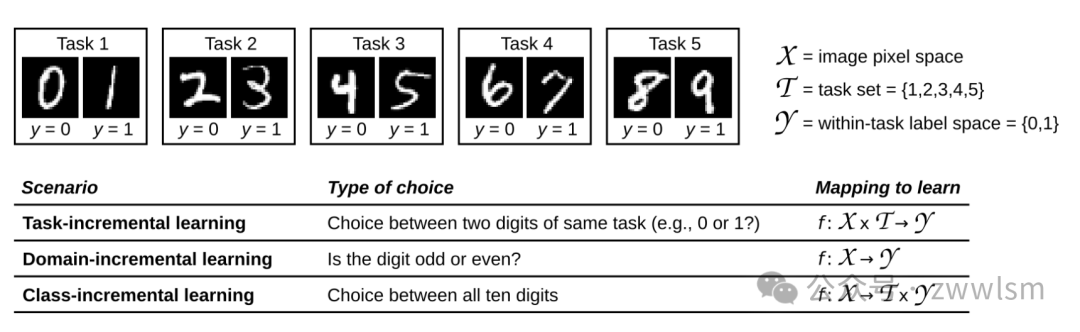
现在,让我们看下这三种学习场景:
- 任务增量学习 (Task-IL):
-
在这种场景中,网络被期望学习一系列不同的任务。
-
在训练和测试时,任务身份都是已知的。
-
网络可以使用任务特定的组件,如每个任务的专用输出层。
-
主要挑战:在不同任务之间共享和迁移知识,同时避免负迁移。
-
示例:学习动物分类(任务1)和建筑分类(任务2),网络知道当前是哪个分类任务。
- 领域增量学习 (Domain-IL):
-
在这种场景中,问题的基本结构保持不变,但输入分布或上下文发生变化。
-
在训练和测试时,任务身份(或域身份)通常是未知的。
-
网络需要适应不同的域,而不依赖于明确的域标识符。
-
主要挑战:在不知道具体域的情况下,对不同域的数据进行泛化。
-
示例:在不同天气条件下识别交通标志,网络不知道当前是哪种天气条件。
- 类增量学习 (Class-IL):
-
在这种场景中,网络需要逐步学习识别越来越多的类别。
-
新类别在训练过程中逐步引入,但在测试时需要区分所有已学习的类别。
-
任务身份在测试时是未知的,网络需要在所有已学类别中进行选择。
-
主要挑战:在不忘记旧类别的同时学习新类别,并在所有类别之间进行有效区分。
-
示例:先学习识别猫和狗,然后学习识别鸟和鱼,最后需要在这四种动物中进行分类。
这三种场景可以用以下表格进行比较:
| 特征 | 任务增量学习 (Task-IL) | 领域增量学习 (Domain-IL) | 类增量学习 (Class-IL) |
|---|---|---|---|
| 任务身份(训练时) | 已知 | 未知 | 已知 |
| 任务身份(测试时) | 已知 | 未知 | 未知 |
| 主要挑战 | 知识共享和迁移 | 跨域泛化 | 增量类别学习和区分 |
| 输出空间 | 每个任务固定 | 跨任务固定 | 随新类别增加 |
理解这些场景的区别对于设计和评估持续学习算法至关重要,因为每种场景都带来了独特的挑战和约束。
2.5 评估
持续学习的评估通常涵盖三个方面:性能、诊断分析和资源效率。以下是一个简单的评估框架示例:
class ContinualLearningEvaluator:def __init__(self):self.performance_history = []self.backward_transfer = []self.forward_transfer = []self.memory_usage = []self.computation_time = []def evaluate(self, model, task_id, X_test, y_test):# 评估性能performance = model.score(X_test, y_test)self.performance_history.append((task_id, performance))# 计算向后迁移if task_id > 0:prev_performance = self.performance_history[task_id-1][1]self.backward_transfer.append(performance - prev_performance)# 记录资源使用self.memory_usage.append(model.get_memory_usage())self.computation_time.append(model.get_computation_time())def report(self):print(f"Average Performance: {np.mean([p for _, p in self.performance_history]):.2f}")print(f"Average Backward Transfer: {np.mean(self.backward_transfer):.2f}")print(f"Average Memory Usage: {np.mean(self.memory_usage):.2f} MB")print(f"Total Computation Time: {sum(self.computation_time):.2f} s")
3. 持续学习方法
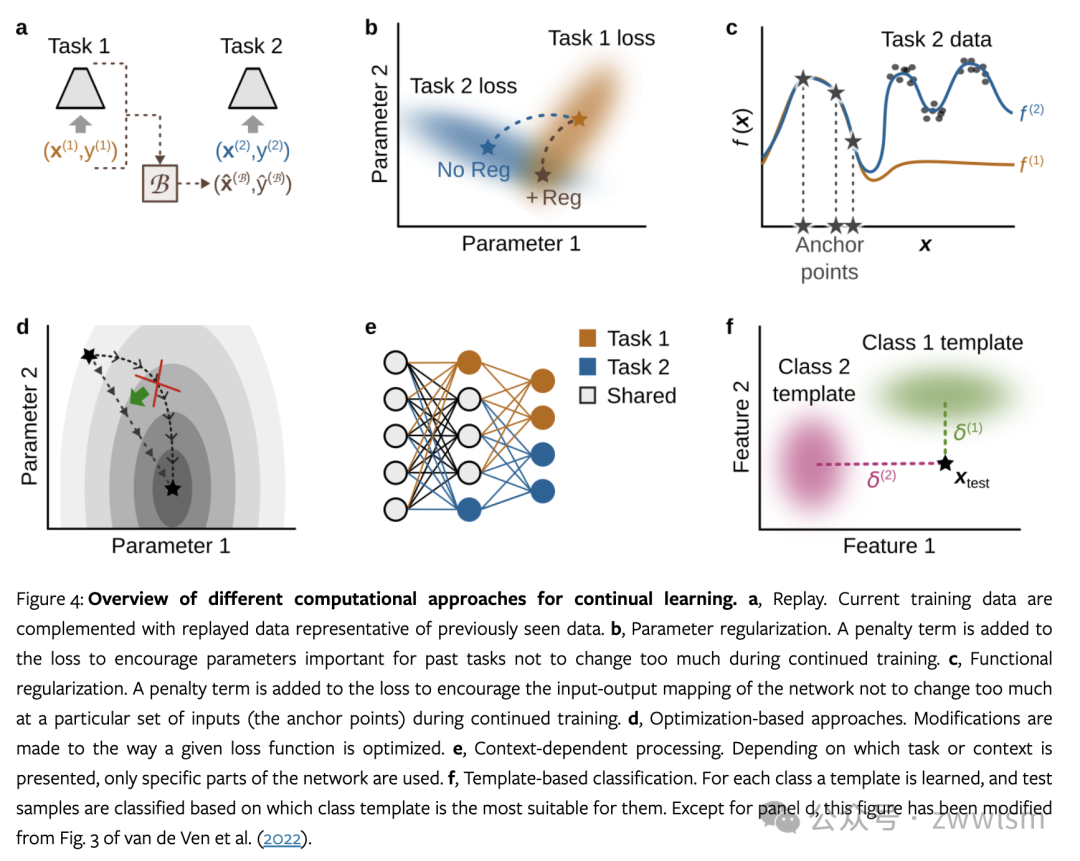
3.1 回放
回放是一种模仿人类记忆系统的方法,通过重复先前学习的信息来防止遗忘,通过补充当前任务的训练数据与代表先前任务的数据来近似交错学习。
详细解释:
-
工作原理:存储部分旧数据或其表示,在学习新任务时同时训练这些旧数据。
-
类型:
-
经验回放:直接存储和重放原始数据样本。
-
生成回放:使用生成模型来创建和重放类似于旧数据的样本。
- 优点:
-
直接对抗遗忘,保持对旧任务的良好性能。
-
实现简单,效果通常很好。
- 缺点:
-
需要额外的存储空间来保存旧数据或生成模型。
-
可能增加训练时间和计算复杂度。
实现考虑:
-
选择性存储:设计策略来选择最具代表性或最重要的样本进行存储。
-
平衡旧数据和新数据:在训练中平衡回放数据和新数据的比例。
-
隐私问题:在某些应用中,存储原始数据可能引发隐私问题。
以下是一个简单的经验回放实现:
class ExperienceReplay:def __init__(self, buffer_size=1000):self.buffer = []self.buffer_size = buffer_sizedef add_experience(self, experience):if len(self.buffer) >= self.buffer_size:self.buffer.pop(0)self.buffer.append(experience)def sample_batch(self, batch_size):return random.sample(self.buffer, min(batch_size, len(self.buffer)))# 使用示例
replay_buffer = ExperienceReplay()
for epoch in range(num_epochs):for x, y in current_task_data:# 训练当前任务model.train_step(x, y)# 添加经验到缓冲区replay_buffer.add_experience((x, y))# 回放旧经验if len(replay_buffer.buffer) > batch_size:replay_batch = replay_buffer.sample_batch(batch_size)for old_x, old_y in replay_batch:model.train_step(old_x, old_y)
3.2 参数正则化
参数正则化通过限制模型参数的变化来防止遗忘,通过阻止对重要参数的大幅度更改来实现的,特别是那些对先前任务重要的参数。
详细解释:
-
工作原理:在学习新任务时,对网络参数施加约束,使其不会过度偏离对旧任务重要的值。
-
方法:
-
L2正则化:基于参数重要性的加权L2惩罚。
-
Fisher信息矩阵:使用Fisher信息来估计参数重要性。
- 优点:
-
不需要存储原始数据,节省存储空间。
-
可以与标准的神经网络训练方法无缝集成。
- 缺点:
-
可能限制模型学习新任务的能力。
-
难以准确估计参数重要性,特别是在复杂模型中。
实现考虑:
-
重要性估计:开发更精确的参数重要性估计方法。
-
自适应正则化:根据任务的相似性动态调整正则化强度。
-
稀疏性:探索如何利用参数正则化来促进模型的稀疏性。
以下是一个使用Fisher信息矩阵的参数正则化示例:
import torch
import torch.nn as nn
import torch.optim as optimclass EWC(nn.Module):def __init__(self, model, lambda_reg=0.1):super(EWC, self).__init__()self.model = modelself.lambda_reg = lambda_regself.fisher = {}self.old_params = {}def estimate_fisher(self, data_loader, num_samples=1000):self.model.eval()for name, param in self.model.named_parameters():self.fisher[name] = torch.zeros_like(param.data)for i, (input, target) in enumerate(data_loader):if i >= num_samples:breakself.model.zero_grad()output = self.model(input)loss = F.cross_entropy(output, target)loss.backward()for name, param in self.model.named_parameters():self.fisher[name] += param.grad.data ** 2 / num_samplesfor name, param in self.model.named_parameters():self.old_params[name] = param.data.clone()def ewc_loss(self):loss = 0for name, param in self.model.named_parameters():loss += (self.fisher[name] * (param - self.old_params[name]) ** 2).sum()return self.lambda_reg * loss# 使用示例
model = MyModel()
ewc = EWC(model)# 估计Fisher信息
ewc.estimate_fisher(old_task_loader)# 训练新任务
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in range(num_epochs):for x, y in new_task_data:optimizer.zero_grad()output = model(x)loss = F.cross_entropy(output, y) + ewc.ewc_loss()loss.backward()optimizer.step()
在这个示例中,EWC类实现了Elastic Weight Consolidation (EWC) 算法,这是一种常用的参数正则化方法。estimate_fisher方法估计参数的Fisher信息,而ewc_loss方法计算正则化损失。
3.3 功能正则化
功能正则化的目标是防止网络的输入-输出映射在特定输入(称为"锚点")处发生大的变化,旨在保持网络在特定输入点的输出一致性,而不是直接约束参数。
详细解释:
-
工作原理:在学习新任务时,保持网络在选定锚点上的输出与之前的输出相似。
-
方法:
-
知识蒸馏:使用旧模型的输出作为软目标。
-
特征蒸馏:在中间层保持特征表示的一致性。
- 优点:
-
比参数正则化更灵活,因为它关注的是输入-输出映射而不是具体参数。
-
可以更好地捕捉任务之间的关系。
- 缺点:
-
选择合适的锚点可能具有挑战性。
-
计算开销可能比参数正则化大。
实现考虑:
-
锚点选择:开发自动选择代表性锚点的方法。
-
多层正则化:在网络的多个层次上应用功能正则化。
-
自适应温度:在知识蒸馏中动态调整温度参数。
以下是一个简单的功能正则化实现:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass FunctionalRegularization(nn.Module):def __init__(self, model, num_anchors=100, lambda_reg=0.1):super(FunctionalRegularization, self).__init__()self.model = modelself.num_anchors = num_anchorsself.lambda_reg = lambda_regself.anchors = Noneself.old_outputs = Nonedef set_anchors(self, data_loader):self.anchors = []self.model.eval()with torch.no_grad():for inputs, _ in data_loader:self.anchors.append(inputs[:self.num_anchors])if len(self.anchors) * inputs.size(0) >= self.num_anchors:breakself.anchors = torch.cat(self.anchors)[:self.num_anchors]self.old_outputs = self.model(self.anchors)def functional_reg_loss(self):if self.anchors is None:return 0new_outputs = self.model(self.anchors)return self.lambda_reg * F.mse_loss(new_outputs, self.old_outputs)# 使用示例
model = MyModel()
func_reg = FunctionalRegularization(model)# 设置锚点
func_reg.set_anchors(old_task_loader)# 训练新任务
optimizer = optim.Adam(model.parameters())
for epoch in range(num_epochs):for x, y in new_task_data:optimizer.zero_grad()output = model(x)loss = F.cross_entropy(output, y) + func_reg.functional_reg_loss()loss.backward()optimizer.step()
在这个示例中,FunctionalRegularization类实现了一个简单的功能正则化方法。set_anchors方法选择锚点并记录旧的输出,而functional_reg_loss方法计算功能正则化损失。
3.4 基于优化的方法
基于优化的方法通过修改学习算法本身来实现持续学习,而不是直接修改损失函数。
详细解释:
-
工作原理:调整优化过程以更好地适应持续学习的场景。
-
方法:
-
梯度投影:将梯度投影到不会干扰旧任务性能的子空间。
-
自适应学习率:根据参数对旧任务的重要性调整学习率。
-
元学习:学习一个能够快速适应新任务的优化算法。
- 优点:
-
可以更精细地控制学习过程。
-
不需要显式存储旧数据或大幅修改模型结构。
- 缺点:
-
可能增加计算复杂度。
-
有时难以与现有的深度学习框架集成。
实现考虑:
-
计算效率:设计计算高效的梯度投影或自适应学习率方法。
-
与其他方法的结合:探索如何将基于优化的方法与其他持续学习技术结合。
-
理论保证:研究这些方法的理论性质,如收敛性和泛化能力。
以下是一个使用自适应学习率的示例:
class AdaptiveLearningRateOptimizer:def __init__(self, model, base_lr=0.01, importance_threshold=0.1):self.model = modelself.base_lr = base_lrself.importance_threshold = importance_thresholdself.parameter_importance = {}def estimate_importance(self, data_loader):self.model.eval()for name, param in self.model.named_parameters():self.parameter_importance[name] = torch.zeros_like(param.data)for inputs, targets in data_loader:self.model.zero_grad()outputs = self.model(inputs)loss = nn.functional.cross_entropy(outputs, targets)loss.backward()for name, param in self.model.named_parameters():self.parameter_importance[name] += torch.abs(param.grad.data)def get_adapted_lr(self, name, param):importance = self.parameter_importance[name]adapted_lr = torch.where(importance > self.importance_threshold,self.base_lr / importance,torch.ones_like(importance) * self.base_lr)return adapted_lrdef step(self):for name, param in self.model.named_parameters():if param.grad is not None:adapted_lr = self.get_adapted_lr(name, param)param.data -= adapted_lr * param.grad.data# 使用示例
model = MyModel()
optimizer = AdaptiveLearningRateOptimizer(model)# 估计参数重要性
optimizer.estimate_importance(old_task_loader)# 训练新任务
for epoch in range(num_epochs):for inputs, targets in new_task_loader:model.zero_grad()outputs = model(inputs)loss = nn.functional.cross_entropy(outputs, targets)loss.backward()optimizer.step()
这个示例实现了一个基于参数重要性的自适应学习率优化器。它首先估计每个参数的重要性,然后在训练新任务时,根据参数的重要性调整学习率。
3.5 上下文相关处理
上下文相关处理通过为不同任务或上下文激活网络的不同部分来减少干扰,思想是仅对特定任务或上下文使用网络的某些部分,参考 MoE 网络。
详细解释:
-
工作原理:根据当前任务或上下文动态调整网络结构或激活模式。
-
方法:
-
多头输出:为每个任务使用专门的输出层。
-
条件计算:使用门控机制选择性激活网络部分。
-
动态架构:根据需要增加新的网络组件。
- 优点:
-
可以有效减少任务间的干扰。
-
允许模型根据需要增长,适应新任务。
- 缺点:
-
可能需要任务标识符,这在某些场景中不可用。
-
可能导致模型规模随任务数量增长而显著增加。
实现考虑:
-
任务识别:开发在没有明确任务标识符的情况下识别当前任务的方法。
-
资源效率:设计能够有效利用网络容量的动态架构策略。
-
知识共享:在任务特定处理的同时促进跨任务知识共享。
以下是一个简单的多头输出层实现:
import torch
import torch.nn as nnclass MultiHeadNetwork(nn.Module):def __init__(self, input_size, hidden_size, num_tasks, task_output_sizes):super(MultiHeadNetwork, self).__init__()self.shared_layers = nn.Sequential(nn.Linear(input_size, hidden_size),nn.ReLU(),nn.Linear(hidden_size, hidden_size),nn.ReLU())self.task_heads = nn.ModuleList([nn.Linear(hidden_size, output_size) for output_size in task_output_sizes])def forward(self, x, task_id):shared_output = self.shared_layers(x)return self.task_heads[task_id](shared_output)# 使用示例
input_size = 784 # 例如,对于MNIST数据集
hidden_size = 256
num_tasks = 5
task_output_sizes = [10, 10, 10, 10, 10] # 假设每个任务都是10类分类model = MultiHeadNetwork(input_size, hidden_size, num_tasks, task_output_sizes)# 训练
optimizer = torch.optim.Adam(model.parameters())
for epoch in range(num_epochs):for inputs, targets, task_id in mixed_task_loader:optimizer.zero_grad()outputs = model(inputs, task_id)loss = nn.functional.cross_entropy(outputs, targets)loss.backward()optimizer.step()
这个示例实现了一个具有多个输出头的网络,每个任务使用一个专门的输出头。共享层处理所有任务的输入,而特定于任务的头部用于最终的分类。
3.6 基于模板的分类
基于模板的分类为每个类别学习一个原型或模板,并基于样本与这些模板的相似度进行分类。
详细解释:
-
工作原理:学习每个类别的代表性模板,将新样本分类到最相似的模板。
-
方法:
-
原型网络:学习类别原型的嵌入表示。
-
基于距离的分类:使用样本到原型的距离进行分类。
-
动态扩展:随着新类别的引入添加新的模板。
- 优点:
-
适合处理类增量学习问题。
-
可以轻松添加新类别,而不需要重新训练整个模型。
- 缺点:
-
可能难以捕捉复杂的类内变化。
-
在高维空间中,基于距离的方法可能遇到挑战。
实现考虑:
-
模板更新:设计有效的策略来更新和维护类别模板。
-
度量学习:探索更好的相似度度量方法,以提高分类性能。
-
层次化模板:为处理大规模类别集开发层次化的模板结构。
以下是一个使用原型网络的简单实现:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass PrototypicalNetwork(nn.Module):def __init__(self, input_size, embedding_size):super(PrototypicalNetwork, self).__init__()self.encoder = nn.Sequential(nn.Linear(input_size, 256),nn.ReLU(),nn.Linear(256, embedding_size))self.prototypes = nn.Parameter(torch.randn(100, embedding_size)) # 假设最多100个类def forward(self, x):embeddings = self.encoder(x)distances = torch.cdist(embeddings, self.prototypes)return -distances # 返回负距离作为相似度得分def add_prototype(self, new_data):with torch.no_grad():new_embedding = self.encoder(new_data).mean(0)self.prototypes = nn.Parameter(torch.cat([self.prototypes, new_embedding.unsqueeze(0)]))# 使用示例
input_size = 784 # 例如,对于MNIST数据集
embedding_size = 64
model = PrototypicalNetwork(input_size, embedding_size)# 训练
optimizer = torch.optim.Adam(model.parameters())
for epoch in range(num_epochs):for inputs, targets in train_loader:optimizer.zero_grad()similarities = model(inputs)loss = F.cross_entropy(-similarities, targets)loss.backward()optimizer.step()# 添加新类
for new_class_data, _ in new_class_loader:model.add_prototype(new_class_data)
这个示例实现了一个简单的原型网络。它学习将输入嵌入到一个低维空间中,并为每个类维护一个原型。分类是通过计算嵌入与原型之间的距离来完成的。
4. 深度学习与认知科学中的持续学习
深度学习和认知科学在持续学习研究中有不同但相关的目标。深度学习旨在设计能够持续学习的人工神经网络,而认知科学关注理解大脑如何实现这种能力。
以下是一个表格,总结了两个领域在持续学习研究中的一些关键差异和潜在的协同效应:
| 方面 | 深度学习 | 认知科学 | 潜在协同效应 |
|---|---|---|---|
| 研究目标 | 开发持续学习算法 | 理解大脑的持续学习机制 | 借鉴生物学启发设计算法 |
| 方法论 | 计算模型和实验 | 行为实验和神经影像学 | 结合计算模型和生物学数据 |
| 遗忘研究 | 关注灾难性遗忘 | 研究多种遗忘机制 | 设计更自然的遗忘机制 |
| 评估指标 | 任务性能和资源效率 | 认知功能和灵活性 | 开发更全面的评估框架 |
| 时间尺度 | 通常关注短期学习 | 研究终身学习过程 | 开发长期持续学习系统 |
5. 结论
持续学习是人工智能领域的一个重要挑战,它不仅需要解决灾难性遗忘问题,还需要开发能够快速适应、利用任务相似性、与任务无关、容忍噪声并高效使用资源的模型。
本章回顾了六种主要的持续学习计算方法:回放、参数正则化、功能正则化、基于优化的方法、上下文相关处理和基于模板的分类。每种方法都有其优缺点,实际应用中往往需要结合多种方法来获得最佳效果。
未来的研究方向可能包括:
-
开发更有效的知识表示和存储方法
-
设计能在不同抽象层次上进行迁移学习的架构
-
探索元学习在持续学习中的应用
-
结合神经科学和认知科学的见解,开发更接近人类学习方式的算法
补充资料:Fisher信息矩阵
Fisher信息矩阵是一个在统计学和机器学习中广泛使用的概念,在持续学习中,特别是在参数正则化方法中,它扮演着重要角色。
Fisher信息矩阵的定义
在神经网络的上下文中,Fisher信息矩阵 F 是一个平方矩阵,其大小等于模型参数的数量。对于参数 θ,Fisher矩阵定义为:
Fisher 信息矩阵的定义:
解释:
-
F 是 Fisher 信息矩阵
-
θ 表示模型参数
-
p(x|θ) 是给定模型参数 θ 时数据 x 的似然
-
∇_θ 表示对参数 θ 的梯度
-
E 表示对数据分布的期望
Fisher矩阵在持续学习中的应用
-
参数重要性估计:Fisher矩阵的对角元素可以被解释为参数重要性的度量。较大的对角元素表示相应的参数对模型输出有较大影响。
-
正则化:在诸如Elastic Weight Consolidation (EWC)等方法中,Fisher矩阵用于构建正则化项,以防止重要参数的大幅变化:
其中:
-
L(θ) 是总的损失函数
-
L_B(θ) 是新任务 B 的损失
-
λ 是正则化强度
-
F_i 是 Fisher 矩阵的第 i 个对角元素
-
θ_i 是当前参数
-
θ_{A,i} 是完成任务 A 后的参数
- 优化:Fisher矩阵提供了参数空间的局部几何信息,可以用来指导优化过程,使其在不大幅改变重要参数的情况下学习新任务。
Fisher矩阵的计算
在实践中,精确计算Fisher矩阵通常是不可行的,特别是对于大型神经网络。因此,通常使用近似方法:
-
对角近似:只计算Fisher矩阵的对角元素,大大减少了计算和存储成本。
-
经验Fisher:使用有限的数据样本来估计Fisher矩阵,而不是对整个数据分布求期望。
在实践中,通常使用经验 Fisher 矩阵的对角近似:
$ F_ii} ≈ \frac{1}{N} \sum_{n=1}^N (\frac{\partial \log p(x_nθ){\partial θ_i})^2 $
解释:
-
F_{i} 是 Fisher 矩阵的第 i 个对角元素
-
N 是样本数量
-
x_n 是第 n 个数据样本
-
θ_i 是第 i 个模型参数
- Kronecker因子分解:将Fisher矩阵分解为Kronecker积的形式,在保留更多结构信息的同时降低计算复杂度。
示例代码
以下是一个使用PyTorch计算Fisher信息矩阵对角近似的简单示例:
import torch
import torch.nn as nn
import torch.nn.functional as Fdef compute_fisher_diag(model, data_loader, num_samples=1000):fisher = {}for name, param in model.named_parameters():fisher[name] = torch.zeros_like(param.data)model.eval()for i, (input, target) in enumerate(data_loader):if i >= num_samples:breakmodel.zero_grad()output = model(input)loss = F.nll_loss(F.log_softmax(output, dim=1), target)loss.backward()for name, param in model.named_parameters():fisher[name] += param.grad.data ** 2 / num_samplesreturn fisher# 使用示例
model = YourNeuralNetwork()
fisher_diag = compute_fisher_diag(model, train_loader)# 在EWC中使用Fisher信息
for name, param in model.named_parameters():ewc_loss += 0.5 * fisher_diag[name] * (param - old_params[name]).pow(2).sum()
Fisher矩阵的优缺点
优点:
-
提供了参数重要性的理论基础。
-
不需要存储原始数据,保护隐私。
-
可以与标准的深度学习优化技术结合。
缺点:
-
精确计算在大型模型中计算成本高。
-
对角近似可能丢失重要的参数间相关性信息。
-
在非凸优化问题中,局部几何信息可能不足以捕捉全局结构。
Fisher信息矩阵是持续学习中参数正则化方法的核心工具之一,它提供了一种理论上合理的方式来估计参数重要性并指导模型在学习新任务时如何保护旧知识。然而,其实际应用还面临着计算效率和准确性的挑战,这也是当前研究的重点之一。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】