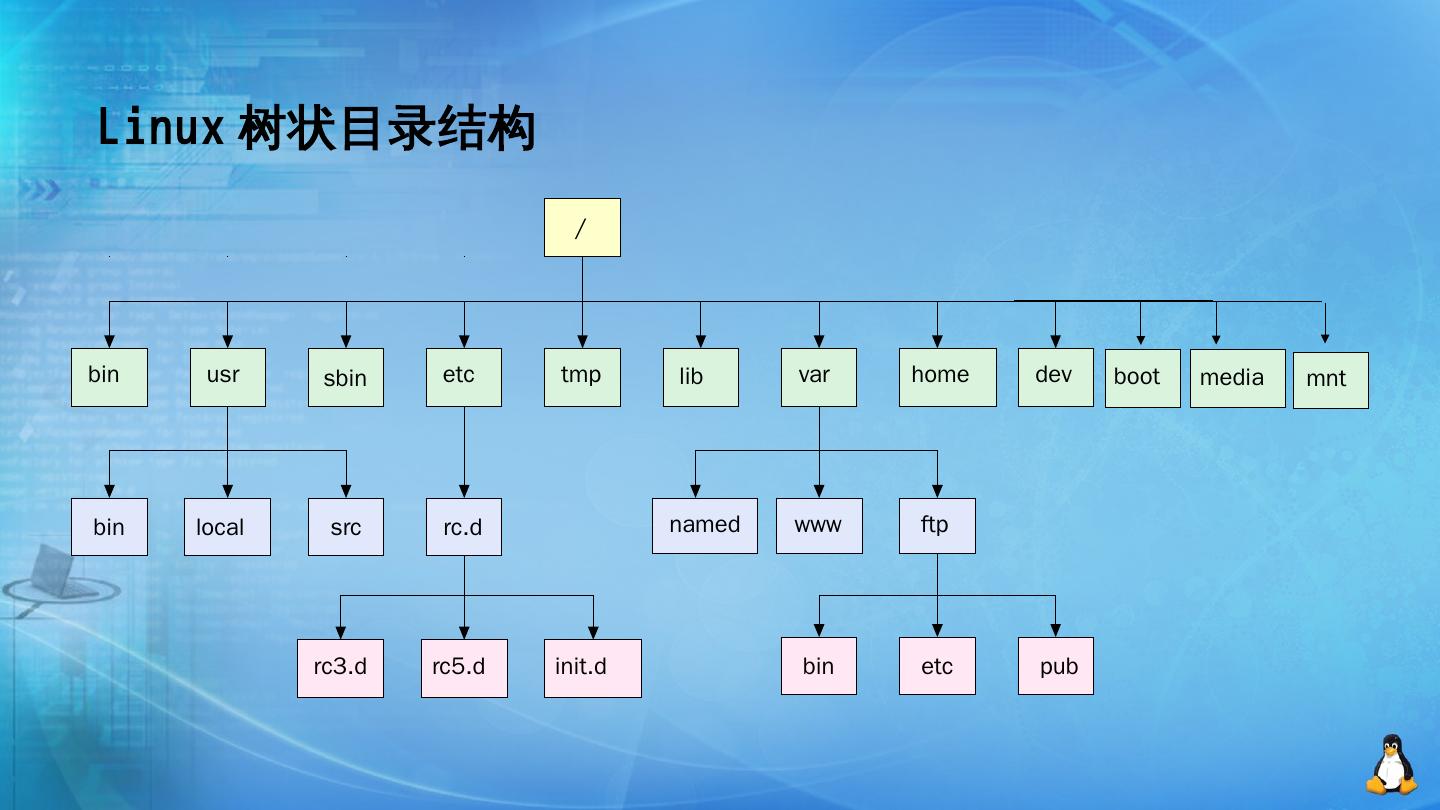
在深度学习领域,随着数据集和模型复杂度的不断增加,单机训练已经难以满足高效、快速的训练需求。为了应对这一挑战,本文介绍了一种基于 PyTorch 和 Kubernetes 的解决方案,旨在构建一个可扩展的深度学习模型训练集群。该方案不仅提高了训练效率,还实现了资源的动态分配和弹性扩展。
一、技术背景与架构
- 深度学习框架:PyTorch,一个开源的机器学习库,以其动态计算图和灵活性而著称。
- 容器编排工具:Kubernetes(K8s),一个开源的容器编排和管理平台,用于自动化部署、扩展和管理容器化应用程序。
- 集群环境:由多个节点组成的计算集群,每个节点运行一个或多个 Docker 容器。
二、PyTorch模型构建
首先,我们使用 PyTorch 构建一个深度学习模型。以图像分类任务为例,我们定义一个简单的卷积神经网络(CNN)。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transformsclass SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(3, 32, 3, 1)self.conv2 = nn.Conv2d(32, 64, 3, 1)self.fc1 = nn.Linear(9216, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.conv1(x)x = nn.functional.relu(x)x = nn.functional.max_pool2d(x, 2)x = self.conv2(x)x = nn.functional.relu(x)x = nn.functional.max_pool2d(x, 2)x = torch.flatten(x, 1)x = self.fc1(x)x = nn.functional.relu(x)x = self.fc2(x)return nn.functional.log_softmax(x, dim=1)# 数据预处理和加载
transform = transforms.Compose([transforms.Resize((32, 32)),transforms.ToTensor(),
])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)三、Kubernetes集群搭建
接下来,我们搭建 Kubernetes 集群。Kubernetes 集群通常由多个节点组成,包括一个主节点和多个工作节点。主节点负责集群的管理和控制,而工作节点负责运行容器化应用程序。
在搭建 Kubernetes 集群时,我们可以选择使用云提供商提供的 Kubernetes 服务(如 GKE、EKS 等),也可以自己搭建裸机集群。无论选择哪种方式,都需要确保集群具有足够的计算资源和网络连通性。
四、PyTorch作业定义与部署
为了将 PyTorch 模型训练作业部署到 Kubernetes 集群上,我们需要定义一个 Kubernetes 作业(Job)。作业是 Kubernetes 中的一种资源对象,用于运行一次性任务或批处理作业。
下面是一个简单的 Kubernetes 作业定义示例:
apiVersion: batch/v1
kind: Job
metadata:name: pytorch-training-job
spec:template:spec:containers:- name: pytorch-trainerimage: pytorch-training-image:latest # 自定义的PyTorch训练镜像command: ["python", "train.py"] # 训练脚本resources:limits:nvidia.com/gpu: 1 # 分配一个GPU资源restartPolicy: NeverbackoffLimit: 4在 train.py 文件中,我们包含上述模型构建的代码,并添加数据加载、模型训练、保存和验证的逻辑。
# train.py
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from model import SimpleCNN # 假设模型定义在model.py文件中# 数据预处理和加载(与上文相同)
# ...def train(model, device, train_loader, optimizer, epoch):model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = F.nll_loss(output, target)loss.backward()optimizer.step()if batch_idx % 10 == 0:print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} ({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')def main():device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = SimpleCNN().to(device)optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)for epoch in range(1, 11): # 训练10个epochtrain(model, device, train_loader, optimizer, epoch)# 保存模型(可选)torch.save(model.state_dict(), "model.pth")if __name__ == "__main__":main()在部署作业时,我们需要确保 PyTorch 训练镜像已经构建并推送到 Docker 仓库中。然后,使用 kubectl apply -f job.yaml 命令将作业定义应用到 Kubernetes 集群上。
五、作业监控与扩展
Kubernetes 提供了丰富的监控和扩展功能。通过 Kubernetes Dashboard 或 kubectl 命令行工具,我们可以实时监控作业的运行状态、资源使用情况以及日志输出。
当需要扩展训练集群时,我们只需增加工作节点的数量或调整作业的资源限制即可。Kubernetes 会自动根据资源需求和可用性来调度和分配容器。