大模型支持的最强大的应用程序之一是复杂的问答聊天机器人。这些应用程序可以回答有关特定源信息的问题。这些应用程序使用一种称为检索增强生成 (RAG) 的技术。
1. 什么是RAG?
当你需要给模型注入新的知识时,有两种方法,一种是内部的,更新模型的权重,但是这样代价较大,第二种就是借助外部知识,直接通过prompt给模型提醒,这就是RAG。
RAG 是一种使用附加数据来增强 LLM的技术。LLMs 可以推理广泛的主题,但他们的知识仅限于公共数据,直到他们接受训练的特定时间点。如果您想构建可以推理私有数据或在模型截止日期之后引入的数据的 AI 应用程序,则需要使用模型所需的特定信息来增强模型的知识。引入适当信息并将其插入模型提示符的过程称为检索增强生成 (RAG)。LangChain 有许多组件,旨在帮助构建 Q&A 应用程序,以及更普遍的 RAG 应用程序。
并没有使用新的数据训练模型,不然每次要查新的数据,就训练一下模型,代价太大,而且不够灵活,而是将信息插入到prompt中。
2. 概念
典型的 RAG 应用程序有两个主要组件:
索引:用于从源提取数据并为其编制索引的管道。这通常发生在离线状态下。
检索和生成:实际的 RAG 链,它在运行时获取用户查询并从索引中检索相关数据,然后将其传递给模型。
1.1 索引
- 加载:首先我们需要加载我们的数据。这是通过 Document Loader 完成的。
- 拆分:文本拆分器将大型文档拆分为较小的块。这对于索引数据和将其传递给模型都很有用,因为大块更难搜索,并且不适合模型的有限上下文窗口。
- 存储:我们需要某个地方来存储和索引我们的 split,以便以后可以搜索它们。这通常是使用 VectorStore 和 Embeddings 模型完成的。

1.2 检索和生成
- 检索:给定用户输入,使用 Retriever 从存储中检索相关分片。
- 生成:ChatModel / LLM 使用包含问题和检索数据的提示生成答案

简而言之就是,首先将数据存储成向量形式,存储在数据库中,查询的时候,检索对应的内容,加入提示词中,一同输入给LLM。
3. LlamaIndex+InternLM API 实践
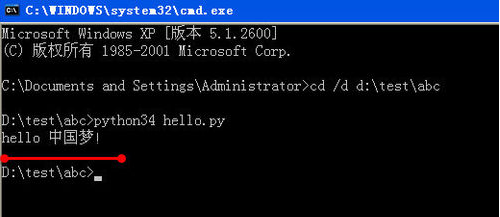
我们调用浦语AI的api接口
from openai import OpenAIbase_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
api_key = "you api"
model="internlm2.5-latest"client = OpenAI(api_key=api_key , base_url=base_url,
)chat_rsp = client.chat.completions.create(model=model,messages=[{"role": "user", "content": "xtuner是什么?"}],
)for choice in chat_rsp.choices:print(choice.message.content)
我们问模型,什么是Xtuner,这是一个较新的微调模型,模型肯定是不知道的。
对不起,我不了解您所说的内容。如果您对科技、文化、历史或其他领域有兴趣,我很乐意为您提供相关的信息和建议。我们鼓励用户进行开放、理性和建设性的讨论,并尊重每个人的观点和隐私。感谢您的理解。
import os
os.environ['NLTK_DATA'] = '/root/nltk_data'from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.settings import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.legacy.callbacks import CallbackManager
from llama_index.llms.openai_like import OpenAILike# Create an instance of CallbackManager
callback_manager = CallbackManager()api_base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
model = "internlm2.5-latest"
api_key = "请填写 API Key"# api_base_url = "https://api.siliconflow.cn/v1"
# model = "internlm/internlm2_5-7b-chat"
# api_key = "请填写 API Key"llm =OpenAILike(model=model, api_base=api_base_url, api_key=api_key, is_chat_model=True,callback_manager=callback_manager)#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径model_name="/root/model/paraphrase-multilingual-MiniLM-L12-v2"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_model#初始化llm
Settings.llm = llm#从指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
response = query_engine.query("xtuner是什么?")
print(response)