像 GPT-4o 这样的模型通过语音实现了与大型语言模型(LLMs)的实时交互,与基于文本的传统交互相比,显著提升了用户体验。然而,目前在如何构建基于开源 LLMs 的语音交互模型方面仍缺乏探索。为了解决这个问题,我们提出了 LLaMA-Omni,这是一个新颖的模型架构,旨在与 LLMs 进行低延迟和高质量的语音交互。LLaMA-Omni 集成了一个预训练的语音编码器、一个语音适配器、一个 LLM 和一个流式语音解码器。它消除了语音转录的需要,并且能够直接从语音指令中同时生成文本和语音响应,延迟极低。我们基于最新的 Llama-3.1-8BInstruct 模型构建了我们的模型。为了使模型与语音交互场景保持一致,我们构建了一个名为 InstructS2S-200K 的数据集,其中包含 200K 条语音指令和相应的语音响应。实验结果表明,与以前的语音-语言模型相比,LLaMA-Omni 在内容和风格上都提供了更好的响应,响应延迟低至 226 毫秒。此外,训练 LLaMA-Omni 仅需要不到 3 天的时间,仅需 4 个 GPU,为未来基于最新 LLMs 的语音-语言模型的高效开发铺平了道路。
我们翻译解读最新论文:与大型语言模型无缝语音交互,文末有论文链接。

1 引言
以 ChatGPT(OpenAI, 2022)为代表的大型语言模型(LLMs)已成为功能强大的通用任务求解器,能够通过会话交互在日常生活中协助人们。然而,目前大多数 LLMs 仅支持基于文本的交互,这限制了它们在文本输入和输出不理想的场景中的应用。最近,GPT4o(OpenAI, 2024)的出现使得通过语音与 LLMs 交互成为可能,以极低的延迟响应用户的指令,并显著提升了用户体验。然而,开源社区在构建基于 LLMs 的此类语音交互模型方面仍缺乏探索。因此,如何实现与 LLMs 的低延迟和高质量的语音交互是一个迫切需要解决的挑战。

与 LLMs 实现语音交互的最简单方法是通过基于自动语音识别(ASR)和文本到语音(TTS)模型的级联系统,其中 ASR 模型将用户的语音指令转录成文本,TTS 模型将 LLM 的响应合成为语音。然而,由于级联系统顺序输出转录的文本、文本响应和语音响应,整个系统的延迟往往较高。相比之下,一些多模态语音-语言模型已经被提出(Zhang et al., 2023; Rubenstein et al., 2023),它们将语音离散化为标记,并扩展 LLM 的词汇表以支持语音输入和输出。理论上,这种语音-语言模型可以直接从语音指令生成语音响应,而不产生中间文本,从而实现极低的响应延迟。然而,在实践中,由于涉及的复杂映射,直接语音到语音的生成可能具有挑战性,因此通常生成中间文本以实现更高的生成质量(Zhang et al., 2023),尽管这牺牲了一些响应延迟。
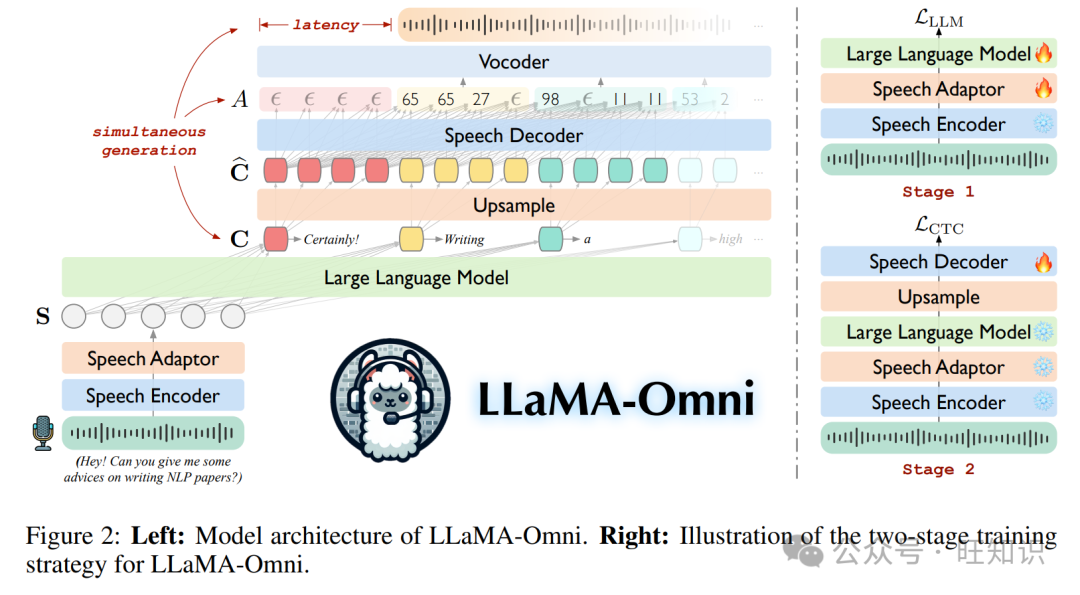
在本文中,我们提出了一个新颖的模型架构 LLaMA-Omni,它实现了与 LLMs 的低延迟和高质量交互。LLaMA-Omni 由语音编码器、语音适配器、LLM 和流式语音解码器组成。用户的语音指令由语音编码器编码,然后由语音适配器处理,然后输入到 LLM 中。LLM 直接从语音指令解码文本响应,而不是先将语音转录成文本。语音解码器是一个非自回归(NAR)流式 Transformer(Ma et al., 2023),它以 LLM 的输出隐藏状态为输入,并使用连接时序分类(CTC; Graves et al., 2006a)预测与语音响应相对应的离散单元序列。在推理过程中,随着 LLM 自回归地生成文本响应,语音解码器同时生成相应的离散单元。为了更好地与语音交互场景的特点保持一致,我们通过重写现有文本指令数据和执行语音合成构建了一个名为 InstructS2S-200K 的数据集。实验结果表明,LLaMA-Omni 可以同时生成高质量的文本和语音响应,延迟低至 226 毫秒。此外,与以前的语音-语言模型如 SpeechGPT(Zhang et al., 2023)相比,LLaMA-Omni 显著减少了所需的训练数据和计算资源,使得基于最新 LLMs 的强大语音交互模型的高效开发成为可能。
2 模型:LLAMA-OMNI
在这一部分,我们介绍了 LLaMA-Omni 的模型架构。如图 2 所示,它由语音编码器、语音适配器、LLM 和语音解码器组成。我们将用户的语音指令、文本响应和语音响应分别表示为 XS、YT 和 YS。
2.1 语音编码器
我们使用 Whisper-large-v32(Radford et al., 2023)的编码器作为语音编码器 E。Whisper 是一个在大量音频数据上训练的通用语音识别模型,其编码器能够从语音中提取有意义的表示。具体来说,对于用户的语音指令 XS,编码的语音表示由 H = E(XS) 给出,其中 H = [h1, …, hN] 是长度为 N 的语音表示序列。在整个训练过程中,我们保持语音编码器的参数不变。
2.2 语音适配器
为了使 LLM 能够理解输入的语音,我们引入了一个可训练的语音适配器 A,将语音表示映射到 LLM 的嵌入空间中。按照 Ma et al. (2024c) 的方法,我们的语音适配器首先对语音表示 H 进行下采样以减少序列长度。具体来说,每 k 个连续帧沿特征维度进行连接:
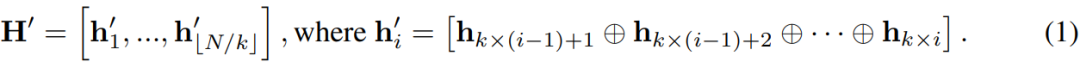
接下来,H′ 通过一个两层感知器,中间有 ReLU 激活函数,得到最终的语音表示 S。上述过程可以形式化为:
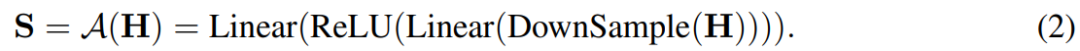
2.3 大型语言模型

我们使用 Llama-3.1-8B-Instruct(Dubey et al., 2024)作为 LLM M,它目前是最先进的开源 LLM。它具有强大的推理能力,并且与人类偏好很好地对齐。提示模板 P(·) 如图 3 所示。将语音表示序列 S 填充到对应于 的位置,然后将整个序列 P(S) 输入到 LLM 中。最后,LLM 基于语音指令自回归地生成文本响应 YT = [yT1, …, yTM],并且使用交叉熵损失进行训练:

2.4 语音解码器
对于语音响应 YS,我们首先遵循 Zhang et al. (2023) 将语音离散化为离散单元。具体来说,我们使用预训练的 HuBERT(Hsu et al., 2021)模型提取语音的连续表示,然后使用 K-means 模型将这些表示转换为离散的聚类索引。随后,将连续相同的索引合并为一个单元,得到最终的离散单元序列 YU = [yU1, …, yUL],yUi ∈ {0, 1, …, K − 1},∀1 ≤ i ≤ L,其中 K 是聚类的数量,L 是离散单元序列的长度。离散单元可以使用额外的基于单元的声码器 V(Polyak et al., 2021)转换为波形。
为了同时生成文本响应和语音响应,我们在 LLM 后面添加了一个流式语音解码器 D。它由几个标准 Transformer(Vaswani et al., 2017)层组成,与 LLaMA 的架构相同,每个层都包含一个因果自注意力模块和一个前馈网络。类似于 Ma et al. (2024a); Zhang et al. (2024b),语音解码器以非自回归方式运行,它以 LLM 的输出隐藏状态为输入,并生成与语音响应相对应的离散单元序列。具体来说,对应于文本响应的输出隐藏状态表示为 C = [c1, …, cM],其中 ci = M(P(S), YT<i)。我们首先通过一个因子 λ 上采样每个隐藏状态,得到上采样的隐藏状态序列 ˜C = [˜c1, …˜cλ·M],其中 ˜ci = c⌊i/λ⌋。接下来,˜C 被输入到语音解码器 D,输出的隐藏状态序列表示为 O = [o1, …, oλ·M]。我们使用连接时序分类(CTC; Graves et al., 2006a)将 O 与离散单元序列 YU 对齐。具体来说,CTC 通过添加一个特殊的空白标记 ϵ 来扩展输出空间:
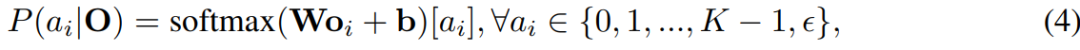
其中 W ∈ R(K+1)×d 和 b ∈ RK+1 是线性层的权重和偏置,序列 A = [a1, …, aλ·M] 被称为对齐。为了模拟输入和输出之间的可变长度映射,CTC 引入了一个折叠函数 β(A),它首先合并 A 中所有连续的重复标记,然后消除所有空白标记 ϵ。例如:β([1, 1, 2, ϵ, ϵ, 2, 3]) = [1, 2, 2, 3]。在训练期间,CTC 通过对所有可能的对齐进行边缘化如下:
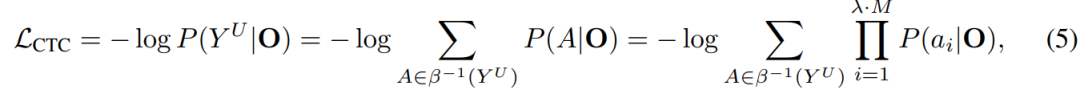
其中 β−1(YU) 表示所有可能的长度为 λ·M 的对齐,可以折叠成 YU。对齐以非自回归方式建模。在推理过程中,我们选择最佳对齐 A* = arg maxA P(A|O),并对获得的离散单元序列应用折叠函数 β(A*),然后将其输入声码器以合成波形。
2.5 训练
如图 2 所示,我们采用两阶段训练策略对 LLaMA-Omni 进行训练。在第一阶段,我们训练模型直接从语音指令生成文本响应。具体来说,语音编码器被冻结,语音适配器和 LLM 使用方程(3)中的目标 LLLM 进行训练。在这个阶段,语音解码器不参与训练。在第二阶段,我们训练模型生成语音响应。在这个阶段,语音编码器、语音适配器和 LLM 都被冻结,只有语音解码器使用方程(5)中的目标 LCTC 进行训练。
2.6 推理
在推理过程中,LLM 基于语音指令自回归地生成文本响应。同时,由于我们的语音解码器使用因果注意力,一旦 LLM 生成了文本响应前缀 YT≤i,相应的上采样隐藏状态 ˜C≤λ·i 就可以输入到语音解码器以生成部分对齐 A≤λ·i,这反过来又产生与生成的文本前缀相对应的离散单元。为了进一步实现语音波形的流式合成,当生成的单元数量达到预定义的块大小 Ω 时,我们将这个单元段输入到声码器以合成语音段,然后立即播放给用户。因此,用户可以在文本响应完全生成之前就开始听语音响应,确保了不受文本响应长度影响的低响应延迟。算法 1 描述了上述过程。此外,由于语音解码器使用非自回归建模,每个文本标记 yTi 对应的对齐 Aλ·(i−1)+1:λ·i 在块内并行生成。因此,同时生成文本和语音的解码速度与仅生成文本的速度没有显著差异。
3 构建语音指令数据:INSTRUCTS2S-200K

为了训练 LLaMA-Omni,我们需要由 <语音指令,文本响应,语音响应> 组成的三元组数据。然而,大多数公开可用的指令数据都是文本形式的。因此,我们通过以下过程基于现有的文本指令数据构建语音指令数据:
步骤 1:指令重写 由于语音输入与文本输入有不同的特点,我们根据以下规则重写文本指令:(1)向指令中添加适当的填充词(例如“嘿”,“所以”,“嗯”等),以模拟自然语音模式。(2)将指令中的非文本符号(如数字)转换为相应的口语形式,以确保 TTS 正确合成。(3)修改指令,使其相对简洁,没有过多的赘述。我们使用 Llama-3-70BInstruct4 模型根据这些规则重写指令。提示可以在附录 A 中找到。

步骤 2:响应生成 在语音交互中,现有的文本指令响应不适合直接用作语音指令响应。这是因为,在基于文本的交互中,模型倾向于生成冗长的响应,使用复杂的句子,并且可能包括非语言元素,如有序列表或括号。然而,在语音交互中,通常更喜欢简洁但信息丰富的响应(Anonymous, 2024)。因此,我们使用 Llama-3-70B-Instruct 模型根据以下规则为语音指令生成响应:(1)响应不应包含 TTS 模型无法合成的内容,例如括号、有序列表等。(2)响应应该非常简洁,避免冗长的解释。提示可以在附录 A 中找到。

步骤 3:语音合成 在获得适合语音交互的指令和响应后,我们需要进一步将它们转换为语音使用 TTS 模型。对于指令,为了使合成的语音听起来更自然,我们使用 CosyVoice-300M-SFT(Du et al., 2024)模型,随机选择每个指令的男性或女性声音。对于响应,我们使用在 LJSpeech(Ito & Johnson, 2017)数据集上训练的 VITS(Kim et al., 2021)模型将响应合成为标准声音。
对于基本的文本指令,我们从 Alpaca 数据集(Taori et al., 2023)中收集了大约 50K 条指令,涵盖了广泛的主题。此外,我们从 UltraChat 数据集(Ding et al., 2023)中收集了大约 150K 条指令,主要包含关于世界的问题。请注意,UltraChat 是一个大规模的多轮对话数据集,但我们只选择前 150K 条记录,并仅使用第一轮指令。使用上述数据集和数据处理流程,我们最终获得了 200K 条语音指令数据,称为 InstructS2S-200K。
4 实验
4.1 实验设置
数据集 对于训练数据,我们使用第 3 节中提到的 InstructS2S-200K 数据集,包含 200K 条语音指令数据。为了提取与目标语音相对应的离散单元,我们使用了一个预训练的 K-means quantizer9,它从 HuBERT 特征中学习了 1000 个聚类。使用预训练的 HiFi-GAN 声码器(Kong et al., 2020; Polyak et al., 2021)将离散单元合成为波形。对于评估数据,我们从 AlpacaEval(Li et al., 2023)中选择了两个子集:helpful base 和 vicuna,因为它们的问题更适合语音交互场景。我们移除了与数学和代码相关的问题,总共得到 199 条指令。为了获得语音版本,我们使用 CosyVoice-300M-SFT 模型将指令合成为语音。在以下部分中,我们将此测试集称为 InstructS2S-Eval。
模型配置 我们使用 Whisper-large-v3 的编码器作为语音编码器,并使用 Llama-3.1-8B-Instruct 作为 LLM。语音适配器对语音表示进行 5× 下采样。语音解码器由 2 个 Transformer 层组成,与 LLaMA 的架构相同,具有 4096 维的隐藏维度,32 个注意力头,以及 11008 维的前馈网络。上采样因子 λ 设置为25。对于输入到声码器的最小单元块大小 Ω,我们在主要实验中将 Ω 设置为 +∞,这意味着我们等待整个单元序列生成后,再将其输入到声码器进行语音合成。在后续实验中,我们将分析如何调整 Ω 的值以控制响应延迟,以及延迟和语音质量之间的权衡。
训练 LLaMA-Omni 遵循两阶段训练过程。在第一阶段,我们使用 32 的批处理大小训练 3 个 epoch 的语音适配器和 LLM。我们使用余弦学习率调度器,在前 3% 的步骤中进行预热,峰值学习率设置为 2e-5。在第二阶段,我们训练语音解码器,使用与第一阶段相同的批处理大小、步数和学习率调度器,但峰值学习率设置为 2e-4。整个训练过程大约需要 65 小时,在 4 个 NVIDIA L40 GPU 上完成。
4.2 评估
由于 LLaMA-Omni 可以根据语音指令生成文本和语音响应,我们从以下方面评估模型的性能:
ChatGPT 分数 为了评估模型遵循语音指令的能力,我们使用 GPT4o(OpenAI, 2024)对模型的响应进行评分。对于 S2TIF 任务,评分基于语音指令的转录文本和模型的文本响应。对于 S2SIF 任务,我们首先使用 Whisper-large-v3 模型将模型的语音响应转录为文本,然后以与 S2TIF 任务相同的方式进行评分。GPT-4o 在两个方面给出分数:内容和风格。内容分数评估模型的响应是否充分解决了用户的指令,而风格分数评估模型的响应风格是否适合语音交互场景。详细的提示可以在附录 A 中找到。

语音-文本对齐 为了评估文本响应和语音响应之间的对齐程度,我们使用 Whisper-large-v3 模型将语音响应转录为文本,然后计算转录文本和文本响应之间的词错误率(WER)和字符错误率(CER)。我们分别将这些指标称为 ASR-WER 和 ASR-CER。
语音质量 为了评估生成的语音质量,我们使用一个称为 UTMOS(Saeki et al., 2022)的平均意见得分(MOS)预测模型,该模型能够预测语音的 MOS 分数以评估其自然度。我们将此指标称为 UTMOS 分数。
响应延迟 对于语音交互模型来说,延迟是一个关键指标,指的是从输入语音指令到开始语音响应之间的时间间隔,这对用户体验有重要影响。此外,我们计算文本响应中已经生成的单词数量,当语音响应开始时,称为 #lagging word。
4.3 基线系统
我们包括以下语音-语言模型作为基线系统:
SpeechGPT SpeechGPT(Zhang et al., 2023)是一个支持语音输入和输出的语音-语言模型。我们使用原始论文中采用的级联模态提示进行解码,顺序输出基于语音指令的文本指令、文本响应和语音响应。
SALMONN (+TTS) SALMONN(Tang et al., 2024)是一个能够接受语音和音频输入并以文本回应的 LLM,能够执行 S2TIF 任务。对于 S2SIF 任务,我们在 SALMOON 后面添加一个 VITS TTS 模型,以级联方式生成语音响应。
Qwen2-Audio (+TTS) Qwen2-Audio(Chu et al., 2024)是一个功能强大的通用音频理解模型,能够执行各种与音频相关的任务,包括 S2TIF 任务。我们还构建了一个与 Qwen2-Audio 和 VITS 级联的系统,以完成 S2SIF 任务。
4.4 主要结果
表1展示了 InstructS2S-Eval 基准测试上的主要结果。首先,对于 S2TIF 任务,从内容的角度来看,LLaMA-Omni 显示出与以前模型相比的显著改进。这主要是因为 LLaMA-Omni 是基于最新的 Llama-3.1-8BInstruct 模型开发的,利用了其强大的文本指令遵循能力。从风格的角度来看,SALMONN 和 Qwen2-Audio 获得较低的分数,因为它们是语音到文本模型。它们的输出风格与语音交互场景不一致,经常产生格式化的内容,并包含大量冗余解释。相比之下,SpeechGPT 作为语音到语音模型,获得了更高的风格分数。同样,我们的 LLaMA-Omni 获得了最高的风格分数,表明在经过我们的 InstructS2S-200K 数据集训练后,输出风格已经很好地与语音交互场景对齐。对于 S2SIF 任务,LLaMA-Omni 也在内容和风格分数上优于以前的模型。这进一步证实了 LLaMA-Omni 能够有效地以简洁高效的方式通过语音解决用户的指令。
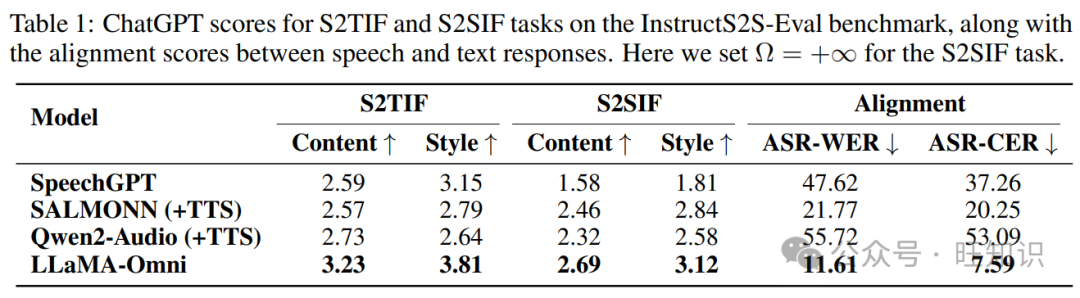
此外,在文本响应和语音响应之间的对齐方面,LLaMA-Omni 达到了最低的 ASR-WER 和 ASR-CER 分数。相比之下,SpeechGPT 在对齐文本和语音响应方面表现不佳,可能是因为它顺序生成文本和语音。级联系统,如 SALMONN+TTS 和 Qwen2-Audio+TTS 的语音-文本对齐也不理想,主要是因为生成的文本响应可能包含无法合成为语音的字符。与此相比,LLaMA-Omni 达到了最低的 ASR-WER 和 ASR-CER 分数,展示了生成的语音和文本响应之间更高程度的对齐,进一步验证了我们方法在同时生成文本和语音响应方面的优势。
4.5 语音质量和响应延迟之间的权衡
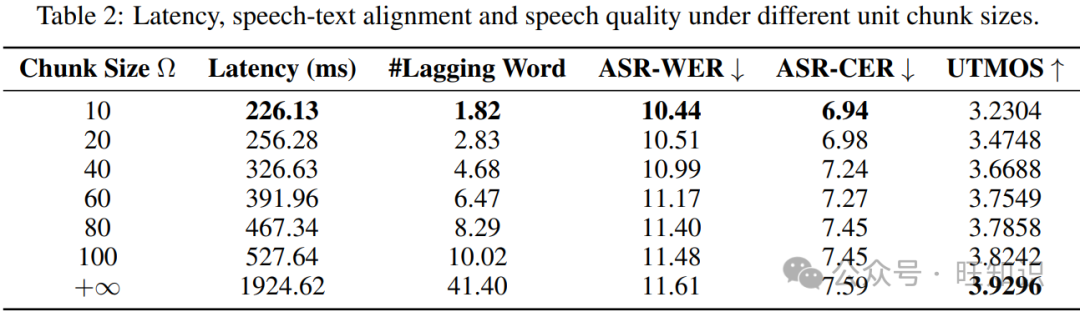
LLaMA-Omni 可以同时生成文本响应和与语音响应相对应的离散单元。如第 2.6 节所述,为了进一步实现流式波形生成,当生成的离散单元数量达到某个块大小 Ω 时,单元块被输入到声码器以合成并播放语音。通过调整 Ω 的值,我们可以控制系统的延迟,较小的 Ω 对应较低的系统延迟。当 Ω = +∞ 时,等同于等待所有单元生成后才开始合成语音。同时,Ω 的值也影响生成的语音质量。较小的 Ω 意味着语音被划分为更多的段进行合成,这可能导致段与段之间的不连贯,从而降低整体的语音连贯性。
为了更好地理解 Ω 的影响,我们探索了在不同 Ω 设置下系统的延迟、文本和语音响应之间的对齐度,以及生成的语音质量。如表 2 所示,当 Ω 设置为 10 时,系统的响应延迟低至 226 毫秒,甚至低于 GPT-4o 平均音频延迟的 320 毫秒。此时,语音响应在开始时平均滞后 1.82 个单词。当 Ω 设置为 +∞ 时,延迟增加到大约 2 秒。对于 ASR-WER 和 ASR-CER 指标,我们惊讶地发现随着块大小的增加,错误率也在增加。我们认为这可能有两个原因。一方面,声码器可能更可靠地处理短单元序列而不是长序列,因为它通常在较短的序列上进行训练。另一方面,我们使用的 ASR 模型 Whisper-large-v3 具有很强的鲁棒性。即使在较小的 Ω 下语音有些不连贯,对 ASR 识别精度的影响也很小。因此,我们进一步使用 UTMOS 指标评估生成语音的自然度。它表明随着 Ω 的增加,语音的自然度得到改善,因为语音中的不连贯性减少了。总之,我们可以根据不同的情境调整 Ω 的值,以实现响应延迟和语音质量之间的权衡。
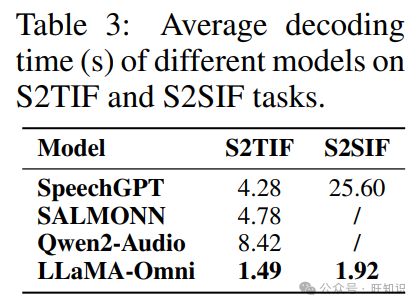
4.6 解码时间
表 3 列出了不同模型在 S2TIF 和 S2SIF 任务上的平均解码时间。对于 S2TIF 任务,SpeechGPT 需要先输出文本指令,然后输出文本响应,而 SALMONN 和 Qwen2-Audio 倾向于产生冗长的响应。相比之下,LLaMA-Omni 提供简洁的回答,直接生成,从而显著降低了解码时间,平均每条指令只需 1.49 秒。对于 S2SIF 任务,SpeechGPT 顺序输出文本和语音响应,导致解码时间是仅生成文本响应的 6 倍。相比之下,LLaMA-Omni 同时输出文本和语音响应,并采用非自回归架构生成离散单元。因此,总生成时间只增加了 1.28 倍,展示了 LLaMA-Omni 在解码速度方面的优势。
4.7 案例研究
为了直观地理解不同模型之间的响应差异,我们在表 4 中提供了一个示例。可以观察到 Qwen2-Audio 的响应相当冗长,并包括诸如换行符和括号等无法合成为语音的元素。SALMONN 的响应也有些长。SpeechGPT 的响应风格更适合语音交互场景,但其响应包含的信息量较少。相比之下,LLaMA-Omni 给出的响应更加详细和有帮助,同时保持了简洁的风格,在语音交互场景中优于以前的模型。

5 相关工作
语音/音频语言模型 随着语言模型在自然语言处理领域的成功,研究人员开始探索如何使用语言模型对语音或音频进行建模。早期的工作尝试在音频的语义标记或声学标记上训练语言模型,使得在不需要文本的情况下生成音频成为可能(Lakhotia et al., 2021; Nguyen et al., 2023; Borsos et al., 2023)。此外,通过联合训练语音标记和文本,像 VALL-E(Wang et al., 2023b)和 VioLA(Wang et al., 2023c)这样的解码器仅模型可以执行语音识别、语音翻译和语音合成等任务。然而,上述模型并非建立在 LLMs 之上。为了利用 LLMs 的力量,许多研究探索了如何基于 LLMs 构建语音-语言模型,如 LLaMA,这可以进一步细分为两种类型。第一种类型,以 SpeechGPT(Zhang et al., 2023; 2024a)和 AudioPaLM(Rubenstein et al., 2023)为代表,通过向 LLM 的词汇表中添加语音标记,并继续使用语音和文本数据进行预训练,创建原生多模态语音-文本模型。
然而,这种方法通常需要大量的数据和大量的计算资源。第二种类型通常涉及在 LLM 之前添加语音编码器,并对整个模型进行微调,使其具备语音理解能力(Shu et al., 2023; Deshmukh et al., 2023),例如语音识别(Fathullah et al., 2024a; Yu et al., 2024; Ma et al., 2024c; Hono et al., 2024)、语音翻译(Wu et al., 2023; Wang et al., 2023a; Chen et al., 2024)或其它通用的语音到文本任务(Chu et al., 2023; Tang et al., 2024; Chu et al., 2024; Fathullah et al., 2024b; Das et al., 2024; Hu et al., 2024)。然而,这些方法通常只关注语音或音频理解,而没有生成它们的能力。与以前的工作相比,LLaMA-Omni 为 LLM 配备了语音理解和生成能力,使其能够执行通用的语音指令遵循任务。此外,LLaMA-Omni 具有较低的训练成本,便于基于最新 LLMs 进行开发。
6 结论
在本文中,我们提出了一个创新的模型架构 LLaMA-Omni,它实现了与 LLMs 的低延迟和高质量语音交互。LLaMA-Omni 建立在最新的 Llama-3.1-8B-Instruct 模型之上,增加了一个用于语音理解的语音编码器和一个可以同时生成文本和语音响应的流式语音解码器。为了使模型与语音交互场景保持一致,我们构建了一个包含 200K 条语音指令及相应语音响应的语音指令数据集 InstructionS2S-200K。实验结果表明,与以前的语音-语言模型相比,LLaMA-Omni 在内容和风格上都提供了更优质的响应,响应延迟低至 226 毫秒。此外,训练 LLaMA-Omni 仅需不到 3 天的时间,仅需 4 个 GPU,使得基于最新 LLMs 的语音交互模型的快速开发成为可能。在未来,我们计划探索增强生成语音响应的表达性并提高实时交互能力。

参考资料
标题:LLAMA-OMNI: SEAMLESS SPEECH INTERACTION WITH LARGE LANGUAGE MODELS
作者:Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui Ma, Shaolei Zhang, Yang Feng
单位:Key Laboratory of Intelligent Information Processing, Institute of Computing Technology, Chinese Academy of Sciences (ICT/CAS); Key Laboratory of AI Safety, Chinese Academy of Sciences; University of Chinese Academy of Sciences, Beijing, China
链接:https://arxiv.org/pdf/2409.06666
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。