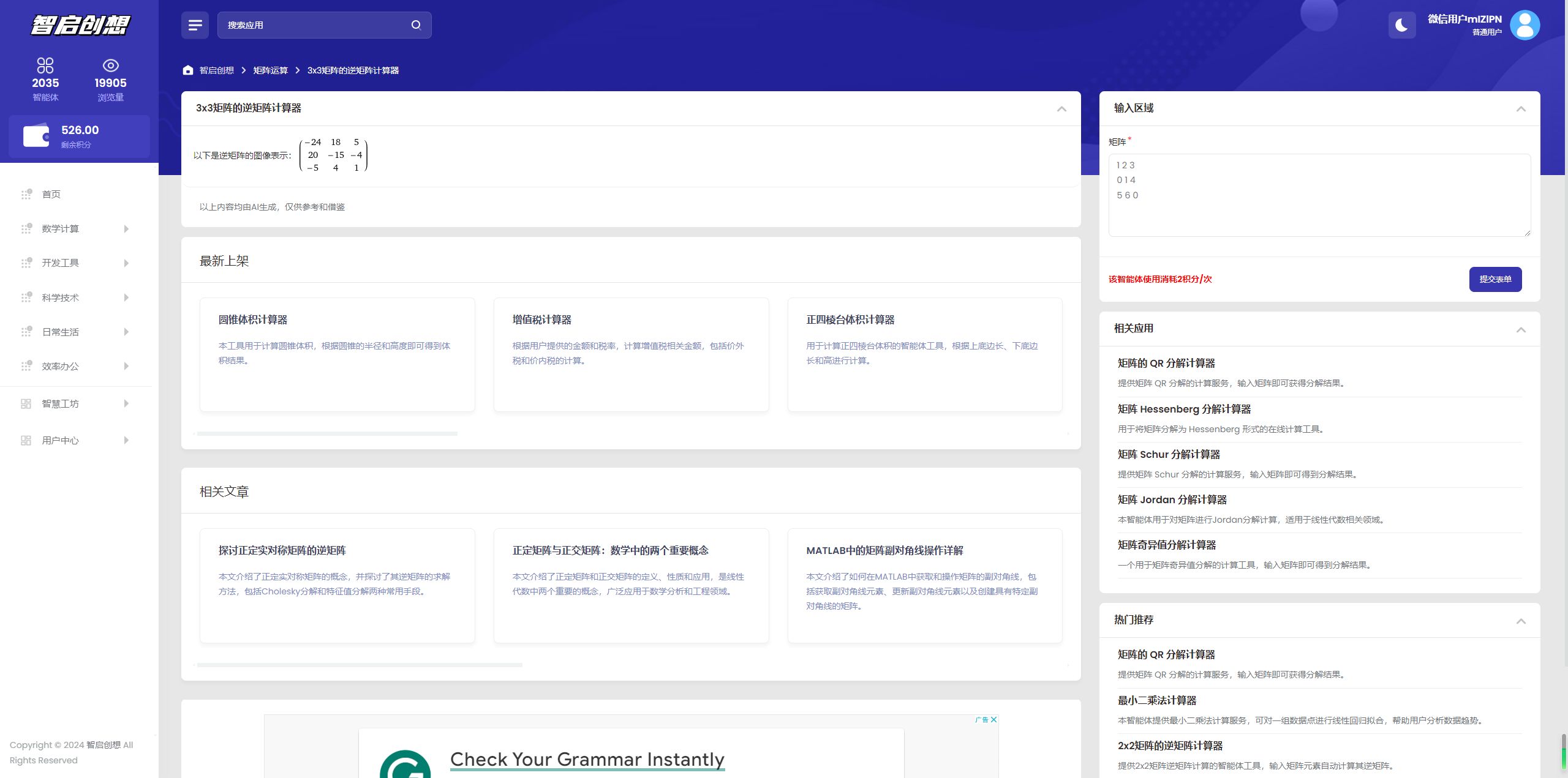
大模型应用
- 前言--名词解释
- 一、大模型幻觉
- 二、AI通用大模型
- 三、工业大模型
- 四、语义大模型
- 五、模型对齐
- 六、知识图谱
- 七、多模态
- 八、NL2SQL
- 九、DALL-E-2
- 十、LLM
- 十一、GAI
- 十二、AIGC
前言–名词解释
大模型幻觉
AI通用大模型
工业大模型
语义大模型
模型对齐
知识图谱
多模态
NL2SQL
DALL-E-2
LLM
GAI
AIGC
一、大模型幻觉
大模型的“幻觉”是指在使用大型语言模型时,模型生成的信息中出现不真实、不准确或虚构的内容。这些现象通常被称为“幻觉”(hallucinations)。这种现象在自然语言处理(NLP)任务中尤其常见,如机器翻译、文本生成和问答系统。简言之就是大模型在对我胡说八道。
二、AI通用大模型
AI通用大模型的核心特性:
①规模庞大:通用大模型通常拥有极其庞大的参数量(数十亿甚至上万亿参数),通过大规模的神经网络进行训练,能在复杂的任务中展现更高的智能水平。
这种规模使得它们能够捕捉到非常丰富的语言模式和知识表达。
②广泛适用性:通用大模型可以在多种任务中表现出色,比如自然语言处理、语言生成、翻译、问答、代码生成、图片生成等。它们可以在没有专门针对某个领域进行微调的情况下,给出合理的答案或解决方案。
③零样本/少样本学习:通用大模型具备零样本(zero-shot)或少样本(few-shot)学习的能力。即使模型没有见过某个特定任务的数据,它也能够根据广泛的语言理解能力进行推理和预测。
这使得模型能够通过少量的示例学习新的任务或领域。
④跨领域的知识整合:由于通用大模型在训练过程中接触了大量不同领域的文本和数据,它们能够跨越不同学科和领域,从而生成或理解涉及多种知识背景的内容。这使得模型不仅可以回答常见问题,还能进行跨领域的知识推理和融合。
总结来说:AI通用大模型可以类比为“百事通”。它具备广泛的知识储备和强大的语言理解与生成能力,能够回答不同领域的问题,就像一个懂很多事物的“百事通”一样。不过,和真正的百事通相比,大模型有时会出现幻觉现象,说的话不一定都对。
三、工业大模型
从通用大模型到工业大模型的过程,核心是将通用模型的广泛知识与特定工业领域的专用数据、专业知识和实际场景相结合。这个过程不仅需要数据驱动,还要结合行业专家的知识,通过定制化训练、模型优化、验证和持续改进,使大模型能够适应工业领域中的复杂任务和需求。
工业大模型是一种专门用于工业领域的大规模预训练模型,它结合了工业细分行业的数据和专家经验,形成垂直化、场景化、专业化的应用模型。 工业大模型通常具有参数量少、专业度高、落地性强等优势,能够更好地适应工业领域的需求。
四、语义大模型
语义大模型主要用于处理和理解文字,但它不仅仅是处理文字的表面形式,更重要的是理解文字背后的深层含义、语境和逻辑关系。它的核心任务是让机器能够像人类一样理解语言中的语义,而不仅仅是简单的词汇匹配或句法分析。
不过,语义大模型不仅限于单纯的文本处理,它还能在一些多模态任务中发挥作用,比如结合图像、视频等数据形式,通过理解其中的文字描述、标签或者场景语义,来做出更加智能的决策或生成内容。因此,虽然它的核心是处理语言文字,但它可以结合其他数据类型进行更广泛的应用。
五、模型对齐
大模型中的模型对齐(Model Alignment)是指确保大型人工智能模型的行为和输出与人类的目标、价值观或预期保持一致的过程。随着大模型的规模和能力不断增加,模型对齐变得尤为重要,以避免模型输出有害、不准确或不符合伦理的结果。
六、知识图谱
知识图谱(Knowledge Graph)是一种用于表示和组织信息的结构化知识库,它通过节点(实体)和边(关系)来构建不同实体之间的关系网络,帮助理解和推理实体之间的关联。知识图谱是人工智能、自然语言处理、搜索引擎、语义网络等领域的重要技术工具,用来帮助系统更好地理解和组织复杂的知识信息。
七、多模态
多模态(Multimodal)是指在计算机科学和人工智能领域,利用多种不同类型的数据(模态)来理解、处理和生成信息。模态可以指不同的感知方式或数据类型,如文本、图像、音频、视频等。多模态技术的核心是能够融合和处理这些不同类型的数据,模拟人类多感官的综合理解能力,从而提升AI系统的表现。
八、NL2SQL
NL2SQL 是 “Natural Language to SQL”(自然语言到SQL)的缩写,它指的是将自然语言查询自动转换为SQL查询语句的技术。通过NL2SQL,用户可以使用自然语言来提问,而系统会将这些问题翻译为SQL语句,从而查询数据库并返回结果。这项技术简化了数据库操作,使得不熟悉SQL语言的用户也能够访问和查询数据库中的数据。
九、DALL-E-2
DALL·E 2 是由 OpenAI 开发的生成图像模型,它可以根据文本描述生成高质量的图像。DALL·E 2 是 DALL·E 的升级版本,具有更强的图像生成能力,能够根据自然语言提示生成比前作更加细致和逼真的图像。它属于一种 文本到图像 的生成模型,结合了自然语言处理和计算机视觉技术。
十、LLM
LLM 是 Large Language Model(大型语言模型)的缩写,指的是基于深度学习技术、通过大规模数据训练的自然语言处理模型**。LLM 具备强大的语言理解和生成能力**,可以在多个任务中表现优异,包括文本生成、翻译、问答、总结、情感分析等。LLM 的典型代表有 OpenAI 的 GPT 系列(如 GPT-3、GPT-4)、Google 的 BERT 和 T5 等
十一、GAI
GAI 是 Generative AI(生成式人工智能)的缩写,指的是能够生成新内容的人工智能技术。与传统的人工智能系统不同,生成式人工智能不仅能分析和处理现有数据,还能基于所学的模式和知识创造新的数据或内容。生成式AI可以生成文本、图像、音乐、代码等多种形式的内容。
GAI 的主要能力是生成全新的内容。例如,通过输入一个文本提示,GAI 能生成一篇文章、图片、或音频。生成式AI通过大量的训练数据学习语言、视觉、音乐等领域中的模式,生成的内容通常是基于这些模式的重组和创新。GAI 能应用于多种场景,涵盖从自然语言处理、图像生成到视频制作等广泛领域。
十二、AIGC
AIGC 是 Artificial Intelligence Generated Content(人工智能生成内容)的缩写,指通过人工智能技术生成各种形式的内容,包括文字、图像、音频、视频等。AIGC 是生成式人工智能(GAI)的应用,它利用深度学习、自然语言处理、计算机视觉等技术,通过对大规模数据的学习,能够自动生成具有创意和实用价值的内容。
文章内容参考大模型工具给出的回答。








![[spring]用MyBatis XML操作数据库 其他查询操作 数据库连接池 mysql企业开发规范](https://i-blog.csdnimg.cn/direct/c882b5582afb4c208f8ded6026bf76f2.png)