PawSQL优化引擎的实现深受PostgreSQL优化器的影响,本文我们来揭密PostgreSQL的代价模型。PawSQL专注于数据库性能优化自动化和智能化,提供的解决方案覆盖SQL开发、测试、运维的整个流程,广泛支持MySQL、PostgreSQL、OpenGauss、Oracle等主流商用和开源数据库,以及openGauss,人大金仓、达梦等国产数据库,为开发者和企业提供一站式的创新SQL优化解决方案,提升了数据库系统的稳定性、应用性能和基础设施利用率。
https://pawsql.com

优化器的代价模型(Cost Model)是数据库查询优化器用于评估不同查询执行计划的代价,并选择最优执行计划的重要核心部分。PostgreSQL 的代价模型通过估算查询执行时的各种操作(如顺序扫描、索引扫描、连接等)的成本,来确定最有效率的查询执行路径。
📈代价的组成
PostgreSQL考虑了多个因素来估算成本:
-
CPU成本:处理元组的CPU时间
-
I/O成本:读取数据页的磁盘I/O时间
-
网络成本:数据传输时间(对分布式查询)
📊 成本估算的公式
在 PostgreSQL 的源代码文件 src/backend/optimizer/path/costsize.c 中,每个成本估算函数都有特定的计算公式。下面我将对之前列出的所有成本函数逐一列出其计算公式,并解释各个公式中的主要变量。
以下是 PostgreSQL 中的成本估算函数的完整列表,包含每个函数的计算公式和变量解释,并按照类别进行组织:
1. 基础扫描操作的成本估算函数
1.1 cost_seqscan - 顺序扫描的成本估算
公式:
total_cost = startup_cost + run_cost run_cost = seq_page_cost * pages + cpu_tuple_cost * tuples
变量解释:
-
startup_cost: 启动扫描的初始成本。 -
run_cost: 完成扫描所有数据的成本。 -
seq_page_cost: 顺序扫描每个页面的 I/O 成本。 -
pages: 需要读取的页面数。 -
cpu_tuple_cost: 处理每个元组的 CPU 成本。 -
tuples: 需要处理的元组数。
1.2 cost_index - 索引扫描的成本估算
公式:
total_cost = indexStartupCost + indexTotalCost + cpu_index_tuple_cost * tuples indexTotalCost = random_page_cost * pages
变量解释:
-
indexStartupCost: 索引扫描的启动成本。 -
indexTotalCost: 索引扫描的总成本。 -
cpu_index_tuple_cost: 处理每个索引元组的 CPU 成本。 -
random_page_cost: 随机页面读取的 I/O 成本。 -
pages: 需要读取的页面数。 -
tuples: 需要处理的元组数。
1.3 cost_indexonlyscan - 索引仅扫描的成本估算
公式:
total_cost = indexStartupCost + indexTotalCost + cpu_index_tuple_cost * tuples
变量解释:
-
indexStartupCost: 索引扫描的启动成本。 -
indexTotalCost: 索引扫描的总成本。 -
cpu_index_tuple_cost: 处理每个索引元组的 CPU 成本。 -
tuples: 需要处理的元组数。
1.4 cost_bitmap_heap_scan - 位图堆扫描的成本估算
公式:
total_cost = startup_cost + run_cost run_cost = page_cost + cpu_tuple_cost * tuples page_cost = random_page_cost * pages
变量解释:
-
startup_cost: 启动扫描的初始成本。 -
run_cost: 完成扫描所有数据的成本。 -
random_page_cost: 随机页面读取的 I/O 成本。 -
page_cost: 需要读取页面的总 I/O 成本。 -
cpu_tuple_cost: 处理每个元组的 CPU 成本。 -
pages: 需要读取的页面数。 -
tuples: 需要处理的元组数。
1.5 cost_bitmap_tree_node - 位图索引扫描的成本估算
公式:
total_cost = cpu_cost + random_page_cost * pages
变量解释:
-
cpu_cost: 处理位图的 CPU 成本。 -
random_page_cost: 随机页面读取的 I/O 成本。 -
pages: 需要读取的页面数。
1.6 cost_subqueryscan - 子查询扫描的成本估算
公式:
total_cost = subquery_startup_cost + subquery_total_cost
变量解释:
-
subquery_startup_cost: 执行子查询的启动成本。 -
subquery_total_cost: 子查询的总执行成本。
1.7 cost_functionscan - 函数扫描的成本估算
公式:
total_cost = cpu_function_cost * num_function_calls
变量解释:
-
cpu_function_cost: 每次调用函数的 CPU 成本。 -
num_function_calls: 函数调用的次数。
1.8 cost_valuesscan - 值扫描的成本估算
公式:
total_cost = cpu_tuple_cost * num_tuples
变量解释:
-
cpu_tuple_cost: 处理每个元组的 CPU 成本。 -
num_tuples: 值扫描中的元组数。
1.9 cost_ctescan - 公用表表达式扫描的成本估算
公式:
total_cost = cte_startup_cost + cte_run_cost
变量解释:
-
cte_startup_cost: 执行 CTE 的启动成本。 -
cte_run_cost: 执行 CTE 的运行成本。
1.10 cost_tablefuncscan - 表函数扫描的成本估算
公式:
total_cost = cpu_function_cost * num_tuples
变量解释:
-
cpu_function_cost: 调用表函数时的 CPU 成本。 -
num_tuples: 表函数返回的元组数。
1.11 cost_tidscan - TID 扫描的成本估算
公式:
total_cost = random_page_cost * num_pages + cpu_tuple_cost * num_tuples
变量解释:
-
random_page_cost: 随机页面读取的 I/O 成本。 -
num_pages: 需要读取的页面数。 -
cpu_tuple_cost: 处理每个元组的 CPU 成本。 -
num_tuples: 需要处理的元组数。
1.12 cost_worktablescan - 工作表扫描的成本估算
公式:
total_cost = startup_cost + run_cost
变量解释:
-
startup_cost: 扫描的启动成本。 -
run_cost: 完成扫描的运行成本。
1.13 cost_foreignscan - 外部数据源扫描的成本估算
公式:
total_cost = foreign_scan_cost
变量解释:
-
foreign_scan_cost: 外部数据源提供的扫描成本。
2. 连接操作的成本估算函数
2.1 cost_nestloop - 嵌套循环连接的成本估算
公式:
total_cost = outer_cost + outer_tuples * inner_cost_per_tuple
变量解释:
-
outer_cost: 扫描外部表的总成本。 -
outer_tuples: 外部表中的元组数。 -
inner_cost_per_tuple: 内部表每个元组的扫描成本。
2.2 cost_mergejoin - 归并连接的成本估算
公式:
total_cost = outer_path_cost + inner_path_cost + merge_cost merge_cost = cpu_operator_cost * num_outer * log2(num_inner)
变量解释:
-
outer_path_cost: 扫描外部表的成本。 -
inner_path_cost: 扫描内部表的成本。 -
merge_cost: 合并两个已排序输入的成本。 -
cpu_operator_cost: 每个连接操作的 CPU 成本。 -
num_outer: 外部表的行数。 -
num_inner: 内部表的行数。
2.3 cost_hashjoin - 哈希连接的成本估算
公式:
total_cost = outer_cost + inner_cost + hash_cost + probe_cost
变量解释:
-
outer_cost: 扫描外部表的成本。 -
inner_cost: 扫描内部表的成本。 -
hash_cost: 构建哈希表的成本。 -
probe_cost: 探测哈希表的成本。
3. 其他操作的成本估算函数
3.1 cost_sort - 排序操作的成本估算
公式:
total_cost = startup_cost + run_cost run_cost = (log2(input_tuples) * input_tuples) * cpu_operator_cost
变量解释:
-
startup_cost: 启动排序的成本。 -
run_cost: 排序的运行成本。 -
input_tuples: 需要排序的元组数。 -
cpu_operator_cost: 每次比较操作的 CPU 成本。
3.2 cost_material - 物化操作的成本估算
公式:
total_cost = startup_cost + cpu_tuple_cost * tuples
变量解释:
-
startup_cost: 物化操作的启动成本。 -
cpu_tuple_cost: 处理每个元组的 CPU 成本。 -
tuples: 需要处理的元组数。
3.3 cost_agg - 聚合操作的成本估算
公式:
total_cost = cpu_agg_cost * numGroups
变量解释:
-
cpu_agg_cost: 每个聚合操作的 CPU 成本。 -
numGroups: 分组的数量。
3.4 cost_windowagg - 窗口聚合操作的成本估算
公式:
total_cost = cpu_windowagg_cost * numGroups
变量解释:
-
cpu_windowagg_cost: 每个窗口聚合操作的 CPU 成本。 -
numGroups: 窗口函数处理的分组数。
3.5 cost_group - 分组操作的成本估算
公式:
total_cost = cpu_group_cost * numGroups
变量解释:
-
cpu_group_cost: 每个分组操作的 CPU 成本。 -
numGroups: 分组的数量。
3.6 cost_unique - 唯一操作的成本估算
公式:
total_cost = cpu_unique_cost * numGroups
变量解释:
-
cpu_unique_cost: 去重操作的 CPU 成本。 -
numGroups: 处理的分组数量。
3.7 cost_setop - 集合操作的成本估算
公式:
total_cost = cpu_setop_cost * numGroups
变量解释:
-
cpu_setop_cost: 集合操作的 CPU 成本。 -
numGroups: 操作中涉及的分组数量。
3.8 cost_limit - LIMIT 操作的成本估算
公式:
total_cost = startup_cost + cpu_tuple_cost * limit_tuples
变量解释:
-
startup_cost: LIMIT 操作的启动成本。 -
cpu_tuple_cost: 处理每个元组的 CPU 成本。 -
limit_tuples: LIMIT 限制的元组数。
3.9 cost_result - Result 节点的成本估算
公式:
total_cost = cpu_result_cost
变量解释:
-
cpu_result_cost: 处理结果的 CPU 成本。
3.10 cost_append - Append 操作的成本估算
公式:
total_cost = startup_cost + run_cost
变量解释:
-
startup_cost: Append 操作的启动成本。 -
run_cost: 执行 Append 操作的运行成本。
3.11 cost_recursive_union - 递归 UNION 操作的成本估算
公式:
total_cost = left_cost + right_cost + recursive_cost
变量解释:
-
left_cost: 左子查询的成本。 -
right_cost: 右子查询的成本。 -
recursive_cost: 递归操作的成本。
4. 路径成本估算函数
4.1 get_path_cost - 获取路径成本
公式:
total_cost = path->total_cost
变量解释:
-
path->total_cost: 已计算的路径的总成本。
4.2 cost_index_path - 索引路径的成本估算
公式:
total_cost = indexStartupCost + indexTotalCost + cpu_index_tuple_cost * tuples
变量解释:
-
indexStartupCost: 索引路径的启动成本。 -
indexTotalCost: 索引路径的总成本。 -
cpu_index_tuple_cost: 每个元组的 CPU 成本。 -
tuples: 处理的元组数。
4.3 cost_bitmap_and_node - 位图 AND 节点的成本估算
公式:
total_cost = cpu_bitmap_and_cost
变量解释:
-
cpu_bitmap_and_cost: 位图 AND 操作的 CPU 成本。
4.4 cost_bitmap_or_node - 位图 OR 节点的成本估算
公式:
total_cost = cpu_bitmap_or_cost
变量解释:
-
cpu_bitmap_or_cost: 位图 OR 操作的 CPU 成本。
5. 其他相关辅助函数
5.1 get_reltuples - 获取关系的行数
公式:
reltuples = rel->rows
变量解释:
-
rel->rows: 估算的表中行数。
5.2 get_relwidth - 获取关系的宽度
公式:
relwidth = rel->reltarget->width
变量解释:
-
rel->reltarget->width: 表中每行的字节宽度。
5.3 clamp_row_est - 行估算值的限制
公式:
clamped_rows = max(min(rows, MAX_ROWS), MIN_ROWS)
变量解释:
-
rows: 估算的行数。 -
MAX_ROWS: 行数的最大合理值。 -
MIN_ROWS: 行数的最小合理值。
这些公式是 PostgreSQL 查询优化器评估不同查询执行计划成本的核心工具。它们根据特定查询操作的性质,结合系统参数和表的统计信息,计算出各种执行路径的成本,从而帮助优化器选择最优路径。
🛠️ 公式中的参数
PostgreSQL优化器的代价模型使用下面这些参数来估算每个算子的代价,这些参数默认值可能会因PostgreSQL的版本或特定的系统配置而有所不同。以下是基于PostgreSQL 14版本的常见默认值:
-
seq_page_cost: 1.0
-
含义: 顺序读取一个磁盘页面的成本
-
-
random_page_cost: 4.0
-
含义: 随机读取一个磁盘页面的成本
-
-
cpu_tuple_cost: 0.01
-
含义: 处理每个元组的CPU成本
-
-
cpu_index_tuple_cost: 0.005
-
含义: 处理每个索引元组的CPU成本
-
-
cpu_operator_cost: 0.0025
-
含义: 执行每个操作符或函数的CPU成本
-
-
pages:
-
含义: 表或索引的页面数,根据实际表或索引大小计算,没有固定默认值
-
-
tuples:
-
含义: 预计处理的元组数,基于表统计信息,没有固定默认值
-
-
index_pages_fetched:
-
含义: 预计读取的索引页面数,根据索引统计信息计算,没有固定默认值
-
-
tuples_fetched:
-
含义: 通过索引获取的元组数,根据查询条件和统计信息估算,没有固定默认值
-
-
bitmap_pages:
-
含义: 位图中的页面数,根据查询条件和统计信息估算,没有固定默认值
-
-
tids_fetched:
-
含义: 通过TID扫描获取的元组数,根据查询条件确定,没有固定默认值
-
重要的是要注意,这些成本参数(如seq_page_cost, random_page_cost等)是相对值,它们之间的比例关系比绝对值更重要。优化器使用这些值来比较不同执行计划的相对成本,从而选择最优计划。
您可以通过修改postgresql.conf文件或使用SET命令来调整这些参数,以更好地适应您的特定硬件和工作负载。在调整这些参数时,建议进行充分的测试,以确保更改确实提高了查询性能。
🌟 总结
-
基于统计信息:
-
PostgreSQL 利用表和索引的统计信息(如行数、页面数、行宽度、唯一值数目等)来估算每种操作的成本。
-
-
成本的组成:
-
代价模型综合考虑了I/O成本(顺序扫描、随机读取)、CPU成本(处理行和执行操作符)以及其他初始化或启动成本,来估算每种查询操作的代价。
-
-
多路径评估:
-
对于每个查询,优化器会生成多种可行路径,并基于代价模型对这些路径进行评估,选择总成本最低的路径。
-
-
灵活性:
-
代价模型中的参数(如
seq_page_cost,cpu_tuple_cost等)可以根据数据库的实际硬件环境和应用场景进行调优,以获得更好的查询性能。
-
通过这种代价模型,PostgreSQL 能够在复杂查询的多种执行路径中选择最优路径,确保高效的查询执行。
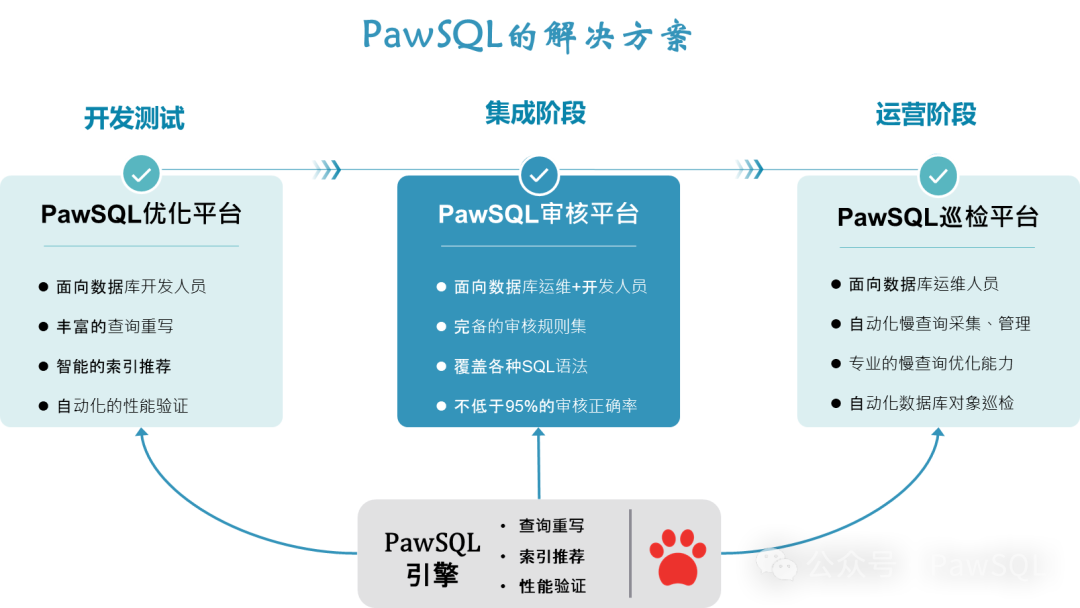
🌟关于PawSQL
PawSQL专注于数据库性能优化自动化和智能化,提供的解决方案覆盖SQL开发、测试、运维的整个流程,广泛支持MySQL、PostgreSQL、OpenGauss、Oracle等主流商用和开源数据库,以及openGauss,人大金仓、达梦等国产数据库,为开发者和企业提供一站式的创新SQL优化解决方案;有效解决了数据库SQL性能及质量问题,提升了数据库系统的稳定性、应用性能和基础设施利用率,为企业节省了大量的运维成本和时间投入。