昨天Claude团队发了一个关于RAG的博客,介绍了上下文召回的思路,可以看看。先看看标准的RAG(检索增强生成)是怎么做的?
- 将用于检索的知识库(文档)拆为小(几百个token)的文本块
- 对文本块进行 TF-IDF 编码以及语义嵌入
- 使用 BM25 检索最相似的文本块
- 使用文本嵌入检索语义相似的文本块
- 合并、去重、排序两种方式检索得到的文本块
- 将 top k 个文本块放进提示词中辅助 LLM 生成回答
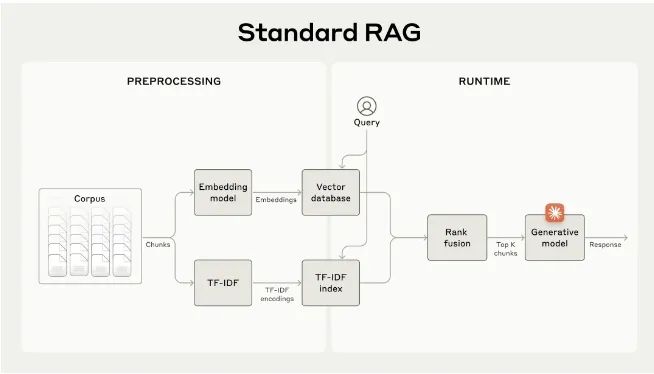
因为需要对文本进行切块,所以经常遇到上下文被不合理分割的情况
举个例子,如果LLM的知识库里有一堆财务信息(比如美国SEC的文件),然后问题是:“ACME公司2023年第二季度的收入增长了多少?”这时候可能会有一个相关的信息是:“这家公司的收入比上个季度涨了3%。”但是呢,这句话没说是哪家公司,也没提具体的时间,这就让模型很难找到准确的信息,也很难有效地利用这个信息。
上下文召回通过在每个文本块前添加特定于该文本块的解释性上下文来解决这个问题。
下面是一个示例展示了原始文本块和包含上下文的文本块的区别
original_chunk = "The company's revenue grew by 3% over the previous quarter."contextualized_chunk = "This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter."
具体怎么做呢?
作者写了一个提示词,指导模型提供简洁的、特定于文本块的上下文,使用整体文档的上下文来解释该文本块:
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
生成的上下文信息通常在50-100个tokens,会被拼接到原始文本块之前。
下面是完整的流程图
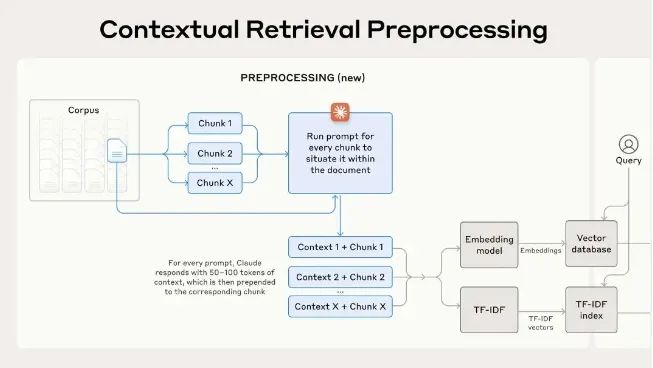
性能提升有多少?
我们的实验表明:
- 上下文嵌入将前20个块的检索失败率降低了35%(从5.7%降至3.7%)。
- 结合上下文嵌入和上下文BM25将前20个块的检索失败率降低了49%(从5.7%降至2.9%)。
一些实验过程可以关注的细节:
- 文本块边界:考虑如何将文档分割成块。块大小、块边界和块重叠的选择会影响检索性能。
- 嵌入模型:不同的模型使用上下文嵌入的提升可能不一样,在作者的实验中Gemini和Voyage嵌入特别有效。
- 自定义上下文提示:虽然提供的通用提示词效果良好,但可能能够通过针对特定领域或用例定制的提示获得更好的结果(例如,包括知识库中仅在其他文档中定义的关键术语词汇表)。
- 块数量:将更多块添加到上下文窗口会增加包含相关信息的机会。然而,更多的信息可能会分散模型的注意力,因此存在一定的限制。尝试了传递5、10和20个块,发现使用20个块在这些选项中表现最佳,但在您的用例中进行实验是值得的。
结合重排性能更佳!
重排是一种常用的过滤技术,以确保只有最相关的片段被传递给模型。
- 执行初始检索以获取最有可能相关的片段(我们使用了前150个);
- 将前N个片段与用户的查询一起传递给重排模型;
- 使用重排模型,根据每个片段与提示的相关性和重要性为其打分,然后选择前K个片段(我们使用了前20个);
- 将前K个片段作为上下文传递给模型以生成最终结果。
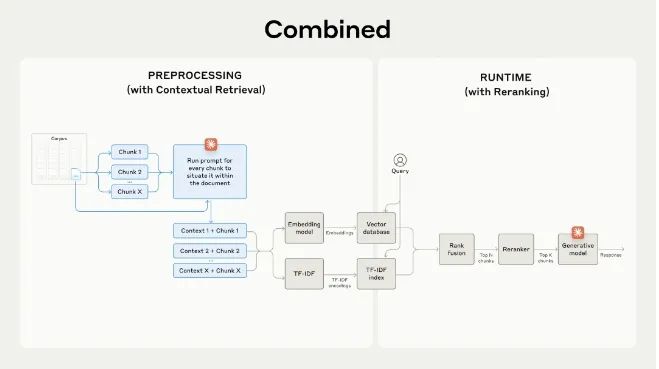
结合重排后 top-20 的召回失败率减少了67% (5.7% → 1.9%)

如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。