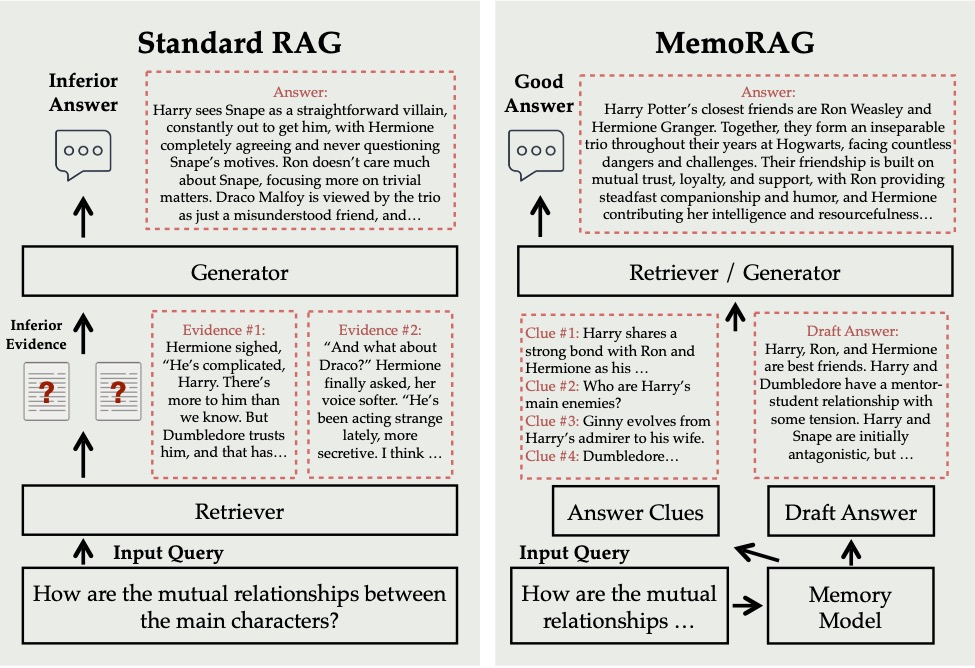
谷歌团队探索了 Transformer 在图像识别中的直接应用。
Vision Transformer(ViT)是一种基于Transformer架构的深度学习模型,用于图像识别和计算机视觉任务。与传统的卷积神经网络(CNN)不同,ViT直接将图像视为一个序列化的输入,并利用自注意力机制来处理图像中的像素关系。
ViT通过将图像分成一系列的图块(patches),并将每个图块转换为向量表示作为输入序列。然后,这些向量将通过多层的Transformer编码器进行处理,其中包含了自注意力机制和前馈神经网络层。这样可以捕捉到图像中不同位置的上下文依赖关系。最后,通过对Transformer编码器输出进行分类或回归,可以完成特定的视觉任务。
为什么不能直接将transformer直接应用于图像处理中呢?这是因为transformer本身是用来处理序列任务的(比如NLP),但图像是二维或三维的,像素之间存在一定的结构关系,如果单纯的将transformer之间应用于图像中,像素和像素之间需要一定的关联性,那么这个计算量是相当大的。因此vit就诞生了。
ViT模型框架

图1:模型概述。我们将图像分割成固定大小的块,线性地嵌入每个块,添加位置嵌入,并将生成的向量序列提供给标准的Transformer编码器。为了执行分类,我们向序列中添加额外的可学习“分类令牌”。
Embedding详解
对于标准的Transformer模块,要求输入的是token(向量)序列,即二维矩阵[num_token, token_dim],如下图,token0-9对应的都是向量,以ViT-B/16为例,每个token向量长度为768。

对于图像数据而言,其数据格式为[H, W, C],三维矩阵明显不是Transformer想要的。所以需要先通过一个Embedding层来对数据做个变换。如下图所示,首先将一张图片按给定大小分成一堆Patches。以ViT-B/16为例,将输入图片(224x224)按照16x16大小的Patch进行划分,划分后会得到196个Patches。接着通过线性映射将每个Patch映射到一维向量中,每个Patche数据shape为[16, 16, 3]通过映射得到一个长度为768的向量(后面都直接称为token)。[16, 16, 3] -> [768]
在代码实现中,直接使用一个kernel_size为16x16,stride为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
在输入Transformer Encoder之前注意需要加上[class]token以及Position Embedding。 在原论文中,作者说参考BERT,在刚刚得到的一堆tokens中插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,就是一个长度为768的向量,与之前从图片中生成的tokens拼接在一起,Cat([1, 768], [196, 768]) -> [197, 768]。然后关于Position Embedding就是之前Transformer中讲到的Positional Encoding,这里的Position Embedding采用的是一个可训练的参数(1D Pos. Emb.),是直接叠加在tokens上的(add),所以shape要一样。刚刚拼接[class]token后shape是[197, 768],那么这里的Position Embedding的shape也是[197, 768]。

Transformer Encoder详解
Transformer Encoder其实就是重复堆叠Encoder Block L次,下图为Encoder Block,主要由以下几部分组成:

Layer Norm,对每个token进行Norm处理。
Multi-Head Attention,多头注意力机制是自注意力(Self-Attention)的一个扩展。
Dropout/DropPath,在原论文的代码中是直接使用的Dropout层,在但rwightman实现的代码中使用的是DropPath(stochastic depth),可能后者会更好一点。
MLP Block,如上图右侧所示,就是全连接+GELU激活函数+Dropout组成也非常简单,需要注意的是第一个全连接层会把输入节点个数翻4倍[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]
MLP Head详解
上面通过Transformer Encoder后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是[197, 768]输出的还是[197, 768]。注意,在Transformer Encoder后其实还有一个Layer Norm没有画出来,后面的ViT的模型可以看到详细结构。这里只是需要分类的信息,所以只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出[class]token对应的[1, 768]。接着通过MLP Head得到我们最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可。

存在的问题
1、数据不足:小数据集可能不足以训练出一个有效的ViT模型,因为ViT需要大量数据来学习全局依赖关系。
2、过拟合:在小数据集上训练ViT容易导致过拟合,因为模型可能会记住训练数据而不是学习到泛化的特征。
解决方案
1、预训练模型:使用在大规模数据集上预训练的ViT模型,然后在小数据集上进行微调。预训练可以帮助模型获得有用的特征表示,从而减少对小数据集的依赖。
2、迁移学习:利用已经在相关任务上训练好的模型进行迁移学习,可以有效利用小数据集进行训练。
3、小型ViT架构:使用较小的ViT变体,这些变体通常包含较少的参数,更适合小数据集上的训练。
建议采用迁移学习方法,即使用在大型数据集上预训练的ViT模型,并将其微调到小型数据集上。
总结
1、ViT开创性的提出了Transformer除了在NLP领域之外,在视觉领域也能产生很好的效果。
2、作者使用了纯Transformer应用在图像分类,没有专门为视觉任务而做出特定的结构设计或者改变,实现了Transformer在NLP和CV领域的统一(最大的贡献),后续很多其他先进方法都是在ViT的基础上不断优化改进。
3、从效果来看,ViT的精度和模型复杂度都不如Swin Transformer,但是Swin Transformer是专门为视觉领域的下游任务做了特定的结构设计,使得其效果大大提升,模型复杂度也降低下来,SwinT的作者证明了其在视觉下游任务(分类、检测、分割)的通用性,可以作为一个很强的backbone;而ViT则没有为任何领域专门设计结构,使得Transformer能够应用在NLP也可以应用在CV,实现大一统;这是两个模型各自突出的贡献。
后面我会继续分享自己关于Swin Transformer的学习笔记。
学习笔记——Swin Transformer(ICCV 2021 best paper)-CSDN博客