一、如何在 mapPartitions 中释放资源
mapPartitions是一种对每个分区进行操作的转换操作,于常用的map操作类似,但它处理的是整个分区而不是单个元素。mapPartitions的应用场景适合处理需要在每个分区内批量处理数据的场景,通常用于优化性能和减少计算开销。例如:减少数据库连接、网络连接等。即然涉及到资源的初始化那么必定伴随着资源的释放,这是本节讨论的重点。
以和 mysql 中数据交互为例,下面是一段伪代码
rdd.mapPartitions(iter => {// 初始化数据库连接lazy val connection = initConnection(args)// 迭代数据val result = iter.map(... /*处理逻辑会使用到 connection 对象*/)// 在返回结果之前需要释放资源connection.close()// 返回处理结果result
})
上面的代码在运行阶段之前都是没有问题的(可编译、可打包),不存在语法问题。但是在运行时会报No operations allowed after connection closed,直接分析报错原因是在 map 中使用 connection 获取数据时该连接已经被关闭,直观的感觉是close方法在map之前被调用,真正的原因是什么呢?
众所周知 spark 在调用行动算子之前是不会执行上游算子中的逻辑,在观察 spark rdd 算子链之间传递的对象是 scala 的迭代器,而 scala 的迭代器具有lazy特性的不如 spark 的lazy特性被人“广为流传”
package fun.uhope.practiseobject P2 {def main(args: Array[String]): Unit = {List(1, 2, 3, 4, 5).toIterator.map(x => {println("map被调用了")x})}
}
上面的代码执行后没有任务输出,因为 scala 的迭代器也需要行动算子去触发计算。那么mapPartitions代码的报错原因显然是iter.map(...)只是返回了一个迭代器对象,内部逻辑并没有被执行,随后下一行代码关闭了数据库连接,当 rdd 在后续调用了行动算子其内部也会去触发这个迭代器对象执行对应的内部逻辑,此时数据库连接才会被使用但这个连接早就被关闭了。
对症下药!!!需要在数据库连接关闭之前执行完map逻辑
方案一:强制触发迭代器计算(不推荐)
将迭代器转换为 scala 的集合类型,代码如下
rdd.mapPartitions(iter => {// 初始化数据库连接lazy val connection = initConnection(args)// 迭代数据val result = iter.map(... /*处理逻辑会使用到 connection 对象*/).toList// 在返回结果之前需要释放资源connection.close()// 返回处理结果result.toIterator
})
toList会强制执行迭代器的逻辑,但后果是迭代器中映射的数据会被全部存储在内存中,如果分区的数据过大调用toList可能会发生 OOM。需要慎用
方案二:重写迭代器(推荐)
mapPartitions需要返回一个迭代器,如果这个迭代器可以实现在初始化的时候获取资源连接,在迭代完最后一个元素时释放资源即可。下面是自定义迭代器实现方式
rdd.mapPartitions(iter => {new Iterator[String]{// 初始化数据库连接lazy val connection = initConnection(args)// 判断迭代器是否还有元素override def hasNext: Boolean = {val hasNext = iter.hasNextif (!hasNext) {// 释放资源connection.close()}hasNext}// 获取迭代器元素override def next(): String = {val line = iter.next()... /*处理逻辑会使用到 connection 对象*/}}
})
该方法即保留了迭代器按需摄取数据的能力又实现了资源的及时释放
二、reduceByKey vs groupByKey
word count 入门案例如下
rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).foreach(println)
同时按照 sql 的实现逻辑还可以这么写
rdd.flatMap(_.split(" ")).map((_, 1)).groupByKey().mapValues(_.sum).foreach(println)
虽然groupByKey可以实现相同的结果,但效率较低,因为它会将所有相同key的值拉到一起,可能导致较大的网络传输开销和内存消耗。而reduceByKey默认实现了map端预聚合
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope {combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
}
三、 是全局有序吗
众所周知大数据场景下的全局排序是极其消耗资源的,hive 在执行 order by 时会将全部的数据 shuffle 到一个 reduce 节点上进行排序。spark 也提供了 rdd 的排序算子那么是全局有序还是分区有序?
sc.parallelize(Seq(1, 2, 3, 4, 5, 6, 7, 8, 9), numSlices = 3).sortBy(x => x).saveAsTextFile("data/sort result")
rdd的分区数是 3 排序后将结果写入本地文件(3 个)依次查看文件数据
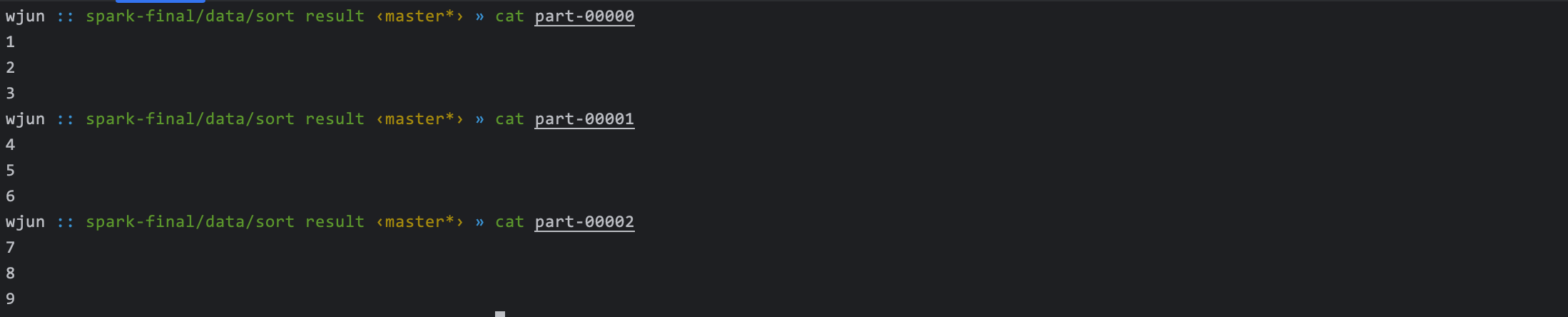
可以看出sortBy居然实现了全局有序,下面一探究竟 spark 是如何在大数据集下进行全局排序。
def sortBy[K](f: (T) => K,ascending: Boolean = true,numPartitions: Int = this.partitions.length)(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] = withScope {this.keyBy[K](f).sortByKey(ascending, numPartitions).values
}def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length): RDD[(K, V)] = self.withScope
{val part = new RangePartitioner(numPartitions, self, ascending)new ShuffledRDD[K, V, V](self, part).setKeyOrdering(if (ascending) ordering else ordering.reverse)
}
从调用链来看关键是使用了RangePartitioner分区器,是一种基于范围的分区器。通过随机采样的方式近似估计分区键的分布情况结合分区数(假定为 n)将 rdd 的数据分为 n 段,随后在每个分区中进行局部排序。因为是基于范围的分区,分区之间本身就具备顺序性当每个分区的局部排序完成之后全局排序便自动完成。
四、多种 rePartition
spark 中提供两种方法进行重分区coalesce、repartition。从调用链分析二者的关系
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {coalesce(numPartitions, shuffle = true)
}
理解coalesce的关键是 shuffle 选项,
从是否 shuffle 的角度分析
- 分区增加一定需要 shuffle,至少存在一个分区数据需要分发给多个分区
- 分区减少可以不需要 shuffle,将若干个分区全部分发给一个分区
从分区变化和是否 shuffle 角度分析
- 是否 shuffle 对分区减少没有必然联系
- 不 shuffle 且增加分区时无效
因此
package fun.uhope.transformimport fun.uhope.util.InitSparkContextobject RePartition {def main(args: Array[String]): Unit = {// 重分区val sc = InitSparkContext.withLocal()val sourceRDD = sc.parallelize(Nil)println(s"原始分区数 ${sourceRDD.partitions.length}")// coalesce 可以减少分区也可以增加分区// 减少分区时,可以不发生 shuffle// 增加分区时,shuffle 一定要设置为 true,否则分区数不发生变化val rdd1 = sourceRDD.coalesce(numPartitions = 4, shuffle = false)println(s"变成 4 分区 shuffle false ${rdd1.partitions.length}")val rdd2 = sourceRDD.coalesce(numPartitions = 16, shuffle = false)println(s"变成 16 分区 shuffle false ${rdd2.partitions.length}")val rdd3 = sourceRDD.coalesce(numPartitions = 16, shuffle = true)println(s"变成 16 分区 shuffle true ${rdd3.partitions.length}")// repartition 底层是 coalesce 且一定会发生 shuffleval rdd4 = sourceRDD.repartition(32)println(s"变成 32 分区的 repartition ${rdd4.partitions.length}")val rdd5 = sourceRDD.repartition(4)println(s"变成 32 分区的 repartition ${rdd5.partitions.length}")sc.stop()}
}
结论:coalesce相对repartition更加底层且灵活,但需要理解分区与shuflle的底层逻辑。repartition是coaleace的一种特殊情况,它总是执行shuffle
Tips: 在数据分布不均的情况下减少分区建议使用shuffle这样可以让最终分区的数据变的更加均衡虽然会带来一定的资源消耗
五、广播变量的多种实现方式
Spark 中的广播变量(Broadcast Variables)是一种优化技术,主要用于在集群中高效分发只读数据。通过广播变量,Spark 可以将数据在各个节点上缓存,从而避免在每个任务中重复发送相同的数据,减少网络传输开销和提高性能。通常的使用场景如下:
- 小型只读数据集的共享
- mapjoin
- 机器学习模型广播
- 重复数据缓存
只考虑技术实现通常有:类 scala 闭包变量引用、spark 广播变量、临时文件
类 scala 闭包变量应用
val config = new HashMap[String, String]()
rdd.map(x => config.getOrElse(x, 'Nil')).foreach(println)
从语法上这是 scala 的闭包实现,但 spark 作为分布式计算框架变量 config 的初始化在Driver端完成,但 map 算子的逻辑在Executor端进行。因此类闭包的实现 spark 会将 config 对象进行序列化后通过网络发送到每个Executor的 JVM 中,至于在Executor中会被反序列化几份需要结合广播的变量类型
- 如果是 object 对象,具备单例每个 JVM(Executor) 只有一份
- 如果是 class 对象,每个 task 一份
Tip: 因为需要序列化,因此被广播的变量一定可以被序列化(继承Serializable)。同时因为内置的序列化协议会附带很多其它无用信息在广播大变量时不建议使用
spark 广播变量
val map = new HashMap[String, String]()
val config = sc.broadcast(map)
rdd.map(x => config.value.getOrElse(x, 'Nil')).foreach(println)
对比类闭包的实现,spark 提供的广播变量有以下优点
- 每个
Executor保存一份 - 使用
BitTorrent协议数据分块分发机制,使得数据可以从多个节点分别获取,有效减少数据传输延迟和带宽消耗加速广播过程 - 可以使用
kryo序列化协议,相比 java 内置的序列化性能更高、序列化后的数据包更小
临时文件
在 MapReduce 编程框架中要实现广播(或mapjoin)通常是在 Job 中调用addCacheFile()将文件分发到集群的各个 Mapper 节点上,这个每个 Mapper都可以在本地文件中访问数据副本。Spark 同样支持
sc.addFile("hdfs://user/spark/jobxxx/config.txt")
之后的算子就可以像访问本地文件一样访问数据副本,但这种方式需要自己维护数据读取和解析在使用上的便捷性不如spark 提供的广播变量。这种方式不推荐使用

















![LeetCode[中等] 189.轮转数组](https://i-blog.csdnimg.cn/direct/1d7366d44f32498b9d9ad99fada01be9.png)
