1. 字符编码和字符集
1.1. 字符编码
编码:字符 –>字节
解码:字节 –>字符
字符编码Character Encoding : 就是一套自然语言的字符与二进制数之间的对应规则。
1.2. 字符集
字符集 Charset:是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
计算机要准确的存储和识别各种字符集符号,需要进行字符编码,一套字符集必然至少有一套字符编码。常见字符集有ASCII字符集、GBK字符集、Unicode字符集等。
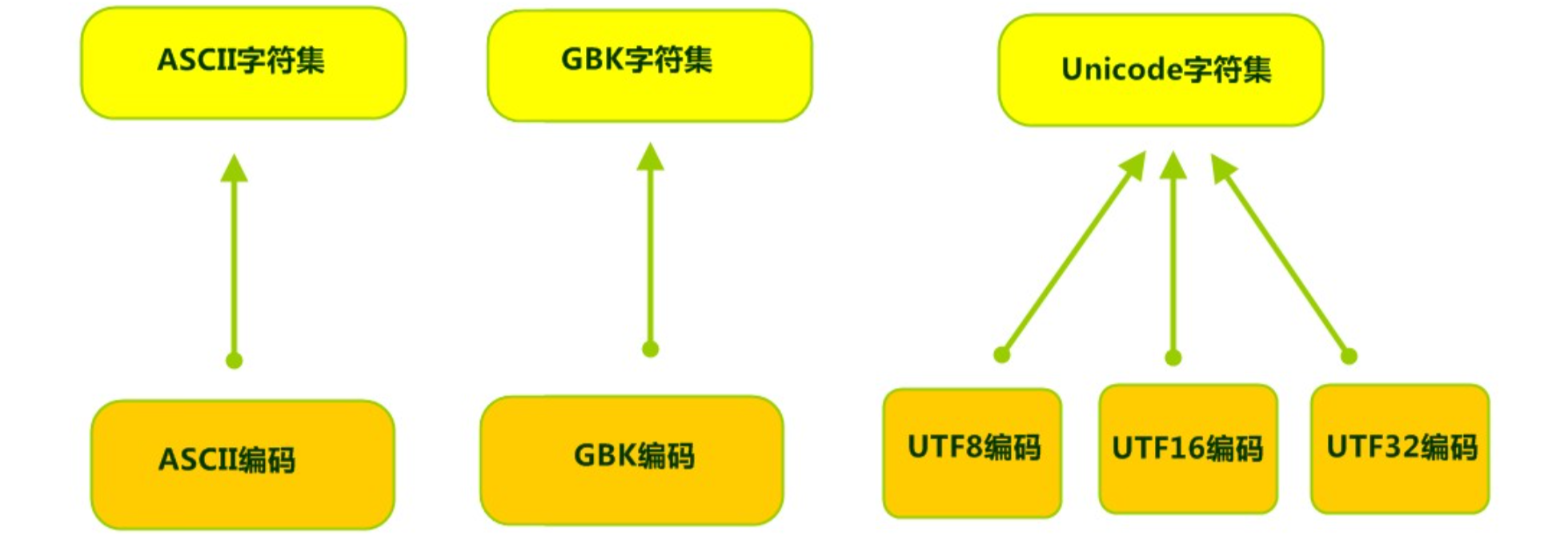
ASCII字符集 (1 字节) :
ASCII用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
基本的ASCII字符集,使用7位(bits)表示一个字符,共128字符。ASCII的扩展字符集使用8位(bits)表示一个字符,共256字符,方便支持欧洲常用字符。
GBxxx字符集 (2 字节) :
GB2312:简体中文码表。一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
GBK:最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。
GB18030:最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
Unicode字符集(1--4 字节) :
它最多使用4个字节的数字来表达每个字母、符号,或者文字。有三种编码方案,UTF-8、UTF-16和UTF-32。最为常用的UTF-8编码。
UTF-8编码:可以用来表示Unicode标准中任何字符,它是电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。它使用一至四个字节为每个字符编码,编码规则:
- 128个US-ASCII字符,只需一个字节编码。
- 拉丁文等字符,需要二个字节编码。
- 大部分常用字(含中文),使用三个字节编码。
- 其他极少使用的Unicode辅助字符,使用四字节编码。