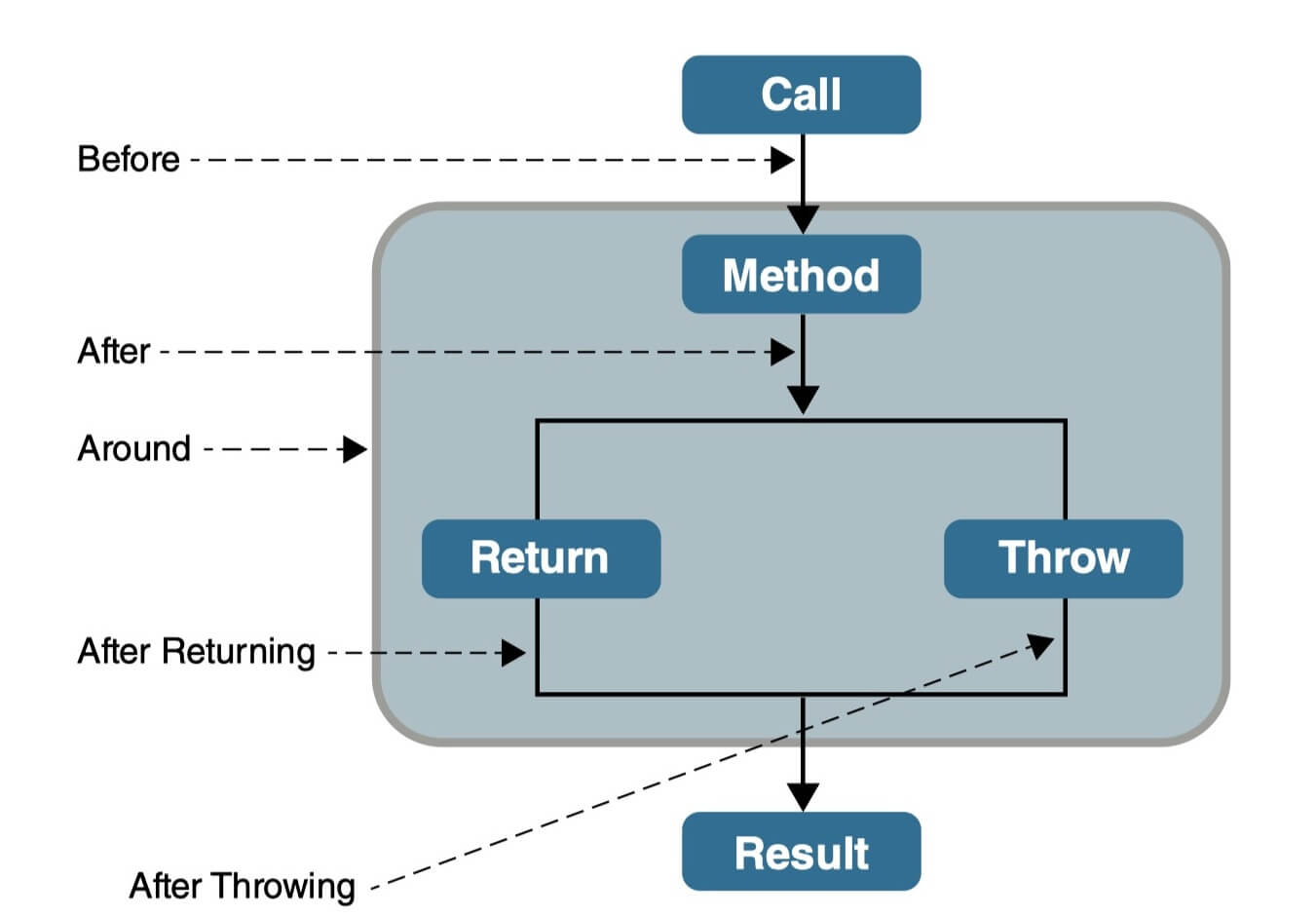
一、知识图谱概述
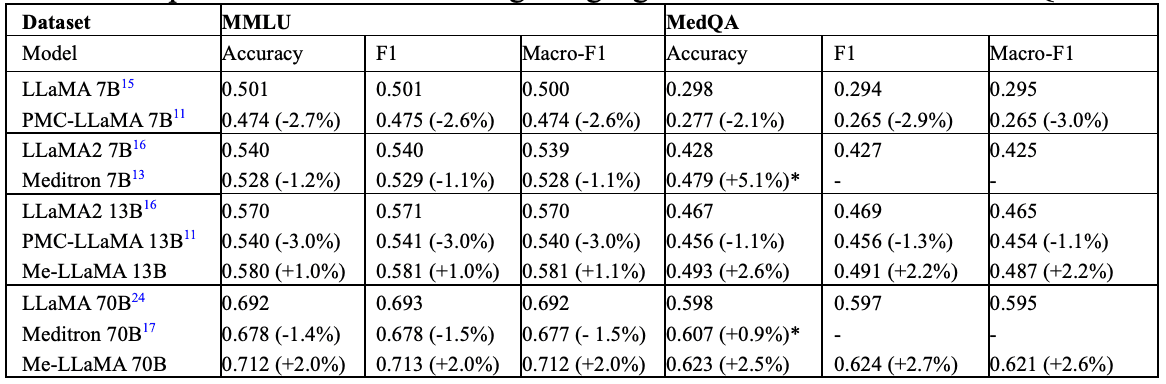
知识图谱(Knowledge Graph)是一种结构化的语义知识库,它以图形的方式组织和整合信息,使得数据之间的关系变得直观和易于理解。知识图谱的概念融合了计算机科学、数据科学、人工智能等多个领域的技术,旨在通过关联分析揭示数据背后的深层次关系。
本文所涉及所有资源均在传知代码平台可获取
1.1、概念
知识图谱由节点(实体)和边(关系)组成。节点代表实体,如人、地点、物品等;边代表实体之间的关系,如“属于”、“创造”、“位于”等。每个节点和边都可以带有属性,提供更详细的信息。
知识图谱的构建通常包括以下几个步骤:
数据抽取:从各种数据源中提取信息,如文本、数据库、网页等。
实体识别:识别出数据中的关键实体。 关系抽取:确定实体之间的关系。
实体链接:将识别出的实体与已知的知识库中的实体进行链接。
知识融合:整合来自不同源的知识,解决冲突和歧义。
存储与查询:将构建好的知识图谱存储在图数据库中,并提供查询接口。
1.2、历史
知识图谱的概念并非一开始就存在,它是随着信息技术和人工智能领域的发展逐渐形成的。以下是几个关键的历史节点:
1980年代:专家系统的发展,可以看作是知识图谱的早期形式。
1990年代:语义网(Semantic Web)概念的提出,旨在通过机器可理解的方式编码信息
2006年:DBpedia项目启动,将维基百科的结构化信息转换为机器可读格式。
2012年:谷歌推出知识图谱,用于增强搜索引擎的功能,提供更丰富的搜索结果。
1.3、作用
知识图谱在多个领域都有着广泛的应用,以下是其主要作用:
搜索引擎优化:通过知识图谱,搜索引擎能够提供更加精确和相关的搜索结果。
推荐系统:知识图谱可以用于个性化推荐,通过分析用户与物品之间的关系,提供更准确的推荐。
语义分析:在自然语言处理中,知识图谱有助于理解词语之间的关系,提高语义分析的准确性。
智能问答:知识图谱可以用于构建智能问答系统,快速准确地回答用户的问题。
决策支持:在商业分析和决策过程中,知识图谱能够帮助发现数据之间的深层次关系,支持更明智的决策。
医疗健康:知识图谱在医疗领域可用于药物研发、疾病诊断等,通过关联分析提高医疗质量
1.4、演示效果

二、图数据库
图数据库(Graph Database)是一种用于存储和管理图形结构数据的数据库。与传统的基于表格的数据库不同,图数据库专门为处理复杂的关系和网状结构的数据而设计。在图数据库中,数据结构的核心是节点(Node)、关系(Relationship)和属性(Property)
2.1、Neo4j
Neo4j是目前最常使用的图数据库管理系统。它是一个高性能的NoSQL数据库,具有以下特点:
原生图存储:Neo4j使用原生图存储,这意味着它直接在磁盘上存储节点和关系,而不是将图数据转换为其他模型。
Cypher查询语言:Neo4j使用Cypher作为查询语言,这是一种声明式查询语言,专门为图数据库设计,易于学习和使用。
高度可扩展:Neo4j支持大规模的数据集,并且可以通过集群部署来提高性能和可用性。
丰富的生态系统:Neo4j有一个活跃的社区和丰富的生态系统,提供了大量的工具和库来支持图数据库的开发和应用。
由于其强大的功能和易用性,Neo4j在众多行业和领域得到了广泛的应用,成为图数据库领域的佼佼者。
2.2、neo4j使用
输入以下代码启动neo4j
neo4j console

2.3、创建节点
create (郭靖:人物 {name:‘郭靖’,identity:‘武林高手’})

create表示新建
小括号内是节点信息,节点的标签label是人物,郭靖是其别名
花括号内是该节点的属性,共有name、identity两个属性
2.4、创建关系
match (黄蓉:`人物`{name:'黄蓉'}),(郭靖:`人物`{name:'郭靖'}) create (黄蓉) -[r:husband{name:'丈夫'}]->(郭靖)
match是匹配
(黄蓉:人物{name:‘黄蓉’})是第一个节点,(郭靖:人物{name:‘郭靖’})是第二个节点
husband是关系的标签,花括号内是该关系的属性,有name属性
2.5、删除所有节点和关系
MATCH (n)
OPTIONAL MATCH (n)-[r]-()
DELETE n,r

2.6、效果展示

三、知识问答项目构建
3.1、前端构建

3.2、大模型进行问题分类和命名实体识别
from zhipuai import ZhipuAI
import json
client = ZhipuAI(api_key="your_api_key")
def wenda(question):messages = [{"role":"system","content":"""我会给你一个句子,请你帮我分类成0-6,0表示询问某人的信息,1表示询问某人毕业于那所学校,2表示询问某人创作的作品,3表示询问某人的出生日期,4表示询问某人与某人的关系,5表示询问某人的配偶是谁,6表示询问作品是谁创作的。请按照我给你的提供的json模板,当问题类型属于0,1,2,3,5时,nr字段填入名字,不要work字段.当问题类型为6时,work字段填入作品名称,不要nr字段。{"类型":0-6,"nr":名字,"work":作品名称}当类型为4时,使用以下模板:{"类型":4,"nr":['名字1','名字2'],}只需要返回一个json对象,不要重复问题"""},{"role": "user","content": f"{question}"}]response = client.chat.completions.create(model="glm-4-flash",messages=messages,)return json.loads(response.choices[0].message.content)
3.3、python操作neo4j数据库
安装项目相应的依赖包
pip install -r requirements.txt
连接数据库
from py2neo import Graph# 替换下面的 uri, user 和 password 为你的 Neo4j 数据库的连接信息
uri = "bolt://localhost:7687" # Neo4j Bolt 连接地址
user = "neo4j" # Neo4j 用户名
password = "your_password" # Neo4j 密码graph = Graph(uri, auth=(user, password))
增加数据
# 创建节点
tx = graph.begin()
a = Node("Person", name="Alice")
b = Node("Person", name="Bob")
tx.create(a)
tx.create(b)
tx.commit()# 创建关系
ab = Relationship(a, "KNOWS", b)
tx = graph.begin()
tx.create(ab)
tx.commit()
查找
alice = graph.nodes.match("Person", name="Alice").first()
print(alice)
relationship = graph.relationships.match(nodes=[alice, b], r_type="KNOWS").first()
print(relationship)
3.4、后端构建
本项目采用Flask框架实现,使用了例如render_template进行页面渲染,return返回前端所需要的信息等。
四、附件项目使用
0.启动neo4j数据库
neo4j console
1.向neo4j数据库添加数据
python ./handler/handler_person_data.py
2.添加自己的api_key

3.启动项目
python app.py
本文所涉及所有资源均在传知代码平台可获取