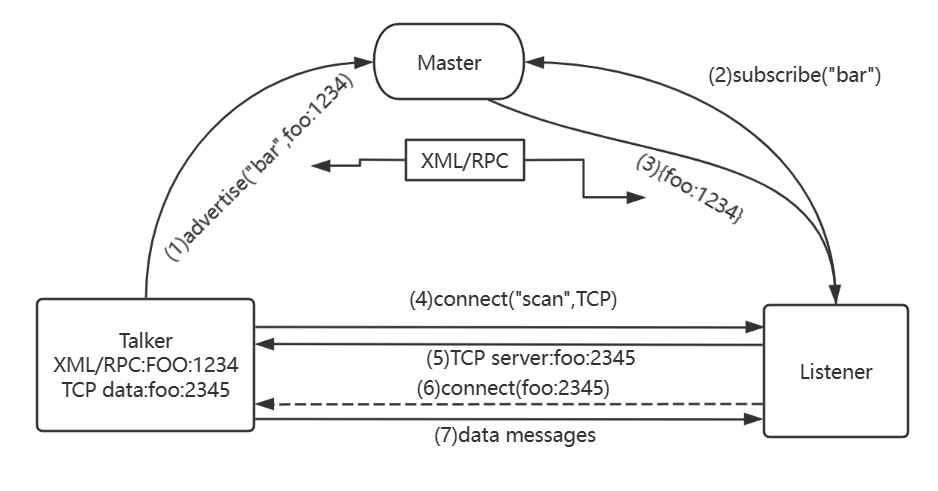
一、Zookeeper概述
- 定义:Zookeeper是一个分布式的、开源的分布式应用程序协调服务。它主要用于管理和协调分布式系统中的各种服务,提供诸如配置管理、命名服务、分布式锁等功能。
- 应用场景举例:在Hadoop生态系统中,用于协调HDFS NameNode和DataNode,以及YARN的ResourceManager和NodeManager之间的工作。
二、数据模型
- 层次结构:Zookeeper的数据模型类似一个文件系统的树形结构,树中的每个节点被称为Znode。
- Znode特性
- 可以存储数据,但是数据量不能太大(一般不超过1MB)。
- 有持久(persistent)节点和临时(ephemeral)节点之分。持久节点在创建后,除非被显式删除,否则一直存在;临时节点与创建它的会话(session)绑定,会话结束时,临时节点自动删除。
三、基本操作
- 创建节点:使用 create 命令,例如 create /myznode "data" 可以创建一个名为 /myznode 的持久节点,并存储 data 数据。
- 读取节点数据:通过 get 命令,如 get /myznode ,可以获取 /myznode 节点存储的数据以及节点的一些元数据(如版本号等)。
- 更新节点数据: set 命令用于更新节点数据,像 set /myznode "new data" 就能更新 /myznode 节点的数据。
- 删除节点: delete 命令用于删除节点,不过只能删除没有子节点的节点;若要删除有子节点的节点,需要使用 deleteall 命令。
四、Zookeeper工作原理
- 角色
- Leader:负责进行投票的发起和决议,处理事务请求(写操作)。
- Follower:接收客户端的请求,将写请求转发给Leader,参与Leader选举投票,处理读请求。
- 集群工作模式:基于ZAB(Zookeeper Atomic Broadcast)协议来保证数据一致性。当客户端发送一个写请求时,Follower会将请求转发给Leader,Leader会广播这个事务给所有Follower,当大多数Follower(半数以上)都完成这个事务后,该事务才算提交成功。
五、安装与配置
- 单机安装:从官网下载Zookeeper的压缩包,解压后进入 conf 目录,复制 zoo_sample.cfg 为 zoo.cfg ,修改配置文件(如数据存储目录 dataDir ),然后在bin目录下运行 zkServer.sh start (对于Linux系统)来启动Zookeeper服务。
- 集群安装:需要在多个节点上进行安装,在每个节点的 zoo.cfg 配置文件中,除了配置基本参数外,还需要配置集群中其他节点的信息( server.x=ip:port:port ,其中 x 是服务器编号, ip 是服务器IP地址, port 相关信息用于选举和通信)。
六、客户端使用
- 原生客户端:Zookeeper提供了原生的Java客户端供开发者使用。通过创建 ZooKeeper 实例,传入连接参数(如服务器地址、会话超时时间等)来建立与Zookeeper服务的连接。之后就可以进行节点的创建、读取、更新、删除等操作,操作完成后要记得关闭连接以释放资源。
- 第三方客户端:除了原生客户端,还有一些流行的第三方客户端,比如Curator。它对Zookeeper的原生API进行了封装,提供了更简洁易用的接口,能更方便地实现诸如分布式锁、领导者选举等复杂功能,并且在处理连接管理、重试机制等方面有更好的表现,大大简化了开发流程。
七、监控与维护
- 监控指标
- 节点状态:关注节点是持久节点还是临时节点,以及节点的数据变化情况。
- 连接数:了解当前有多少客户端与Zookeeper服务建立了连接,过多的连接可能影响性能。
- 请求处理情况:统计读写请求的处理数量、处理时长等,以便及时发现处理缓慢等异常情况。
- 日志查看:Zookeeper会生成详细的日志文件,通过查看日志可以了解服务运行过程中的各种事件,比如节点创建、删除的记录,选举过程等。定期查看日志有助于提前发现潜在问题并及时解决。
- 数据备份与恢复
- 备份:定期对Zookeeper的数据目录进行备份,可以采用脚本定时将数据目录复制到其他存储位置的方式。备份频率可根据业务需求和数据变更频率来确定。
- 恢复:在出现数据丢失或损坏等情况时,若有备份,可以停止Zookeeper服务,将备份数据还原到数据目录,然后重新启动服务来恢复数据。但要注意恢复过程可能会影响到正在运行的相关应用程序,需谨慎操作。
八、常见问题及解决
- 连接问题:如果客户端无法连接到Zookeeper服务,首先检查网络是否畅通,然后确认服务器地址、端口等连接参数是否正确配置。也有可能是Zookeeper服务本身未正常启动,可查看服务启动日志排查故障。
- 节点数据不一致:当出现节点数据在不同客户端看到不一致的情况时,很可能是由于数据同步尚未完成。可等待一段时间让Zookeeper基于ZAB协议完成数据同步,或者检查集群中各节点的运行状态是否正常,是否存在故障节点影响了数据同步。
- 选举异常:在Leader选举过程中,如果出现异常,比如长时间无法选出Leader,可能是因为集群节点配置错误(如服务器编号重复等),或者网络不稳定导致节点间通信不畅。需要仔细检查集群配置文件和网络状况来解决问题。
九、与其他技术的集成
- 与Hadoop集成:在Hadoop生态系统中,Zookeeper起着至关重要的作用。例如,在HDFS中,它协助维护NameNode的高可用性。当主NameNode出现故障时,通过Zookeeper的协调机制,备用NameNode能够快速接管服务,保障文件系统的正常运行。同时,在YARN中,Zookeeper也用于协调ResourceManager和NodeManager之间的关系,确保资源分配和任务调度的顺畅进行。
- 与Kafka集成:Kafka利用Zookeeper来管理集群的元数据,比如记录Broker的信息、主题(Topic)的配置以及消费者组(Consumer Group)的偏移量等。通过Zookeeper的分布式协调能力,Kafka能够实现高效的消息发布与订阅,并且在集群扩展、故障恢复等方面表现得更加稳定和可靠。
- 与Dubbo集成:在Dubbo微服务架构中,Zookeeper常被用作注册中心。服务提供者在启动时会将自身的服务信息(如服务接口、IP地址、端口等)注册到Zookeeper上,而服务消费者则从Zookeeper中获取服务提供者的信息来建立连接并调用服务。这样一来,Dubbo借助Zookeeper实现了服务的自动发现和治理,提高了微服务架构的灵活性和可维护性。
十、性能优化
- 硬件层面:
- 足够的内存:确保服务器有足够的内存来运行Zookeeper。内存不足可能导致频繁的磁盘I/O,影响性能。一般建议根据集群规模和数据量大小,为每个节点配备合适的内存容量,比如对于中等规模的集群,每个节点可配备8GB - 16GB内存。
- 快速的磁盘:使用高速的磁盘,如SSD,能显著提升Zookeeper的读写性能。因为Zookeeper在处理事务时会有频繁的日志写入操作,快速磁盘可以减少写入等待时间,加快数据处理速度。
- 配置层面:
- 调整会话超时时间:合理设置会话超时时间(sessionTimeout)参数。如果设置得太短,可能会导致客户端频繁重新连接,增加网络开销;而设置得太长,则可能在客户端实际故障后,较长时间内占用服务器资源。一般可根据网络状况和客户端的稳定性需求,设置在10 - 30秒之间。
- 优化ZAB协议相关参数:比如调整选举超时时间(electionTimeout)等与ZAB协议相关的参数。通过合理设置这些参数,可以使Leader选举过程更加高效,减少因选举而导致的服务暂停时间。
- 应用层面:
- 减少不必要的读写操作:在应用程序设计时,尽量避免频繁地对Zookeeper节点进行读写操作。可以通过缓存等方式,在本地保存一些常用的数据,减少对Zookeeper的直接访问,从而提高整体性能。
- 优化节点结构:合理规划Zookeeper的节点结构,避免创建过多过深的节点层次。因为每次对节点的操作都可能涉及到对树形结构的遍历,复杂的节点结构会增加操作的复杂度和时间成本。
十一、安全相关
- 认证机制:
- Zookeeper支持多种认证方式,如简单的用户名密码认证(Digest认证)。通过在配置文件中设置相关参数,可以要求客户端在连接时提供正确的用户名和密码组合,以确保只有授权的客户端能够访问Zookeeper服务。例如,在 zoo.cfg 配置文件中添加类似如下语句来启用Digest认证并设置用户信息:
authProvider.1=org.apache.zookeeper.server.auth.DigestAuthenticationProvider
requireClientAuthScheme=digest
jaasLoginRenew=3600000
- 同时,在客户端连接时,需要使用相应的API来提供认证信息,比如在Java客户端中通过 ZooKeeper 对象的构造函数传入包含用户名和密码的 ZooKeeper.DigestLoginCredentials 实例。
- 权限控制:
- Zookeeper采用类似ACL(访问控制列表)的机制来控制对节点的访问权限。可以为每个节点单独设置不同的访问权限,权限类型包括读(READ)、写(WRITE)、创建(CREATE)、删除(DELETE)等。
- 通过 setAcl 命令可以设置节点的ACL,例如 setAcl /myznode world:anyone:cdrwa 表示赋予所有用户对 /myznode 节点的创建、删除、读、写、管理(admin)等全部权限;而 setAcl /myznode digest:user:password:cdrwa 则是针对特定用户(通过用户名和密码认证的用户)赋予相应权限。
- 网络安全:
- 确保Zookeeper服务运行在安全的网络环境中。如果是在云环境或者企业内部网络等场景下,可利用网络防火墙等设施来限制对Zookeeper服务端口的访问,只允许授权的IP地址段能够连接到Zookeeper服务器,防止外部恶意攻击。
- 对于跨网络区域的Zookeeper集群,可考虑采用VPN(虚拟专用网络)等技术来保障网络连接的安全性和稳定性,避免数据在传输过程中被窃取或篡改。
十二、发展趋势
- 与容器化技术融合:随着容器化技术如Docker和Kubernetes的广泛应用,Zookeeper也在不断适配与融合。在容器编排环境中,Zookeeper可以更好地协调容器化应用的各个组件,比如在Kubernetes集群中,协助管理微服务之间的关系、进行配置管理等,并且能够利用容器化平台的资源管理优势,提高自身的运行效率和稳定性。
- 性能提升与优化持续进行:研发人员不断致力于Zookeeper的性能提升,从改进内部算法到优化数据结构,再到调整各种参数的合理设置,目标是让Zookeeper在处理大规模分布式系统的协调任务时能够更加高效、快速地完成,减少延迟和资源消耗。
- 增强的安全特性:面对日益复杂的网络安全环境,Zookeeper未来有望进一步强化其安全特性,比如完善认证和权限控制机制,增加对新兴安全技术的应用,如加密传输协议的进一步采用等,以确保分布式系统在使用Zookeeper进行协调时的安全性。