项目源码获取方式见文章末尾! 600多个深度学习项目资料,快来加入社群一起学习吧。
《------往期经典推荐------》
项目名称
1.【DDRNet模型创新实现人像分割】
2.【卫星图像道路检测DeepLabV3Plus模型】
3.【GAN模型实现二次元头像生成】
4.【CNN模型实现mnist手写数字识别】
5.【fasterRCNN模型实现飞机类目标检测】
6.【CNN-LSTM住宅用电量预测】
7.【VGG16模型实现新冠肺炎图片多分类】
8.【AlexNet模型实现鸟类识别】
9.【DIN模型实现推荐算法】
10.【FiBiNET模型实现推荐算法】
11.【钢板表面缺陷检测基于HRNET模型】
…
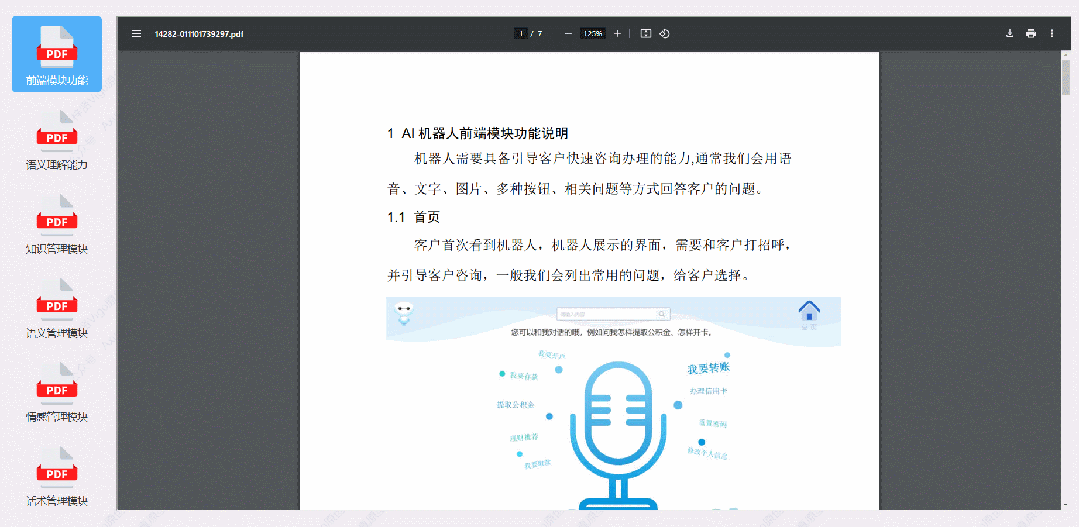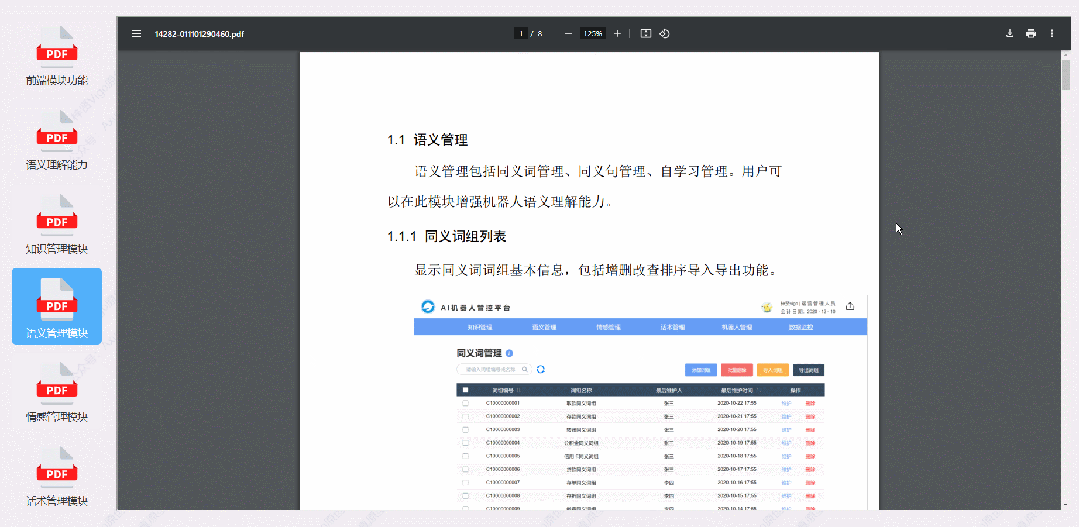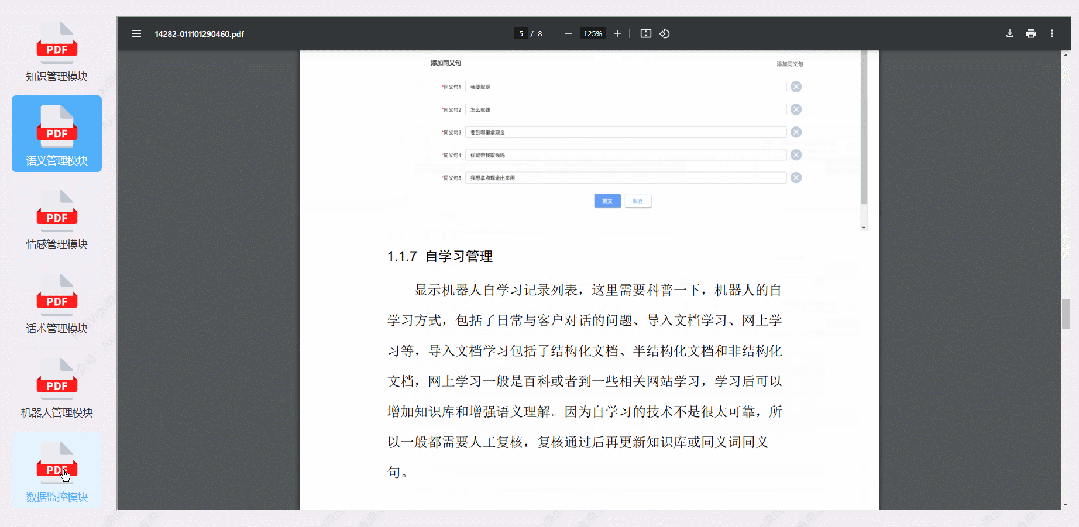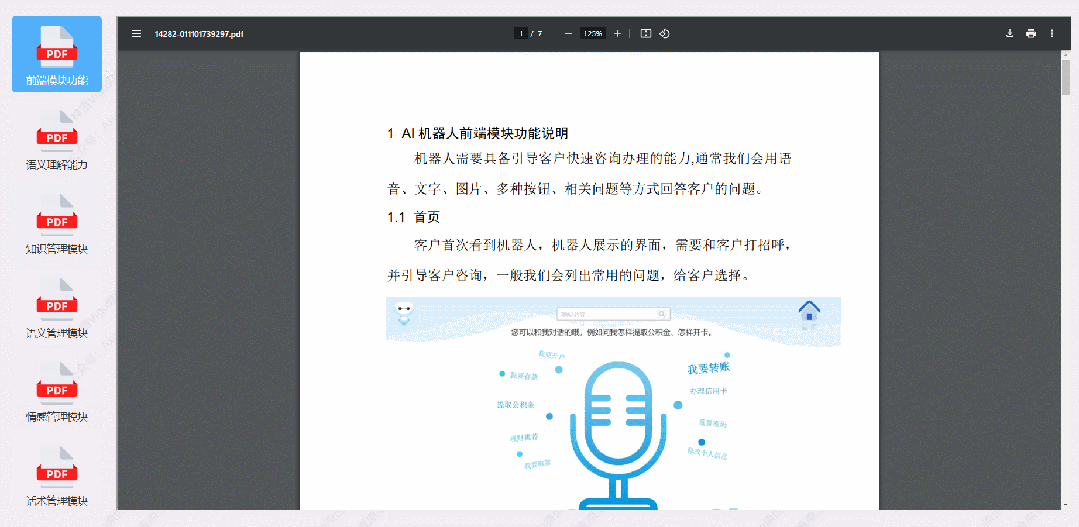
1. 项目简介
项目核心是基于PaddleNLP框架的问答系统(FAQ系统),专为政务及其他服务性领域的常见问题解答(如政策、保险、法律等)提供解决方案。该系统的目标是通过深度学习模型和高效的语义索引方法,为政府及相关行业简化答疑流程,提升工作效率。系统利用了PaddleNLP中的RocketQA DualEncoder模型,以便在无标注数据下实现高效的检索式问答。模型在推理和服务性能上进行了优化,结合Paddle Inference和Milvus库,实现高性能的向量检索和查询。同时,Paddle Serving的集成保证了模型在实际应用中的响应速度。此类FAQ系统适用于智慧城市、保险行业、电信服务、法律咨询和金融服务等领域,为这些领域提供自动化问答和信息查询支持。

2.技术创新点摘要
在ann_util.py中,项目采用了hnswlib库构建高效的近似最近邻(ANN)索引,其主要创新点在于结合了高维语义向量的索引构建和快速查询优化。该文件提供了一个build_index函数,该函数结合了以下特点:
- 高维空间内的内积距离计算:使用了
hnswlib.Index(space='ip', dim=output_emb_size)来构建基于内积的向量相似性度量,这对于基于深度学习生成的语义向量查询来说,更符合FAQ系统的需求。 - 动态平衡查询速度与内存消耗:通过
hnsw_ef和hnsw_m参数,控制了索引在构建过程中的查询速度与准确率之间的权衡,同时优化了模型的内存占用和效率。
在data.py中,数据处理模块实现了一个较为创新的问答配对匹配方式。主要内容包括:
- 相似文本对的精准标注:通过从给定的文本对文件(
similar_text_pair)中读取匹配的问答对,然后对召回结果进行逐条验证。模型将相似度高的文本对与真实相似对进行对比,用于生成相关性标签,从而有效识别和标记用户查询与知识库答案之间的语义相似性。 - 逐步筛选与优化召回结果:该文件对召回结果进行了逐步的多次筛选,并通过对比用户输入和召回文本的相似性得分,来优化问答系统的精度。
此实现有助于提高问答系统对语义相似度的识别效果,从而提升了用户查询和答案的匹配度。接下来将继续分析evaluate.py,以查找更多技术创新点。
在evaluate.py中,项目实现了一个创新的召回率评估方法,主要集中在以下方面:
- 精确的Top-N召回评估:
recall函数计算了模型在Top-N检索结果中的召回率,用于评估FAQ系统在实际应用场景中的召回表现。这种评估方式通过计算前N个返回结果中相关答案的比例,从而衡量模型在高频查询中的性能,确保系统在用户检索时能够返回更多有效的匹配结果。 - 高效的批量处理机制:通过对结果进行逐批次的处理,
evaluate.py优化了评估的计算效率,便于在较大规模的测试集上快速评估模型的实际召回效果。
综上分析,项目的创新点主要体现在:结合hnswlib的高效近似最近邻索引、基于相似文本对的动态召回匹配,以及多维度的Top-N召回率评估方法。这些技术创新显著提升了FAQ系统的效率和准确性,使其在处理大量查询时更具鲁棒性。
3. 数据集与预处理
该项目的数据集主要用于FAQ问答系统的训练和测试,包含了各类真实场景中的问答对,例如政务服务咨询、政策解读、保险业务及金融服务等领域的问题。这些问答对通常包括用户常见问题和标准答案,具备丰富的领域特性和多样化的语言表达,为模型的泛化和语义理解提供了有效支持。
数据预处理流程
- 数据清洗与归一化:首先对原始文本数据进行清洗,去除特殊字符、空格及冗余内容,确保文本的规范性。然后进行归一化处理,将文本中的不同格式(如大写字母、小写字母、数字等)统一为标准形式,以提升语义匹配的准确性。
- 分词与向量化:项目采用深度学习中的分词和向量化技术,将文本转化为模型可处理的数值格式。在分词过程中,使用PaddleNLP的预训练模型对文本进行词嵌入编码,将每个词语转化为高维空间的向量表示。这一处理方式有助于模型理解词语的上下文关系,进而提升FAQ系统的语义匹配能力。
- 数据增强:针对数据量不足或领域偏差的问题,项目应用了数据增强策略。常见的增强方法包括同义词替换、问句重构等,以生成更多不同表达方式的问答对。这种增强方式有助于模型在不同表述方式下更准确地识别相似语义。
- 特征工程:在向量化文本的基础上,项目进一步优化特征,通过选择语义相似度较高的特征对进行标注和筛选,确保在问答匹配时仅关注核心信息,从而提升模型召回和匹配的效果。
4. 模型架构
- 模型结构的逻辑
本项目构建的FAQ问答系统基于PaddleNLP的RocketQA DualEncoder架构。该模型结构主要包括以下几个关键组件:
- 双编码器(DualEncoder)架构:系统使用两个独立的编码器分别对用户问题和候选答案进行编码。每个编码器生成高维语义向量,将输入问题和答案映射到相似的向量空间中,以便能够通过计算向量间的相似度来进行问题匹配。
- 语义向量检索:通过高效的ANN(Approximate Nearest Neighbor)索引和
hnswlib库,模型能够将每个查询的问题向量与答案库的向量进行快速匹配,从而实现高效的问答对召回。 - 嵌入优化:模型采用了Paddle Inference进行语义向量的高效生成,通过无监督微调实现了在无标注数据的情况下对语义匹配的优化,以增强模型对文本相似度的理解。
- 模型的整体训练流程和评估指标
训练流程
- 数据加载与预处理:项目加载问答对数据集,并通过预处理步骤对数据进行分词和向量化处理,生成输入模型的语义向量。
- 无监督微调:模型使用无监督学习策略,将问题和答案对送入DualEncoder模型进行嵌入训练,基于无标签数据优化模型的语义表示能力。通过调整学习率衰减(如LinearDecayWithWarmup)提升训练的效果。
- 语义索引构建:在完成训练后,使用ANN索引库
hnswlib对生成的语义向量进行索引构建。该索引用于实际应用中的快速语义检索,保证查询速度和准确率的平衡。
评估指标
- 召回率(Recall@N) :评估模型的主要指标是Top-N召回率,即在N个返回结果中召回正确答案的比例。通过计算Top-N召回率,可以有效评估模型在实际应用中的有效性,尤其是评估其对高频查询的响应性能。
- 语义相似度:在模型内部,通过计算问题与答案的语义相似度得分来判断匹配效果。项目通过此评估在不同表述情况下模型对相似语义的捕捉能力。
5. 核心代码详细讲解
ann_util.py中的build_index函数为项目构建了高效的近似最近邻(ANN)索引。下面是该函数的核心代码和详细解释:
build_index 函数
暂时无法在飞书文档外展示此内容
output_emb_size:指定模型生成的嵌入向量的维度。hnsw_max_elements:HNSW索引的最大元素数,即可以处理的数据容量。hnsw_ef和hnsw_m:分别用于设置HNSW索引构建过程中的查准率与查询速度的平衡参数。
暂时无法在飞书文档外展示此内容
hnswlib.Index(space='ip', dim=output_emb_size):初始化了一个基于hnswlib库的近似最近邻索引,space='ip'表示在向量空间中使用内积(inner product)来计算相似度,这种方法对问答匹配中的语义相似性非常有效。
暂时无法在飞书文档外展示此内容
index.init_index():设置索引的最大容量、查准率和内存消耗的平衡参数(M),并初始化索引。index.set_ef(hnsw_ef):在查询时设置查准率,较高的值提升准确率但会增加查询时间。index.set_num_threads(16):为索引设置了并行处理线程数,这里使用16线程以提高构建和查询速度。
暂时无法在飞书文档外展示此内容
all_embeddings:累积所有文本的嵌入向量。for text_embeddings in model.get_semantic_embedding(data_loader):利用模型的get_semantic_embedding方法将数据加载器中的文本转换为嵌入向量。index.add_items(all_embeddings):将所有嵌入向量添加到索引中,使得查询时可以快速检索到与问题语义最相似的答案。
暂时无法在飞书文档外展示此内容
index.get_current_count():用于获取索引中的当前条目数,确认索引已成功构建完成。return index:返回构建的索引对象,供后续检索时使用。
get_rs 函数
暂时无法在飞书文档外展示此内容
similar_text_pair:包含文本及其相似文本的文件路径。text2similar:用于存储文本和对应相似文本的字典。for line in f:逐行读取文件中的问答对,将每对问答映射存储到字典中,供后续检索和标注使用。
暂时无法在飞书文档外展示此内容
recall_result_file:召回结果文件路径,用于记录模型在不同阈值下的召回结果。for index, line in enumerate(f):迭代召回结果文件中的每一行记录。if index % recall_num == 0:按指定数量分段保存每次召回的结果,便于后续分批次计算准确率。if text == recalled_text:跳过相同文本,避免自我匹配。if text2similar[text] == recalled_text:检查召回文本是否匹配正确的答案,将匹配成功的对标记为1,其他情况标记为0。return rs:返回分段的召回结果列表,用于进一步的模型评估。
在evaluate.py中,项目实现了用于评估模型召回率的函数,以下是核心代码及其逐行解析:
recall 函数
暂时无法在飞书文档外展示此内容
recall(rs, N=10):计算模型在Top-N召回结果中的准确率。rs:传入的分段召回结果列表,其中每个子列表包含召回的相关性标签。[np.sum(r[0:N]) for r in rs]:对于每个召回段,统计前N个返回结果中的正确匹配数量。np.mean(recall_flags):返回召回率的平均值,反映在Top-N检索结果中的总体准确性。
该函数通过计算Top-N召回率,有效评估了模型在处理实际查询时的准确性和实用性。
1. 数据加载 (read_simcse_text 函数)
暂时无法在飞书文档外展示此内容
data_path:数据文件路径。read_simcse_text:用于加载和读取问答数据,将每条记录处理成字典格式。with open(data_path, 'r', encoding='utf-8') as f:逐行读取文件,确保加载数据的高效性。yield {'text_a': data, 'text_b': data}:返回每条问答数据的文本对,便于后续模型的训练和检索处理。
2. 数据集加载与显示
暂时无法在飞书文档外展示此内容
train_set_file:定义训练集文件路径。train_ds = load_dataset(...):使用load_dataset方法加载训练集,并应用read_simcse_text进行数据处理。for i in range(3): print(train_ds[i]):输出训练集中前三条数据,以便快速检查数据加载和预处理的正确性。
在main.ipynb中,模型构建和训练过程的关键代码如下:
1. 样本转换与Tokenization (convert_example函数)
暂时无法在飞书文档外展示此内容
convert_example:该函数将每个示例转化为模型所需的ID格式。for key, text in example.items():遍历每个输入样本,将文本转换为词嵌入ID。encoded_inputs = tokenizer(...):使用PaddleNLP的tokenizer将文本编码为词嵌入ID和分词类型ID。result += [input_ids, token_type_ids]:将编码的ID添加到结果列表中,以便形成模型输入。
2. Dataloader 构建
暂时无法在飞书文档外展示此内容
tokenizer:加载PaddleNLP提供的预训练分词器。trans_func:使用partial函数将convert_example包装为特定的转换函数,用于批处理数据的转换。batchify_fn:将多个样本转换为批处理格式,使用Pad对ID进行填充,以确保批数据维度一致。
6. 模型优缺点评价
优点
- 高效的双编码器架构:模型采用DualEncoder结构,分别对问题和答案进行编码,通过向量空间的相似度计算实现高效匹配,尤其适合大规模问答对的检索任务。
- 快速检索与高准确率:通过
hnswlib近似最近邻(ANN)索引,大幅提升查询速度,使得模型在实际应用中能快速响应用户查询,同时保证较高的匹配准确性。 - 无监督微调的灵活性:模型利用无标签数据的无监督微调,适应无标注数据的场景,使得模型具有更广泛的可迁移性和鲁棒性。
缺点
- 依赖语义向量相似度的局限性:模型的检索完全基于语义向量,可能对复杂句式或含有多义词的查询结果不够精确,容易导致错误匹配。
- 数据处理复杂度:需要预先构建语义索引,这对大规模数据的内存和计算资源要求较高,同时索引构建也需较长时间。
- 领域适应性限制:RocketQA模型在特定领域可能表现较优,但对于某些垂直领域如医疗或法律等专有词汇较多的领域,可能需要额外的微调。
改进方向
- 模型结构优化:可以引入Cross-Encoder模型,将查询与候选答案联合编码,以提升复杂语义关系的理解力。
- 超参数调整:优化hnsw索引参数(如
ef和M值)以进一步平衡精度和速度;在模型训练中可尝试不同的学习率策略。 - 多样化的数据增强:引入数据增广方法,如同义词替换、随机删除等,以增加模型的泛化能力,使其更能适应用户多样化的表达方式。
全部项目数据集、代码、教程点击下方名片