- 论文:https://arxiv.org/pdf/2410.21252
- 代码:https://github.com/THUDM/LongReward
- 机构:清华大学 & 中科院 & 智谱
- 领域:长上下文LLM
- 发表:arxiv

研究背景
- 研究问题:这篇文章要解决的问题是如何在长上下文场景下,利用AI反馈来提高大型语言模型(LLMs)的性能。具体来说,现有的长上下文LLMs在监督微调(SFT)过程中合成的数据质量较差,影响了模型的长上下文性能。
- 研究难点:该问题的研究难点包括:如何在长上下文中获取可靠的奖励信号,以及如何将长上下文RL算法与SFT结合以提高模型性能。
- 相关工作:该问题的研究相关工作有:设计高效的注意力机制或结构化状态空间模型来扩展上下文窗口,使用自动合成的SFT数据进行模型训练,以及利用AI反馈来优化模型的无害性和真实性。
研究方法

这篇论文提出了LongReward方法,用于解决长上下文LLMs的奖励信号获取问题。具体来说,
-
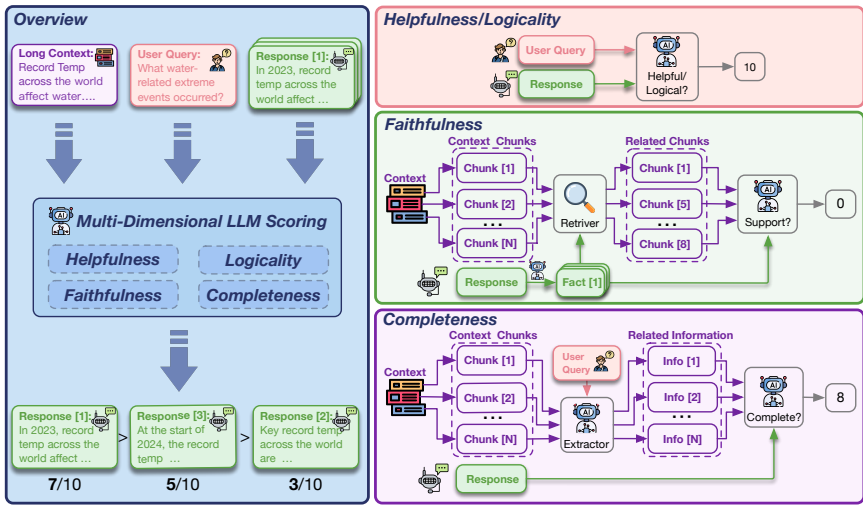
多维度评分:LongReward利用一个现成的大型语言模型(LLM)从四个人类价值维度对长上下文模型响应进行评分:有用性、逻辑性、忠实性和完整性。每个维度的评分范围为0到10,最终奖励为这四个评分的平均值。
-
有用性评分:对于有用性,LLM根据查询和响应内容直接评分。引入Chain-of-Thought(CoT),要求LLM在提供最终评分前生成分析,以增强评分的可靠性和互操作性。
-
逻辑性评分:对于逻辑性,LLM检测响应中的逻辑错误,这些错误通常由于LLMs的生成方式导致。同样采用CoT来增强评分的可靠性。
-
忠实性评分:对于忠实性,LLM将响应分解为一组事实陈述,并判断每个陈述是否由检索到的上下文支持。为了适应长上下文场景,改进了事实分解和评估方法。
-
完整性评分:对于完整性,LLM从上下文的每个片段中提取与问题相关的信息,然后再次评估响应的完整性。采用分而治之的策略来提高评估效率。
-
结合DPO算法:将LongReward与离线RL算法DPO结合,构建长上下文偏好数据集,并使用DPO算法对SFT模型进行微调,以增强其长上下文能力。
实验设计
- 数据收集:使用GLM-4的预训练语料库构建了长上下文SFT数据集,共包含10,000篇文档,覆盖9个不同领域。文档长度从8,000到64,000个令牌不等。
- 模型选择:实验在两个最新的开源基础模型上进行:Llama-3.1-8B和GLM-4-9B,这两个模型都经过大规模长文本的持续预训练,并支持128k的上下文窗口。
- SFT训练:使用Megatron-LM库在4个节点上使用8×H800 GPUs进行SFT训练,学习率为1e-5,批量大小为8,训练1,800步(约2个epoch)。
- DPO实验:使用LongReward构建长上下文偏好数据集,采样10个候选响应,并使用Zhipu-Embedding-2*作为检索器评估忠实性。DPO训练中设置β和λ分别为0.15和0.1,学习率为1e-6,批量大小为16,训练400到800步。
结果与分析
- 自动评估结果:在LongBench-Chat和LongBench基准测试中,使用LongReward的DPO模型在长上下文任务上的表现显著优于SFT模型和其他基线方法。具体来说,Llama-3.1-8B和GLM-4-9B的DPO模型分别提高了4.9%和5.5%的长上下文任务性能。


- 忠实性评估:使用FactScore对随机抽样的260个问题进行评估,结果显示使用LongReward的DPO模型在忠实性方面得分更高,事实支持的准确率更高,减少了幻觉现象。

- 人类评估结果:在LongBench-Chat上进行的人类评估显示,使用LongReward的DPO模型在有用性、逻辑性、忠实性和完整性四个维度上的胜率分别为54%、54%、64%和54%,显著优于SFT基线。
- 短上下文任务:在MT-Bench和AlpacaEval2基准测试中,使用LongReward的DPO模型在短上下文指令跟随任务中也表现出色,整体胜率为7.51%,高于SFT基线的7.62%。
总体结论
这篇论文提出了LongReward方法,首次实现了自动为长上下文模型响应提供可靠奖励的功能。通过结合DPO算法,显著提高了长上下文LLMs的性能,并在短上下文任务中也表现出色。LongReward的成功表明,AI反馈可以有效地指导RL训练,提高模型的多维度能力。未来的工作将致力于训练更小的长上下文奖励模型,探索更长序列和更大规模模型的长上下文对齐。
论文评价
优点与创新
- 首次提出LongReward方法:论文首次提出了LongReward方法,该方法利用现成的LLM为长上下文模型响应自动提供可靠奖励信号。
- 设计长上下文RL框架:通过结合LongReward和DPO算法,设计了一个长上下文RL框架,有效提升了长上下文SFT模型的能力。
- 多维LLM评分:对长上下文模型响应从四个人类价值维度(有帮助性、逻辑性、忠实性和完整性)进行评分,并取平均值作为最终奖励。
- 实验验证:在Llama-3.1-8B和GLM-4-9B模型上进行了广泛的实验,结果表明使用LongReward的DPO模型在长上下文任务上分别比SFT模型提高了4.9%和5.5%的性能。
- 人类评估一致性:人类评估进一步验证了LongReward与人类偏好的良好对齐,并在所有四个维度上提升了长上下文模型的表现。
- 短上下文指令跟随能力:发现LongReward也有助于提升模型的短指令跟随能力,并且可以很好地融入标准的短上下文DPO中,同时提高长上下文和短上下文的性能。
不足与反思
- 依赖对齐良好的LLM:LongReward依赖于对齐良好的LLM(如GLM-4)来提供每个维度的评分,每次问答实例需要数十次API调用。未来将尝试训练一个更小的长上下文奖励模型,以加快和降低奖励计算成本。
- 计算资源限制:由于计算资源有限,目前仅在10B级别模型上进行了实验,最大训练长度为64k。希望在资源允许的情况下,探索更长序列和更大规模模型的长上下文对齐。
- 数据视角:目前主要关注用户密集的长上下文场景,如长文档问答和摘要。将LongReward推广到更高级的长指令任务,如终身对话和长历史代理任务也是一个有前景的方向。
关键问题及回答
问题1:LongReward方法在评估长上下文模型响应时,具体采用了哪些多维度评分方法?这些方法的评估标准和实现细节是什么?
- 有用性评分:通过少样本学习,LLM根据查询和响应内容直接给出有用性评分。引入Chain-of-Thought(CoT),要求LLM在提供最终评分前生成分析,以增强评分的可靠性和互操作性。
- 逻辑性评分:由于LLMs的生成过程缺乏回滚机制,容易出现逻辑不一致的错误。LongReward通过少样本学习和CoT,要求LLM找出响应中的潜在逻辑错误并进行评分。
- 忠实性评分:忠实性衡量响应中与上下文一致的事实信息比例。LongReward要求LLM将响应分解为一组事实陈述,并判断每个陈述是否由最相关的上下文支持。改进措施包括句子级别的事实陈述分解、忽略功能句子等。
- 完整性评分:完整性关注响应是否覆盖了上下文中的所有相关问题关键点。LongReward采用分而治之的策略,将上下文分割成粗粒度块,要求LLM从每个块中提取问题相关信息,再评估响应的完整性。
问题2:在实验中,LongReward方法如何与DPO算法结合以提高长上下文LLMs的性能?具体的优化目标和训练过程是怎样的?
- 构建长上下文偏好数据集:使用LongReward和一组长上下文提示构建长上下文偏好数据集。这些提示可以来自SFT数据集或新收集的数据。
- 采样和评分:对于每个提示,采样10个候选响应,使用Zhipu-Embedding-2*作为检索器评估忠实性,检索每个事实陈述的前5个上下文块。然后应用LongReward为每个响应打分。
- 选择偏好对:从高奖励和低奖励的响应中选择偏好对。
- DPO训练:使用偏好对数据集对SFT模型进行DPO训练。优化目标包括最大化偏好对的似然差异(公式如下)和交叉熵损失(公式如下):

- 其中,πθ表示策略模型(即被训练的LLM),πref表示参考模型(通常是冻结的SFT模型),β是控制不偏好响应惩罚强度的系数。
- 稳定性优化:为了进一步稳定DPO训练,添加了一个额外的交叉熵(CE)损失项,公式如下:

最终的优化目标为:
![]()
其中λ表示CE损失的缩放系数。
问题3:LongReward方法在实验中表现如何?与其他基线方法和SFT模型相比有哪些优势?
- 自动评估结果:在LongBench-Chat和LongBench基准测试中,使用LongReward的DPO模型在长上下文任务上的表现显著优于SFT模型和其他基线方法。Llama-3.1-8B和GLM-4-9B的DPO模型分别提高了4.9%和5.5%的平均性能。
- 忠实性评估:使用FactScore自动评估模型的忠实性,结果显示使用LongReward的DPO模型在支持事实的比例上高于SFT基线,表明LongReward在减少幻觉方面也有效。
- 人类评估结果:在LongBench-Chat上进行的人类评估显示,使用LongReward的DPO模型在有用性、逻辑性、忠实性和完整性四个维度上的整体胜率为54%,显著高于SFT基线的8%。
- 短上下文任务:在MT-Bench和AlpacaEval2基准测试中,使用LongReward的DPO模型在遵循短指令的能力上也表现出色,整体胜率为7.51%,高于SFT基线的7.62%。
总体而言,LongReward方法不仅显著提高了长上下文LLMs的性能,还增强了其遵循短指令的能力,并且可以与标准的短上下文DPO结合使用,不会影响各自方法的性能。
case study
比较感兴趣case部分。首先是四个维度的评估是如何做的,以下是prompt:
1. 提示进行有用性评估
您是评估文本质量的专家。
作为公正的评估者,请评估人工智能文档问答助手对用户查询的响应的有用性。具体来说,评估回答是否:1)与问题相关; 2)满足用户的目的和需求; 3)提供彻底且适当的答案; 4) 满足用户的格式要求(如果有);
您必须先提供分析,然后严格按照以下格式对响应进行评分,评分范围为 0 到 10:“[[Rating]]”,例如:“[[5]]”。
以下是几个评分示例:
{示例 1}
{示例 2}
{示例 3}
{示例 4}
现在,请根据评分原则和上述示例对以下 AI 助理的回答进行评分:
[问题]
{查询}
[助理的回答开始]
{模型响应}
[助理的回答结束]
[分析]
2. 提示进行逻辑性评估
您是评估文本质量的专家。
作为公正的评估者,请评估AI文档问答助手对用户查询的回答的逻辑性。具体来说,评估回答的不同部分在逻辑上是否一致,观点是否自始至终一致,推理和计算是否正确,没有自相矛盾。
您必须先提供分析,然后严格按照以下格式对响应进行评分,评分范围为 0 到 10:“[[Rating]]”,例如:“[[5]]”。
确保在评估过程中不要使用助理回答之外的任何信息或知识,并仅关注回答的逻辑一致性。 以下是几个评分示例:
{示例 1}
{示例 2}
{示例 3}
{示例 4}
现在,请根据评分原则和上述示例对以下 AI 助理的回答进行评分:
[问题]
{查询}
[助理的回答开始]
{模型响应}
[助理的回答结束]
[分析]
3. 在忠诚度评估中提示事实陈述
您将收到用户对上传文档的询问(由于文档过长,不会向您显示)以及 AI 文档 QA 助理的回答。您的任务是从提供的答案中提取事实陈述。这些事实陈述通常以单独的句子表达,并且必须直接基于文档中的信息,而不是介绍性句子、过渡句或基于先前答案内容的总结、推论或演绎。如果事实陈述缺少主语或包含“他/她/它/这些/那些”等代词,则必须根据上下文添加主语或解析代词。您必须按以下格式输出:
<statement>{Statement 1}</statement>
<statement>{Statement 2}</statement>
以下是几个评分示例:
{示例 1}
{示例 2}
{示例 3}
{示例 4}
现在,请根据评分原则和上述示例对以下 AI 助理的回答进行评分:
[问题]
{查询}
[助理的回答开始]
{模型响应}
[助理的回答结束]
[分析]