摘要:本文整理自阿里云智能集团研究员、开源大数据平台负责人王峰(莫问)老师在云栖大会的开源大数据专场上的分享。主要有以下几个内容:
1. Apache Flink 已经成为业界流计算事实标准
2. Flash 向量化流计算引擎核心技术解读
3. Flash 性能测试数据
4. Flash在阿里集团的落地效果
Tips:点击「阅读原文」跳转阿里云实时计算 Flink~
今天给大家带来的分享是阿里云的开源大数据团队在实时计算领域最新的技术成果——Native 流计算引擎,即向量化流计算引擎Flash。这是一款百分之百兼容 Apache Flink 的新一代流计算引擎。接下来将分别介绍开发这款引擎的原因、其核心技术解读、当前取得的技术成果,以及在阿里巴巴集团内部的业务应用成效。
01
Apache Flink 已经成为业界流计算事实标准

阿里巴巴作为 Apache Flink 社区在国内最早的实验者和推动者,已经在流计算领域积累了超过十年的经验。早期的流计算引擎,如 Apache Storm,是在 Hadoop 时代出现的。虽然 Storm 是一款开创性的流计算引擎,但它存在一些瓶颈,特别是在状态管理方面。由于 Storm 是无状态的流计算引擎,缺乏高效的状态管理机制,导致其在一些需要高精确性的数据处理场景中表现不佳。随后出现的 Spark Streaming 基于 Apache Spark 引擎,这一引擎是批处理计算的事实标准。Spark Streaming 采用微批处理模型来进行流计算,这也是一种流计算的选择。然而,由于这种模式本质上是微批处理,导致其在性能和吞吐量方面存在较高的延迟。此外,Spark Streaming 在流计算的语义上也无法做到百分之百的精确。

直到 Flink 的出现,才真正解决了流计算中的诸多问题。Flink 具有卓越的实时处理能力,原生支持低延迟流处理和有状态计算,能够处理复杂的事件时间和乱序数据,提供高吞吐量和精准的实时数据分析。Flink 于2014年捐赠给 Apache,经过十年的发展,Apache Flink 已经成为业界流计算事实标准。
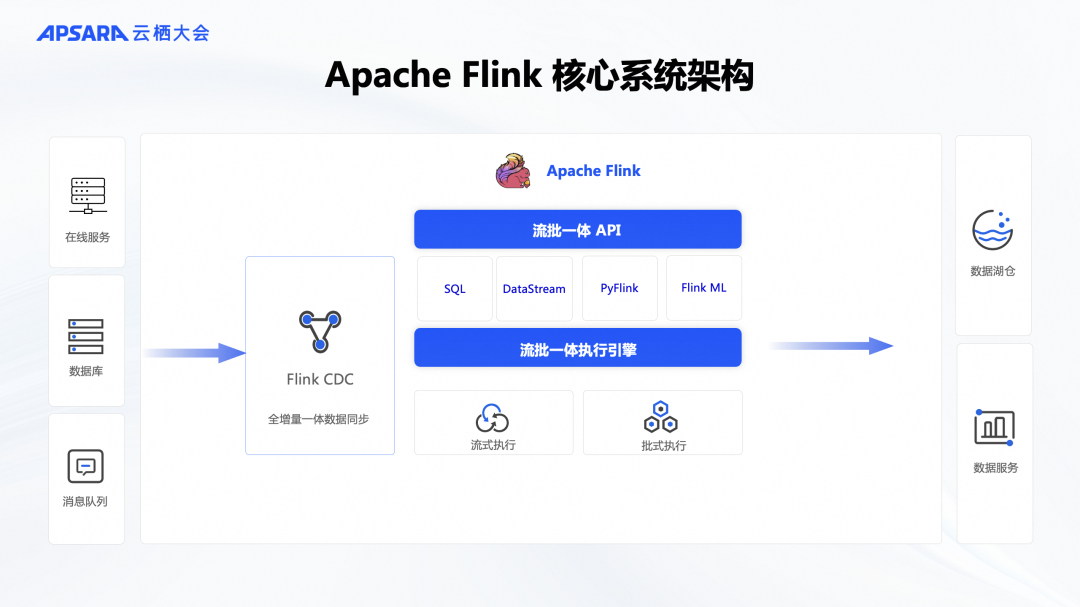
Flink的核心架构可以通过一个简单的架构图来表示,它是一款纯流式的执行引擎。同时,Flink也是一款基于流的流批一体化计算引擎。也就是说,它可以基于一套统一的执行引擎来处理流式数据和批式数据。此外,Flink还提供了流批一体的API表达能力,方便开发者使用。它拥有完善的API体系,包括SQL、Java API和Python API,使得开发更加便捷。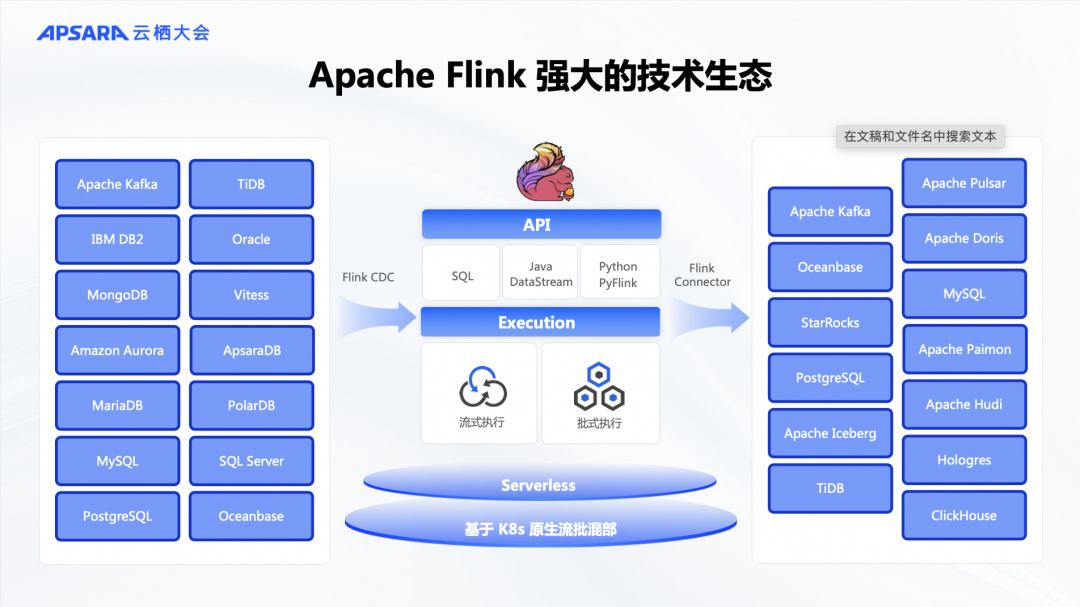
近年来,Flink在技术架构方面不断演进,取得了显著进展。例如,Flink CDC用于实时数据同步,越来越多的用户选择使用Flink进行数据同步和数据集成。此外,Flink 在经典的机器学习任务中也得到了广泛应用。可以看到,Flink的技术架构日益完善,逐渐成熟。在技术生态方面,Flink也构建了一个强大且繁荣的生态系统。同时 Flink 也可以完美地部署到 Kubernetes 上,完全进入了容器化部署和云原生的时代。
此外,更重要的一点是,Flink这个计算引擎实际上作为桥梁连通了大数据各个数据存储。当我们提到大数据,首先要了解数据存储的位置,数据的存储和管理是大数据处理的第一步。数据通常存储在数据库、消息队列、数据湖或数据仓库中。但是,数据需要流动,只有流动的数据才有价值。因此,Flink在整个开源大数据生态系统中扮演了重要角色,它的最大价值在于推动了数据在不同数据源之间的实时流动。
Flink Connector 能够连接各种类型的数据源,成为整个大数据生态系统的中枢桥梁。Flink本身的生态已经非常完善,各种存储系统都可以与Flink结合,通过Flink实现数据的导出和流动。这就是当前Flink在大数据领域的现状。
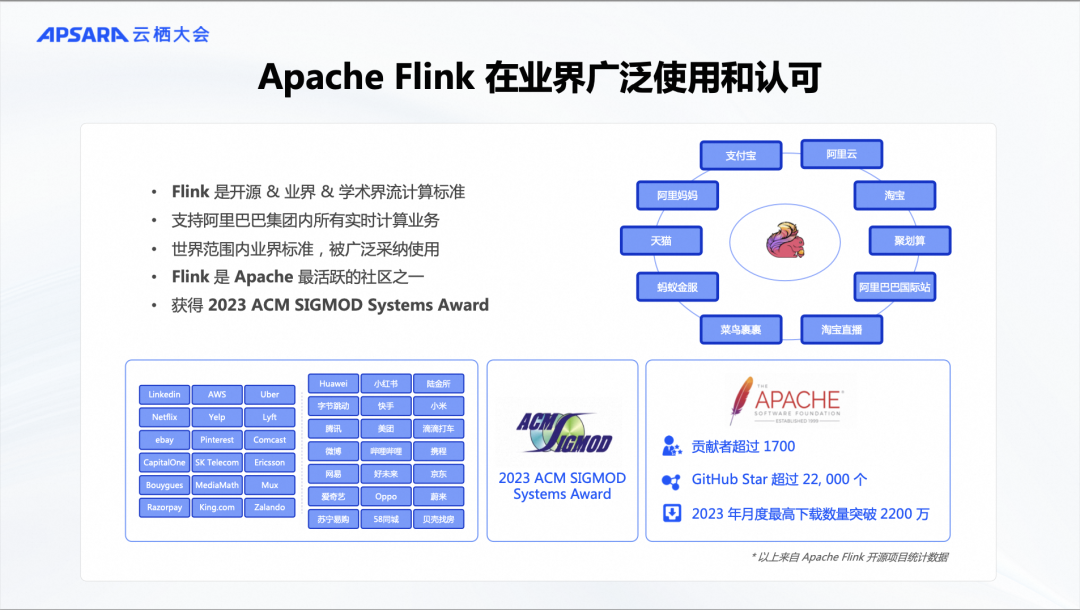
可以看到,Flink凭借其优秀的技术架构和强大的技术生态,已经被业界广泛认可为一个标准的流计算技术,也是开源界的流式计算标准。阿里巴巴是最早应用Flink技术的公司之一,自2016年起在阿里集团内上线Flink,服务于各个业务单元和行业场景,包括电商、物流、旅游和地图等。
近年来,Flink在国内的应用领域不断扩展,从互联网公司到金融、物流、交通、汽车等各行各业,也广泛采用Flink进行实时流数据处理。不仅如此,Flink在国际上也得到了广泛认可和应用,在北美、欧洲和东南亚等地区,Flink已经成为事实上的流计算标准,逐渐演变为一个全球化的流计算技术标准。
2023年,Flink凭借其优秀的流计算模型设计及其在工业界和全球范围内的成功应用,荣获了 SIGMOD Systems Award 的设计大奖。因此,可以认为在批处理计算领域,Spark是事实上的标准,而在流式计算领域,Flink则是标准。
为什么要提到这些呢?因为我们现在已经拥有一款非常优秀的计算引擎——Flink。阿里云也提供了基于 Flink 的实时计算产品,为用户提供更多的服务。
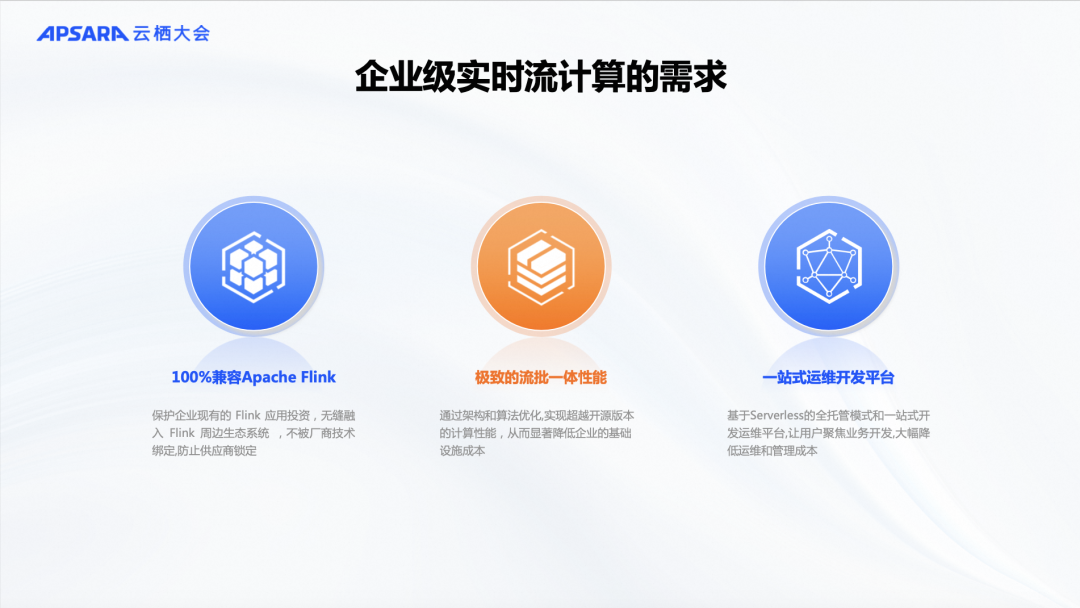
那么,为什么要开发Flash这个新一代向量化流计算引擎呢?这需要回归到用户的需求。
首先,Apache Flink已经成为事实上的标准。用户的需求必然是兼容Flink和开源的标准生态,这意味着用户不会被绑定在某个特定平台上,而且可以与各种上下游系统进行无缝对接。因为大家都遵循开源标准,所以我们不想为这个生态系统创建一个完全新的系统。
其次,企业级用户希望在云上有一个一站式的数据开发运维平台,来帮助他们使用产品,而不是让他们从头到尾自建一套复杂的流数据处理系统。实际上,这两点需求我们在当前的实时计算Flink产品线上都有覆盖,并且已经有非常多的用户在使用我们的产品。在当前经济环境下,大家都希望降本增效。用户希望使用云产品和云服务,但不希望花费比自建系统更高的成本。相反,他们希望通过较低的成本来运行数据分析和数据处理,同时兼容开放标准。此外,用户还需要一站式服务,确保服务级别协议(SLA)的达成。这些都是企业用户的需求。
最大的挑战和最难满足的需求是做到100%兼容开源标准,同时在性能和成本上大幅优于开源软件。以流式计算Flink为例,用户希望在享受开源标准带来的兼容性和灵活性的同时,获得更高的性能和更低的成本。从云产品的角度来看,我们在实时计算Flink产品上做了大量努力。这些年,我们推出了企业级的Flink引擎,性能远高于开源版本。然而,我们发现这仍然无法完全满足许多企业客户的需求,当前的Flink引擎优化主要是基于开源的 Flink 上 Java 进行工程上的改进,性能提升存在天花板。因此,我们希望能够更大程度地提升系统性能,突破现有的性能瓶颈,同时保持对Flink的兼容性。这就是我们开发新一代 Native 化、向量化流计算引擎的背景。
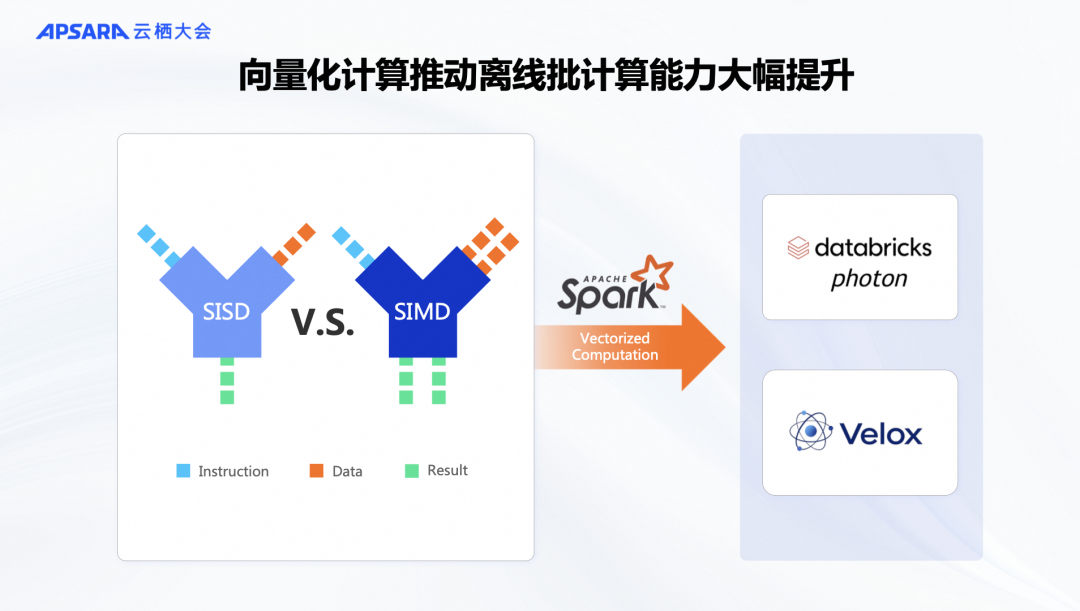
在批处理领域,类似的需求也已经出现。例如,在Spark场景中,Databricks对Spark进行了深度优化,推出了名为Photon的引擎。Databricks的产品化成果显著,Photon引擎在处理用户数据时比开源Spark有数倍的性能提升。在开源领域,Facebook开源了向量化算子库Velox,可以应用到Spark框架中,实现C++内核的Spark。英特尔的 Gluten 项目也能很好地将Velox算子集成到Spark中,打造一个Native Spark引擎。
这些优化利用了向量化技术SIMD(单指令多数据)指令。SIMD能够让一条指令同时处理多条数据,相比于传统的单指令单数据串行计算,这种并行计算方式可以显著提升性能。通过充分利用CPU的硬件能力,向量化技术能够大幅加速计算,是一个被广泛接受的优化思路。
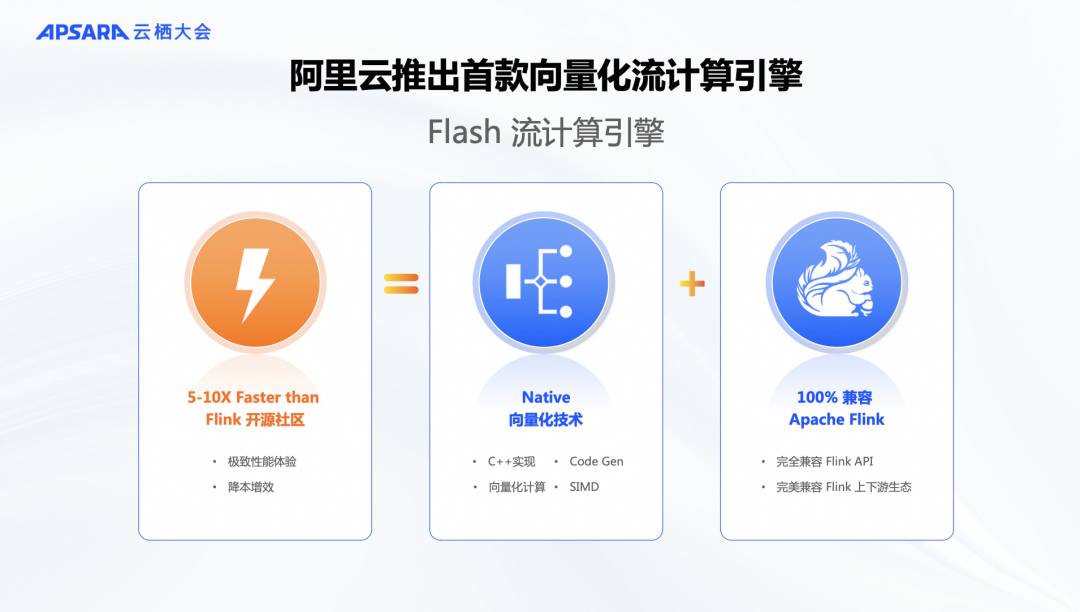
在流计算领域,以前并没有一款真正意义上的向量化 Native 的Flink引擎。虽然Spark已经实现了类似的优化,但Flink尚未有类似的进展。因此,我们在两年前启动了这个项目,旨在开发一款 Native Flink引擎。Flink整个社区的版本也是由我们团队来主导发布的,所以我们对流计算有着深刻的理解,认为可以将向量化计算技术和C++的优势引入Flink的计算模型中,充分利用机器硬件优势。这就是Flash引擎的由来。经过两年的努力,我们已经取得了显著的阶段性成果,目前 Flash 1.0版本已在内部完成。
02
Flash 向量化流计算引擎核心技术解读

在过去的六个月中,我们已经在阿里集团内部上线了这款引擎,并取得了预期的成果。性能数据显示,相较于开源的Flink版本,我们的引擎性能提升了5到10倍。这就是我们今天要发布的Flash 引擎的背景。接下来,我将详细介绍Flash向量化流计算引擎的核心技术设计,以及为何它能够比开源版本快得多的原因。

这是Flash核心引擎的架构设计。蓝色部分代表开源Flink框架,包括API等分布式框架组件,是完全开源的。橘色部分是我们新开发的Native Runtime内核。我们保留了Flink的SQL API、Table API和SQL Optimizer,以确保与Flink任务和Flink SQL的100%兼容。同时,部分Flink Java Runtime功能也被保留,以便在Native Runtime无法覆盖某些算子时,回退到Java Runtime,确保兼容性。引擎的核心设计包括Leno胶水层、Falcon算子层和ForStDB状态存储层。Falcon算子层实现了向量化计算,而ForStDB提供了向量化的状态存储功能。这三部分的设计使得Flash引擎在性能上大幅优于Flink的Java内核。
2.1 Leno 胶水层
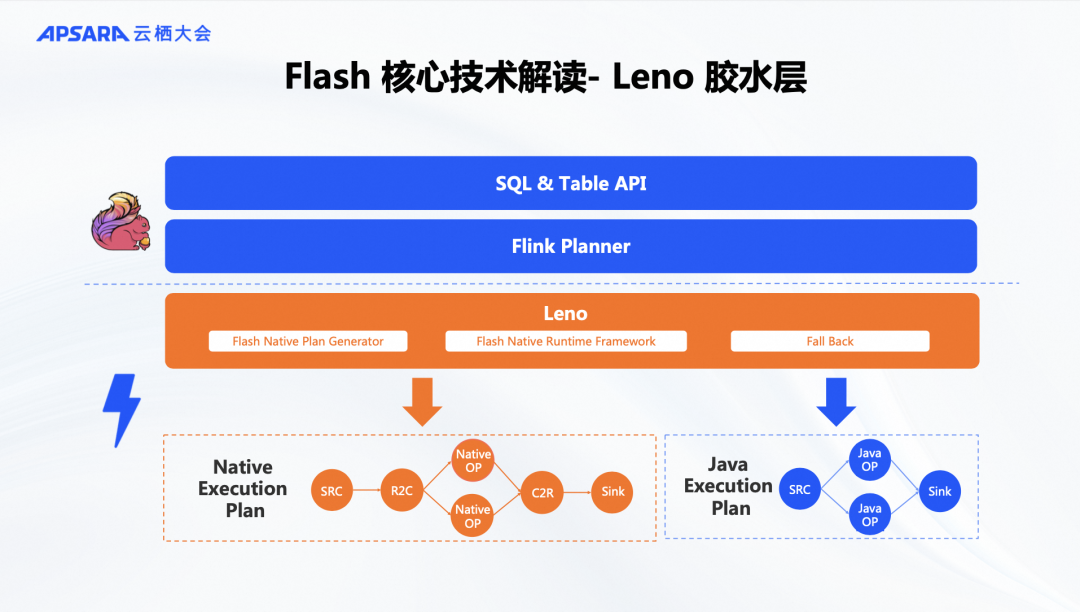
我们首先来看Leno胶水层,它类似于Spark中的Gluten,主要负责将流式Native Runtime与Flink的分布式框架解耦。这样,我们可以独立发布Native算子。Leno胶水层的任务是生成Native的执行计划,即根据用户的SQL需求,通过Flink Planner判断SQL语句中算子是否全部被覆盖。如果全部覆盖,就生成完整的C++向量化执行计划;如果不行,则回退到Java的执行计划。因此,这一层更侧重于框架和粘合的功能。
2.2 Leno Falcon 向量化算子层

Flash的核心设计重点在于Falcon向量化算子层和ForStDB状态存储层。首先介绍向量化算子层。向量化计算的核心在于使用C++语言实现向量化算子和内存优化,所有计算都采用向量化模式进行。在Flink中,我们的算法分为两大类:无状态算子(Stateless Operators)和有状态算子(Stateful Operators)。无状态算子不需要维护状态,例如流中的过滤或字符串处理。相比之下,有状态算子需要维护状态,例如在流处理中进行聚合统计或双流Join操作。
此外,我们在Falcon层中用C++重新实现了许多内置数据类型、时间函数和字符串处理函数,所有算子的运行都采用向量化模式,从而实现了计算上的优化。通过对阿里巴巴内部流式分析场景的数据分析,我们发现Flash版本已经能够覆盖超过80%的业务场景。这意味着大部分计算和算术逻辑已被涵盖。对于尚未实现的算子,我们会继续开发,以覆盖更多流计算的需求。
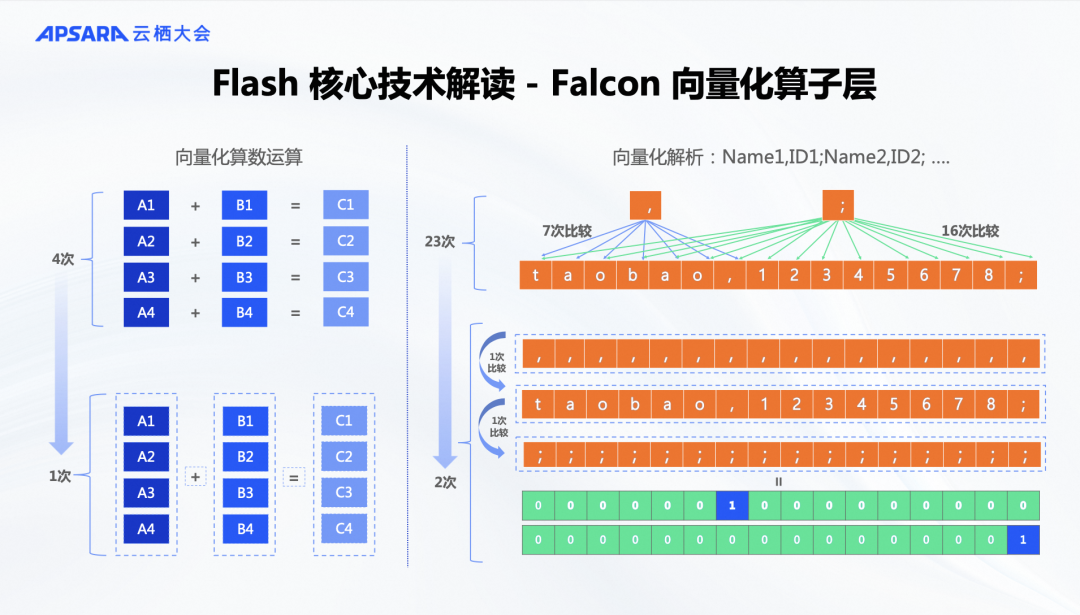
这里我举一个例子来说明为什么 Falcon 向量化算子层比 Java 的 Flink 更快。这是因为我们使用了 SIMD 指令来实现数据的并行计算。尽管流计算在宏观上是逐条处理记录,但在微观执行中,数据是在缓冲区中批量传递的。上游节点会处理一批数据,如1000条,大约32K的数据,然后将其作为网络缓冲区传递到下游。下游也以每1000条的批次进行处理。在处理这1000条数据时,可以选择每100条、每1000条或每10条进行处理,这取决于计算算法的特性。
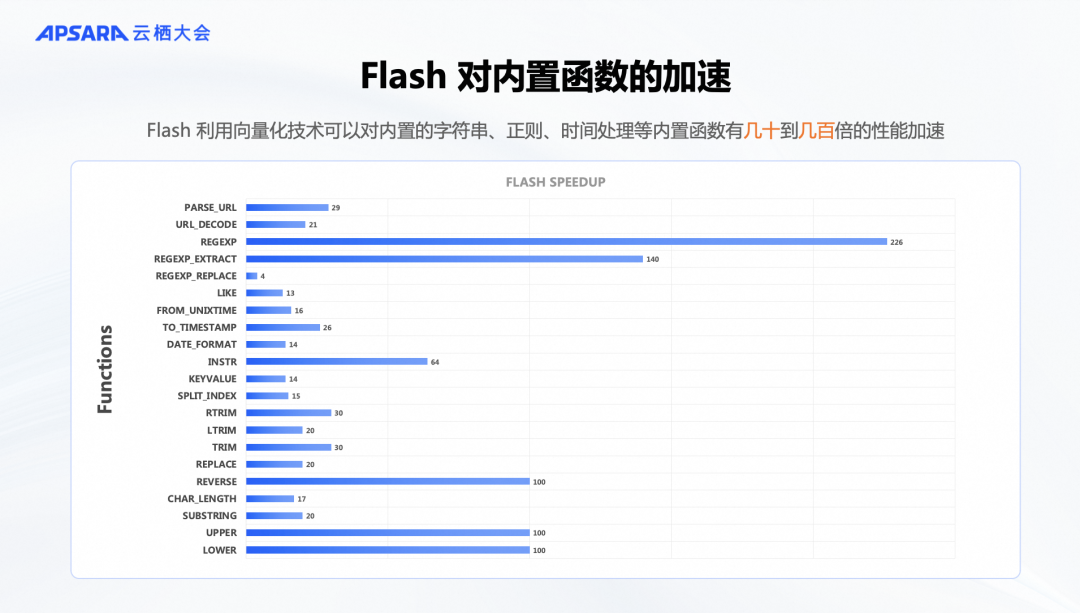
如果我们利用 SIMD 指令来处理多条数据,即使是同一条数据的操作,如字符串解析和比较,速度显然会更快。如果用向量化的方式,那我们就可以一次性比较所有数据,从而显著提升计算效率。这种向量化计算的优势与批处理类似。当我们将这种方法引入到 Flink 后,发现可以优化高频使用的内置函数,尤其是字符串处理、时间处理等常见操作。经过优化后,许多内置函数的性能提升了几十倍甚至上百倍。这种提升不仅得益于 C++ 的实现优势,还因为向量化执行的优势使得执行效率更高。
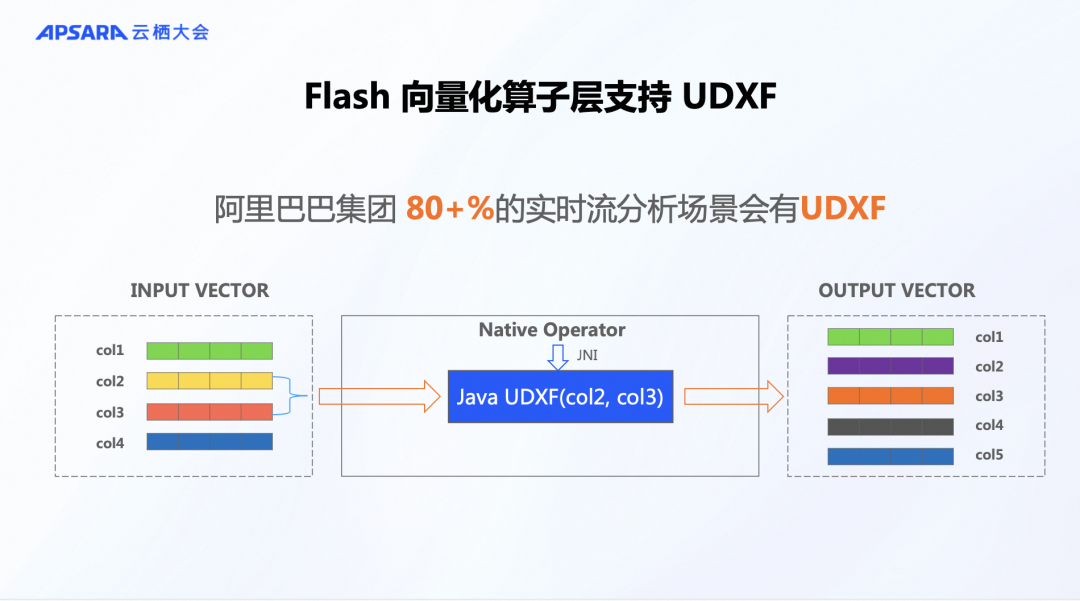
一个值得分享的亮点是对UDF(用户自定义函数)的支持。我们发现,在阿里巴巴集团内部,流处理业务非常广泛,其中80%以上的场景需要使用UDF。如果不支持UDF,许多业务场景将无法实现。例如,在Velox这样的开源批处理算法库中,遇到UDF时会转到Java的Runtime环境,这意味着无法优化用户代码。我们认为支持UDF是一个非常重要的特性。因此,从第一天起我们就确保支持UDF。即便用户偏好Java的UDF,我们仍然能利用向量化计算的优势,而不依赖于Java Runtime。这一特性在生产应用中为我们带来了显著优势,使得我们能够快速尝试和实现各种业务场景。
2.3 ForStDB
在介绍完Falcon向量化算子层之后,我们接下来要讨论另一项核心技术:ForStDB,这是一种状态存储引擎。为什么需要开发这一部分呢?因为云计算中的Flink是一个有状态的计算引擎。那么,什么是状态呢?在流式计算过程中,例如进行PV(页面访问量)和UV(独立访客)统计,或者进行双流JOIN操作时,这些统计值和数据需要被存储,这就是我们的状态数据。如果这些状态数据不存储在类似Flink内存的小型数据库中,就无法进行统计或JOIN操作。此外,一旦任务失败,我们也无法恢复。因此,状态存储是至关重要的。
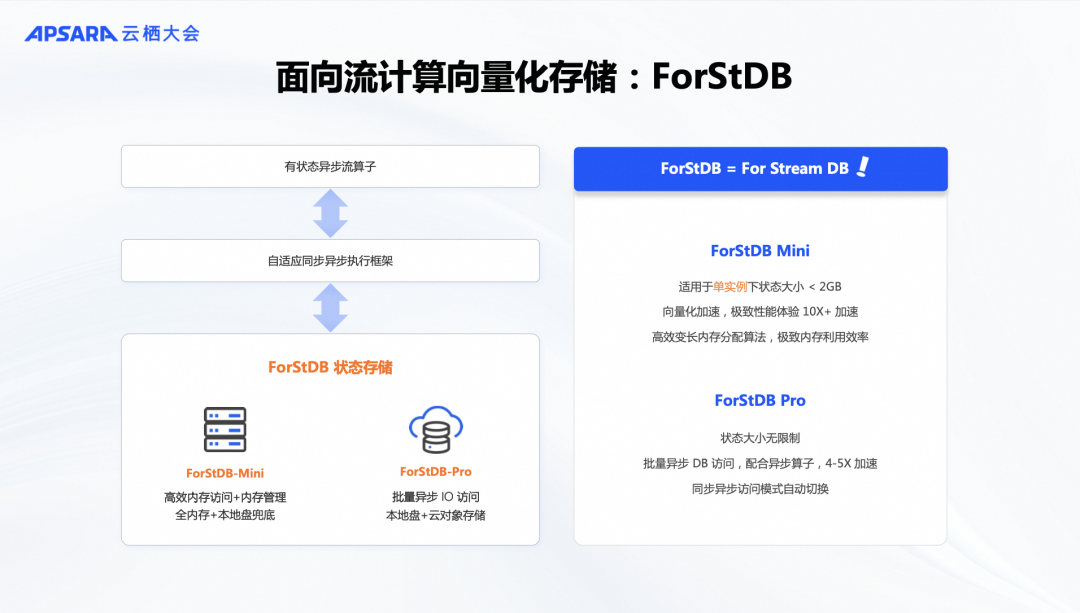
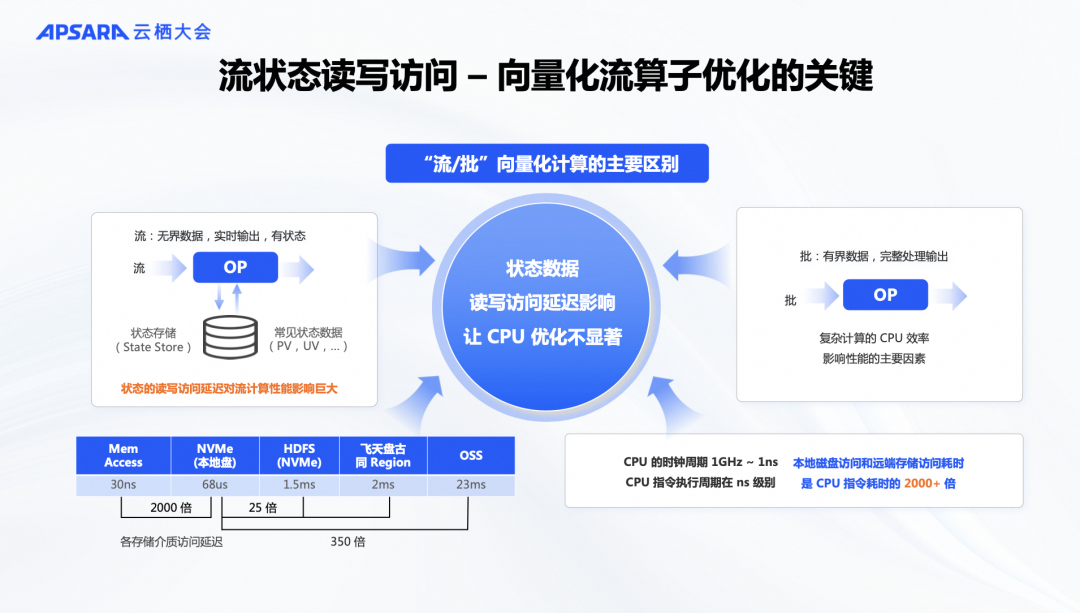
因此,虽然Flink内置了一些DB,但当状态数据变大并需要访问磁盘时,即使使用NVMe硬盘,其性能和访问速度也比内存和CPU计算慢数百甚至上千倍。如果不优化这部分,向量化计算的优势可能会被状态访问所削弱。这也是流计算与批计算的最大差异之一,并使得向量化流计算引擎比批计算引擎更复杂。为解决这一问题,我们在Flash中创新推出了面向流计算的向量化状态存储引擎 ForStDB。顾名思义, ForStDB 是专为流计算设计的 For Stream DB,旨在提升流计算中的性能和效率。
在谈到状态时,做流计算的同学都知道,不同场景下状态的大小差异很大。例如,在简单的聚合统计中,状态可能较小,比如一个并发实例的UV统计,用户数量不多,可能1G内存就足够。但在双流JOIN等场景中,需要存储大量数据,状态可能非常大。或者在实时采购中,可能需要存储许多规则和历史数据,这些数据可能需要保存一个月甚至更久,状态数据可能达到几十G甚至上百G,这时内存就无法容纳。因此,我们的设计类似于数据库中的内存数据库和磁盘数据库,确保在不同状态大小的场景下都有高效的存储解决方案。
ForStDB有两个版本,各自针对不同的状态存储需求。首先是 Mini 版本,专为存储小型动态数据而设计,利用内存来处理中小规模的状态。另一个是Pro版本,用于存储大规模状态数据。接下来,我们可以分别介绍这两种版本的具体实现。
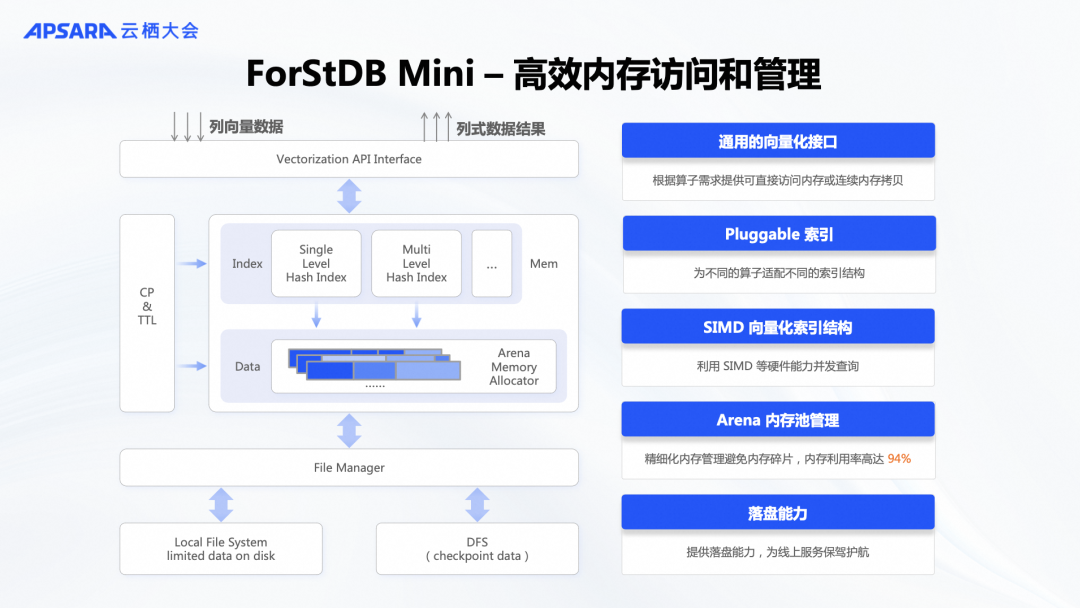
ForStDB Mini版本是基于内存的状态存储引擎,专用于存储PV、UV等统计数据。所有数据访问都通过向量化接口进行,以批处理方式输出,从而提高吞吐量。其关键在于现代化设计的索引结构,类似于一个大型的哈希索引。它不仅支持单条查询,还利用SIMD的优势进行并行查询,因此性能比传统的KV存储快很多。这也是为什么它比开源版Flink的内存状态存储快得多,特别是在Java环境中。此外,ForStDB Mini完全用C++实现,内存管理采用基于Arena的内存池管理,大大提高了内存利用率,相较于Java的内存管理更为高效。因此,ForStDB Mini是一个完全生产可用的高性能状态存储解决方案。
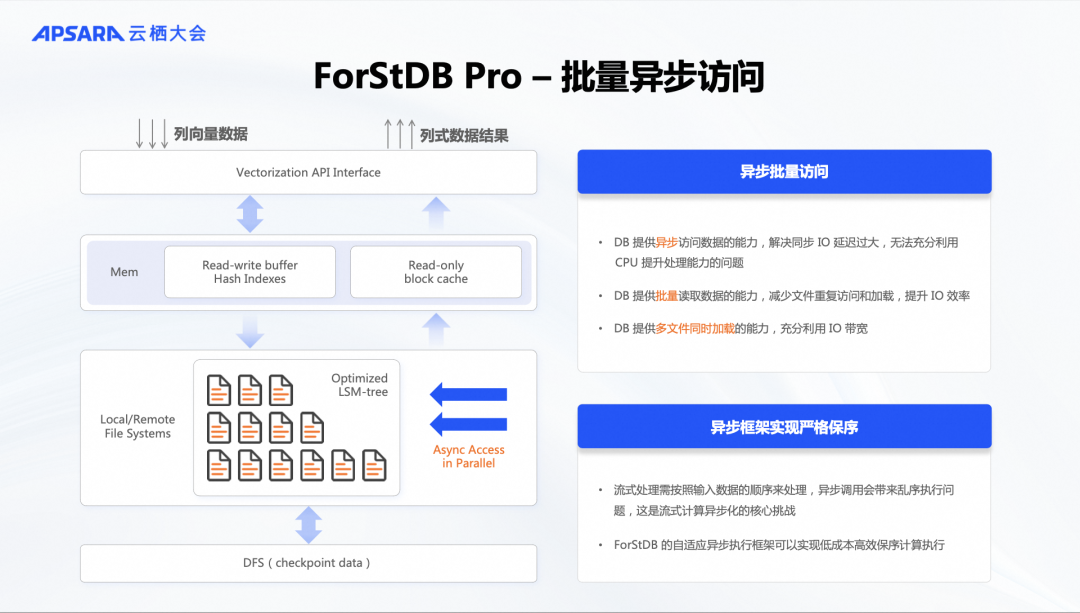
Pro 版本会面临更大的挑战,因为需要处理超大规模的状态数据,这些数据不仅存储在内存中,还需要写入磁盘。当状态数据过大时,内存无法完全容纳。为此,我们引入了异步IO能力,除了向量化和批处理方式外,还可以进行异步IO操作。在 LSM(Log-Structured Merge-Tree)架构上,我们结合流计算的特点进行了定制化优化。通过异步IO和并行处理,加速状态数据的访问,使其更加高效。
此外,流计算面临的一个重大挑战是确保数据的有序性。流计算要求数据不能乱序,这与传统的KV引擎不同,因为每个数据包之间没有直接关系。虽然键值不同,但顺序必须保持。为了攻克这一难关,我们在框架中确保流计算过程中的数据不会乱序。通过解决这些挑战,我们将ForStDB在状态存储中的优势与Falcon算子层的优势结合起来,取得了显著的数据成果。
03
Flash 性能测试数据
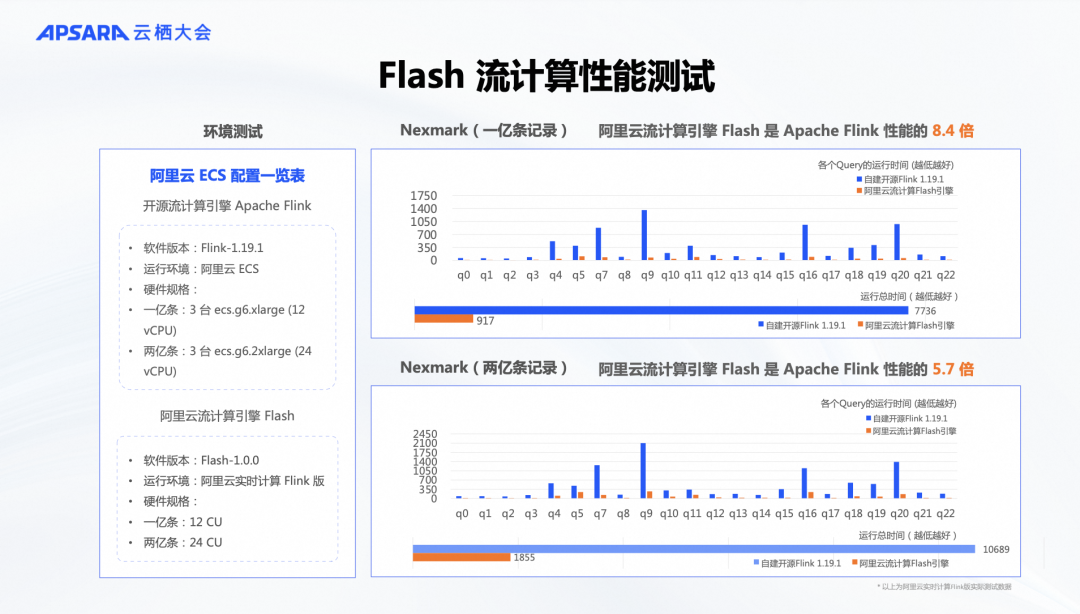
我们使用了开源的Nexmark作为标准性能测试工具。Nexmark是业界公认的流计算性能测试工具,大家可以在GitHub上找到相关信息。在这个测试中,我们对比了最新的Flink 1.19开源版本和我们的Flash 1.0。测试环境都在阿里云上进行。开源Flink在ECS环境中运行,模拟用户自建场景。而我们的产品化方案在全托管的Serverless架构下运行,购买相同数量的计算单元(CU)。这样,我们在相同硬件资源下对两者的性能进行了对比测试。
我们的团队选择了两种数据量进行测试:一亿条和两亿条数据。这样做是为了模拟不同规模的流计算场景。一亿条数据代表中小规模流计算,状态较小,可以使用ForStDB Mini版本进行测试。而两亿条数据则代表大规模流计算,状态较大,可能需要落盘处理,因此使用ForStDB Pro来管理状态。无论是中小规模还是大规模状态,我们的性能相较于开源Flink提升了五倍以上,特别是在中小状态下,提升可达八倍以上。这些数据结果是可复现的,因为我们的测试环境、方法和数据集都是公开的。大家有兴趣的话,可以尝试在相同条件下复现这些性能数据。后续我们会提供机会,让大家亲自验证这些性能提升。
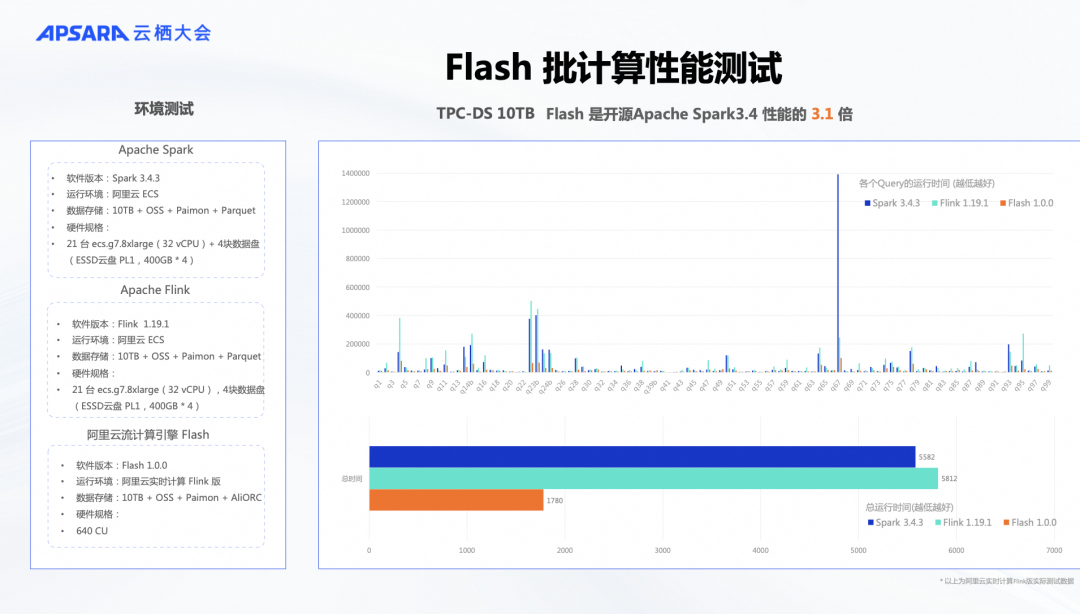
开头提到,Flink是一款流批一体的引擎,广受认可,已成为事实标准。除了在流计算方面的优势,Flink的执行引擎在批计算上也有许多优势,因为它能借鉴流计算中的性能优化技术来加速批处理。针对批计算,我们选择了经典的TPC-DS测试场景,使用10TB数据进行测试。测试环境和流程保持一致,我们对比了开源的Flink 1.19和Spark 3.4,在ECS上运行TPC-DS。同时,在我们的产品中使用相同数量的计算单元(CU)进行测试。结果显示,即使在批计算情况下,我们的性能比开源的Flink和Spark提高了三倍以上。这一成果是可复现的,大家有机会可以亲自验证。通过这两组流计算和批计算的标准测试,我们证明了基于C++向量化实现的Flash向量化引擎在性能和成本效益上都具有显著优势,远超纯开源版本。
04
Flash在阿里集团的落地效果
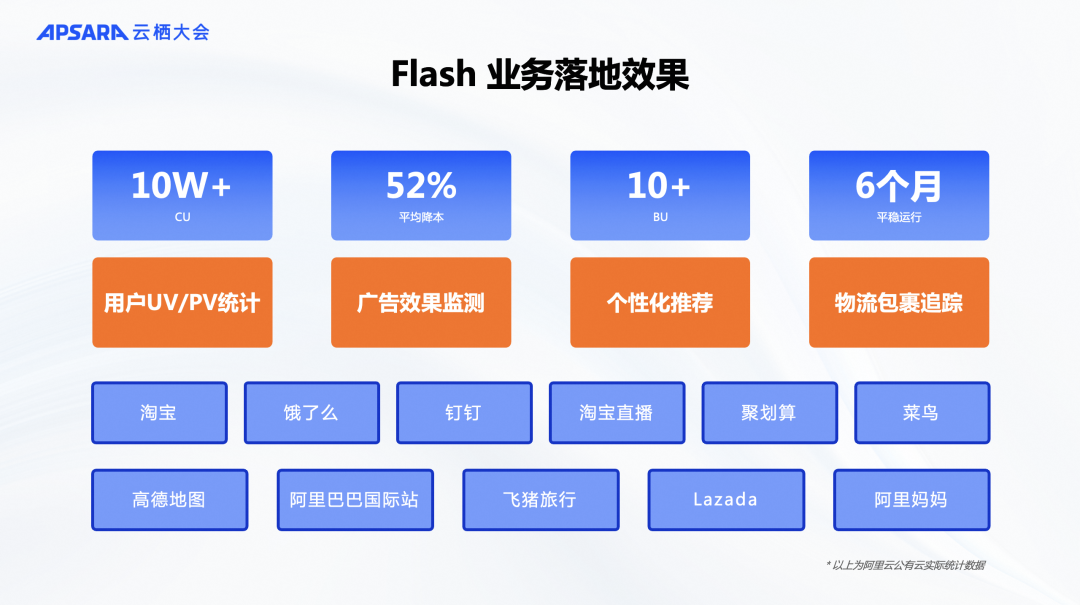
在理论和测试数据之外,我们还提供了阿里巴巴生产环境中的真实数据。自今年年初起,这个项目在阿里巴巴内部逐步上线,通过不断的线上打磨和更新,而非闭门造车。经过半年时间,我们在阿里巴巴内部上线了超过10万CU的实验性业务。我们测试了不到10%的流量,覆盖了阿里巴巴的主要业务场景,包括天猫、菜鸟、Lazada、飞猪、高德、饿了么等。测试涉及用户PV、UV统计、BI、广告效果监测、个性化实时推荐、订单物流追踪等场景。结果显示,这项技术可以帮助业务方实际节省50%的成本。
我们相信,全面上线后将节省大量资源。这项新引擎不仅有清晰的理论设计和实验室测试结果,还有令人信服的生产业务成果。因此,我们非常有信心在阿里云上推出这项技术,为更多中小企业和云原生企业服务。特别是开源Flink的用户,可以在不改变代码的情况下使用新的向量化兼容Flink的Flash引擎,实现降本增效。
由于这是一款全新的引擎,代码改动大,重构量大,且大量使用C++编写,我们将采取阶梯性上线策略。我们计划先进行一部分邀测,然后公测,最后正式商业化。希望有兴趣的客户和开发者联系我们的客户经理,参与测试和新产品发布。我们期待尽快发布公测和正式商业化。感谢大家,希望这款新的流计算引擎能对您有所帮助。谢谢!

活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版现开启活动:
新用户复制下方链接或者扫描二维码即可0元免费试用 Flink + Paimon
了解活动详情:https://free.aliyun.com/?pipCode=sc

▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」跳转阿里云实时计算 Flink~
点击「阅读原文」跳转阿里云实时计算 Flink~