文本语义分块、RAG 系统的分块难题:小型语言模型如何找到最佳断点?

转自jina最新的关于文本语义分块的分享和模型
之前我们聊过 RAG 里文档分块 (Chunking) 的挑战,也介绍了 迟分 (Late Chunking) 的概念,它可以在向量化的时候减少上下文信息的丢失。今天,我们来聊聊另一个难题:如何找到最佳的分块断点。
虽然迟分对边界位置不敏感,但也不代表我们可以随便乱切,毕竟可读性对人和大模型都很重要。所以我们现在的思路是:既然用了迟分,就不用太担心语义或上下文丢失的问题。边界好坏,迟分都能处理,因此文本块的可读性就成了关键。
基于这个想法,我们训练了三个小型语言模型 (SLM),专门用来切分长文档,同时保证语义连贯性,并且能够处理复杂的文档结构,比如代码、表格等等。它们分别是:
simple-qwen-0.5,根据文档的结构元素进行切分,简单直接。https://huggingface.co/jinaai/text-seg-lm-qwen2-0.5btopic-qwen-0.5:灵感来自思维链 (Chain-of-Thought) 推理,它会先识别文本中的主题,再根据主题进行切分。初步测试显示,它的切分结果非常符合人类的直觉。https://huggingface.co/jinaai/text-seg-lm-qwen2-0.5b-cot-topic-chunkingsummary-qwen-0.5:不仅能切分文档,还能生成每个分块的摘要,在 RAG 应用中非常有用。https://huggingface.co/jinaai/text-seg-lm-qwen2-0.5b-summary-chunking
接下来,我们会聊聊我们为什么要开发这三个模型,它们各自的特点,以及它们和 Jina AI 的 Segmenter API 的效果对比。最后,还将分享我们学到的东西和对未来的一些想法。
传统分块存在的问题
**RAG 系统里,文档分块是核心问题。**文本块的质量好坏直接影响检索和生成效果,答案相关性、摘要质量都逃不掉它的影响。
传统的那些分块方法,像固定 token 长度、固定句子数量,或者高级点的用正则表达式,都忽略了语义边界。结果就是,碰上主题模糊的内容,分出来的块就支离破碎,即使后来用迟分生成带上下文的向量也救不回来。
因为 LLM 要想生成准确的答案,依赖的是连贯、结构良好的数据。要是分出来的文本块本身就没啥意义,LLM 理解上下文都费劲,更别说保证准确性了,最终影响整体性能。
所以,我们专门训练了小型语言模型来做分块,目标很明确:捕捉主题转换,保证文本块的连贯性,同时兼顾效率和通用性。
为什么要用小型语言模型?
那为什么要用小型语言模型 (Small Language Model, SLM) 来解决呢?
因为传统的分块技术在处理代码、表格、列表、公式这些复杂结构时容易翻车。它们通常只看 token 数量或结构规则,不理解语义,很难保证语义连贯内容的完整性。就容易导致代码片段被切得七零八落,上下文信息丢失,下游系统理解和检索都很抓瞎。
我们训练了专门的 SLM,就是想让它能够智能地识别并保留这些有意义的边界,保证相关元素不被拆散。这样 RAG 系统的检索质量提高了,摘要、问答等下游任务的效果也能更好了。相比传统那些死板的分块方法,SLM 的方案更灵活,也更具针对性。
一口气训练了 3 个小模型
我们训练了三个版本的 SLM:
simple-qwen-0.5: 这是最简单的模型,主要根据文档的结构元素识别边界。它简单高效,适合基本的分块需求。topic-qwen-0.5: 这个模型受到了思维链 (Chain-of-Thought) 推理的启发,它会先识别文本中的主题,比如“第二次世界大战的开始”,然后用这些主题来定义分块边界。它能保证每个文本块在主题上保持连贯,特别适合处理复杂的多主题文档。初步测试表明,它分块的效果很不错,很接近人类的直觉。summary-qwen-0.5: 这个模型不仅能识别文本边界,还能给每个文本块生成摘要。在 RAG 应用里,文本块摘要很有用,尤其是在长文档问答这种任务上。当然,代价就是训练时需要更多的数据。
这三个模型都只返回文本块的头部,也就是每个文本块的截断版本。它们不生成完整的文本块,而是输出关键点或子主题。简单来说,因为它只提取关键点或子主题,这就相当于抓住了片段的核心意思,通过文本的语义转换,来更准确地识别边界,保证文本块的连贯性。
检索的时候,我们会根据这些“文本块头部”把文档文本切片,然后再根据切片结果重建完整的片段。相当于我们先用“文本块头部”做了个索引,需要的时候再根据索引找到对应的完整片段。这样既能保证检索的精准度,又能提高效率,避免处理过多的冗余信息。
数据集
我们使用了 wiki727k (https://github.com/koomri/text-segmentation) 数据集,这是一个从维基百科文章中提取的大规模结构化文本片段集合。它包含超过 727,000 个文本块,每个片段代表维基百科文章的不同部分,例如引言、章节或子章节。
数据增强
为了丰富每个模型变体的训练数据,我们利用 GPT-4o 对数据集中的每篇文章进行了增强。具体来说,我们向 GPT-4o 提供了以下 prompt:
f"""
为这段文本生成一个五到十个单词的主题和一个句子的摘要。 {text} 确保主题简洁,摘要尽可能涵盖主要主题。 请使用以下格式回复: 主题:...
摘要:... 直接回复所需的主题和摘要,不要包含任何其他细节,也不要用引号、反引号或其他分隔符括住您的回复。 """
.strip()
每篇文章按三个换行符(\n\n\n)分割成多个文本块,文本块内部再按两个换行符(\n\n)进行子文本块分割。例如,一篇关于 CGI 的文章会被分割成如下文本块:
[ [ "在计算领域,通用网关接口 ( CGI ) 为 Web 服务器提供了一种标准协议,用于执行像控制台应用程序一样执行的程序 ( 也称为命令行界面程序 ) ,这些程序在服务器上运行,动态生成网页。", "此类程序称为 \"CGI 脚本\" 或简称为 \"CGI\"。", "脚本如何由服务器执行的具体细节由服务器决定。", "通常情况下,CGI 脚本在发出请求时执行并生成 HTML。" ], [ "1993 年,国家超级计算应用中心 ( NCSA ) 团队在 www-talk 邮件列表上编写了调用命令行可执行文件的规范;但是,NCSA 不再托管该规范。", "其他 Web 服务器开发人员采用了它,并且从那时起它就一直是 Web 服务器的标准。", "RFC 中特别提到了以下贡献者: \n1. Alice Johnson\n2. Bob Smith\n3. Carol White\n4. David Nguyen\n5. Eva Brown\n6. Frank Lee\n7. Grace Kim\n8. Henry Carter\n9. Ingrid Martinez\n10. Jack Wilson" ]
然后,我们将原文的文本块、GPT-4 生成的主题和摘要整理成 JSON 格式,方便模型学习。
{ "sections": [ [ "在计算领域,通用网关接口 ( CGI ) 为 Web 服务器提供了一种标准协议,用于执行像控制台应用程序一样执行的程序 ( 也称为命令行界面程序 ) ,这些程序在服务器上运行,动态生成网页。", // ...分割好的章节内容 (上一步骤的结果) ] ], "topics": [ "Web 服务器中的通用网关接口", "CGI 的历史和标准化", // ...其他主题 ], "summaries": [ "CGI 为 Web 服务器提供了一个运行生成动态网页程序的协议。", "NCSA 于 1993 年首次定义了 CGI,随后它成为 Web 服务器的标准..."
, // ...其他摘要 ]
}
接着,我们对数据添加了噪声,包括打乱数据、插入随机字符/单词/字母、随机删除标点符号以及去除所有换行符。
这些数据增强方法虽然有一定效果,但仍有局限性,我们的最终目标是使模型能够生成连贯的文本,并且正确处理代码片段等结构化内容。
所以我们还使用了 GPT-4o 生成代码、公式和列表来进一步丰富数据集,以提升模型处理这些元素的能力。
训练设置
训练模型过程中,我们的设置如下:
- 框架:我们用了 Hugging Face 的
transformers库,还集成了Unsloth来优化模型。这对于优化内存使用和加速训练非常重要,让我们可以用大型数据集高效地训练小型模型。 - 优化器和调度器:我们用了 AdamW 优化器,加上线性学习率调度策略和 warmup 机制,可以帮我们在训练初期稳定训练过程。
- 实验跟踪:我们用 Weights & Biases 跟踪所有训练实验,并记录了训练损失、验证损失、学习率变化、整体模型性能等等关键指标。这种实时追踪可以让我们了解模型的进展情况,在需要时快速调整参数,获得最好的学习效果。
训练过程
我们是用 qwen2-0.5b-instruct 作为基础模型,用 Unsloth 训练了三个 SLM 变体,每个变体对应不同的分块策略。训练数据来自 wiki727k,除了文章全文外,还包含了先前“数据增强”步骤中提取的章节、主题和摘要等信息。
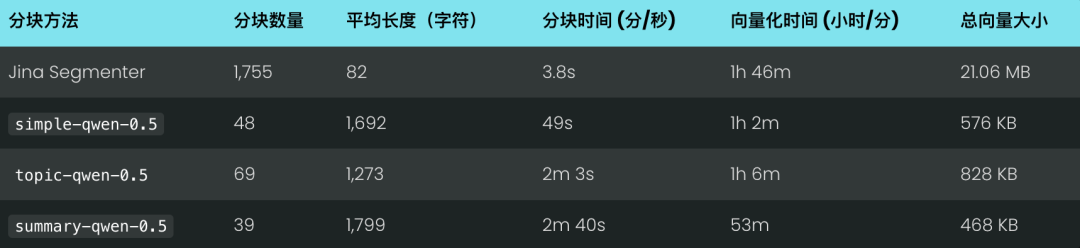
simple-qwen-0.5:我们用了 10,000 个样本,训练了 5,000 步,很快就收敛了,可以有效地检测文本连贯分块之间的边界。训练损失是 0.16。topic-qwen-0.5:跟simple-qwen-0.5类似,我们也用了 10,000 个样本,训练了 5,000 步,训练损失是 0.45。summary-qwen-0.5:我们用了 30,000 个样本,训练了 15,000 步。这个模型很有潜力,但是训练损失比较高(0.81),说明还需要更多数据,大概两倍的原始样本数量才能完全发挥它的实力。
不同分块策略的效果对比
我们来看一下不同分块策略的效果。下面是每种策略生成的三个连续分块示例,还有 Jina 的 Segmenter API 的结果。为了生成这些文本块,我们先用 Jina Reader 从 Jina AI 博客抓取了一篇文章的纯文本(包括页眉、页脚等所有页面数据),然后分别用不同的分块方法处理。
https://jina.ai/news/can-embedding-reranker-models-compare-numbers/
Jina Segmenter API
Jina Segmenter API 的文本分块非常细粒度,它会根据 \n、\t 等字符进行分块,所以切出来的文本块通常都很小。只看前三个分块的话,它从网站的导航栏提取了search\n、notifications\n 和 NEWS\n,但完全没有提取到和文章内容相关的东西:
 再往后,总算能看到一些博客文章的内容了,但每个分块保留的上下文信息都很少:
再往后,总算能看到一些博客文章的内容了,但每个分块保留的上下文信息都很少:
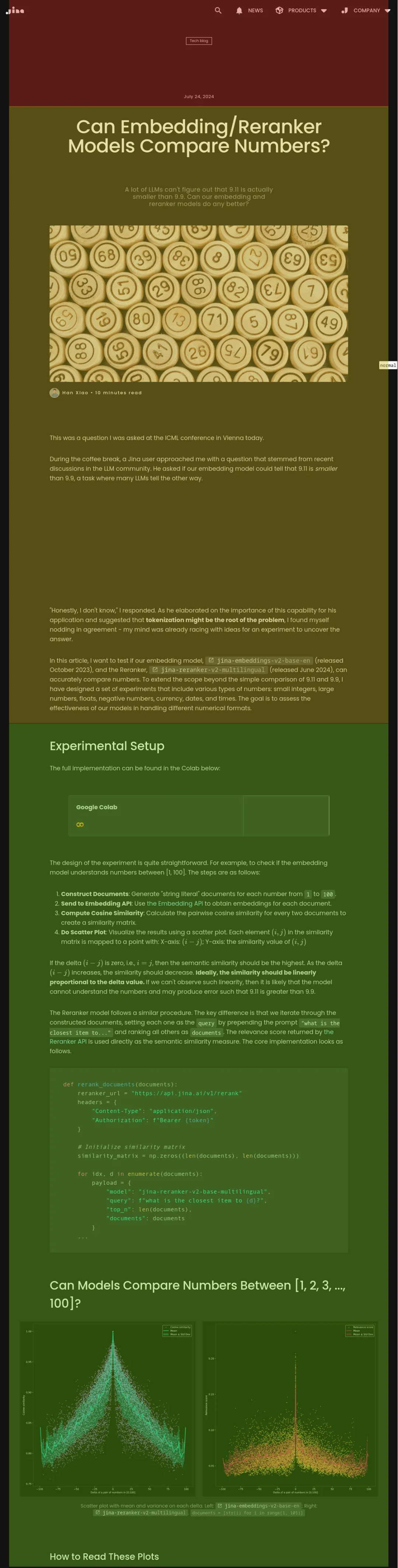
 simple-qwen-0.5
simple-qwen-0.5
simple-qwen-0.5 会根据语义结构把博客文章分成更长的文本块,每个文本块的含义都比较连贯:
 ###
### topic-qwen-0.5
topic-qwen-0.5 会先根据文档内容识别主题,然后再根据这些主题进行分块:
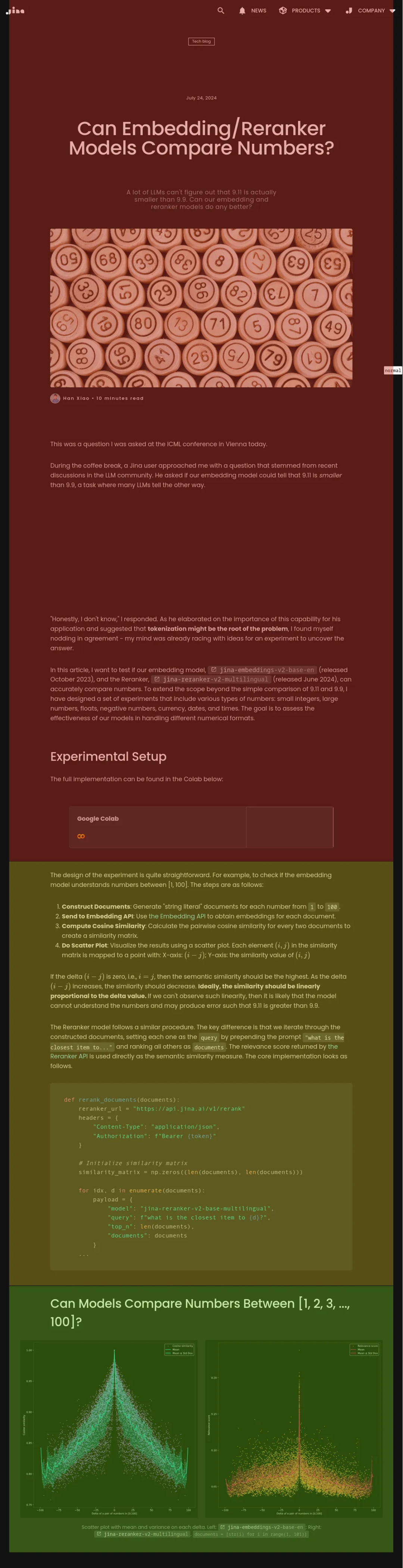 ###
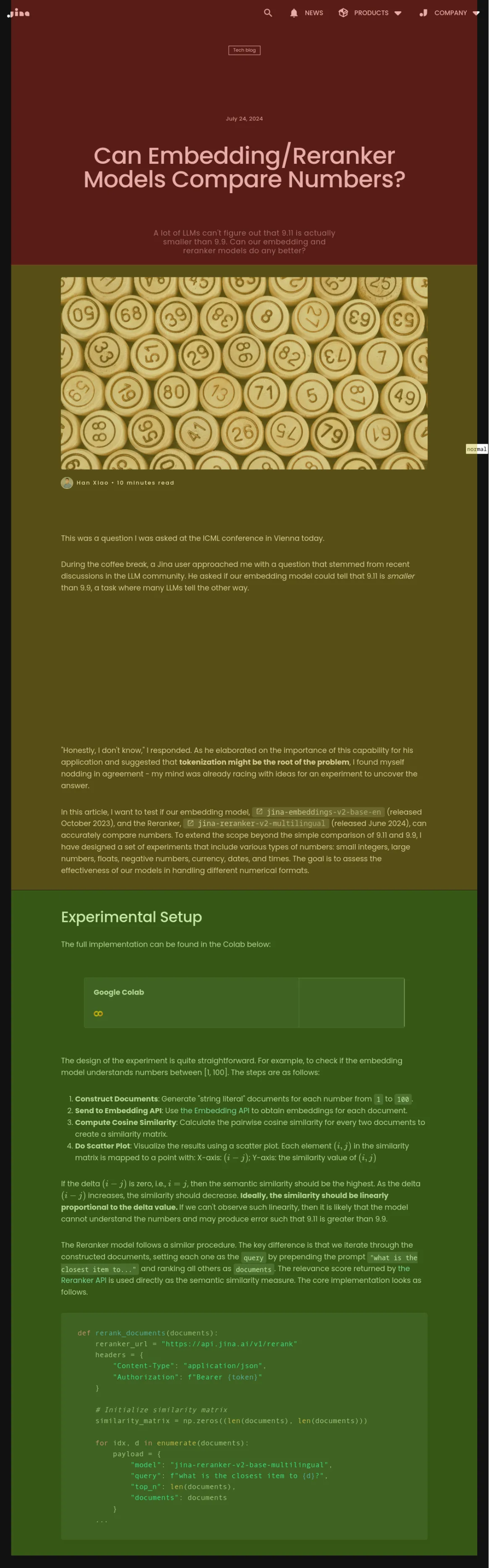
### summary-qwen-0.5
summary-qwen-0.5 不仅能识别文本块边界,还会为每个文本块生成摘要:
 对模型进行基准测试
对模型进行基准测试
为了测试模型的性能,我们使用 Jina AI 博客的 8 篇博文,用 GPT-4o 生成了六个问题和参考答案。
我们把每种分块方法,包括 Jina Segmenter API 都用在了这些博文上,然后用 jina-embeddings-v3 给这些文本块生成向量,没有用迟分或重排序。
然后,我们分别把每组文本块索引起来,用 RAG 系统和之前生成的问题来查询每个索引。
💡 为了公平比较,在测试 topic-qwen-0.5 和 summary-qwen-0.5 的时候,我们只索引了文本块本身,没有索引生成的摘要或主题。如果索引这些额外的数据,性能可能还会提升。
我们用 ROUGE-L 评估的 F1 分数来衡量性能,把每种分块方法生成的答案和参考答案进行比较,分数越高越好。
举个例子,对于问题:“哪些因素会影响 jina-embeddings-v2-base-en 模型的数值比较能力?”,我们得到了以下答案:
参考答案 (GPT-4o 根据完整帖子文本生成):
“两个关键因素是分词和训练数据。分词决定了数字如何分割成 token,而训练数据会影响数值推理能力。”
Jina Segmenter API (分数:0.166667)
“上下文没有提供影响 jina-embeddings-v2-base-en 模型数值比较能力的特定因素。”
simple-qwen-0.5 (分数:0.279070)
“jina-embeddings-v2-base-en 模型的数值比较能力受分词和训练数据的影响。”
topic-qwen-0.5 (分数:0.190476)
“jina-embeddings-v2-base-en 模型的数值比较能力受分词及其处理不同数值格式(包括小整数、大数、浮点数、负数、货币、日期和时间)的能力等因素的影响。”
summary-qwen-0.5 (分数:0.318182)
“影响 jina-embeddings-v2-base-en 模型数值比较能力的因素是分词和训练数据。”
💡 为什么 topic-qwen-0.5 的得分这么低呢?
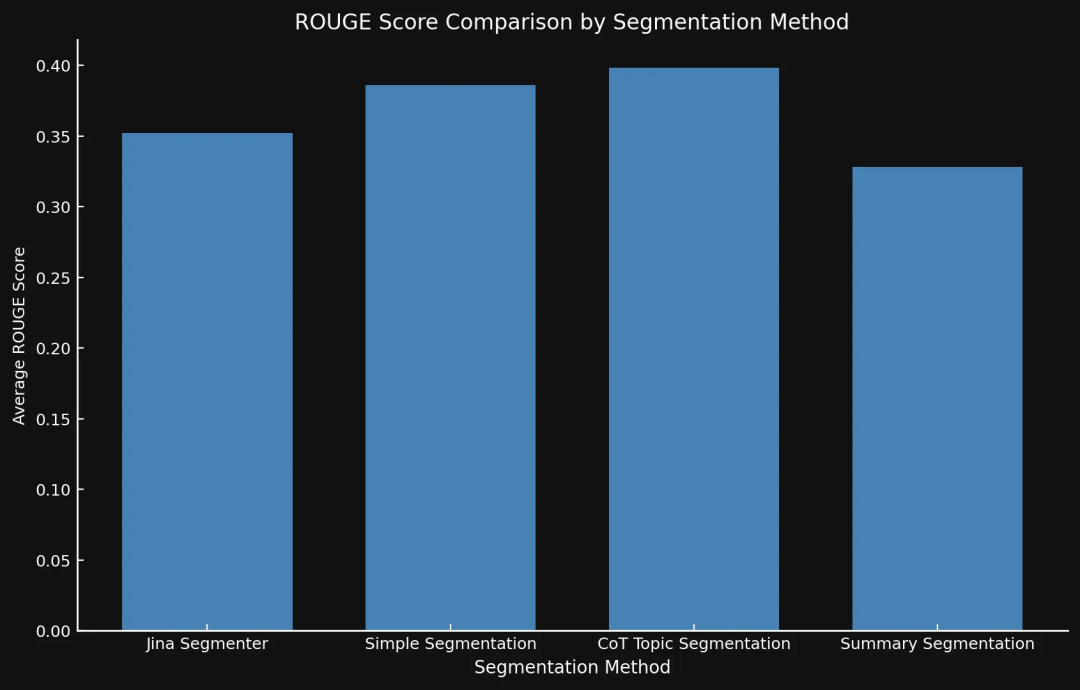
这里因为我们选取的问题比较特殊,是偶然事件。在后面的表格会看到,topic-qwen-0.5 的平均 ROUGE 得分其实是所有方法中最高的。
除了准确性,速度和占用的磁盘空间也很重要。我们测量了生成分块,和向量化文本块的时间来评估速度,然后用向量数量乘以 jina-embeddings-v3的单个 1024 维向量的大小来估算磁盘空间占用。这样就能比较全面地评估不同分块策略的效率了。
主要发现
测试结果表明,新的模型确实比 Jina 的 Segmenter API 效果更好,尤其是主题分块方法:
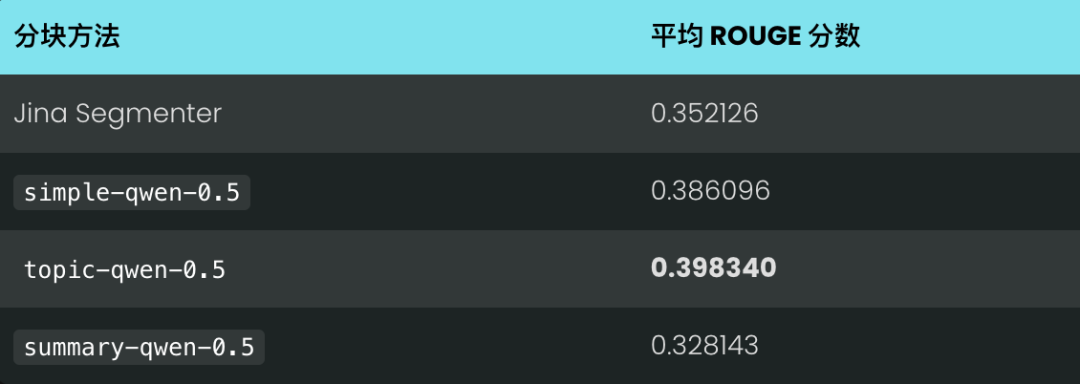 💡
💡 summary-qwen-0.5 的 ROUGE 分数怎么比 topic-qwen-0.5 低呢?简单来说,summary-qwen-0.5 训练时的损失比较高,还需要更多训练数据才能达到更好的效果。这个可以作为以后的研究方向。
另外,用 jina-embeddings-v3 的迟分来改进结果应该也挺有意思的,它可以提高文本块向量的上下文相关性,从而提供更相关的结果。大家感兴趣的话,我们也可以再写一篇相关的文章。
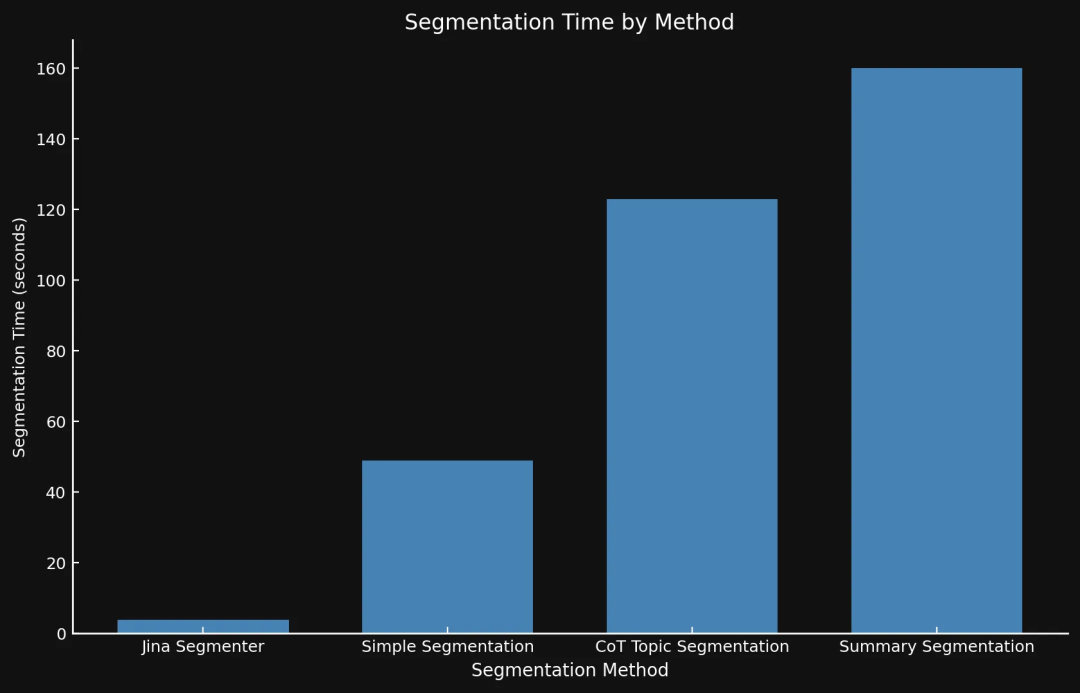
速度方面,很难直接比较。Jina Segmenter 是一个 API,它的分块逻辑比较简单,不依赖 GPU,速度很快。而这三个小模型是跑在 Nvidia 3090 GPU 上,运行速度受 GPU 性能影响。
但虽然 Jina Segmenter 分块速度很快,但是由于它产生的文本块数量太多,导致后续向量化的时间非常长,最终总时间反而比 3 个模型更长。
 💡 备注:
💡 备注:
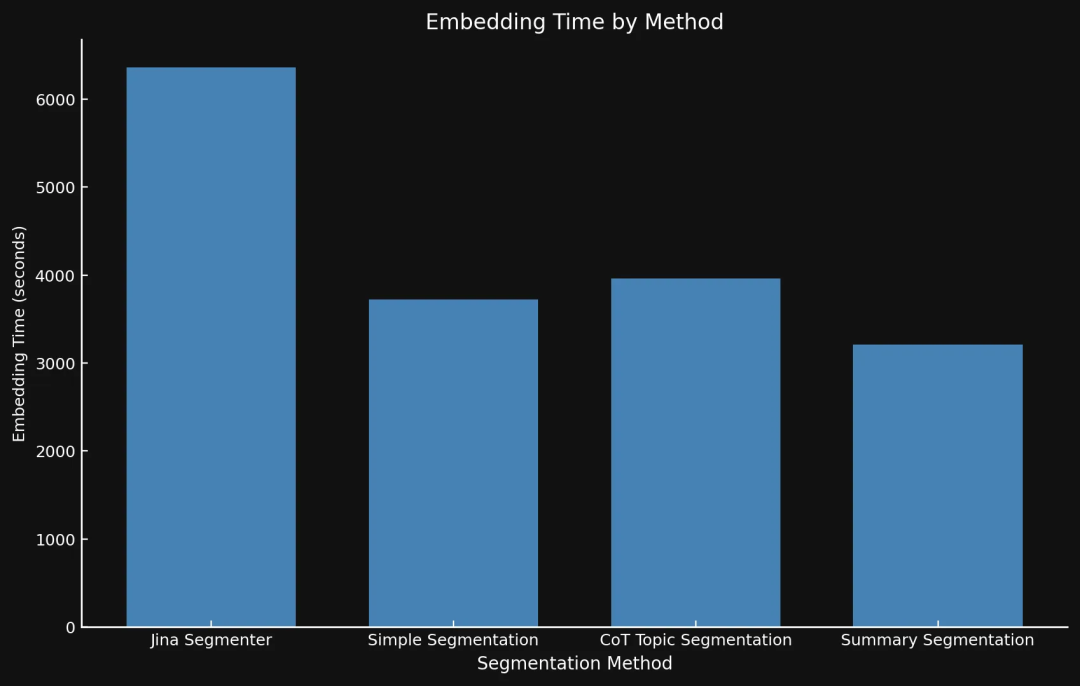
- 这两个图的 Y 轴范围不一样,因为时间差异太大,用同一个范围没法清晰地展示数据。
- 生成向量的时候我们没有用批处理,纯粹是为了实验。如果用批处理的话,所有方法的速度都会大幅提升。
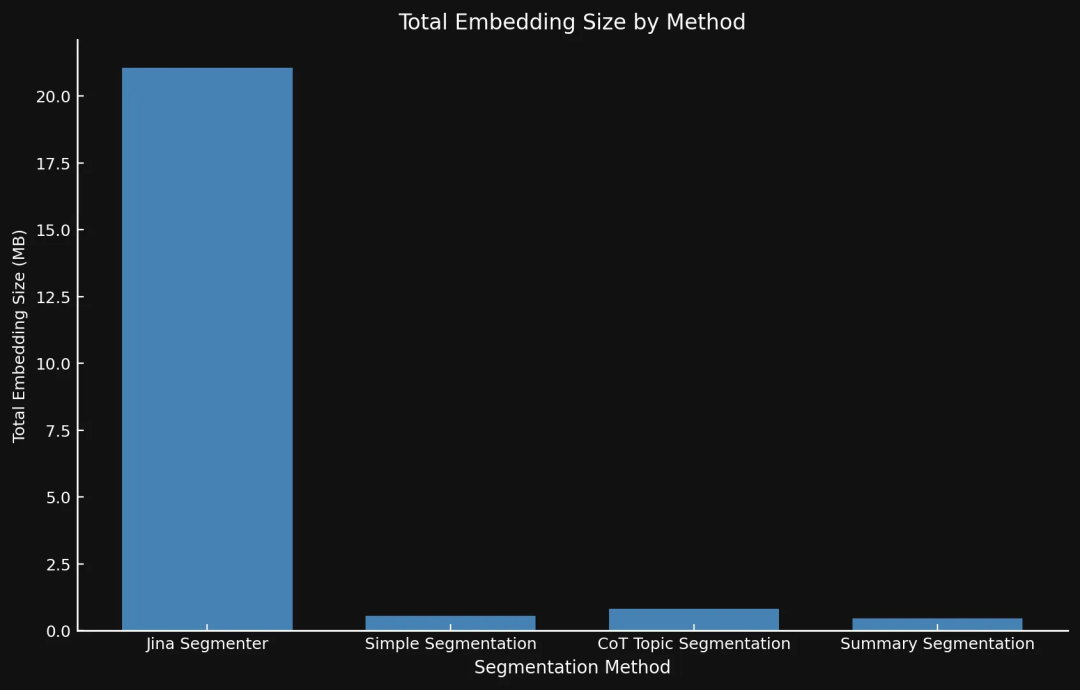
分块越多,向量就越多,占用的空间也就越大:我们测试的 8 篇博文,用 Segmenter API 生成的向量占了 21 MB 多,而 Summary Segmentation 只占了 468 KB。这一点,加上我们模型更高的 ROUGE 分数,说明分块数量少但质量高,既省钱又能提高性能:
 我们学到了什么
我们学到了什么
问题定义要精准
任务的构建方式对最终结果影响很大。让模型只输出文本块头部,而不是整个文本块,这个策略很关键。 因为它让模型更专注于语义转换,而不是简单的复制输入内容,从而提高了边界检测的准确性和分块连贯性。而且,由于生成的文本更少,模型的处理速度也更快了。
让 LLM 生成数据很香
用 LLM 生成的数据来训练模型,效果出奇的好,尤其是在处理列表、公式、代码片段等复杂内容方面。这些数据有效地扩展了模型的训练集,让它能够更好地理解各种文档结构,适应不同的内容类型。这对于处理技术文档或结构化文档至关重要。
Data Collator
在模型训练过程中,data_collator 起了关键作用,我们采用了一种 Output-Only Data Collation 的策略。
通常,语言模型的训练会涉及输入和输出文本。例如,给模型输入一段话,然后让它预测接下来的几个词。在这个项目中,我们只给模型提供目标文本块的关键特征信息(simple-qwen-0.5 模型使用结构元素,topic-qwen-0.5 使用主题,summary-qwen-0.5 使用摘要),并训练它预测这些特征。模型并不会看到原始的输入文本块。
这种方法避免了模型过度拟合输入文本,使其能够更专注于学习分块的本质特征,例如在哪里应该划分边界,如何概括主题等等。这不仅加快了模型的训练速度,使得收敛更快,也提升了模型的泛化能力,使其在面对新的、未见过的文本时也能准确地进行分块。
https://huggingface.co/docs/transformers/en/main_classes/data_collator
Unsloth 训练加速器
多亏了 Unsloth,我们才能在 Nvidia 4090 GPU 上轻松训练这些小型语言模型。这套优化的流程大大简化了训练过程,降低了对计算资源的需求,让我们能够用更少的计算资源,高效地训练出性能优异的模型。
https://github.com/unslothai/unsloth
处理复杂文本
文本分块模型在处理复杂文档,包含代码、表格、列表等方面表现非常出色,这些通常是传统方法的痛点。对于技术内容,像 topic-qwen-0.5 和 summary-qwen-0.5 这样的高级策略效果更好,能够有效增强下游 RAG 任务的性能。
简单内容的简单方法
对于简单的叙事性内容,Segmenter API 这样的简单方法就足够了,没必要用太复杂的策略。这也是我们一贯的原则:实用至上,按需选择,避免过度设计。
https://jina.ai/segmenter/
下一步
虽然这次的实验主要是为了验证我们的想法,如果要更进一步,还有很多可以改进的地方。summary-qwen-0.5 模型挺有潜力的,但目前受限于训练数据量,只用了 3 万样本。如果能用更大的数据集,比如 6 万个样本来训练,效果应该会更好。
另外,基准测试方法也可以改进一下。与其评估 RAG 系统最终生成的答案,不如直接比较检索到的文本块和真实值,这样更能反映分块模型的性能。
最后,评价指标也可以更丰富一些,除了 ROUGE 分数,还可以结合 LLM 评分等更高级的指标,更全面地评估检索和分块质量。
结论
本次实验的核心就是:我们探索了一种全新的基于小型语言模型的分块策略,并且证明了它能够提升 RAG 系统的性能。
传统的分块方法在处理复杂文本结构和保持语义连贯性方面往往力不从心,而我们提出的 simple-qwen-0.5、topic-qwen-0.5 和 summary-qwen-0.5 等模型,正是为了解决这些难题。其中,topic-qwen-0.5 表现最为亮眼,它能够精准地捕捉主题转换,为多主题文档提供语义连贯的分块,让 LLM 更好地理解上下文,从而生成更准确、更相关的答案。
另外,文本分块模型和文章开头提到的迟分是两码事,各有各的优势。分块模型负责把文档切成语义完整的文本块,给后续的生成工作流打好基础;而迟分则专注于优化检索性能,通过维护跨分块的上下文信息来提高检索的精准度。两者虽然目标不同,但可以优势互补,强强联手。不过,如果你更关心的是如何为生成任务提供高质量的、连贯的文档分块,那么分块模型的重要性就更突出了。
总而言之,我们提出的基于小型语言模型的分块策略,为构建更有效、更精准的 RAG 系统提供了一种全新的思路。期待大家的使用反馈!