前期准备
Hadoop-分布式部署(服务全部在线)
Mysql-node1节点部署(确认安装正常)
apache-hive -node1节点部署(需要与MySQL元数据联动存储)
参考博客:
Hadoop
Hadoop集群搭建-完全分布式_hadoop完全分布式搭建-CSDN博客
2024海南省大数据应用技术高校教师培训-Hadoop集群部署_hadoop师资培训-CSDN博客
Mysql
MySQL安装配置-5.7.25版本_mysql5.7.25-CSDN博客
Centos7-rpm包管理器方式安装MySQL 5.7.25及开启root用户远程连接-弱密码登录-CSDN博客
rpm安装MySQL包出现的文件冲突解决_rpm版本冲突-CSDN博客
Apache-Hive
大数据Hive组件安装-元数据库联动Mysql_hadoop hive 安装-CSDN博客
大数据Hive安装与配置_hadoop的hive怎么登陆-CSDN博客
其他组件
Flume安装配置-CSDN博客
Centos7安装sqoop1.4.7超详细教程-CSDN博客
ZooKeeper安装配置--集群模式-CSDN博客
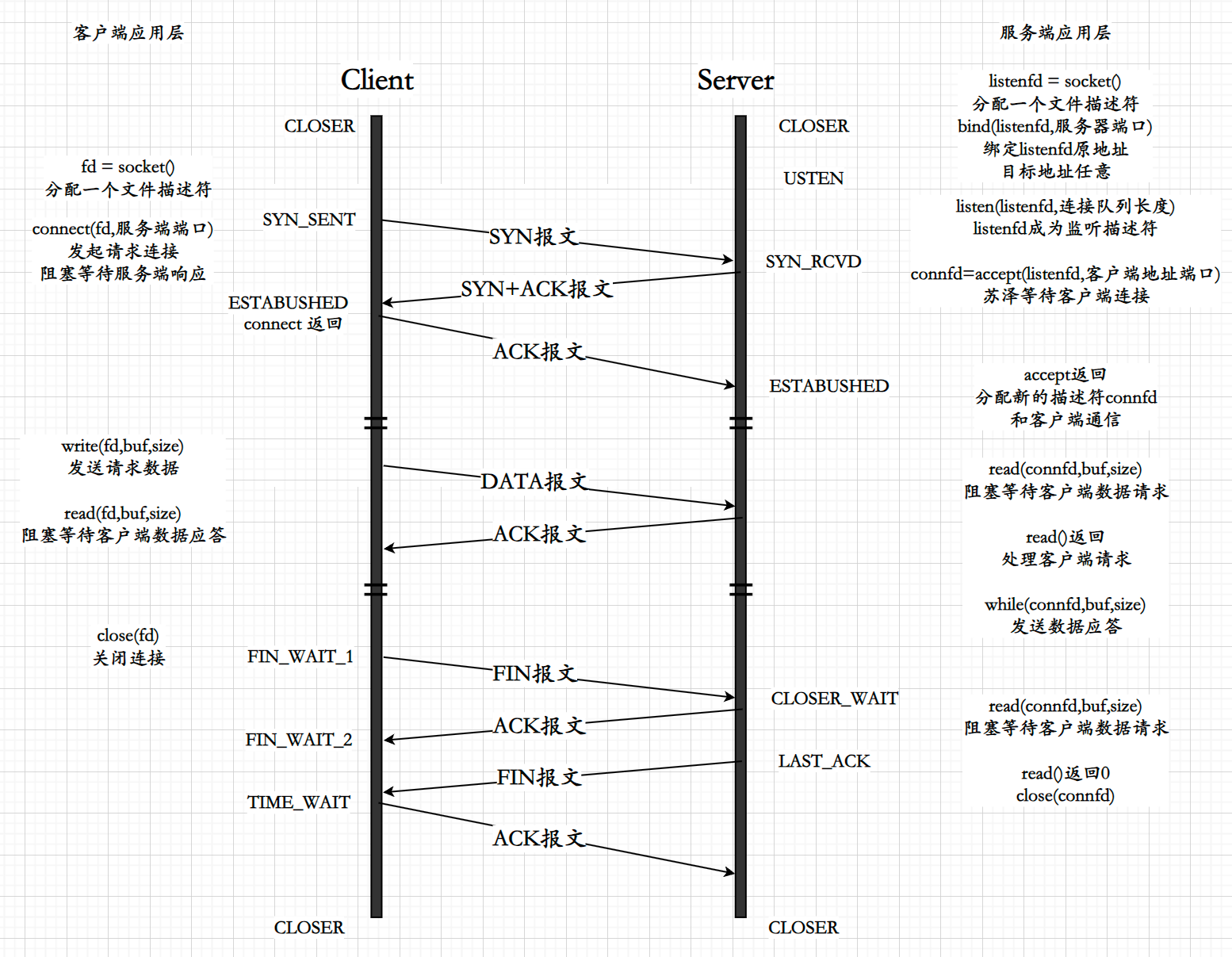
一,基础操作
1,查看/创建/删除hive中的数据库
(1)查看hive中有多少个数据库
SHOW DATABASES;
(2)在hive中创建一个数据库
CREATE DATABASE IF NOT EXISTS test6;IF NOT EXISTS 可以避免在数据库已存在时报错。
test6 是库名

查看是否创建数据库成功
SHOW DATABASES;
创建成功。
(3)删除数据库
DROP DATABASE IF EXISTS test6;
2,查看/创建/删除数据库中的表
(1)进入/使用test数据库
USE test;
(2)查看test数据库中所有的表
SHOW TABLES;
之前测试过创建表,所以OK值下面会有一个表,如果是新的数据库,是没有这个表的,只会返回OK值,如新创建一个test3数据库,进入查看:

(3)创建测试表test_table2
假设给定几个字段,要求在创建表时增加进去:
表名:test_table
字段:时间,国家,省份,性别,联网设备,是否成年
假设数据类型如下:
- 时间:
STRING(也可以根据具体需求设置为TIMESTAMP类型)- 国家:
STRING- 省份:
STRING- 性别:
STRING- 联网设备:
INT(假设该字段记录设备数量)- 是否成年:
BOOLEAN- 假设表的存储格式为
ORC,示例如下:
CREATE TABLE IF NOT EXISTS test_table2 (`time` STRING,country STRING,province STRING,gender STRING,devices INT,is_adult BOOLEAN
)
STORED AS ORC;
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',':指定以逗号作为字段分隔符。STORED AS ORC:指定使用 ORC 格式存储数据。如果需要其他格式或者分隔符,可以进行相应调整。

查看是否创建成功
SHOW TABLES;
(4)删除测试表test_table2
DROP TABLE IF EXISTS test_table2;
查看是否删除完成
SHOW TABLES;
完成。
3,查看/增加/删除表中字段
(1)查看表结构
DESCRIBE test_table;
可以看到表中有一个字段time_column,类型为string
查看详细结构信息
DESCRIBE FORMATTD test_table;
(2)增加表中数据
举例:
在test_table表中增加邮箱字段。
ALTER TABLE test_table ADD COLUMNS (email STRING COMMENT 'Email Address');
查看
DESCRIBE FORMATTD test_table;
增加成功。
(3)修改表中字段。
示例:
把test_table表中的email字段改为email_table2,类型string不变。
ALTER TABLE test_table CHANGE email email_table2 STRING;
(4)删除表中字段
Hive 不支持直接删除字段,可以通过以下方式实现:
- 创建一个新的表,不包括需要删除的字段。
- 将原表中的数据插入到新的表中。
- 删除原表,并将新表重命名为原表名。
示例:
1. 创建新表,保留所需字段:time_column, email_table2
CREATE TABLE test3_table AS
SELECT time_column, email_table2
FROM test_table;

查看是否执行完成:
SHOW TABLES;
执行日志:
hive> CREATE TABLE test3_table AS> SELECT time_column, email_table2> FROM test_table;
2024-11-05T23:08:44,344 INFO [main] org.apache.hadoop.hive.conf.HiveConf - Using the default value passed in for log id: a0e610d6-9cab-473f-b04f-f539de818377
2024-11-05T23:08:44,344 INFO [main] org.apache.hadoop.hive.ql.session.SessionState - Updating thread name to a0e610d6-9cab-473f-b04f-f539de818377 main
2024-11-05T23:08:44,520 INFO [a0e610d6-9cab-473f-b04f-f539de818377 main] org.apache.hadoop.hive.common.FileUtils - Creating directory if it doesn't exist: hdfs://node1:8020/user/hive/warehouse/test.db/.hive-staging_hive_2024-11-05_23-08-44_402_1029558810549486972-1
Query ID = root_20241105230844_1f4afcb5-d5fb-4057-a42a-c36597c03a35
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
2024-11-05T23:08:47,405 INFO [a0e610d6-9cab-473f-b04f-f539de818377 main] org.apache.hadoop.conf.Configuration.deprecation - mapred.submit.replication is deprecated. Instead, use mapreduce.client.submit.file.replication
2024-11-05T23:09:38,078 INFO [a0e610d6-9cab-473f-b04f-f539de818377 main] org.apache.hadoop.conf.Configuration.deprecation - yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
2024-11-05T23:09:40,426 INFO [a0e610d6-9cab-473f-b04f-f539de818377 main] org.apache.hadoop.conf.Configuration - resource-types.xml not found
Starting Job = job_1730818870875_0001, Tracking URL = http://node1:8088/proxy/application_1730818870875_0001/
Kill Command = /export/server/hadoop-3.3.0/bin/mapred job -kill job_1730818870875_0001
Hadoop job information for Stage-1: number of mappers: 0; number of reducers: 0
2024-11-05 23:10:24,063 Stage-1 map = 0%, reduce = 0%
Ended Job = job_1730818870875_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://node1:8020/user/hive/warehouse/test.db/.hive-staging_hive_2024-11-05_23-08-44_402_1029558810549486972-1/-ext-10002
Moving data to directory hdfs://node1:8020/user/hive/warehouse/test.db/test3_table
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 0 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
Time taken: 109.25 seconds
2024-11-05T23:10:33,809 INFO [a0e610d6-9cab-473f-b04f-f539de818377 main] org.apache.hadoop.hive.conf.HiveConf - Using the default value passed in for log id: a0e610d6-9cab-473f-b04f-f539de818377
2024-11-05T23:10:33,809 INFO [a0e610d6-9cab-473f-b04f-f539de818377 main] org.apache.hadoop.hive.ql.session.SessionState - Resetting thread name to main
hive>
2,删除原表
DROP TABLE test_table;
3. 将新表test3_table重命名为原表名test5_table
ALTER TABLE test3_table RENAME TO test5_table;
增删改的注意事项
- 如果表中的数据量非常大,重建表的方式可能会花费较多的资源和时间。
- 执行删除操作前,最好备份数据,确保数据安全。
(5)查看表中字段下的数据
以随机一个数据文件做演示
列出全部字段及记录
语句会返回hyxx_table表的全部记录,包含所有字段的信息
hive> SELECT *> FROM hyxx_table> LIMIT ;
列出表中所有字段和前10条记录
以下语句会返回hyxx_table表的前10条记录,包含所有字段的信息
SELECT *
FROM hyxx_table
LIMIT 10;
列出特定字段的前10条记录
在Hive中,可以使用
SELECT语句来查看特定字段的数据。假设要查看hyxx_table表中某些字段的内容,例如查看会员卡号、会员等级和注册时间,可以使用以下SQL语句:
SELECT member_card_number, member_level, registration_time
FROM hyxx_table
LIMIT 10;

二,进阶操作
1. 分区(Partition)管理
分区是Hive提高查询效率的重要机制。它将数据按指定列(如日期)划分到不同的目录中,从而加速数据查询。
创建分区表
示例:
创建一个分区表,字段为id INT,name STRING ,year INT,month INT
CREATE TABLE partitioned_table (id INT,name STRING
) PARTITIONED BY (year INT, month INT);

查看

添加分区
ALTER TABLE partitioned_table ADD PARTITION (year=2024,month=10);
查询分区
SELECT * FROM partitioned_table WHERE year = 2024 AND month = 10;

删除分区
ALTER TABLE partitioned_table DROP PARTITION (year=2024, month=10);
2. 桶(Bucketing)管理
桶将数据分散到多个文件中,以提高查询性能,尤其是当你需要按某个列进行散列分布时。桶可以配合分区使用。
创建桶表
CREATE TABLE bucketed_table (id INT,name STRING
) CLUSTERED BY (id) INTO 4 BUCKETS;
查看

查询桶表
SELECT * FROM bucketed_table;
3. 视图(View)
视图是一个虚拟的表,它并不存储数据,而是存储查询定义。通过视图,可以简化复杂查询的执行。
创建视图
CREATE VIEW view_name AS
SELECT id, name FROM partitioned_table WHERE year = 2024;

查询视图
SELECT *FROM view_name;
查看

删除视图
DROP VIEW view_name;
4. 外部表(External Table)
外部表指的是数据存储在外部文件系统中(如HDFS、S3等),Hive不会管理数据的生命周期。它适用于数据频繁更新的场景。
创建外部表
示例,这里的外部表存储在hdfs的tmp目录下,数据接口:hdfs://node1:8020/tmp/
CREATE EXTERNAL TABLE external_table (
id INT,
name STRING
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION 'hdfs://node1:8020/tmp/';

查看外部表
SHOW TABLES;
查看表结构/细节
DESCRIBE FORMATTED external_table;
删除外部表
DROP TABLE external_table;
5. 窗口函数(Window Functions)
窗口函数允许你在查询结果的某些行之间执行计算,而无需使用GROUP BY。常见的窗口函数有
ROW_NUMBER()、RANK()、LEAD()、LAG()等。示例:使用
ROW_NUMBER()对每个分组进行排序
SELECT id, name, ROW_NUMBER() OVER (PARTITION BY year ORDER BY id) AS row_num
FROM partitioned_table;
6. JOIN操作
Hive支持各种类型的JOIN操作,包括内连接(INNER JOIN)、左连接(LEFT JOIN)、右连接(RIGHT JOIN)、全连接(FULL OUTER JOIN)等。
示例:内连接(INNER JOIN)
SELECT a.id, a.name, b.department
FROM employees a
JOIN departments b
ON a.department_id = b.id;
示例:左连接(LEFT JOIN)
SELECT a.id, a.name, b.department
FROM employees a
LEFT JOIN departments b
ON a.department_id = b.id;
7. 子查询(Subqueries)
Hive也支持在
SELECT、WHERE和FROM等子句中使用子查询。
示例:在SELECT中使用子查询
SELECT id, name,(SELECT MAX(salary) FROM salary_table WHERE employee_id = employees.id) AS max_salary
FROM employees;
示例:在WHERE中使用子查询
SELECT * FROM employees
WHERE department_id IN (SELECT id FROM departments WHERE name = 'Engineering');
8. 用户定义函数(UDF)
Hive支持用户定义函数(UDF),允许你使用自定义的Java代码扩展Hive的功能。通过UDF可以处理一些标准SQL不支持的操作。
注册UDF
ADD JAR /path/to/udf.jar;
CREATE TEMPORARY FUNCTION my_udf AS 'com.example.MyUDF';
使用UDF
SELECT my_udf(column_name) FROM table_name;
9. 事务支持
Hive从0.13版本开始支持ACID(原子性、一致性、隔离性和持久性)事务,但仅适用于支持ORC格式的表。
创建支持事务的表
CREATE TABLE transaction_table (id INT,name STRING
) STORED AS ORC TBLPROPERTIES ('transactional'='true');
启用事务
SET hive.support.concurrency=true;
SET hive.enforce.bucketing=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
10. 数据导入与导出
Hive支持将数据导入和导出到各种存储系统中,例如HDFS、Local File System、Amazon S3等。
从本地文件系统导入数据
hyxx.txt数据集为随机生成,内容为:
会员卡号 会员等级 会员来源 注册时间 所属店铺编码 性别 生日 年齡 生命级别
BL6099033963550303769 黄金会员 线下扫码 2019-03-31 DPXX07 女 1975-04-04 43 活跃
BL6099033963450303763 黄金会员 线下扫码 2019-03-31 DPXX07 女 1982-04-02 36 活跃
BL6099033963464003767 白银会员 电商入口 2019-03-31 DPS00X 女 1988-08-13 30 沉睡
BL6099033963460503766 黄金会员 线下扫码 2019-03-31 DPXX07 女 1993-11-24 25 活跃
BL6099033963660603765 白银会员 电商入口 2019-03-31 DPS00X 女 1993-03-20 26 沉睡
BL6099033963659903764 白银会员 电商入口 2019-03-31 DPS00X 女 1985-04-19 33 沉睡
BL6099033963636603763 黄金会员 线下扫码 2019-03-31 DPXX07 女 1976-02-26 43 活跃
BL6099033963696903766 白银会员 电商入口 2019-03-31 DPS00X 女 2000-02-18 19 沉睡
BL6099033963970603760 白银会员 电商入口 2019-03-31 DPS00X 女 1992-10-20 26 沉睡
BL6099033963950603759 白银会员 电商入口 2019-03-31 DPS00X 男 1984-10-30 34 沉睡
BL6099033963039603755 黄金会员 线下扫码 2019-03-31 DPXX07 女 2000-02-07 19 活跃
BL6099033963040903756 白银会员 线下扫码 2019-03-31 DPX780 女 1984-05-09 34 沉睡
BL6099033963034603759 白银会员 线下扫码 2019-03-31 DPXX07 女 1978-11-25 40 活跃
BL6099033963033403750 白银会员 线下扫码 2019-03-31 DPJ0X3 女 1970-01-01 49 沉睡
BL6099033963099603743 黄金会员 线下扫码 2019-03-31 DPXX07 女 1984-08-10 34 活跃
BL6099033966590603746 白银会员 线下扫码 2019-03-31 DPXX07 女 1978-04-22 40 活跃
BL6099033966569403743 白银会员 电商入口 2019-03-31 DPS00X 女 1983-11-29 35 沉睡
BL6099033966555303746 白银会员 线下扫码 2019-03-31 DPXX07 女 1980-04-06 38 活跃
BL6099033966534503739 黄金会员 线下扫码 2019-03-31 DPXX07 女 1979-09-06 39 活跃
BL6099033966599303735 白银会员 电商入口 2019-03-31 DPS00X 女 1983-03-07 36 沉睡
BL6099033966470003736 白银会员 线下扫码 2019-03-31 DPXX07 女 1990-09-22 28 活跃
BL6099033966456903739 白银会员 电商入口 2019-03-31 DPS00X 女 1985-04-04 33 沉睡
BL6099033966459903730 白银会员 电商入口 2019-03-31 DPS00X 女 1991-08-24 27 沉睡
BL6099033966459503769 白银会员 电商入口 2019-03-31 DPS00X 女 1969-03-09 50 沉睡
BL6099033966445003763 白银会员 电商入口 2019-03-31 DPS00X 女 1995-04-06 23 沉睡
BL6099033966444503767 白银会员 线下扫码 2019-03-31 DPXX07 女 1979-09-02 39 活跃
BL6099033966466903766 黄金会员 线下扫码 2019-03-31 DPXX07 女 1974-01-01 45 活跃
将txt数据文件上传到root目录

如果没有对应的表,需要创建对应的hyxx_table表
CREATE TABLE hyxx_table (member_card_number STRING, -- 会员卡号member_level STRING, -- 会员等级member_source STRING, -- 会员来源registration_time TIMESTAMP, -- 注册时间store_code STRING, -- 所属店铺编码gender STRING, -- 性别 (建议使用 'M' 或 'F' 表示性别)birthday DATE, -- 生日age INT, -- 年龄life_level STRING -- 生命级别
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t' -- 假设字段使用制表符分隔
STORED AS TEXTFILE;
字段说明
member_card_number: 会员卡号,使用STRING类型,可以存储各种字符组合。member_level: 会员等级,使用STRING类型,可存储如"普通会员"、"VIP"等。member_source: 会员来源,STRING类型,例如"线上"、"线下"等。registration_time: 注册时间,TIMESTAMP类型,存储年-月-日 时:分:秒。store_code: 所属店铺编码,STRING类型,用于存储各店铺的唯一标识。gender: 性别,使用STRING类型,通常用"M"或"F"标识。birthday: 生日,使用DATE类型。age: 年龄,使用INT类型。life_level: 生命级别,使用STRING类型。创建完成后,可以使用
LOAD DATA命令将数据加载到表中。

查看表中字段

然后从本地文件系统/root目录下导入数据
LOAD DATA LOCAL INPATH '/root/hyxx.txt' INTO TABLE hyxx_table;
查看字段下的数据
在Hive中,可以使用
SELECT语句来查看特定字段的数据。假设要查看hyxx_table表中某些字段的内容,例如查看会员卡号、会员等级和注册时间,可以使用以下SQL语句:
SELECT member_card_number, member_level, registration_time
FROM hyxx_table
LIMIT 10;
解释
SELECT: 用于选择指定的字段。member_card_number, member_level, registration_time: 这些是要查看的字段名称。LIMIT 10: 限制返回的记录数为10条,以避免查询过多数据(可以根据需要调整或去掉此部分)。
示例
如果需要查看全部字段的数据,可以用
*表示:
SELECT *
FROM hyxx_table
LIMIT 10;
以上语句会返回hyxx_table表的前10条记录,包含所有字段的信息。
如果需要列出全部记录,不用加上数值即可。
SELECT *
FROM hyxx_table
LIMIT ;
从HDFS导入数据
先上传hyxx.txt文件到hdfs中。
hadoop fs -put hyxx.txt /hive_tables/

上传完成,查看

hyxx_table2表跟hyxx_table表中的字段内容相同,仅更名
LOAD DATA INPATH '/hive_tables/hyxx.txt' INTO TABLE hyxx_table2;

导入hive后hdfs中的数据文件会消失,属于正常现象,查看导入的表的字段下的数据,存在即可

查看表下字段中的数据

查看表中字段

查看字段下的数据

正常
导出数据到本地文件系统
INSERT OVERWRITE LOCAL DIRECTORY '/root/hive_data'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
SELECT * FROM hyxx_table2;

执行日志:
hive> INSERT OVERWRITE LOCAL DIRECTORY '/root/hive_data'> ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' > SELECT * FROM hyxx_table2;
2024-11-06T01:41:59,210 INFO [main] org.apache.hadoop.hive.conf.HiveConf - Using the default value passed in for log id: dba1e2f5-60c0-4488-8b37-57d7d6c1c38c
2024-11-06T01:41:59,211 INFO [main] org.apache.hadoop.hive.ql.session.SessionState - Updating thread name to dba1e2f5-60c0-4488-8b37-57d7d6c1c38c main
2024-11-06T01:42:02,734 INFO [dba1e2f5-60c0-4488-8b37-57d7d6c1c38c main] org.apache.hadoop.hive.common.FileUtils - Creating directory if it doesn't exist: hdfs://node1:8020/root/hive_data/.hive-staging_hive_2024-11-06_01-41-59_264_4655809944502720066-1
Query ID = root_20241106014159_a28aceb5-a14f-433a-9fe6-b79120211fd2
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
2024-11-06T01:42:05,017 INFO [dba1e2f5-60c0-4488-8b37-57d7d6c1c38c main] org.apache.hadoop.conf.Configuration.deprecation - mapred.submit.replication is deprecated. Instead, use mapreduce.client.submit.file.replication
2024-11-06T01:42:50,376 INFO [dba1e2f5-60c0-4488-8b37-57d7d6c1c38c main] org.apache.hadoop.conf.Configuration.deprecation - yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
2024-11-06T01:42:52,378 INFO [dba1e2f5-60c0-4488-8b37-57d7d6c1c38c main] org.apache.hadoop.conf.Configuration - resource-types.xml not found
Starting Job = job_1730818870875_0002, Tracking URL = http://node1:8088/proxy/application_1730818870875_0002/
Kill Command = /export/server/hadoop-3.3.0/bin/mapred job -kill job_1730818870875_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2024-11-06 01:43:33,360 Stage-1 map = 0%, reduce = 0%
2024-11-06 01:44:32,141 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 19.91 sec
MapReduce Total cumulative CPU time: 19 seconds 910 msec
Ended Job = job_1730818870875_0002
Moving data to local directory /root/hive_data
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 19.91 sec HDFS Read: 8770 HDFS Write: 2035 SUCCESS
Total MapReduce CPU Time Spent: 19 seconds 910 msec
OK
Time taken: 155.654 seconds
2024-11-06T01:44:34,888 INFO [dba1e2f5-60c0-4488-8b37-57d7d6c1c38c main] org.apache.hadoop.hive.conf.HiveConf - Using the default value passed in for log id: dba1e2f5-60c0-4488-8b37-57d7d6c1c38c
2024-11-06T01:44:34,889 INFO [dba1e2f5-60c0-4488-8b37-57d7d6c1c38c main] org.apache.hadoop.hive.ql.session.SessionState - Resetting thread name to main
hive>
查看本地目录

导出数据到本地文件系统完成。
Hive的进阶操作包括分区、桶、视图、外部表、窗口函数、JOIN、子查询、UDF、事务支持以及数据导入导出等。这些操作可以帮助你在大数据环境中高效处理复杂的数据分析任务。通过灵活运用这些功能,你可以显著提高查询性能并简化数据处理工作。