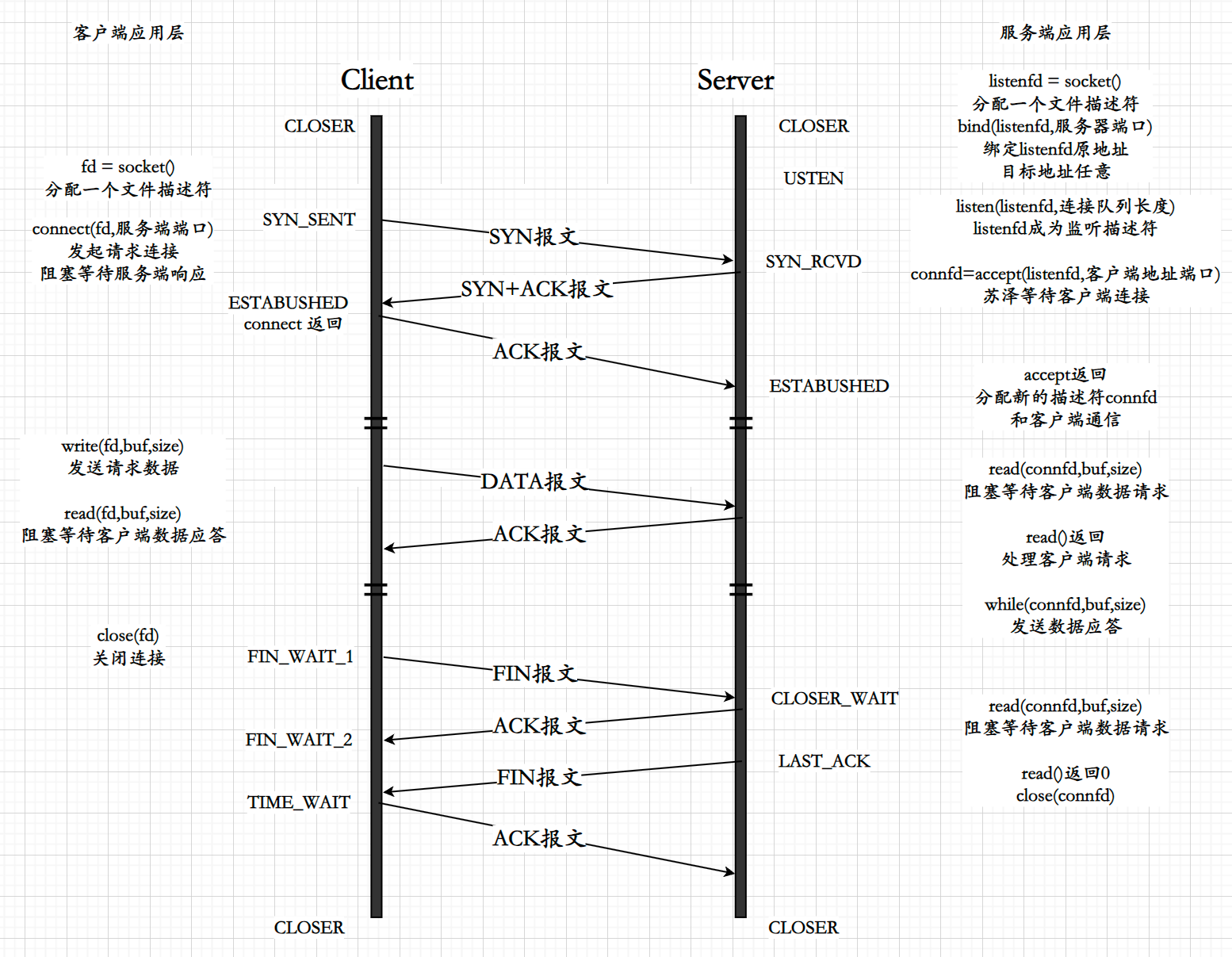
U-Net是继FCN之后又一个经典的语义分割网络模型,并且也是很多后续语义分割模型的“祖宗”。这个网络模型是2015年提出来的,它具有一个非常对称的结构,很像字母“U”,所以被称作U-Net。U-Net被广泛应用于医学影像领域,如分割器官、肿瘤、血管等。由于医学图像通常具有复杂的结构和较高的分辨率要求,U-Net 的结构特点使其能够有效地处理这些图像,并提供准确的分割结果,为医学诊断和治疗提供重要的支持,在遥感卫星分析和工业质量检测中也有广泛的应用。U-Net相比于FCN,它对于细节的把控能力更强。U-Net总体结构如下:

和FCN一样,它也分成了编码和解码模块两部分,编码模块也被称作下采样,解码模块也被称作上采样。
1.输入572x572,经过3x3卷积和ReLU,大小变为570x570。(卷积计算公示:output = (input-kernel_size+2*padding)/stride + 1),再做一次卷积和ReLU,大小变为568x568,通道数变成64;
2.经过最大池化层,长宽变为原来的一半,变成284x284,经过两次卷积和ReLU,大小变成280x280,通道数变成128;
3.再次经过最大池化层,长宽变为原来的一半,变成140下140,再经过两次卷积和ReLU,大小变成136x136,通道数加倍变成256;
4.再次经过最大池化层,长宽继续减半,变成68x68,再经过两次卷积和ReLU,大小变成64x64,通道数变成512;
5.再次经过最大池化层,长宽继续减半,变成32x32,再经过两次卷积和ReLU,大小变成28x28,通道数变成1024;
6.此处开始上采样。经过2x2上采样,长宽变成原来的两倍,56x56,同时通道数减半,变成512;
7.从下采样过程中的512x64x64结果中,裁剪512x56x56的部分,和上采样后得到的512x56x56结果,进行通道维度上的拼接,注意不是求和是拼接concat,得到1024x56x56的结果,再做一次卷积和ReLU,通道数减半,变成512x54x54,再做一次卷积和ReLU,这次通道数保持不变,大小变成了52x52,所以这一层最终输出512x52x52;
8.上采样,通道数进一步减小变成256x256,长宽再变大一倍,得到256x104x104,和下采样过程中通道是256x136x136的部分拼接,因为长宽不同,所以需要裁剪,将下采样过程中的结果裁剪成256x104x104,按通道维度拼接,得到512x104x104,再经过卷积和ReLU,通道数减半,变成256x102x102,再经过卷积和ReLU,得到256x100x100;
9.上采样,通道数进一步减半变成128x128,长宽再变大一倍,得到128x200x200,和下采样过程中通道是128的部分拼接,裁剪成200x200大小后,按通道维度拼接,得到256x200x200,经过卷积和ReLU,通道数减半,得到128x198x198,再经过一次卷积和ReLU,通道不变,得到128x196x196;
10.上采样,通道数进一步减半变成64x64,长宽再变大一倍,得到64x392x392,和下采样过程中通道是64的部分拼接,裁剪成392x392大小后,按通道维度拼接,得到128x392x392,经过卷积和ReLU,通道数减半,得到64x390x390,再经过一次卷积和ReLU,通道不变,得到64x388x388,最后经过一次1x1卷积,改变通道数为2,得到2x388x388,也就是最终的输出。论文最终输出是分成了两类。
不过这里有一个问题,就是输入图像的大小和输出的大小是不一致的。输入是572X572的图像,输出的结果是388X388的,当然在医学影像中可能是无所谓的,不过在大部分的语义分割场景,最好还是使得输入图像和输出结果的大小是一致的,大部分的语义分割数据集,如VOC2012的图像和标签大小也是一直的,所以我们最好使得输入和输出大小一致。
U-Net的简单实现如下:
import torch.nn as nn
import torchvision.models as models
import torchclass UNetEncoder(nn.Module):def __init__(self, pretrained=True) -> None:super(UNetEncoder, self).__init__()vgg = models.vgg16(pretrained=pretrained)self.encoder = nn.Sequential(*list(vgg.children())[:-2])self.layer1 = nn.Sequential(vgg.features[:4])self.layer2 = nn.Sequential(vgg.features[4:9])self.layer3 = nn.Sequential(vgg.features[9:16])self.layer4 = nn.Sequential(vgg.features[16:23])self.layer5 = nn.Sequential(vgg.features[23:-1])def forward(self, x):features = []x = self.layer1(x)print("x.shape: ",x.shape)features.append(x)x = self.layer2(x)print("x.shape: ",x.shape)features.append(x)x = self.layer3(x)print("x.shape: ",x.shape)features.append(x)x = self.layer4(x)print("x.shape: ",x.shape)features.append(x)x = self.layer5(x)print("x.shape: ",x.shape)features.append(x)return featuresclass UNetDecoder(nn.Module):def __init__(self, num_classes) -> None:super(UNetDecoder, self).__init__()# 定义解码器层self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)self.conv1 = nn.Conv2d(in_channels=1024, out_channels=512, kernel_size=3, padding=1)self.conv2 = nn.Conv2d(in_channels=768, out_channels=256, kernel_size=3, padding=1)self.conv3 = nn.Conv2d(in_channels=384, out_channels=128, kernel_size=3, padding=1)self.conv4 = nn.Conv2d(in_channels=192, out_channels=64, kernel_size=3, padding=1)self.classifier = nn.Conv2d(in_channels=64, out_channels=num_classes, kernel_size=1)def forward(self, features):x5 = features[-1] # 最后一层编码的结果print("x5.shape: ",x5.shape)x4 = self.upsample(x5)x4 = torch.cat([x4, features[-2]], dim=1) # 根据通道维度进行合并,第0维是batch_sizex4 = self.conv1(x4)print("x4.shape: ",x4.shape)x3 = self.upsample(x4)x3 = torch.cat([x3, features[-3]], dim=1)x3 = self.conv2(x3)print("x3.shape: ",x3.shape)x2 = self.upsample(x3)x2 = torch.cat([x2, features[-4]], dim=1)x2 = self.conv3(x2)print("x2.shape: ",x2.shape)x1 = self.upsample(x2)x1 = torch.cat([x1, features[-5]], dim=1)x1 = self.conv4(x1)print("x1.shape: ",x1.shape)out = self.classifier(x1)return outclass UNet(nn.Module):def __init__(self, num_classes, pretrained=True):super(UNet, self).__init__()self.encoder = UNetEncoder(pretrained=pretrained)self.decoder = UNetDecoder(num_classes)def forward(self, x):features = self.encoder(x)out = self.decoder(features)return outif __name__ == '__main__':model = UNet(num_classes=21, pretrained=True)x = torch.randn(1, 3, 480, 320)out = model(x)print(out.shape)
# 输出:
x.shape: torch.Size([1, 64, 480, 320])
x.shape: torch.Size([1, 128, 240, 160])
x.shape: torch.Size([1, 256, 120, 80])
x.shape: torch.Size([1, 512, 60, 40])
x.shape: torch.Size([1, 512, 30, 20])
x5.shape: torch.Size([1, 512, 30, 20])
x4.shape: torch.Size([1, 512, 60, 40])
x3.shape: torch.Size([1, 256, 120, 80])
x2.shape: torch.Size([1, 128, 240, 160])
x1.shape: torch.Size([1, 64, 480, 320])
torch.Size([1, 21, 480, 320])可以看到,输入是四维的数据,batch_size=1,三通道的彩色图像,宽480,高320的一幅图像,输出batch_size=1,通道数21,用来分类,宽480,高320的分割结果图像。
整个U-Net代码分为编码器Encoder和解码器Decoder。Encoder就是下采样模块,采用预训练的vgg模型的特征提取模块。Decoder就是上采样模块,把特征图不断恢复为原始图像大小,并在整个过程中,按通道维度拼接特征提取过程中的特征图。
根据输出可以看到图像的变换过程,如下图所示:

下面,我们来看看这个U-Net模型在GID和VOC2012两个数据集上的分割效果:

从GID的分割结果可以看到U-Net的分割结果更为精细,细节部分比FCN提高了不少。

在VOC2012数据集上分割效果还比较一般,只能分割出大致形态,细节还不够完善。
这里有一个要注意的问题,就是U-Net并不是任意大小的输入都可以运行的,对于一些长宽不符合要求的会报错。因为在下采样过程中要进行卷积运算,由于长宽不一定是偶数,可能造成图像长宽变化,上采样后无法和下采样过程中的特征图进行拼接,所以训练过程中最好对图像进行裁剪操作,裁剪成适合U-Net运行的大小,或者改进U-Net模型,使其可以兼容各种不同大小的数据。