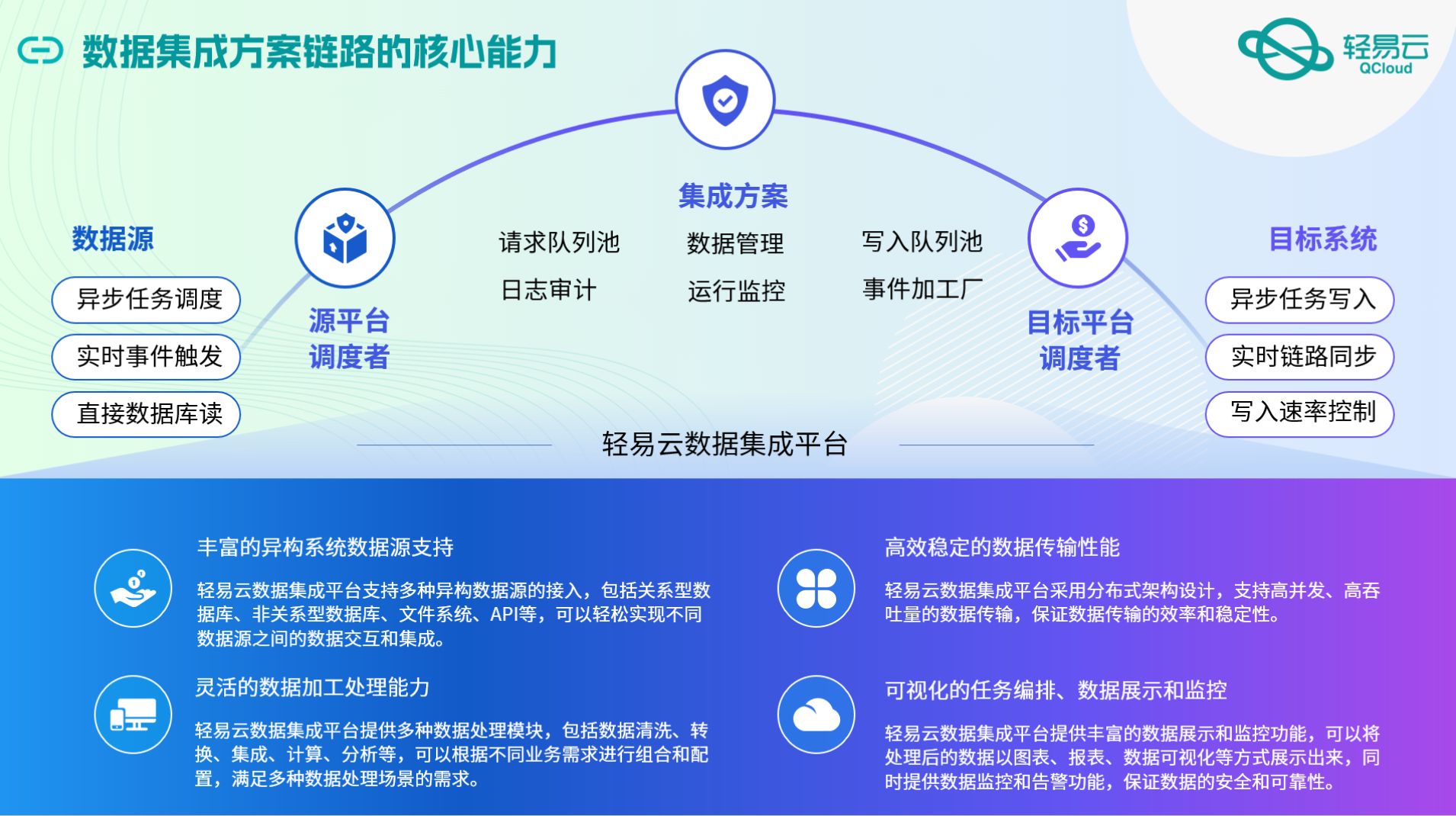
目录
编辑
逻辑回归原理
损失函数与优化
正则化
基于框架的实现
1. 数据预处理
2. 模型初始化与训练
3. 模型评估与调优
4. 特征缩放
逻辑回归的应用
信用评分
医疗诊断
垃圾邮件识别
推荐系统
结论
在机器学习领域,逻辑回归是一种基础且强大的分类算法,尤其适用于二分类问题。本文将详细介绍逻辑回归的原理、如何在流行的机器学习框架中实现逻辑回归,以及其在实际应用中的价值。
逻辑回归原理
逻辑回归的核心在于使用逻辑函数(通常是Sigmoid函数)将线性回归模型的输出映射到0和1之间,从而预测一个事件发生的概率。Sigmoid函数的公式为:
[ ]
其中,( ) 是输入特征的线性组合,即 (
)。这个函数的输出值在0到1之间,可以被解释为属于某个类别的概率。
损失函数与优化
逻辑回归的损失函数通常采用交叉熵损失(Binary Cross-Entropy Loss),它衡量的是模型预测概率与实际发生事件之间的差异。优化算法,如梯度下降,用于最小化这个损失函数,从而找到最佳的模型参数。
为了更深入地理解这一点,我们可以手动计算交叉熵损失:
import numpy as np# 假设y_true是真实标签,y_pred是模型预测的概率
y_true = np.array([0, 1, 1, 0])
y_pred = np.array([0.1, 0.9, 0.8, 0.2])# 计算交叉熵损失
def binary_cross_entropy(y_true, y_pred):# 避免对数为0的情况y_pred = np.clip(y_pred, 1e-15, 1 - 1e-15)return -np.mean(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))loss = binary_cross_entropy(y_true, y_pred)
print(f"Cross-Entropy Loss: {loss:.4f}")这个损失函数的计算涉及到对数函数,因此我们需要确保预测概率y_pred不会是0或1,因为这会导致对数函数的输入为0,从而产生数学上的错误。np.clip函数在这里被用来限制y_pred的值,防止这种情况的发生。
正则化
为了防止过拟合,逻辑回归可以加入L1正则化(Lasso)或L2正则化(Ridge)。这些正则化技术通过在损失函数中添加一个惩罚项来限制模型的复杂度。正则化项是模型参数的函数,通常与参数的平方和(L2正则化)或绝对值(L1正则化)成比例。
以下是如何在逻辑回归中加入L2正则化的示例:
from sklearn.linear_model import LogisticRegression# 创建带有L2正则化的逻辑回归模型
model_l2 = LogisticRegression(penalty='l2', C=1.0)# 假设X_train和y_train是训练数据和标签
# model_l2.fit(X_train, y_train)# 预测
# y_pred_l2 = model_l2.predict(X_test)# 评估模型
# accuracy_l2 = accuracy_score(y_test, y_pred_l2)
# print(f"Accuracy with L2 regularization: {accuracy_l2:.2f}")在这个例子中,C参数控制正则化的强度。较小的C值表示更大的正则化强度,这会使得模型参数更趋向于0,从而减少模型的复杂度。相反,较大的C值会减弱正则化的效果,允许模型更加复杂。
基于框架的实现
1. 数据预处理
在应用逻辑回归之前,需要对数据进行预处理,包括特征缩放、处理缺失值等,以确保模型能够更好地学习。
以下是如何使用SimpleImputer处理缺失值的示例:
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler# 假设X_train和X_test包含缺失值
imputer = SimpleImputer(strategy='mean')
X_train_imputed = imputer.fit_transform(X_train)
X_test_imputed = imputer.transform(X_test)# 特征缩放
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train_imputed)
X_test_scaled = scaler.transform(X_test_imputed)特征缩放是机器学习中的一个重要步骤,因为它可以加速学习算法的收敛,并提高模型的性能。StandardScaler通过减去平均值并除以标准差来标准化特征,使得每个特征的均值为0,标准差为1。
2. 模型初始化与训练
使用机器学习框架,如scikit-learn,可以方便地初始化和训练逻辑回归模型。以下是使用scikit-learn实现逻辑回归的简单示例:
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建逻辑回归模型
model = LogisticRegression()# 训练模型
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")# 显示分类报告
print(classification_report(y_test, y_pred))# 显示混淆矩阵
print(confusion_matrix(y_test, y_pred))在这个例子中,我们首先从scikit-learn库中加载了鸢尾花(Iris)数据集,这是一个经典的多类分类数据集。然后,我们使用train_test_split函数将数据集分为训练集和测试集。接着,我们创建了一个LogisticRegression模型,并使用训练集上的数据来训练它。最后,我们在测试集上评估模型的性能,并打印出准确率、分类报告和混淆矩阵。
3. 模型评估与调优
使用验证集或测试集评估模型性能,并根据评估结果调整模型参数或结构,以优化模型性能。例如,我们可以通过调整正则化强度来防止过拟合:
# 创建带有不同正则化强度的逻辑回归模型
model_with_regularization = LogisticRegression(C=0.1, penalty='l2')# 训练模型
model_with_regularization.fit(X_train, y_train)# 预测
y_pred_regularized = model_with_regularization.predict(X_test)# 评估模型
accuracy_regularized = accuracy_score(y_test, y_pred_regularized)
print(f"Accuracy with L2 regularization: {accuracy_regularized:.2f}")在这个例子中,我们创建了一个新的逻辑回归模型,并设置了不同的正则化强度(C=0.1)。这个参数控制了模型的正则化程度,较小的值表示更强的正则化,可以帮助防止过拟合。通过比较不同正则化强度下的模型性能,我们可以找到最佳的正则化参数。
4. 特征缩放
特征缩放是提高模型性能的重要步骤,尤其是在使用梯度下降算法时。以下是如何使用StandardScaler进行特征缩放的示例:
from sklearn.preprocessing import StandardScaler# 特征缩放
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# 使用缩放后的特征训练模型
model.fit(X_train_scaled, y_train)# 预测
y_pred_scaled = model.predict(X_test_scaled)# 评估模型
accuracy_scaled = accuracy_score(y_test, y_pred_scaled)
print(f"Accuracy with feature scaling: {accuracy_scaled:.2f}")在这个例子中,我们使用了StandardScaler来标准化特征。标准化后,每个特征的均值为0,标准差为1,这有助于梯度下降算法更快地收敛。我们首先在训练集上拟合StandardScaler,然后将训练集和测试集的特征都进行标准化。接着,我们使用标准化后的特征来训练逻辑回归模型,并在测试集上评估模型的性能。
逻辑回归的应用
逻辑回归因其简单性和有效性,在多个领域有着广泛的应用,包括但不限于:
- 信用评分:预测个人或企业的信用风险。
- 医疗诊断:如预测疾病的发展或患者的生存概率。
- 垃圾邮件识别:在电子邮件服务中识别和过滤垃圾邮件。
- 推荐系统:预测用户对特定产品或服务的偏好。
信用评分
在信用评分领域,逻辑回归可以帮助银行和金融机构评估客户的信用风险。信用评分模型的目标是预测借款人是否会违约。以下是如何使用逻辑回归进行信用评分的详细示例:
# 假设credit_data包含客户的信用信息
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, roc_auc_score
from sklearn.preprocessing import StandardScaler# 加载数据集
credit_data = load_credit_data()
X_credit, y_credit = credit_data.data, credit_data.target# 数据集划分
X_train_credit, X_test_credit, y_train_credit, y_test_credit = train_test_split(X_credit, y_credit, test_size=0.2, random_state=42)# 特征缩放
scaler = StandardScaler()
X_train_credit_scaled = scaler.fit_transform(X_train_credit)
X_test_credit_scaled = scaler.transform(X_test_credit)# 创建逻辑回归模型
model_credit = LogisticRegression()# 训练模型
model_credit.fit(X_train_credit_scaled, y_train_credit)# 预测概率
y_pred_prob_credit = model_credit.predict_proba(X_test_credit_scaled)[:, 1]# 预测
y_pred_credit = model_credit.predict(X_test_credit_scaled)# 评估模型
accuracy_credit = accuracy_score(y_test_credit, y_pred_credit)
roc_auc_credit = roc_auc_score(y_test_credit, y_pred_prob_credit)
print(f"Credit Scoring Accuracy: {accuracy_credit:.2f}")
print(f"Credit Scoring ROC AUC: {roc_auc_credit:.2f}")在这个例子中,我们首先加载了信用数据集,并将数据集分为训练集和测试集。然后,我们使用StandardScaler对特征进行缩放,以确保所有特征都在相同的尺度上。接着,我们创建了一个逻辑回归模型,并使用缩放后的训练集数据来训练它。我们还预测了测试集上的概率,并使用这些概率来计算接收者操作特征(ROC AUC)得分,这是一个衡量模型性能的指标,特别是在信用评分领域。
医疗诊断
在医疗诊断领域,逻辑回归可以帮助医生预测疾病的发展或患者的生存概率。以下是如何使用逻辑回归进行医疗诊断的示例:
# 假设medical_data包含患者的医疗信息
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据集
medical_data = load_medical_data()
X_medical, y_medical = medical_data.data, medical_data.target# 数据集划分
X_train_medical, X_test_medical, y_train_medical, y_test_medical = train_test_split(X_medical, y_medical, test_size=0.2, random_state=42)# 创建逻辑回归模型
model_medical = LogisticRegression()# 训练模型
model_medical.fit(X_train_medical, y_train_medical)# 预测
y_pred_medical = model_medical.predict(X_test_medical)# 评估模型
accuracy_medical = accuracy_score(y_test_medical, y_pred_medical)
print(f"Medical Diagnosis Accuracy: {accuracy_medical:.2f}")在这个例子中,我们首先加载了医疗数据集,并将数据集分为训练集和测试集。然后,我们创建了一个逻辑回归模型,并使用训练集上的数据来训练它。最后,我们在测试集上评估模型的性能,并打印出准确率。
垃圾邮件识别
在垃圾邮件识别领域,逻辑回归可以帮助电子邮件服务识别和过滤垃圾邮件。以下是如何使用逻辑回归进行垃圾邮件识别的示例:
# 假设spam_data包含邮件信息
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据集
spam_data = load_spam_data()
X_spam, y_spam = spam_data.data, spam_data.target# 数据集划分
X_train_spam, X_test_spam, y_train_spam, y_test_spam = train_test_split(X_spam, y_spam, test_size=0.2, random_state=42)# 创建逻辑回归模型
model_spam = LogisticRegression()# 训练模型
model_spam.fit(X_train_spam, y_train_spam)# 预测
y_pred_spam = model_spam.predict(X_test_spam)# 评估模型
accuracy_spam = accuracy_score(y_test_spam, y_pred_spam)
print(f"Spam Detection Accuracy: {accuracy_spam:.2f}")在这个例子中,我们首先加载了垃圾邮件数据集,并将数据集分为训练集和测试集。然后,我们创建了一个逻辑回归模型,并使用训练集上的数据来训练它。最后,我们在测试集上评估模型的性能,并打印出准确率。
推荐系统
在推荐系统领域,逻辑回归可以帮助预测用户对特定产品或服务的偏好。以下是如何使用逻辑回归进行推荐系统的示例:
# 假设recommendation_data包含用户和产品信息
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据集
recommendation_data = load_recommendation_data()
X_recommendation, y_recommendation = recommendation_data.data, recommendation_data.target# 数据集划分
X_train_recommendation, X_test_recommendation, y_train_recommendation, y_test_recommendation = train_test_split(X_recommendation, y_recommendation, test_size=0.2, random_state=42)# 创建逻辑回归模型
model_recommendation = LogisticRegression()# 训练模型
model_recommendation.fit(X_train_recommendation, y_train_recommendation)# 预测
y_pred_recommendation = model_recommendation.predict(X_test_recommendation)# 评估模型
accuracy_recommendation = accuracy_score(y_test_recommendation, y_pred_recommendation)
print(f"Recommendation System Accuracy: {accuracy_recommendation:.2f}")在这个例子中,我们首先加载了推荐系统数据集,并将数据集分为训练集和测试集。然后,我们创建了一个逻辑回归模型,并使用训练集上的数据来训练它。最后,我们在测试集上评估模型的性能,并打印出准确率。
结论
逻辑回归作为一种经典的分类算法,不仅在理论上具有坚实的基础,而且在实际应用中也表现出色。通过现代机器学习框架,我们可以轻松地实现和优化逻辑回归模型,以解决各种分类问题。随着技术的不断进步,逻辑回归仍然是机器学习领域中一个不可忽视的工具。