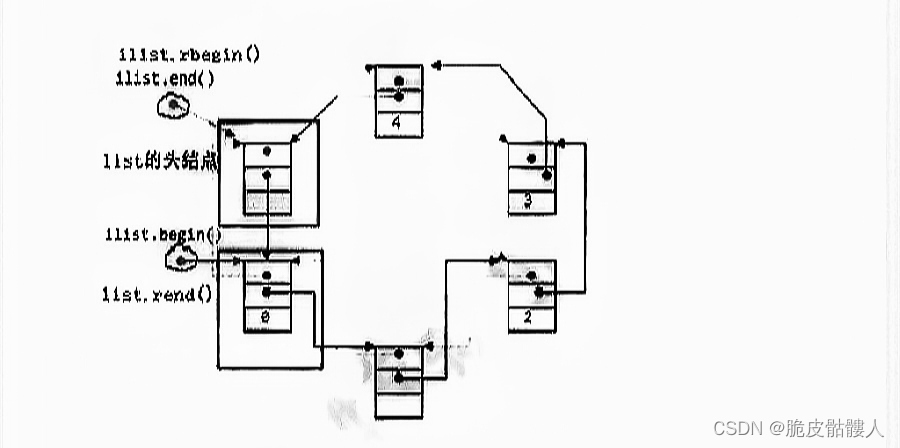
图片说明来自李宏毅老师视频的学习笔记,如有侵权,请通知下架
影片参考
【李宏毅】3.第一节 - (上) - 机器学习基本概念简介_哔哩哔哩_bilibili
1. 机器学习的概念与任务类型
- 概念:机器学习近似于寻找函数,用于处理不同类型的任务。
- 任务类型
- 回归(Regression):函数输出一个标量,例如预测 PM2.5 浓度。
- 分类(Classification):函数从给定的选项(类别)中输出正确的一个,如语音识别、图像识别、垃圾邮件过滤、围棋落子位置预测等。
- 结构化学习(Structured Learning):创建具有结构的内容,如图像、文档。
2. 寻找函数的方法
- 确定具有未知参数的函数:基于领域知识构建模型,包含权重、偏差和特征等参数。
- 从训练数据定义损失(Loss)
- 损失是参数的函数,表示一组值的好坏程度。
- 例如使用交叉熵(Cross - entropy)作为损失函数。
- 通过分析 2017 年 1 月 1 日 - 2020 年 12 月 31 日的数据来定义损失。
- 优化
- 使用梯度下降(Gradient Descent)算法,计算正负梯度以更新参数,朝着损失减小的方向优化。
- 讨论了局部最小值和全局最小值问题,指出在大多数深度学习框架中,优化过程可以用一行代码实现。
3. 模型的局限性与改进
- 线性模型的局限性:以预测视频观看量为例,说明线性模型存在严重局限性,需要更灵活的模型。
- 改进方向
- 增加特征和激活函数
- 介绍了如何用分段线性曲线近似连续曲线,以及 sigmoid 函数及其相关操作(改变斜率、平移、改变高度)。
- 提出新模型增加特征,如使用 Rectified Linear Unit (ReLU) 作为激活函数,并对比了不同激活函数和不同隐藏层数量的实验结果。
- 深度学习模型
- 多层神经网络(Neural Network),即深度学习,包含多个隐藏层。介绍了 AlexNet、VGG、GoogleNet、Residual Net 等网络结构及层数,并指出深度学习中 “深”(Many hidden layers)的特点。
- 解释了为什么选择 “深” 网络而非 “胖” 网络,同时提到过度拟合(Overfitting)问题,即模型在训练数据上表现好,但在未见过的数据上表现差。
- 增加特征和激活函数
最后,文档提到下次将讨论模型选择,并给出了相关学习资源的链接,还介绍了反向传播(Backpropagation)是一种高效计算梯度的方法。
本課程介紹機器學習和深度學習的基本概念,並透過實際例子解釋如何利用機器學習來預測YouTube頻道的觀看人數。首先,機器學習是讓機器找出複雜函式的能力,並通過回歸分析和分類任務來實現。接著,課程詳細說明了如何定義損失函數並使用梯度下降法來優化參數,最終達到最小化損失的目的。透過不斷調整模型,能夠提高預測的準確性,並探討如何利用過去的數據來預測未來的趨勢。
幻灯片 2:机器学习的近似概念
- 表明机器学习≈寻找函数,并列举了语音识别、图像识别、下围棋等应用场景作为示例。

00:01 那我们就开始上课吧
00:04 那第一堂课啊是要简单跟大家介绍一下machine learning
00:09 还有deep learning的基本概念啊
00:12 等一下呢
00:13 会讲一个跟宝可梦完全没有关系的故事
00:17 告诉你机器学习
00:19 还有深度学习的基本概念好
00:23 那什么是机器学习呢
00:26 那我知我想必大家在报章杂志上
00:28 其实往往都已经听过机器学习这个词汇
00:32 那你可能也知道说啊
00:34 机器学习就是跟今天很热门的AI
00:38 好像有那么一点关联
00:41 那所谓的机器学习到底是什么呢
00:45 顾名思义好像是说机器它具备有学习的能力
00:50 那些科普文章往往把机器学习这个东西
00:54 吹得玄之又玄
00:56 好像机器会学习以后
00:57 我们就有了人工智慧
00:59 有了人工智慧以后
01:00 机器接下来就要统治人类了
01:03 好那机器学习到底是什么呢
01:10 可以用一句话来描述机器学习这件事
01:14 什么叫机器学习呢
01:16 机器学习就是让机器具备找一个函式的能力
01:22 那机器具备找函式的能力以后
01:25 他可以做什么样的事情呢
01:27 它确实可以做很多事
01:29 举例来说
01:30 假设你今天想要叫机器做语音辨识
01:33 机器听一段声音
01:35 产生这段声音对应的文字
01:37 那你需要的就是一个函式
01:40 这个函式的输入是声音讯号
01:43 输出是这段声音讯号的内容
01:48 那你可以想象说这个可以把声音讯号当作输入
01:52 文字当做输出的函式
01:54 显然非常非常的复杂
01:56 它绝对不是你只可以用人手写出来的方程式
02:01 这个函式它非常非常的复杂
02:04 人类绝对没有能力把它写出来
02:06 所以我们期待凭借着机器的力量
02:09 把这个函式自动找出来
02:12 这件事情就是机器学习
02:15 那刚才举的例子是语音辨识
02:18 还有好多好多的任务
02:20 我们都需要找一个很复杂的函式
02:24 举例来说
02:25 假设我们现在要做影像辨识
02:29 那这个影像辨识我们需要什么样的函式呢
02:32 这个函式的输入是一张图片
02:36 它的输出是什么呢
02:38 它是这个图片里面有什么样的内容
02:42 或者是大家都知道的阿尔法狗
02:46 其实也可以看作是一个函式
02:48 要让机器下围棋
02:50 我们需要的就是一个函式
02:52 这个函式的输入是棋盘上黑子跟白子的位置
02:56 输出是什么
02:57 输出是机器下一步应该落子的位置
03:02 假设你可以找到一个函式
03:04 这个函式的输入就是棋盘上黑子跟白子的位置
03:08 输出就是下一步应该落子的位置
03:13 那我们就可以让机器做自动下围棋这件事
03:17 就可以做一个阿尔法狗
03:20 而那随着我们要找的函式不同啊
幻灯片 3 - 4:不同类型的函数 - 回归
- 回归类型中函数输出一个标量,以预测明天的 PM2.5 为例,展示了其可能与今天的 PM2.5、温度、O3 浓度等因素相关。

03:23 机器学习有不同的类别
03:26 那这边介绍几个专有名词给大家认识一下好
03:31 第一个专有名词叫做regression
03:34 regression的意思是说
03:36 假设我们今天要找的函式
03:39 它的输出是一个数值好
03:43 它的输出是一个scale
03:45 那这样子的机器学习的任务
03:48 我们称之为regression
03:51 那这边举一个regression的例子
03:53 假设我们今天要机器做的事情
03:55 是预测未来某一个时间的pm2.5的数值
04:00 你要叫机器做的事情是找一个函式啊
04:03 这个我们用F来表示
04:04 这个函式的输出是明天中午的pm2.5的数值
04:10 它的输入可能是种种
04:12 跟预测pm2.5有关的指数
04:14 包括今天的pm2.5的数值
04:16 今天的平均温度
04:18 今天平均的臭氧浓度等等
04:20 这个函式可以拿这些数值当做输入输出
04:24 明天中午的pm2.5的数值
04:27 那这一个找这个函式的任务叫做regression
04:34 那还有别的任务吗
04:35 还有别的任务
04:37 除了regression以外
04:38 另外一个呃大家耳熟能详的任务呢叫做classification
04:45 那classification这个任务要机器做的是选择题哦
04:50 我们人类先准备好一些选项啊
04:53 这些选项呢又叫做类别
04:56 又叫做FS
04:57 我们现在要找的函式
04:59 它的输出啊
05:00 就是从我们设定好的选项里面
05:03 选择一个当做输出啊
05:06 这个问题这个任务就叫做classification
05:10 举例来说啊
05:11 现在每个人都有gmail com
05:14 那gmail com里面呢有一个函数
05:17 这个函式可以帮我们侦测一封邮件
05:20 是不是乐色邮件
05:22 这个函式的输入是一封电子邮件
05:26 那它的输出是什么呢
05:28 你要先准备好你要机器选的选项
05:31 在侦测垃圾邮件这个问题里面
05:34 可能的选项就是两个是垃圾邮件
05:37 或不是垃圾邮件
05:38 yes或者是NO
05:40 那机器要从yes跟NO里面选一个选项出来
05:45 这个问题叫做classification
05:48 那classification不止不一定只有两个选项
05:51 也可以有多个选项
 05:54 举例来说
05:54 举例来说
05:55 阿尔法狗本身也是一个classification的问题
06:00 那只是这个classification它的选项是比较多的
06:04 那如果要叫机器下围棋
06:06 你想追到阿尔法go的话
06:07 我们要给机器多少个选项呢
06:10 你就想想看棋盘上有多少个位置
06:14 让我们知道棋盘上有19×19个位置
06:18 那叫机器下围棋
06:19 这个问题
06:20 其实就是一个有19×19个选项的选择题
06:25 你要叫机器做的就是找一个函式
06:27 这个函式的输入是棋盘上黑纸和白纸的位置
06:31 输出
06:31 就是从19×19个选项里面
06:34 选出一个正确的选项
06:36 从19×19个可以落子的位置里面
06:40 选出下一步应该要落子的位置
06:44 这个问题也是一个分类的问题
亮點:
01:10 機器學習是一種讓機器具備自動找出函式能力的技術,能夠處理複雜的任務如語音辨識和影像辨識。這種技術的核心在於不需要人類手動編寫複雜的方程式,機器能自動學習。
-語音辨識是機器學習的一個實際應用案例,機器需要找到將聲音訊號轉換為文字的函式。這個函式的複雜性遠超過人類能手動撰寫的範疇,因此機器的學習能力至關重要。
-影像辨識同樣需要機器學習,機器需要識別圖像內容並找出合適的函式。這需要機器分析圖像的各種特徵,並做出準確的判斷,這在各種應用中都非常重要。
-機器學習的不同類型包括回歸和分類任務。回歸任務尋求預測數值,而分類任務則需要從多個選項中選擇一個,這些都是機器學習在實際應用中的關鍵技術。
幻灯片 5 - 7:不同类型的函数 - 分类
- 分类任务中函数从给定选项(类别)中输出正确的一个。
- 分别以垃圾邮件过滤(是 / 否类别)和围棋下一步落子位置预测(19x19 个类别)为例进行说明。
 06:48 那其实很多教科书啊
06:48 那其实很多教科书啊
06:50 在讲机器学习的种种不同类型的任务的时候
06:54 往往就讲到这边告诉你说机器学习两大类任务
06:59 一个叫做regression
07:02 一个叫做classification
07:04 然后就结束了
07:06 但是假设你对机器学习的认知只停留在
07:10 机器学习
07:10 就是两大类任务
07:12 regression和classification
07:13 那就好像你以为说这个世界只有五大洲一样
07:18 你知道这个世界不是只有五大洲
07:21 对不对
07:21 哎这个世界不是外面是有一个黑暗大陆的
07:25 哎
07:25 不在鬼灭之刃联赛之前
07:28 我们就已经出发前往黑暗大陆了
07:30 鬼灭之刃联赛以后
07:31 我们居然都还没有到
07:33 可见这个黑暗大陆距离我远
07:36 那在机器学习这个领域里面
07:38 所谓的黑暗大陆是什么呢
07:40 在regression和classification以外
07:43 大家往往害怕碰触的问题叫做structure的
07:48 也就是机器今天不只是要做选择题
07:51 不只是输出一个数字
07:53 它要产生一个有结构的物件
07:57 举例来说
07:58 机器画一张图
08:00 写一篇文章
08:01 这种叫机器产生有结构的东西的这个问题呀
08:06 就叫做structure learning
08:08 那如果要讲的比较拟人化
08:10 比较潮一点
08:11 Structure learning
08:12 你可以用拟人化的讲法说
08:14 我们就是要让机器学会创造这件事情好
08:20 那到目前为止
08:21 我们就是讲了三个机器学习的任务
08:24 regression classification跟structure learning
08:27 接下来我们要讲的是




幻灯片 9:如何寻找函数 - 案例研究
- 以 YouTube 频道数据为例展开说明如何寻找函数。
08:30 那我们说机器学习就是要找一个函式
08:33 那机器怎么找一个函式呢
08:37 那这边要用个例子跟大家说明说
08:39 机器怎么找一个函式
08:43 这边的例子是什么呢
08:44 这边的例子在讲这个例子之前呢
08:47 先跟大家说一下
08:49 说这门课呢有一个YOUTUBE的频道啦
08:53 诶然后这个呃
08:55 我会把上课的录音呢
08:56 放到这个YOUTUBE的YOUTUBE的频道上面啊
09:00 那这个频道呢感谢呃
09:02 过去修过这门课的同学不嫌弃
09:04 其实也蛮多人订阅
09:06 所以我算是一个三流的YOUTUBE啊
09:09 是没有什么太多流量
09:10 但是也是有这边也是7万多订阅啦
09:14 那为什么突然提到这个YOUTUBE的频道呢
09:17 因为我们等一下要举的例子啊
09:19 跟YOUTUBE是有关系的
09:22 那你知道身为一个YOUTUBE啊
09:24 YOUTUBE在意的东西是什么呢
09:26 YOUTUBE在意的就是这个频道的流量
09:29 对不对
09:30 就假设这个有一个YOUTUBE呢是靠着YOUTUBE为生的
09:34 他会在意说频道有没有流量
09:36 这样的他才会知道他可以获利多少
09:41 所以我在想说
09:42 我们有没有可能找一个函式
09:45 这个函式它的输入是YOUTUBE后台的资讯输出
09:49 是这个频道隔天的总点阅率总共有多少哦
09:55 假设你自己有YOUTUBE频道的话
09:57 你会知道说在YOUTUBE后台
09:59 你可以看到很多相关的资讯
10:02 比如说每一天看赞的人数有多少啊
10:05 每天订阅的人数有多少啊
10:07 每天观看的次数有多少
10:09 我们能不能够根据一个频道
10:11 过往所有的资讯去预测
10:14 他明天有可能的观看的次数是多少呢
10:18 我们能不能够找一个函式
10:20 这个函式的输入是啊
10:23 YOUTUBE上面YOUTUBE后台是我的资讯输出
10:27 就是某一天隔天呃
10:30 这个频道会有的总观看的次数呢
10:33 那你可能会问说为什么要做这个嗯
10:37 如果我有盈利的话
10:39 我可以知道我未来可以赚到多少钱
10:41 但我其实没有开盈利
10:42 所以我也不知道我为什么要做这个
10:44 就是完全没有任何卵用
10:46 我单纯就是想举一个例子而已好
10:50 那接下来啊我们就要问怎么找出这个函式呢
10:54 怎么找这个函式
08:30 那我们说机器学习就是要找一个函式
08:33 那机器怎么找一个函式呢
08:37 那这边要用个例子跟大家说明说
08:39 机器怎么找一个函式
08:43 这边的例子是什么呢
08:44 这边的例子在讲这个例子之前呢
08:47 先跟大家说一下
08:49 说这门课呢有一个YOUTUBE的频道啦
08:53 诶然后这个呃
08:55 我会把上课的录音呢
08:56 放到这个YOUTUBE的YOUTUBE的频道上面啊
09:00 那这个频道呢感谢呃
09:02 过去修过这门课的同学不嫌弃
09:04 其实也蛮多人订阅
09:06 所以我算是一个三流的YOUTUBE啊
09:09 是没有什么太多流量
09:10 但是也是有这边也是7万多订阅啦
09:14 那为什么突然提到这个YOUTUBE的频道呢
09:17 因为我们等一下要举的例子啊
09:19 跟YOUTUBE是有关系的
09:22 那你知道身为一个YOUTUBE啊
09:24 YOUTUBE在意的东西是什么呢
09:26 YOUTUBE在意的就是这个频道的流量
09:29 对不对
09:30 就假设这个有一个YOUTUBE呢是靠着YOUTUBE为生的
09:34 他会在意说频道有没有流量
09:36 这样的他才会知道他可以获利多少
09:41 所以我在想说
09:42 我们有没有可能找一个函式
09:45 这个函式它的输入是YOUTUBE后台的资讯输出
09:49 是这个频道隔天的总点阅率总共有多少哦
09:55 假设你自己有YOUTUBE频道的话
09:57 你会知道说在YOUTUBE后台
09:59 你可以看到很多相关的资讯
10:02 比如说每一天看赞的人数有多少啊
10:05 每天订阅的人数有多少啊
10:07 每天观看的次数有多少
10:09 我们能不能够根据一个频道
10:11 过往所有的资讯去预测
10:14 他明天有可能的观看的次数是多少呢
10:18 我们能不能够找一个函式
10:20 这个函式的输入是啊
10:23 YOUTUBE上面YOUTUBE后台是我的资讯输出
10:27 就是某一天隔天呃
10:30 这个频道会有的总观看的次数呢
10:33 那你可能会问说为什么要做这个嗯
10:37 如果我有盈利的话
10:39 我可以知道我未来可以赚到多少钱
10:41 但我其实没有开盈利
10:42 所以我也不知道我为什么要做这个
10:44 就是完全没有任何卵用
10:46 我单纯就是想举一个例子而已好
10:50 那接下来啊我们就要问怎么找出这个函式呢
10:54 怎么找这个函式
10:55 F输入是YOUTUBE后台的资料输出
10:58 是这个频道隔天的点阅的总人数呢
11:03 那机器学习找这个函式的过程啊
11:06 分成三个步骤
11:08 那我们就用YOUTUBE频道点阅人数预测这件事情
11:12 来跟大家说明这三个步骤是怎么运作的
11:17 第一个步骤是
11:19 我们要写出一个带有未知参数的函数
11:25 简单来说就是我们先猜测一下
11:28 我们打算找的这个函式F
11:30 它的数学式到底长什么样
11:35 举例来说呃
11:36 我们这边先做一个最初步的猜测
11:39 这个F长什么样子呢
11:41 这个输入跟Y之间有什么样的关系呢
11:45 我们写成这个样子
11:46 Y等于B加W乘以XY
11:51 这边的每一个数值是什么呢
11:53 这个Y啊是就假设是今天吧
11:56 这个Y因为今天还没有过完嘛
11:58 所以我还不知道今天总共的点阅次数是多少
12:01 所以这件事情是我们未知的
12:03 Y是我们准备要预测的东西
12:05 我们准备要预测的是今天2月26号
12:08 这个频道总共观看的人数
幻灯片 10 - 11:具有未知参数的函数
- 基于领域知识确定函数,包含模型的权重、偏差和特征等未知参数。

12:11 那x1是什么呢
12:13 x1是这个频道前一天总共观看的人数的
12:18 Y跟X呢跟XY呢都是数值
12:22 都是我们啊
12:23 这个这个Y呢是我们准备要预测的东西
12:26 而XY是我们已经知道的资讯啊
12:31 那B跟W是什么呢
12:33 B跟W未知的参数
12:36 它是准备要透过资料去找出来的
12:40 我们还不知道W跟B应该是多少
12:44 我们只是隐约的猜测说
12:46 但这个猜测为什么会有这个猜测呢
12:48 这个猜测往往就来自于你对这个问题上的了解
12:53 也就是for man knowledge
12:55 所以常常会听到有人说啊
12:57 这个做机器学习呀
12:59 你就需要一些domain knowledge
13:01 这个dmain knowledge通常是用在哪里呢
13:04 这个domain knowledge
13:05 就是用在写这个带有未知数的函数的时候
13:10 所以我们怎么知道说
13:12 这个能够预测未来点阅次数的函数是F
13:15 它就一定是前一天的点阅次数乘上W
13:20 再加上B呢
13:21 我们其实不知道这是一个猜测
13:24 也许我们觉得说呃
13:25 这个呃
13:26 呃今天的点阅次数
13:29 总是会跟昨天的点阅次数有点关联吧
13:32 好所以我们把昨天的点阅次数乘三个数值
13:35 但是总是不会一模一样
13:37 所以再加三个B做修正
13:39 当做是对于2月26号点阅次数的预测啊
13:44 这是一个猜测
13:45 他不一定是对的
13:47 我们等一下回头会再来修正这个猜测
13:50 好
13:51 那现在总之我们就随便猜
13:53 说Y等于B加W乘以XY
13:56 而B跟W是未知的
13:59 这个带有未知的参数啊
14:02 这个parameter中文通常翻译成参数了
14:05 这个带有unknown的parameter的这个function
14:08 那我们就叫做妈的
14:11 所以常常听到有人说模型model这个东西
14:15 model这个东西在机器学习里面
14:17 就是一个带有未知的parameter的function
14:23 好
14:23 那这个x1哪是这个方式里面
14:26 我们已知的已经知道的东西
14:28 它是来自于YOUTUBE后台的资讯
14:30 我们已经知道
14:31 2月25号点阅的总人数是多少
14:35 这个东西叫做正确
14:38 而W跟B是我们不知道的
14:40 他是unknown的parameter
14:42 那这边我们也给W跟B呢给它一个名字
14:46 这个跟feature做相乘的未知的参数
14:49 这个W我们叫它weight
14:52 这个没有跟feature相乘的
14:54 是直接加上去的
14:55 这个我们叫它白眼
14:58 那这个只是一些名词的定义而已
15:01 让你等一下我们讲课的时候
15:03 在称呼模型里面的每一个东西的时候
15:05 会更为方便好
15:07 那这个是第一个步骤好
06:00 機器學習不僅僅是回歸和分類這兩大類任務,還包括結構學習。這意味著機器不僅要做出選擇或預測數字,還需要創造有結構的物件,如圖像或文本。
-在機器學習中,棋盤遊戲如圍棋的問題可以視為一個分類問題。機器需要從19×19的選擇中找到最佳的落子位置,這展示了機器學習在解決複雜問題上的能力。
-結構學習的概念讓機器學會創造,例如自動生成圖像或文本。這種能力的發展不僅增強了機器的智能,也拓展了人工智慧的應用範疇。
-舉例來說,預測YouTube頻道的觀眾數量可以透過機器學習找到函式,這個函式的輸入是頻道的各種數據。這展示了如何利用過去資料進行未來預測的過程。
幻灯片 12 - 19:从训练数据定义损失
- 损失是参数的函数,表示一组值的好坏程度。
- 以 2017 年 1 月 1 日 - 2020 年 12 月 31 日的数据为例,介绍如何根据数据定义损失,涉及到交叉熵等概念。
- 通过数据展示不同时间点的数值以及对应的标签,分析如何衡量损失。

15:12 那第二个步骤是什么呢
15:13 第二个步骤呢是我们要定义一个东西叫做loss
15:19 什么是loss呢
15:20 loss啊
15:21 它也是一个function
15:24 那这个function它的输入是我们model里面的参数
15:31 我刚才已经把我们的model写出来了
15:33 对不对
15:34 我们说我们的model叫做Y等于B加W乘以XY
15:38 而第一个W是未知的
15:40 是我们准备要找出来的
15:42 那所谓的L啊
15:44 所谓的这个loss啊
15:46 它是一个方向
15:47 这个方向的输入是什么
15:49 这个方向的输入就是B跟W
15:53 所以LO它是一个方式
15:55 它的输入是parameter
15:57 是model里面的parameter
16:00 但这个north这个方向的输出的值代表什么呢
16:03 这个方式输出的值代表说
16:05 现在如果我们把这一组未知的参数
16:10 设定某一个数值的时候
16:12 这组数值好还是不好
16:15 那这样讲可能你觉得有点抽象
16:19 所以我就举一个具体的例子
16:21 假设现在我们给未知的参数的设定是D
16:27 这个bias x等于0.5K
16:30 这个WF呢直接等于一
16:34 那这个loss怎么计算呢
16:35 如果我们B设0.5K这个W正一
16:40 那我们拿来预测
16:42 而未来的这个点阅次数的函式啊
16:46 就变成Y等于0.5K加一倍的XY
16:51 那这样子的一个函式
16:54 这个0.5K跟一它们所代表的这个函数
16:58 它有多好呢
16:59 这个东西就是loss
17:02 那在我们的问题里面
17:03 我们要怎么计算这个loss呢
17:06 好这个我们就要从训练资料来进行计算
17:11 在这个问题里面
17:12 我们的训练资料是什么呢
17:14 我们的训练资料是这个频道过去的点阅次数
17:19 举例来说
17:20 从2017年到2020年的点阅次数
17:25 每天的这个频道点阅次数都知道吧
17:27 啊这边是假的数字了
17:29 随便乱编的好
17:31 那所以我们知道2017年1月1号
17:34 到2020年12月31号
17:36 的点阅数字是多少
17:38 好接下来我们就可以计算loss怎么计算呢
17:43 我们把2017年1月1号的点阅次数
17:47 代入这一个函式里面
17:50 我们已经说
17:51 我们想要知道D设定为0.5
17:54 KW设定为一的时候
17:55 这个函式有多棒
17:57 好
17:57 当B设定为0.5KW设定为一的时候
18:00 我们拿来预测的这个函数是Y等于0.5K
18:03 加一倍的XY
18:05 那我就把这个XY带4.8K
18:08 看看预测出来的结果是多少哦
18:10 所以根据这个函式
18:12 根据B设0.5KKW设一的这个函式
18:17 如果1月1号是4.8K的点阅次数的话
18:21 那隔天应该是4.8K乘以10.5K
18:24 也就是5.3K的点阅次数
18:26 那隔天实际上的点阅次数
18:28 1月2号的点阅次数我们知道吗
18:31 从后台的资讯里面我们是知道的
18:34 所以我们可以比对一下
18:35 现在这个函式预估的结果跟真正的结果
18:39 它的差距有多大
18:41 这个函式预估的结果是5.3K
18:45 真正的结果是多少呢
18:46 真正的结果是4.9K
18:49 看来是高估了
18:50 高估了这个频道可能的这个点阅的人数
18:53 就可以计算一下这个差距
18:55 计算一下估测的值跟真实的值的差距
18:59 这边估测的值用Y来表示真实的值
19:02 用y hand来表示
19:03 你可以计算Y跟y hat之间的差距

19:06 得到一个1万
19:07 代表估测的值跟真实的值之间的差距
19:11 那计算差距其实有不止一种方式
19:13 我们这边把Y跟Y开始相减
19:15 直接取绝对值
19:17 算出来的值是0.4K好
19:21 那我们今天有的资料
19:23 不是只有1月1号跟1月2号的资料
19:26 我们有2017年1月1号到
19:29 2020年12月31号总共3年的资料
19:33 好像这个真真实的词啊
19:35 叫做label啊
19:36 所以常常听到有人说做机器学习就需要label
19:40 label指的就是正确的数值
19:43 这个东西叫做label好
19:46 那我们不只
19:48 我们不是只能够看
19:49 用1月1号来预测1月2号的值
19:51 我们可以用1月2号的值来预测1月3号的值
19:55 如果我们现在的函数是Y等于0.5K
19:57 加一倍的XY
19:59 那1月2号根据1月2号的点阅次数
20:02 预测的1月3号的点阅次数值是多少呢
20:05 是5.4K
20:06 你h one带4.9K进去
20:09 乘以倍加0.5K等于5.4K
20:11 接下来计算这个5.4K跟真正的答案
20:15 跟label之间的差距
20:16 label是7.5K
20:17 看来是一个低估啊
20:19 低估了啊
20:20 这个频道在1月3号的时候的点阅次数
20:23 那就可以算出EQ啊
20:25 这个EQ是Y减跟Y跟y hat之间的差距
20:29 算出来12.1K
20:31 那同样的方法
20:32 你就可以算过这3年来每一天的预测的误差
20:37 假设我们今天的function是Y等于0.5K
20:40 加一倍的XY
 20:41 这3年来每一天的误差通通都可以算出来
20:41 这3年来每一天的误差通通都可以算出来
20:45 每一天的误差都可以给我们一个小一好
20:50 那接下来我们就把每一天的误差通通加起来
20:53 好加起来
20:54 然后取一个平均
20:55 这个大N呢代表我们的训练资料的次数的个数
20:59 那我们训练资料的个数
21:01 就是3年来的训练资料嘛
21:02 所以就365×3了
21:04 每年365天3年
21:06 所以365×3好
21:08 那我们算出一个L好
21:10 我们算出一个大LL
21:12 这个大L是每一笔训练资料的误差
21:15 这个一呀相加以后的结果
21:17 这个大LL就是我们的loss
21:20 这个大L越大
21:21 代表说我们现在这一组参数越不好
21:24 这个大L越小代表我们现在这一组参数越好
21:28 那这个一呀
21:30 就是计算这个估测的值跟实际的值之间的差距
21:34 其实有不同的计算方法
21:35 在我们刚才例子里面
21:37 我们是算Y跟YA解绝对值的差距
21:40 这种计算差距的方法得到的这个大L啊
21:44 得到的loss啊叫做main test alute error哦
21:48 所显示FA1
21:49 那在作业一里面呢
21:51 我们是算Y跟y hat相减以后的平方哦
21:56 如果你接的一是用相减后平方算出来的
21:59 这个叫mesquare error
22:00 叫MS1
22:01 那NS1跟NA1
22:03 它们其实有非常微妙的差别啦
22:05 那通常你要选择用哪一种方法来衡量距离
22:09 那只看你的需求
22:11 看你对这个任务的理解
22:13 那在这边呢我们就不往下细讲
22:16 反正我们就是选择了ma1
22:18 作为我们计算这个误差的方式
22:20 把所有的误差加起来就得到loss
22:23 但你要选择NS1也是可以的
22:25 在作业里面我们会用MNC
22:28 那有一些任务有如果Y跟y head
22:31 它都是几率
22:35 都是几率分布的话
22:37 在这个时候你可能会选择cos entropy
22:41 那这个我们都之后再说
22:42 反正我们这边就是选择了MA1好

22:46 那这个是机器学习的第二步
22:50 那我刚才举的那些数字不是真正的例子
22:53 但是在这门课里面
22:55 我在讲课的时候就是要举真正的例子给你看
22:58 所以以下的数字是真实的例子
23:01 是这个频道真实的后台的数据所计算出来的
23:05 结果好
23:07 那我们可以调整不同的搭配
23:09 我们可以调整不同的B穷
23:12 举各种W穷取各种V我组合起来以后
23:15 我们可以为不同的W跟的跟B的组合
23:19 都不去计算它的loss
23:22 然后就可以画出以下这一个等高线图
23:26 好在这个等高线图上面呐
23:29 越偏红色系代表计算出来的loss越大
23:33 就代表说这一组W跟B呢越差哦
23:37 如果越偏蓝色系就代表loss越小
23:40 就代表这一组W跟B呢越好
23:43 拿这一组跟W跟B呢放到我们的function里面
23:47 放到我们的model里面
23:48 那我们的预测会越精准啊
23:51 所以你就可以
23:52 所以你就知道说诶
23:53 假设W带-0.25
23:56 这个B呢大于-500
23:58 就代表说了这个W在-0.25B代表-500
24:02 就代表说这个频道每天看的人越来越少
24:04 而且lose是很大
24:05 只能真实的状况不太可
24:07 如果W带0.75B1带500
24:13 这个正确率会啊
24:14 这个会这个估测呢会比较精准
24:17 那估测最精准的地方看起来应该是在这里啊
24:20 如果你今天W带一个很接近一的值
24:23 必须带一个小小的值
24:25 比如说100多
24:26 那这个时候估测是最精准的
24:29 那这跟大家预期可能是比较接近的
24:32 就是你拿前一天的点阅的总次数去预测
24:36 隔天的点阅的总次数
24:38 那可能前一天跟隔天的点阅的总次数
24:41 其实差不多的
24:42 所以W是一
24:42 然后B呢设一个小一点的数值
24:46 也许你的估测就会蛮精准的
24:49 那像这样子的一个等高线图啊
24:51 就是你试着试了不同的参数
24:54 然后计算它的north画出来的这个等高线图哇
24:58 叫做error的surface好
25:02 那这种是机器学习的第二步好
25:05 那接下来我们进入机器学习的第三步
25:09 那第三步要做的事情
25:11 其实是解一个最佳化的问题
25:14 那如果你知道最佳化的问题是什么的话
25:16 也没有关系
幻灯片 20 - 23:优化 - 梯度下降
- 介绍优化过程使用梯度下降算法。
- 通过图像展示误差表面(Error Surface),说明损失是参数的函数,并解释如何通过计算正负梯度来更新参数,以减小损失。
- 讨论了局部最小值和全局最小值问题,以及在大多数深度学习框架中优化过程的便捷性。

25:17 我们今天要做的事情就是找一个W跟B
25:21 把未知的参数找一个数值出来
25:24 看带哪一个数值进去
25:26 可以让我们的大L让我们的loss的值最小
25:30 那个就是我们要找的W跟B
25:33 那这个可以让loss最小的W跟B啊
25:35 我们就叫做w star跟b star
25:39 代表说他们是最好的一组
25:40 W跟B可以让loss的值最小好
25:45 那这个东西要怎么做呢
25:47 在这门课里面
25:49 我们唯一会用到的optimization的方法
25:52 叫做gradient descent
25:55 好像这个gradient descend这个方法怎么做呢
25:57 他是这样做的
25:58 为了简化起见
25:59 我们先假设我们未知的参数只有一个啊
26:02 就是W我们先假设没有B那个位置的参数
26:06 只有W这个位置的参数
26:08 那当我们W在不同的数值的时候
26:11 我们就会得到不同的loss
26:14 那这一条曲线就是apple surface
26:17 只是刚才在前一个例子里面
26:18 我们看到的error surface是二二维的
26:21 是2D的
26:22 那这边只有一个参数
26:24 所以我们看到的这个error surface是1D的好
26:29 那怎么样找一个W去让这个loss的值最小的
26:34 那首先呢你要随机选取一个初始的点啊
26:39 这个初始的点我们叫做ARU0
26:42 那这个初始的点往往真的就是随机的
26:46 就是随便选一个真的都是随机的
26:48 那在往后的课程里面
26:50 我们其实会看到
26:51 也许有些方法可以给我们一个比较好的
26:55 W0的值
26:56 那我们先不讲这件事
26:57 是我们先当做就是随机的
27:00 随便掷个骰子
27:01 随机决定说W0的值应该是多少

27:04 那假设我们随机决定的结果是在这个地方好
27:08 那接下来呀
27:09 你就要计算说这个在W等于W0的时候
27:14 他就这个参数对loss的微分是多少
27:18 那我假设你知道微分是什么
27:20 你知道微分是什么
27:21 这对你来说不是个问题
27:23 就计算W等于loss的微分是多少
27:27 而如果你不知道微分是什么的话
27:29 那没有关系
27:30 反正我们做的事情就是计算在这一个点
27:34 在W0这个位置呃
27:37 这个error surface的切线斜率也就是这一条蓝色的虚线
27:44 它的斜率
27:45 但如果这个这条曲线的斜率是负的
27:48 那代表什么意思呢
27:50 代表说左边比较高
27:52 右边比较低
27:53 代表在这个位置附近
27:54 左边比较高
27:55 右边比较低
27:56 那如果左边比较高
27:58 右边比较低的话
27:59 那我们要做什么样的事情呢
28:00 如果左边比较高
28:01 右边比较低的话
28:03 那我们就把W的值变大
28:05 那我们就可以让loss变小
28:08 如果算出来的斜率是正的
28:11 就代表说左边比较低
28:12 右边比较高
28:13 是这个样子啊
28:14 左边比较低
28:15 右边比较高
28:16 如果左边比较低
28:17 右边比较高的话
28:19 那就代表左代表我们把W变小嘛
28:21 W往左边移
28:22 我们可以让roll loss的值变小
28:24 那这个时候你就应该把W的值变小
28:28 那假设你连斜率是什么的话
28:30 是什么都不知道的话
28:32 也没有关系
28:32 我就想像说有一个人站在这个地方
28:35 然后呢他左右环视一下
28:38 那这个算微分这件事啊
28:41 就是左右反式
28:42 然后他会知道说左边比较高还是右边比较高
28:44 看哪边比较低
28:45 他就往比较低的地方跨出一步
28:49 那这一步要跨多大呢
28:51 这一步的步伐的大小啊
28:53 取决于两件事情
28:55 第一件事情是这个地方的斜率有多大
28:59 这个地方斜率大
29:00 这个步伐就画大一点
29:02 斜率小步伐就画小一点
29:05 另外除了斜率以外
29:08 就是除了这个微分这一项和微分这一项
29:10 我们刚才说他就代表了斜率
29:12 除了微分这一项以外
29:13 这个还有另外一个东西会影响步伐的大小
29:16 这个东西我们这边用艾塔来表示
29:19 这个艾塔叫做learning rate
29:23 叫做学习速率
29:25 这个learning rr它是怎么来的呢
29:27 它是你自己设定的
29:29 你自己决定这个A塔的大小
29:31 如果A塔设大一点
29:33 那你每次参数它data的就会量很大
29:37 你的学习可能就比较快
29:38 如果ELA设小一点
29:40 那你参数的update就很慢
29:42 每次都会只会改变一点点参数的数值
29:46 那这种你在做机器学习需要自己设定的东西
29:50 叫做HYPERPARADIOR
29:53 这个我们刚才想说
29:55 机器学习第一步就是定一个有未知参数的function
30:00 而这些参数
30:01 这些未知的参数是机器自己找出来的

36:21 但之后会再告诉你说
36:23 gradient descend真正的痛点到底是什么
36:29 好那刚才举的是只有一个参数的例子而已
36:34 那我们实际上我们刚才模型有两个参数
36:36 有WW跟B那有两个参数的情况下
36:40 怎么用gradient descend呢
36:42 其实跟刚才一个参数没有什么不同
36:44 如果一个参数你没有问题的话
36:46 你可以很快的推广到两个参数
36:49 好我们现在有两个参数
36:51 那我们给它两个参数
36:53 我们都给它随机的初始的值就是W0跟B0
36:57 然后接接下来呢你要计算W对loss的微分
37:02 你要计算B对loss的微分计算在哪里
37:05 计算是在W等于W0的位置
37:08 B等于B0的位置
37:09 在W等于W0的位置
37:11 B等于V0的位置
37:12 你要计算W对L的微分计算
37:15 一对L的微分计算完以后
37:19 就根据我们刚才一个参数的时候的做法
37:22 去更新W跟B啊
37:24 W0减掉learning rate乘上微分的结果得到w one
37:29 把B0减掉learning rate乘上微分的结果得到b one
37:34 那有的同学可能会问
37:35 说嘶这个微分这个要怎么算呢
37:39 呃在这么你不会算微分的话
37:42 不用紧张
37:44 怎么不用紧张呢
37:46 在deep learning的framework里面
37:49 或在我们做一会用的PYTORCH里面
37:52 这个算微分呐
37:53 都是程序自动帮你算的
幻灯片 24 - 25:线性模型的局限性
- 以预测 2021 年视频观看量为例,将 2017 - 2020 年训练数据上建立的线性模型应用到 2021 年数据上,发现线性模型存在严重局限性,红色(实际观看量)和蓝色(估计观看量)曲线差异较大。

12:12 在這段內容中,我們探討了如何利用已知的數據來預測未來的點閱次數。這涉及到模型的建立及未知參數的估算,並強調了領域知識在機器學習中的重要性。
-我們定義了模型的基本結構,其中Y是我們要預測的點閱次數,B與W則是未知的參數。這些參數的估算需要依賴於我們對問題的理解和領域知識的應用。
-在建立模型的過程中,損失函數(loss)起到了重要的作用。它用來評估所選參數在預測未來點閱數時的準確性,並指導我們調整參數以達到更好的預測效果。
-訓練資料在計算損失函數時是必不可少的。我們需要利用過去的點閱次數數據來評估預測模型的準確性,以便逐步改善模型的表現。

18:17 在這段影片中,討論如何利用歷史數據預測YouTube頻道的點閱次數,並分析預估值與實際值之間的差距。這些數據有助於評估預測模型的準確性,從而提高未來預測的準確性。
-透過比較預測值與實際值,我們發現預測模型存在高估情況,這對頻道的點閱數可能造成誤導。預測值5.3K與實際值4.9K的差距,顯示出模型的改進空間。
-影片提到使用不同方法計算預測誤差,包括絕對值和平方差。這些方法可用來衡量模型的好壞,並選擇合適的損失函數來優化模型效果。
-在分析不同的損失函數時,影片強調選擇合適的計算方法取決於具體需求。這影響模型的表現和預測準確性,因此對於機器學習而言,選擇正確的損失函數至關重要。


24:20 在機器學習中,最佳化問題的解決至關重要,特別是尋找能最小化損失值的參數W和B。這個過程通常使用梯度下降法進行,透過不斷調整參數來達到最佳效果。
-為了預測點閱次數,可以利用前一天的數據進行估算。如果設置適當的參數值,則可以達到較高的預測準確度,這是機器學習的基本概念之一。
-在最佳化過程中,W和B的選擇對損失函數的最小化至關重要。找到最佳的W和B值,即w star和b star,使得損失最小,這是機器學習中的核心任務。
-梯度下降法是一種常用的最佳化方法,它依賴於計算損失函數的斜率來調整參數。這種方法的步伐大小受斜率和學習速率的影響,學習速率的設置對算法的效率有重大影響。
30:22 loss函數可以是負值,因為它由使用者自行定義,這意味著使用者可以根據需求設計出不同的loss函數。雖然在某些情況下loss的定義可能不會出現負值,但使用者的定義仍然有彈性。
-loss函數的形狀和定義是由使用者決定的,這意味著可以創建出各種不同的損失曲線。這種靈活性讓機器學習模型可以根據特定任務進行調整和優化。
-HYPERPARAMETER是機器學習過程中需要自行設定的參數,這些參數會影響模型的學習過程與效果。使用者需根據實際情況調整這些參數以獲得最佳結果。
-gradient descent方法在尋找最小值時可能陷入local minima,導致模型無法找到global minima。這一點在實務操作中非常重要,因為它會影響模型的最終表現。
36:29 在進行多參數的梯度下降時,對於每個參數都需計算對損失函數的微分,然後根據這些微分來更新參數的值。這個過程與單參數的情況相似,關鍵在於如何有效地計算和更新這些參數。
-在使用梯度下降法時,初始值的選擇對於最終結果影響很大。隨機選擇的初始值可能會導致不同的收斂結果,因此需謹慎設定初始參數W0和B0。
-計算微分的過程可以通過深度學習框架自動化完成,使用者只需撰寫簡單的程式碼即可獲得所需的微分值。這降低了對數學知識的依賴,使得更多人能夠進行模型訓練。
-在訓練過程中,持續更新參數W和B是尋求最佳解的關鍵。透過不斷的迭代,最終能找到使損失值最小的參數組合,這對於預測的準確性至關重要。
42:33 透過分析觀看人次的數據,我們發現模型的預測精度受到時間週期的影響。這意味著考慮更多的歷史數據,如前七天的觀看人次,可以顯著提高預測的準確性。
-在進行數據分析時,我們使用每天的觀看人次來預測隔天的數據,並計算出平均誤差值。這樣的分析持續進行,直到情人節的數據收集完成。
-模型的預測結果顯示,僅僅依賴前一天的數據進行預測並不夠準確。透過觀察數據的周期性,我們發現每週五和六的觀看人次特別低,這是需要考慮的因素。
-為了提高預測的準確性,我們提出了一個新模型,考慮到前七天的觀看人次。這樣的調整使得訓練數據的誤差值顯著下降,顯示出模型的改進效果。
48:36 考慮不同天數的數據對於預測準確性至關重要。在實驗中,使用前28天和56天的數據進行預測,結果顯示在訓練資料和未見過的資料上表現有所不同。
-在考慮前七天的預測基礎上,若擴展至28天的資料,訓練資料上的效果提高至0.33K,未見過的資料則達到0.46K,顯示出考慮更多數據的潛力。
-進一步考慮56天的數據,發現訓練資料略微下降至0.32K,但未見過的資料仍保持在0.46K,這顯示出考慮天數可能達到一定的極限。
-這些預測模型使用feature乘以weight再加上BIOS來得到結果,這類模型被稱為linear model,後續將探討如何進一步改進這些模型的性能。




















幻灯片 26 - 31:改进方向 - 增加特征和激活函数
- 探讨如何用分段线性曲线近似连续曲线,介绍 sigmoid 函数及其操作(改变斜率、平移、改变高度),并提出新模型需要增加特征。
- 介绍 Rectified Linear Unit (ReLU) 作为激活函数,对比不同激活函数(线性、10 ReLU、100 ReLU、1000 ReLU)在 2017 - 2020 年和 2021 年数据上的损失情况。
- 进一步对比不同隐藏层数量(1 层、2 层、3 层、4 层)在相同条件下的损失情况,其中每层使用 100 ReLU 作为激活函数,输入特征为过去 56 天的观看量。