目录
前言
数据分页的作用
RuoYi中的实现步骤
前端的显示界面(实例介绍)
源码分析(前端)
Pagination(分页组件)介绍
前端:getList()(方法源码分析)
源码分析(后端)
后端:List()(源码分析)
pagehelper.startpage()方法
roleService.selectRoleList()
getDataTable()
rspData.setTotal()分析
LIMIT ? 的含义
前言
部署好的项目,随着时间的变迁,后端的数据也会变得越来越庞大,慢慢的系统响应时间增长,用户体验下降,我们后端的SQL服务由于慢慢增加的“载重”,犹如从一辆快速的高铁变成充满负荷的绿皮火车,这个时候“乘客”的压力就给到了我们这些对这个列车负责的“人员”,我们应该立即采取行动,对系统进行优化升级。通过数据分页,数据库索引优化,查询缓存,分表分库等策略,减轻SQL服务的负担,提升数据处理效率。同时,加强系统监控,及时发现并解决性能瓶颈,确保列车安全、准时地抵达每一位“乘客”的目的地,重拾用户的信任与满意度。
//**********************一声巨响牛马登场,(nvliz o.o)***********************//
数据分页的作用
1. 提高用户体验 : 当数据量很大时,一次性加载所有数据会给用户造成浏览和查找的不便,分页可以减少单次加载的数据量,使用户能够更快地找到他们需要的信息。
2. 减轻服务器压力 : 如果服务器一次性返回大量数据,会占用大量服务器资源,可能导致服务器响应缓慢甚至崩溃。分页可以减少单次请求的数据量,降低服务器的负载。
3. 优化网络传输 : 在网络传输数据时,分页可以减少数据传输量,降低网络拥塞的可能性,特别是在移动网络环境下,这一点尤为重要。
4. 节约存储空间 : 在某些应用场景下,如缓存数据到本地,分页可以减少需要缓存的数据量,节约存储空间。(瞎编的o.o,有些框架的机制会缓存到本地,应该可以减少储存空间)
RuoYi中的实现步骤
接下来,用二次开发的万金油框架RuoYi来具体展示数据分页的实现步骤。怪不得人家优秀呢人家在我们进行二次开发前就给我们铺好路了,站在巨人的肩膀上就是看的远啊~~~~~。
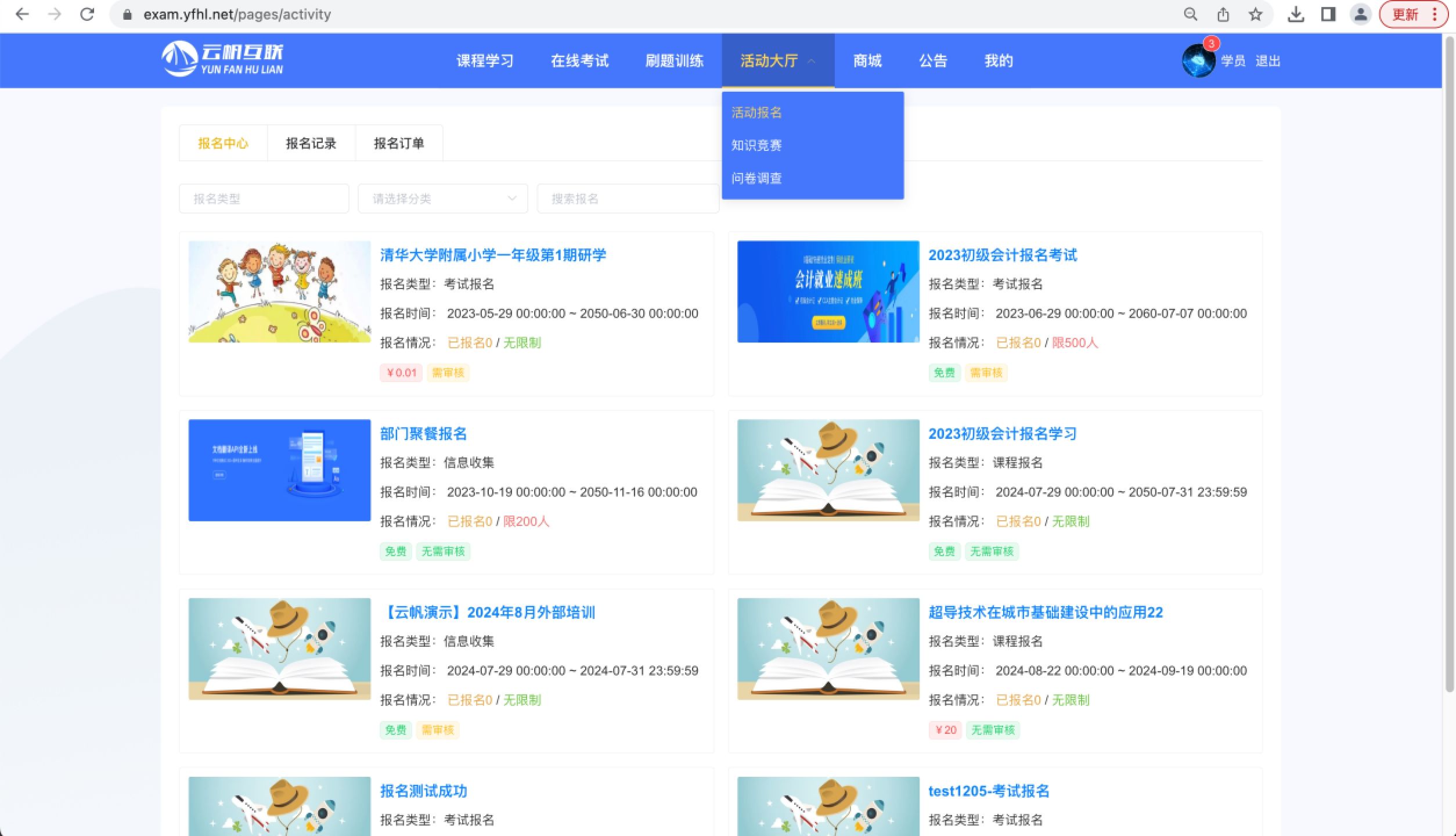
前端的显示界面(实例介绍)

在这张图片中,这个路径下,你可以看到数据库返回的部分,右下角是RuoYi在实现分页的前端显示,可以看到一共有两条记录。
源码分析(前端)
进入到这个路径下,在这个index.vue的文件中我们可以看到上面实例界面的前端代码。
路径://(RuoYi-Vue----ruoyi-ui----src----views----system----role-----index.vue)

Pagination(分页组件)介绍
在前端中有一个专门给数据分页的分页组件叫 Pagination ,Pagination 组件是前端开发中常用的一种用户界面元素,它用于在长列表数据或大量内容中实现分页显示。
Pagination 组件是一组用于在多个页面之间导航的控件,通常包括页码链接、上一页和下一页按钮,有时还包括直接跳转到首页和尾页的链接,RuoYi兼具上述所有的功能。
找到index.vue文件下的pagination组件,如下图:

上面需要注意是双向绑定的作用:双向绑定是Vue.js(以及其他一些前端框架,如Angular)中的一个核心概念,它允许开发者在一个方向上自动更新数据的同时,在另一个方向上也自动更新。这意味着当数据模型(通常是JavaScript对象)的状态发生变化时,视图(即DOM元素)会自动更新以反映这些变化;反之,当视图中的数据发生变化(例如用户输入)时,绑定的数据模型也会自动更新。
所以根据图中的注释,可以得出的信息是,在分页组件中,最主要的逻辑就是通过getList()方法重新获取数据列表,换句话描述,分页功能的实现,他的核心是getList的这个方法。
前端:getList()(方法源码分析)
首先,我们进入到这个方法中去,他的代码如下:

图中可能些许凌乱,这里做一个总结:就是调用后端一个API接口,获取到它的返回值,根据返回值中的总条数进行分页。
我们也可以打开开头展示的实例的浏览器的检查界面来看里面具体的一些参数:

感觉太小o.o,我们可以切换到负载界面:

切到预览看后端返回的数据:

后端的日志:

到这呢,我们前端的工作的就完毕了,接下来我们分析我们后端的代码
源码分析(后端)
在后端,通过GetMapping("/list") 去响应前端的Http请求。

路径为~~~~上面自己看太长了QAQ,藏宝一样的。
后端:List()(源码分析)
注意:这里的list是个数组,并不是一个方法名,下面图中是TableDataInfo list(SysRole role),方法签名为TableDataInfo(),list是该方法中的属性,在返回的参数这一点也可以体现。

pagehelper.startpage()方法
上面的图中提到startPage()是mybatis提供的一个方法,但是在这个方法里面我们没有刚才看到的那两个值(pagename和pagesize),说明他在这里应该只是一个调用,并没有真正的实现分页的功能,他只是把这个pagehelper.startpage()封装到了这个方法里面,我们按住ctrl,进入到这个方法里面去看一下:

欸嘿,它里面居然还是个调用,敲个代码,玩起推理来了。
此处应该有:就这样一层一层的拨开他的心。 -------------《洋葱》
我们在进:

如上这个方法函数的庐山真面目就出现了,可以看到参数的获取和分页参数的设置。
roleService.selectRoleList()
这是roleService接口中的一个方法,它的目的是根据传入的SysRole对象中的属性值来筛选数据库中的角色记录。这个方法使用MyBatis来实现数据访问。(AI生成) 他的背后应该是服务层的实现,使用了SQL或者mybatis的功能,去表里返回我们要查找的数据。(o.o上课听了,但是忘了)
getDataTable()
我们按照老样子进入到getDataTable():

在上图比较难以理解的就是最后那句
rspData.setTotal(new PageInfo(list).getTotal());
接下来详细分析一波:
rspData.setTotal()分析
首页创建了一个PageInfo对象(new PageInfo(list))

可以看到它是公共构造函数,它接受一个泛型列表List<T>作为参数。这个构造函数允许你创建一个PageInfo对象,它会包含整个列表,并且假设每页默认显示8条记录。这个PageInfo对象通常用于分页显示数据,它包含了分页所需的信息,如总记录数、总页数、当前页码等。
然后使用了.getTotal()的方法

传入的参数total值赋给当前对象的total字段。this关键字是对当前对象的引用。
rspData.setTotal(),他这的setTotal()其实就是上面的图片中的那个方法,确实有点多此一举了,但是这样前端就可以知道总共有多少条记录,从而正确地显示分页控件和进行分页操作。
到这Ruoyi的分页就全部分析完毕了。
(*************任务**********)
LIMIT ? 的含义
其他关于日志中LIMIT ? 后面值的含义。
答案:
1.当LIMIT后面只有一个数值时,这个数值表示返回的最大记录数。
2.当LIMIT后面有两个数值时,第一个数值表示返回记录的起始位置(从0开始计数),第二个数值表示返回的最大记录数

这是我截取的两端不同查询条件的日志,可以看到当我啥都不选择的时候,他的LIMIT后面是空的但是在我加上条件之后;

这里添加的条件是一段日期,可以发现在比较长的日志中,我们SQL语句已经改变。(即说明我们的答案)