说话人识别,又称声纹识别。从上世纪60年代开始到现在,声纹识别一直是生物识别技术研究的主题。从传统的基于模板匹配的方法,到早期基于统计学方法,直到基于深度学习的声纹识别技术成为主流。本项目给出一个从传统(基于GMM、GMM-UBM、GMM-SVM[3]、联合因子分析、i-vector的方法),到基于深度学习的声纹识别方法的实现。
1、基于GMM的声纹识别
1.1 测试环境:
操作系统:Windows10
代码环境:Python3.6
主要用到的开源库:sklearn、librosa、numpy
数据集:TIMIT语音识别数据集和我自己收集的有15个说话人,每个人6句话的小数据集(暂不公开)
1.2 在TIMIT数据集上进行测试
TIMIT语料库是为声学语音知识的获取(模型训练)以及自动语音识别系统(ASR)的评估(模型测试)而构建的,是由国防部赞助,在研究计划署(DARPA-ISTO)、麻省理工学院(MIT)、斯坦福研究院(SRI)、德州仪器(TI)共同努力下完成。说话人信息:由来自美国8个主要方言地区的630位说话者讲10个句子构成。10个句子分为:
**SA-**方言句子(Dialect sentence):由SRI设计,总共2句。每个人都会读SA1、SA2这两个句子,体现不同地区方言的差别。(因此可用于方言判断算法的数据集,而其他情况一般不用该类句子)
**SX-**音素紧凑的句子(Phondtically-compact sentence):由MIT设计,总共450句,目的是让句子中的音素分布平衡,尽可能的包含所有音素对。每个人读5个SX句子,并且每个SX句子被7个不同的人读。
**SI-**音素发散的句子(Phonetically-diverse sentence):由TI在现有语料库Brown Corpus与剧作家对话集(the Playwrights Dialog)挑选的,总共1890句。目的是增加句子类型和音素文本的多样性,使之尽可能的包括所有的等位语境(Allophonic context)。每个人读三个SI句子,并且每个SI句子仅被一个人读一次。
630个说话人被分为TRAIN(462人)和TEST(168人)。我只用到TRAIN的462个说话人语音数据。所以我的说话人样本数是462个。因为SA的两个句子是方言,所以我并没有用到这两个句子。其他8个句子,我是用SX的5个句子和SI的1个句子作为训练集,SI的另外2个句子作为测试集。并将6个训练句子合并为1个句子方便提取MFCC特征。
我自己在TIMIT数据集基础上划分的数据。[Baidu Driver | Google Driver]
也可下载TIMIT原始数据,根据你自己的情况划分数据。[Baidu Driver | Google Driver]
├─TEST(168人)
│ ├─DR1
│ │ ├─FCJF0
│ │ ├─FDAW0 .......
│ ├─DR2
│ │ ├─FAEM0
│ │ ├─FAJW0
......
│ ├─DR3
│ │ ├─FALK0
│ │ ├─FCKE0
......
├─TEST_MFCC(测试集提取MFCC,462人)
│ ├─spk_1
│ ├─spk_10
│ ├─spk_100
......
├─TRAIN(训练集数据,462人)
│ ├─DR1
│ │ ├─FCJF0
│ │ ├─FDAW0
......
│ ├─DR2
│ │ ├─MTJG0
......
│ ├─DR3
│ │ ├─FALK0
│ │ ├─FCKE0
......
└─TRAIN_MFCC(提取的训练集MFCC,462人)
├─spk_1
├─spk_10
├─spk_100
......
我使用Python实现的算法流程大致如下:
(1)提取24维MFCC特征。首先分别读入462个说话人的经过合并后的一段长语音(大概20s),MFCC特征提取过程与之前描述的在我自己小样本数据集上提取的过程一致,这里不再赘述。与之不同的主要有两点:第一,对于20s的语音提取MFCC之后特征维度大致为(2000,24)。因此需要将特征保存,避免重复提取。使用librosa提取的MFCC特征为numpy格式,因此我保存为.npy格式的文件,使用时load参数即可。第二,对462个说话人提取24维MFCC特征相当耗时,所以在实际代码实现时,我将462个说话人分为4批,对每一批分别开一个进程进行特征提取,运行效率提升了4倍左右。

(2)进行gmm训练。将每个说话人语音的24维MFCC特征参数作为输入,训练GMM。经过调参对比后,GMM的聚类数量设为3个,协方差矩阵选取full的效果最好。同样,gmm的训练过程也是多进行并行计算。
(3)测试说话人gmm模型。我使用SI中的1个句子作为测试数据(2s左右)。将2s语音作为输入,分别提取24维MFCC参数。然后分别将462个人的MFCC特征输入gmm模型,然后gmm对每一个输入进行打分。之后使用softmax将所有说话人的得分归一化到[0,1]区间,即得到每个说话人在当前gmm模型上的概率。概率最大的就是模型对应的说话人。
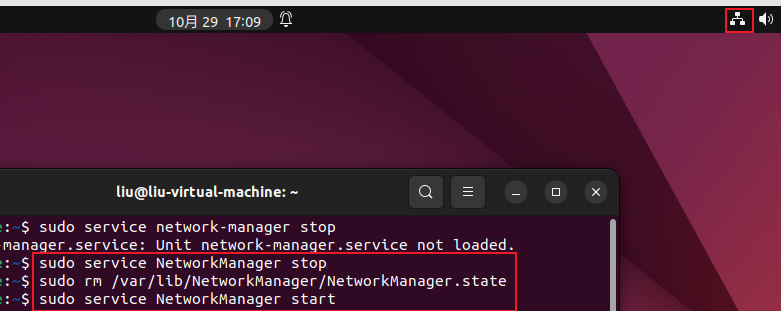
(4)测试结果:SI第一个句子的测试结果:验证正确的数量为294,验证错误的数量为168,识别准确率为63.6%。 SI第二个句子的测试结果为:验证正确的数量为204,验证错误的数量为258,识别准确率为44.2%。
2、基于self-attention的说话人识别
2.1 测试环境:
google colab(Telsa T4 -16G)
Pytorch 1.7.1
数据集:VoxCeleb数据集(选取其中600个说话人)
主要参考李宏毅2021年深度学习课程作业HW4。使用开源的声纹识别数据集VoxCeleb1,我们从中选取了其中600个说话人的数据,然后分别对这600个人的语音使用mel滤波器组提取40维特征,作为神经网络的输入。
网络结构部分,我们使用self-attention机制。下图是《attention is all you need》论文中提出的Transformer结构。主要分为编码器encoder和解码器decoder两部分。对于本网络只用到左侧的encoder部分。

简单介绍一下Transformer的encoder。Encoder可以由下面一组串联的Block组成。每一个Block是一个self-attention。

这里的self-attention的输出比传统的self-attention在输出之后又加了对应的输入。然后对相加后的结果做了Layer Norm。Layer Norm不同于Batch Norm。Batch Norm是对不同样本的同一个维度的不同特征计算mean和std。Layer Norm是计算同一个样本不同维度的相同特征计算mean和std,然后计算norm。之后再对做了norm的输出通过FC,然后相加,再做Layer Norm,然后输出。
说话人识别网络结构代码:
class Classifier(nn.Module):def __init__(self, d_model=80, n_spks=600, dropout=0.1):super().__init__()# Project the dimension of features from that of input into d_model.self.prenet = nn.Linear(40, d_model)self.encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, dim_feedforward=256, nhead=2)self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=2)# Project the the dimension of features from d_model into speaker nums.self.pred_layer = nn.Sequential(nn.Linear(d_model, n_spks),)def forward(self, mels):"""args:mels: (batch size, length, 40)return:out: (batch size, n_spks)"""# out: (batch size, length, d_model)out = self.prenet(mels)# out: (length, batch size, d_model)out = out.permute(1, 0, 2)# The encoder layer expect features in the shape of (length, batch size, d_model).out = self.encoder(out)# out: (batch size, length, d_model)out = out.transpose(0, 1)# mean poolingstats = out.mean(dim=1)# out: (batch, n_spks)out = self.pred_layer(stats)return outnet = Classifier()
summary(net.to("cuda"), (2,40), device="cuda")网络结构如下图所示:

接下来划分训练集和验证集。将90%的数据用于train,10%的数据用于validation。
由于说话人识别是一个分类问题,所以定义损失函数为CrossEntropyLoss(),在Pytorch中交叉熵损失把softmax和CrossEntropy都定义在nn.CrossEntropyLoss(),因此不需要再定义softmax,只需要将模型的输出和labels输入CrossEntropyLoss()即可。定义优化函数为AdamW,这是Adam的改进版本,有更好的优化效果。
训练过程如下图所示。训练过程共迭代70000次,每2000次做一次validation。从结果可以看出,训练集上的损失在不断下降,准确率在不断上升,训练结束时的准确率为91%,验证集的准确率为80%。











![[ComfyUI]FaceAging:太好玩啦!FaceAging终于装好了!负50到正100岁随心调整!超强又难装的节点安装教程来了! Comfyui教程](https://img-blog.csdnimg.cn/direct/4ef6c3c84f424b47afa657004903bf17.png)