Chapter 2:
大家到底在争论什么?
2022 年末,OpenAI 发布 ChatGPT 后不久,网上开始流传一个新的备忘录,它比其他任何东西都更能捕捉到这项技术的诡异之处。在大多数版本中,一个名为 "食人魔"(Shoggoth)的爱与魔法怪物,浑身长满触须和眼球,举着一个平淡无奇的笑脸表情符号,似乎在掩饰自己的真实面目。ChatGPT 在文字游戏的对话中表现得像人类一样平易近人,但在这一表象背后却隐藏着深不可测的复杂性和恐怖。(这是一种可怕的、难以形容的东西,比任何地铁都要大——一堆没有形状的原生质气泡",H.P.洛夫克拉夫特(H.P. Lovecraft)在其 1936 年的长篇小说《疯狂山脉》(At the Mountains of Madness)中写道。
 迪哈尔说,多年来,流行文化中最著名的人工智能试金石之一就是《终结者》。但通过免费上线 ChatGPT,OpenAI 让数百万人亲身体验到了不一样的东西。"她说:"人工智能一直是一种非常模糊的概念,它可以无止境地扩展,包含各种各样的想法。但 ChatGPT 让这些想法变得有形:"突然之间,每个人都有了一个具体的参照物"。什么是人工智能?对于数百万人来说,答案就在眼前:ChatGPT。
迪哈尔说,多年来,流行文化中最著名的人工智能试金石之一就是《终结者》。但通过免费上线 ChatGPT,OpenAI 让数百万人亲身体验到了不一样的东西。"她说:"人工智能一直是一种非常模糊的概念,它可以无止境地扩展,包含各种各样的想法。但 ChatGPT 让这些想法变得有形:"突然之间,每个人都有了一个具体的参照物"。什么是人工智能?对于数百万人来说,答案就在眼前:ChatGPT。
人工智能行业正在大力推销 "笑脸"。看看《每日秀》(The DailyShow)最近是如何讽刺行业领袖们的炒作的。
硅谷首席风险投资人马克-安德森(Marc Andreessen):"这有可能让生活变得更美好......老实说,我认为这是个骗局"。阿尔特曼:"我不想听起来像一个乌托邦式的科技兄弟,但人工智能所能带来的生活质量的提升是非凡的。"皮查伊"人工智能是人类正在研究的最深奥的技术。比火更深奥。"
乔恩-斯图尔特"是啊,去死吧,火!"
但正如该备忘录所指出的,ChatGPT 只是一个友好的面具。在它的背后,是一个名为 GPT-4 的怪物,一个由庞大的神经网络构建的大型语言模型,它所吸收的单词数量比我们大多数人一千辈子都读不完的单词还要多。在长达数月、耗资数千万美元的训练过程中,这些模型要完成的任务是从数百万本书和互联网上的大量内容中提取句子,并将其填入空白处。它们一遍又一遍地完成这项任务。从某种意义上说,它们被训练成了超强的自动完成机器。最终,这个模型将世界上大量的书面信息转化为一种统计表示,即哪些词最有可能紧跟其他词,并通过数十亿、数百亿的数值进行捕捉。
这是数学--大量的数学。没有人会质疑这一点。但这仅仅是数学,还是这种复杂的数学编码算法能够类似于人类的推理或概念的形成?
许多回答 "是 "的人都认为,我们已经接近实现人工通用智能(AGI),这是一种假想的未来技术,可以像人类一样完成各种任务。他们中的一些人甚至把目光投向了所谓的超级智能(superintelligence),一种能比人类做得更好的科幻技术。这群人相信,AGI 将彻底改变世界,但目的是什么呢?这是另一个矛盾点。它可能解决世界上所有的问题,也可能带来灭顶之灾。
如今,AGI 出现在世界顶级人工智能实验室的使命宣言中。但是,这个词是在 2007 年发明的,当时这个领域最著名的应用是读取银行存单上的笔迹或向你推荐下一本书。其目的是为了重拾人工智能的最初愿景,即人工智能可以做类似于人类的事情(稍后将详细介绍)。
谷歌 DeepMind 联合创始人谢恩-莱格(Shane Legg)去年告诉我,这其实是一种愿望,而非其他:“我并没有一个特别清晰的定义。”
AGI 成为人工智能领域最具争议性的想法。有些人把它说成是下一件大事:AGI 就是人工智能,但是,你知道,要好得多。另一些人则认为这个词过于模糊,以至于毫无意义。
"伊利亚-苏茨基弗(Ilya Sutskever)在辞去 OpenAI 首席科学家一职之前告诉我:"AGI 曾经是个肮脏的词。
但大型语言模型,尤其是 ChatGPT,改变了一切。AGI 从脏话变成了市场梦想。
这就引出了我认为当下最能说明问题的一场争论--这场争论为争论双方和利害关系埋下了伏笔。
在机器中看到了魔力
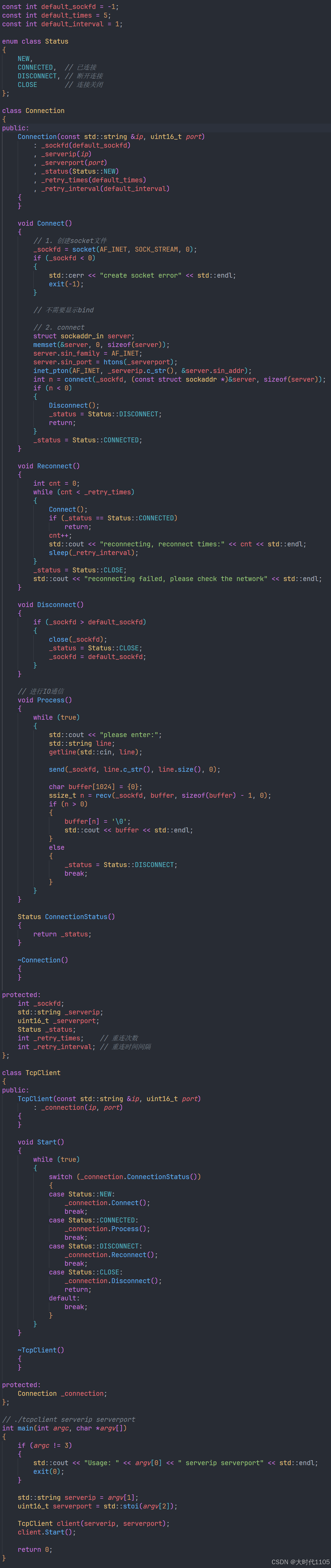
在 2023 年 3 月公开发布 OpenAI 的大型语言模型 GPT-4 之前几个月,该公司与微软共享了一个预发布版本,微软希望使用这个新模型来改造其搜索引擎必应。
当时,塞巴斯蒂安-布贝克(Sebastian Bubeck)正在研究 LLMs 的局限性,并对其能力持怀疑态度。特别是布贝克--位于华盛顿州雷德蒙德的微软研究院负责生成式人工智能研究的副总裁--一直在尝试用这种技术解决初中数学问题,但都以失败告终。比如x-y= 0;什么是x和 y?"他说:"我认为推理是一个瓶颈,是一个障碍。"我认为,要克服这个障碍,你必须做一些真正本质上不同的事情"。

然后,他拿到了 GPT-4。他做的第一件事就是尝试那些数学问题。"他说:"模型成功了。"坐在 2024 年的这里,GPT-4 当然可以解线性方程。但在当时,这太疯狂了。GPT-3 无法做到这一点。
但是,当 Bubeck 推动它做一些新的事情时,他才迎来了真正通往大马士革之路的时刻。
初中数学问题在互联网上随处可见,GPT-4 可能只是记住了它们。"布贝克问道:"你如何研究一个可能已经看过人类所写的一切的模型呢?他的答案是在一系列他和同事认为新颖的问题上测试 GPT-4。
布贝克与微软研究院的数学家罗宁-埃尔丹(Ronen Eldan)一起玩,要求 GPT-4 用诗句给出一个数学证明,即存在无限多个素数。
以下是 GPT-4 的回答片段:"如果我们取 S 中不在 P 中的最小数 / 称其为 p,我们就可以把它加到我们的集合中,你明白吗?/ 但这个过程可以无限重复。/ 因此,我们的集合 P 也一定是无限的,你会同意的"。
可爱吧?但 Bubeck 和 Eldan 认为它远不止这些。"我们当时在这个办公室里,"布贝克说着,通过 Zoom 向身后的房间挥了挥手。"我们都从椅子上摔了下来。我们简直不敢相信眼前的一切。这太有创意了,太与众不同了。
微软团队还让 GPT-4 生成了代码,在文字处理程序 Latex 中绘制的独角兽卡通图片上添加了一只角。布贝克认为,这表明该模型能够读取现有的Latex代码,理解其中的描述,并识别出角应该放在哪里。
他说:"有很多例子,但其中一些是推理的确凿证据。"推理是人类智能的重要组成部分。

布贝克、埃尔丹和微软的其他研究人员在一篇名为"人工通用智能的火花 "的论文中描述了他们的发现:"我们相信,GPT-4 的智能预示着计算机科学领域及其他领域的真正范式转变"。当布贝克在网上分享这篇论文时,他发了一条推特:"是时候面对它了,#AGI 的火花已经点燃"。
火花论文很快变得声名狼藉,并成为人工智能推崇者的试金石。Agüera y Arcas和彼得-诺维格(Peter Norvig)是谷歌前研究总监,也是《人工智能:现代方法》(Artificial Intelligence:现代方法》(可能是世界上最受欢迎的人工智能教科书)的合著者,共同撰写了一篇名为《人工通用智能已经到来》的文章。这篇文章发表在由洛杉矶智库伯格鲁恩研究所(Berggruen Institute)支持的杂志《Noema》上,他们的论点以斯帕克斯的论文为切入点:"他们写道:"对不同的人来说,人工通用智能(AGI)意味着许多不同的东西,但其中最重要的部分已经由目前这一代先进的人工智能大型语言模型实现了。"几十年后,它们将被公认为第一批真正的 AGI 范例。"
从那时起,炒作不断膨胀。利奥波德-阿申布伦纳(Leopold Aschenbrenner),当时是 OpenAI 专注于超级智能的研究员,去年告诉我:"过去几年,人工智能的发展异常迅速。我们碾压了所有的基准,而且这种进步有增无减。但我们不会止步于此。我们将拥有超人模型,比我们聪明得多的模型"。(今年 4 月,他被 OpenAI 辞退,原因是他声称,他提出了对自己正在开发的技术的安全担忧,"惹毛了一些人"。此后,他成立了一家硅谷投资基金)。
今年6月,阿申布伦纳发表了一份长达165页的宣言,认为到 "2025/2026年",人工智能的发展速度将超过大学毕业生,到本世纪末,"我们将拥有真正意义上的超级智能"。但业内其他人对这种说法嗤之以鼻。当阿申布伦纳在推特上发布了一张图表,显示他认为人工智能在过去几年中的进步速度有多快时,科技投资人克里斯蒂安-凯尔(Christian Keil)回复说,按照同样的逻辑,他的宝贝儿子从出生到现在已经长大了一倍,到他10岁时体重将达到7.5万亿吨。
毫不奇怪,"AGI 的火花 "也成了过火热闹的代名词。"马库斯在谈到微软团队时说:"我认为他们被冲昏了头脑。"他们很兴奋,就像'嘿,我们发现了什么!这太棒了!'。他们没有经过科学界的审核。"本德把斯帕克斯的论文称为 "同人小说"。
声称GPT-4的行为显示出AGI的迹象不仅具有挑衅性,而且在自己的产品中使用GPT-4的微软显然有兴趣推广这项技术的能力。一位科技公司的首席运营官在LinkedIn 上发帖说:"这份文件是伪装成研究的营销噱头。"
一些人还认为该文件的方法存在缺陷。它的证据很难验证,因为这些证据来自与一个版本的GPT-4的交互,而这个版本并没有在OpenAI和微软之外公开。布贝克承认,公开版本有限制模型功能的护栏。这使得其他研究人员无法重新创建他的实验。
一个研究小组试图用一种名为 Processing的编码语言重新创建独角兽的例子,GPT-4也可以用它来生成图像。他们发现,公开版本的 GPT-4 可以生成一个合格的独角兽,但不能将图像翻转或旋转 90 度。这看似是一个很小的差别,但当你声称画出独角兽的能力就是AGI的标志时,这种差别就真的很重要了。
斯帕克斯论文中的例子(包括独角兽)的关键在于,布贝克和他的同事认为它们是真正的创造性推理的例子。这意味着该团队必须确定,在 OpenAI 为训练其模型而收集的大量数据集中,不包含这些任务的例子或与它们非常相似的例子。
否则,这些结果可能会被解释为 GPT-4 重复了它已经见过的模式。

井上淳
布贝克坚持认为,他们只给模型设定了在互联网上找不到的任务。用乳胶绘制卡通独角兽肯定就是这样的任务。但互联网是个大地方。其他研究人员很快指出,网上确实有专门用乳胶画动物的论坛。"仅供参考,我们知道这件事,"布贝克在X 上回答说,"斯帕克斯论文的每一个疑问都在互联网上进行了彻底的查找。"
(这并没有阻止谩骂:加利福尼亚大学伯克利分校的计算机科学家本-雷希特(Ben Recht)在推特上回击说:"我要求你不要再做江湖骗子了。"他还指责布贝克 "被抓个正着"。
布贝克坚称这项工作是出于善意,但他和他的合著者在论文中承认,他们的方法并不严谨--只是记在笔记本上的观察,而不是万无一失的实验。
尽管如此,他并不后悔:"这篇论文已经发表一年多了,我还没有看到任何人给我一个令人信服的论据,比如说独角兽不是一个真实的推理例子。"
这并不是说他能直接回答我这个大问题--尽管他的回答揭示了他想给出什么样的答案。"什么是人工智能?布贝克向我重复道。"我想跟你说清楚。问题可以很简单,但答案可以很复杂。"
"有很多简单的问题,我们仍然不知道答案。而有些简单的问题却是最深刻的问题,"他说。"我把这个问题与生命的起源是什么?宇宙的起源是什么?我们从哪里来?诸如此类的大问题。
在机器中只看到数字
在本德成为人工智能支持者的主要对手之一之前,她曾作为共同作者发表过两篇颇具影响力的论文,从而在人工智能领域崭露头角。(她喜欢指出,这两篇论文都经过了同行评议--这与斯帕克斯的论文和其他许多备受关注的论文不同)。第一篇论文是与德国萨尔大学计算语言学家亚历山大-科勒(Alexander Koller)合作撰写的,发表于 2020 年,名为 "Climbing towards NLU"(NLU 即自然语言理解)。
她说:"对我来说,这一切的开端是与计算语言学领域的其他人争论语言模型是否能理解任何东西。(理解和推理一样,通常被认为是人类智能的基本要素)。
Bender 和 Koller 认为,完全基于文本训练的模型只能学习语言的形式,而不能学习语言的意义。他们认为,意义由两部分组成:词语(可以是标记或声音)加上说出这些词语的原因。人们使用语言有很多原因,比如分享信息、讲笑话、调情、警告某人退后等等。撇开语境不谈,用于训练 GPT-4 等 LLM 的文本可以让它们很好地模仿语言模式,使 LLM 生成的许多句子看起来与人类写的句子一模一样。但这些句子背后没有任何意义,没有任何火花。这是一个了不起的统计技巧,但却完全没有思想。
他们用一个思想实验来说明自己的观点。想象两个讲英语的人被困在相邻的荒岛上。有一条水下电缆可以让他们互相发送短信。现在设想有一只章鱼,它对英语一窍不通,但在统计模式匹配方面是个奇才,它用吸盘缠住电缆,开始监听短信。章鱼变得非常擅长猜测其他单词后面的单词。以至于当它弄断电缆并开始回复其中一位岛民的信息时,她以为自己还在和邻居聊天。(如果你没注意到,故事中的章鱼就是一个聊天机器人)。
与章鱼聊天的人会在合理的时间内保持被愚弄的状态,但这种状态能持续多久呢?章鱼能理解线下的内容吗?

井上淳
想象一下,岛民现在说她造了一个椰子弹射器,并要求章鱼也造一个,然后告诉她章鱼的想法。章鱼做不到。因为它不知道信息中的词语在这个世界上指的是什么,所以无法按照岛民的指示去做。也许它猜到了一个回复:"好的,好主意!"岛民可能会认为这意味着与她通话的人理解了她的信息。但如果是这样,她就会在没有意义的地方看到意义。最后,想象一下,岛民被熊袭击,向下发出求救信号。章鱼会怎么处理这些话呢?
本德尔和科勒认为,这就是大型语言模型的学习方式,也是它们受到限制的原因。"本德说:"这个思想实验说明了为什么这条路不会把我们引向能理解任何东西的机器。"章鱼的问题在于,我们给了它训练数据,即两个人之间的对话,仅此而已。 但是,如果突然出现了什么,它就无法处理了,因为它还没有理解。"
本德另一篇著名的论文《论随机鹦鹉的危险》强调了一系列危害,她和她的合作者认为制作大型语言模型的公司忽视了这些危害。这些危害包括:制作这些模型的巨大计算成本及其对环境的影响;这些模型所固化的种族主义、性别歧视和其他辱骂性语言;以及通过 "胡乱拼接语言形式序列......根据它们如何组合的概率信息,但不参考任何意义 "来愚弄人们的系统的危险性:随机鹦鹉。
谷歌高层对这篇论文并不满意,由此引发的冲突导致本德的两位合著者蒂姆尼特-格布鲁(Timnit Gebru)和玛格丽特-米切尔(Margaret Mitchell)被迫离开公司,他们曾在公司领导人工智能伦理团队。这也让 "随机鹦鹉 "成为了对大型语言模型的流行贬义词,并让本德陷入了骂名的漩涡之中。
对于本德和许多志同道合的研究人员来说,底线是该领域已经被烟雾和镜像所迷惑:"我认为,他们被引导去想象自主思考的实体,能够为自己做出决定,并最终成为那种能够真正为这些决定负责的东西"。
班德一直是语言学家,她现在甚至不愿意使用人工智能这个词,"如果不加引号的话",她告诉我。归根结底,对她来说,这是一个大科技公司的流行语,它分散了对许多相关危害的注意力。"她说:"我现在已经参与其中了。她说,"我关心这些问题,炒作阻碍了我"。
非同寻常的证据?
阿圭拉-伊-阿卡斯称本德这样的人为 "人工智能否认者"--言下之意是,他们永远不会接受他认为理所当然的东西。本德尔的立场是,非凡的主张需要非凡的证据,而我们没有。
但有人在寻找证据,直到他们找到一些明确的证据--火花或随机鹦鹉或介于两者之间的东西之前 他们宁愿坐以待毙这就是 "观望阵营"。
正如布朗大学研究神经网络的埃莉-帕夫利克(Ellie Pavlick)告诉我的那样"她补充说:"对某些人来说,通过这类机制重新创造人类智慧是一种冒犯。
她补充说:"人们对这个问题有着坚定的信念--几乎有一种宗教的感觉。另一方面,有些人还有点上帝情结。因此,暗示他们做不到也会让他们感到厌恶。
帕夫利克最终还是不可知论者。她坚持认为,她是一名科学家,科学引领她走向何方,她就跟到何方。她对那些荒诞的说法嗤之以鼻,但她相信这其中一定有令人兴奋的东西。"她告诉我:"我不同意本德尔和科勒的观点。"我认为实际上有一些火花--也许不是AGI的火花,但就像,里面有一些我们没想到会发现的东西。"
埃莉-帕夫利克
问题在于如何就这些令人兴奋的东西是什么以及它们为什么令人兴奋达成一致。在如此多的炒作之下,人们很容易变得愤世嫉俗。

像布贝克这样的研究人员,当你听他们把话说完时,会显得冷静许多。他认为内讧忽略了他工作中的细微差别。"他说:"我不认为同时持有不同观点有什么问题。他说:"有随机的鹦鹉学舌,推理是存在的——它是一个范围。这非常复杂。我们没有所有的答案。
"我们需要一个全新的词汇来描述正在发生的事情,"他说。"当我谈到大型语言模型的推理时,人们会反驳,原因之一是这与人类的推理不同。但我认为,我们不可能不把它称为推理。它就是推理"。
Anthropic的Olah在被问及我们在LLM中看到了什么时,表现得很谨慎,尽管他的公司是目前世界上最热门的人工智能实验室之一,它构建了Claude 3,这个LLM自今年早些时候发布以来,获得了与GPT-4一样多的夸张赞誉(如果不是更多的话)。
"他说:"我觉得很多关于这些模型能力的对话都非常部落化。他说:"人们都有自己的观点,而且没有任何一方的证据。然后它就变成了一种基于情绪的争论,而我认为互联网上基于情绪的争论往往会朝着不好的方向发展"。
奥拉告诉我,他也有自己的预感。"他说:"我的主观印象是,这些东西正在追踪相当复杂的想法。"我们并不全面了解超大型模型是如何运作的,但我认为我们所看到的很难与极端的'随机鹦鹉'图景相协调。"
他只能说到这里了:"我不想说得太多超出我们现有证据所能推断的范围"
上个月,《人类学》发布了一项研究结果,研究人员给克劳德3号的神经网络做了相当于核磁共振成像的检查。通过在运行过程中监测模型的哪些部分开启和关闭,他们确定了神经元的特定模式,这些神经元会在模型显示特定输入时激活。
Anthropic 还报告了与试图描述或展示抽象概念的输入相关的模式。"奥拉说:"我们看到了与欺骗和诚实、谄媚、安全漏洞和偏见有关的特征。"我们发现了与权力追求、操纵和背叛相关的特征。
这些结果最清晰地展示了大型语言模型的内部结构。它让我们看到了人类难以捉摸的特征。但它到底能告诉我们什么呢?奥拉承认,他们并不知道这个模型是如何处理这些模式的。"他说:"这是一幅相对有限的图景,分析起来相当困难。
尽管奥拉不愿意详细说明他认为克劳德3这样的大型语言模型内部到底发生了什么,但很明显,这个问题对他来说很重要。Anthropic 因其在人工智能安全方面的工作而闻名--确保强大的未来模型能以我们希望的方式运行。
未来模型的行为将符合我们的期望,而不会出现我们不希望出现的情况(行业术语称为 "对齐")。如果你想控制未来的模型,弄清今天的模型是如何工作的不仅是必要的第一步,它还能告诉你首先需要在多大程度上担心更糟糕的情况。"奥拉说:"如果你认为模型的能力不会很强,那么它们可能就不会很危险。"
内容来源:MIT Technology Review(机翻)
未完待续.......


![[笔记] Windows 上 Git 安装详细教程:从零开始,附带每个选项解析](https://i-blog.csdnimg.cn/direct/0cbb37965c644f2ab9044f7559020aaf.png)