在湖仓一体(Lakehouse)出现之前,数据仓库和数据湖堪称数据领域的两大“顶流”。打个比方,要是把数据仓库比作一座大型图书馆,那其中的数据就如同馆内藏书,需要按照规范放好,借阅者只需依照类别索引,便能精准找到想要的信息。反观数据湖,更像是一个大型仓库,海纳百川,可以存储任何形式和任何格式的原始数据。 然而,这两大传统模式各有掣肘。数据湖擅长存储大规模、非结构化数据,但缺乏数据治理和查询优化能力,导致数据“沼泽”现象频发;数据仓库可以提供强大的分析能力,但其扩展性和灵活性较差,尤其在处理非结构化数据时,表现不如数据湖。这些局限性导致了企业数据孤岛林立、重复管理耗时费力等问题,愈发难以契合现代企业在海量、多元数据浪潮冲击下的数智需求。 市场和行业都在呼唤着新一代数据架构模式的破局与革新,从传统数仓到结合数据湖和数据仓库两层架构,再到构建高性能计算引擎,直接在数据湖上进行数据探查以及分析。 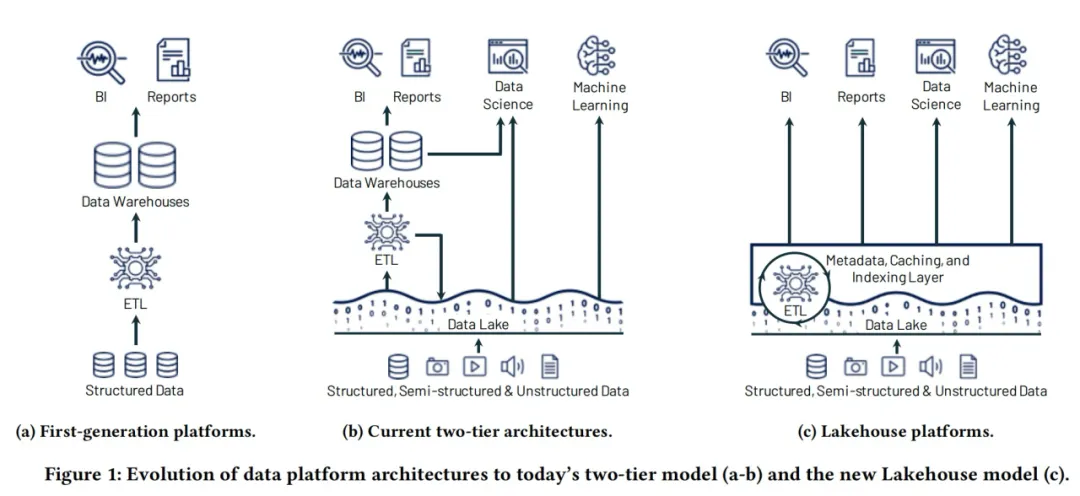 无外乎都在表明新的数据架构被期望具备以下功能: 能够提供ACID支持,支持插入/更新操作 具有高度的可扩展性,经济高效且灵活 优秀的BI性能以及数据仓库的访问控制机制 能够处理所有数据格式并支持多种用例的统一平台 而满足这些功能点的便是新的数据架构——湖仓一体Lakehouse
无外乎都在表明新的数据架构被期望具备以下功能: 能够提供ACID支持,支持插入/更新操作 具有高度的可扩展性,经济高效且灵活 优秀的BI性能以及数据仓库的访问控制机制 能够处理所有数据格式并支持多种用例的统一平台 而满足这些功能点的便是新的数据架构——湖仓一体Lakehouse
01什么是Lakehouse
Lakehouse本质上是一个带有附加事物层和高性能计算引擎的数据湖,从结构上来说可以拆成两个层面: 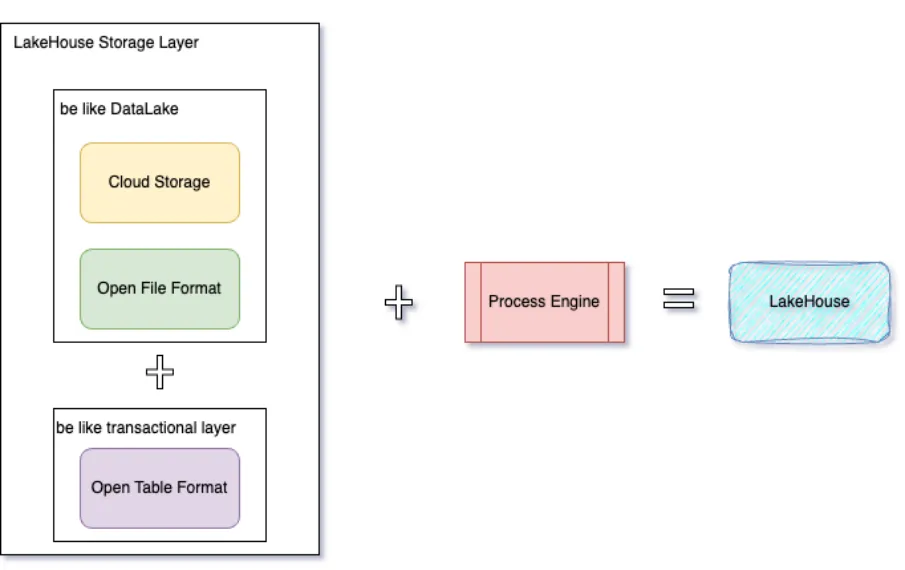 1、带有附加事物特性的存储层 这一层主要由三个组件组成:开放的表格式、开发的文件格式和云存储。
1、带有附加事物特性的存储层 这一层主要由三个组件组成:开放的表格式、开发的文件格式和云存储。 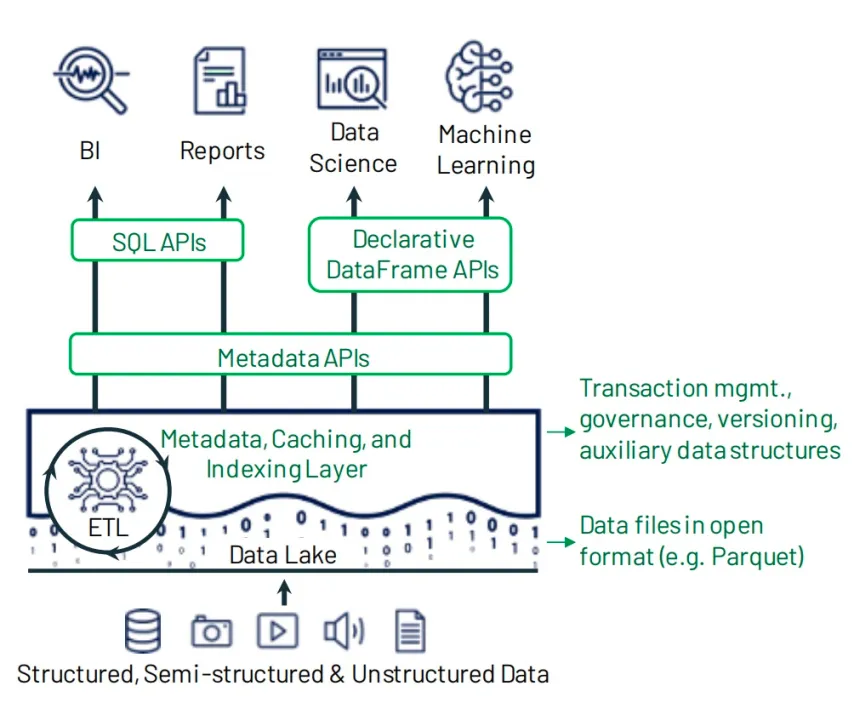
- 开放的表格式 可以理解为是提供类似数据仓库ACID数据和其他特性的元数据层(Metadata APIs),为了保持一致性,它提供了与事务相关的元数据。 目前开源社区比较流行的湖表格式有Apache Paimon、Apache Iceberg、Apache Hudi以及DeltaLake。每种表格式所侧重的能力不一样,用户可根据自身业务特性自由选择。
- 开放的文件格式 数据平台可以将不同文件格式的数据存储在云存储中,对于分析平台,最广泛采用的有Apache Parquet、Apache ORC、Apache AVRO。这几种都是开源的列式存储格式,很多存储和处理引擎都会兼容这几种存储格式。
- 云存储 云存储服务,如AWS的S3或阿里云的OSS对象存储,提供了高可用性、持久性和可扩展性等特性,是构建数据湖和Lakehouse平台的理想选择。 公司也可以使用本地 HDFS 存储来实施 Lakehouse,但考虑到成本低、计算与存储分离、易于扩展等特点,建议使用云对象存储作为实现 Lakehouse 的底层基础设施。
- 2、高性能的计算引擎层* 开放性,以及可由任何兼容处理引擎直接访问、或查询的能力是Lakehouse架构的主要优点之一,它不需要任何特定的专有引擎来运行BI以及Ad-hoc。这些引擎可以是开源的,比如Spark、Trino或者Presto;也可以是商业查询引擎,比如Starrocks以及selectDB。
02为什么要追求元数据的“大一统”
根据上文所述,Lakehouse架构采用了一种“开放”的方法来构建数据平台,允许我们自由选择开源的数据格式和计算引擎。与传统数据仓库相比,后者通常将计算与存储紧密绑定,这种设计虽然适用于特定场景下的数据处理,但面对海量数据时,容易出现错误且实施成本高昂。此外,由于其结构较为固定,当需要对大量数据进行处理或分析时,灵活性差,构建成本溢出。相比之下,Lakehouse架构可以使用与底层存储格式兼容的任何分布式计算引擎,在灵活性和兼容性方面有明显优势。 当然,“开放”带来灵活性的同时,也带来了其他的诸如跨查询引擎等互操作性引起的一些问题: - 1、多计算引擎间Catalog元数据难以管理* 企业用户通常会根据业务需求选择不同的计算引擎来处理和分析数据,而每个引擎都有自己的 catalog 元数据管理系统。想象一个简单的场景,对于同一个数据源下的同一张表,用户可能先用 Flink 完成数据采集,然后再用 Trino 或 Spark 来分析这些数据。这样一来,用户就不得不在每个计算引擎里重复创建 catalog 实例并注册表。随着数据源和表的数量增加,这种重复操作会变得越来越麻烦,时间和成本都会增加。而更糟糕的是,人工操作难免会出错,不同计算引擎之间的“catalog”元数据一致性也没法保证。
- 2、不同标准下的湖表元数据格式引起的“数据孤岛”效应* 如今,各种开源湖表格式层出不穷,每种表格式都有其独特的侧重点和与相关计算引擎的适配特性。比如,HUDI 强调高性能的实时写入,而 Iceberg 则侧重于数据分析。用户会根据不同的业务场景,选择与当前计算引擎适配度较高的表格式,以便更高效地实现业务需求。不同表格式在数据量暴增的情况下带来的数据存储成本和管理难度也在成倍增加,“数据孤岛”的问题变得越来越突出。
03利用DataLake实现元数据统一
DataLake是袋鼠云自研的,开放、一站式的湖仓一体管理工具,旨在帮助企业快速完成湖仓构建,实现“一键式”入湖,并通过对湖表进行统一治理,达到降本增效的目的,实现数据价值最大化。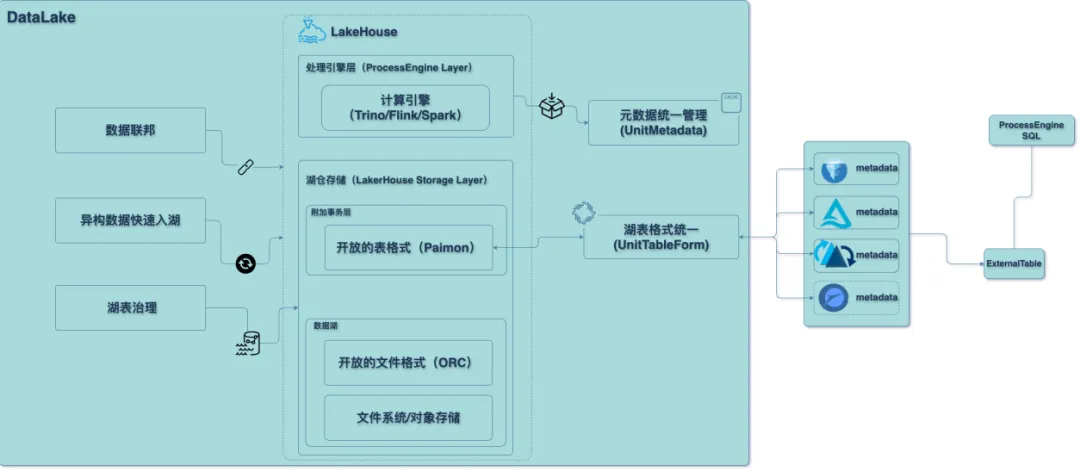
- 1、数据处理层* 从数据架构层面来讲,DataLake集成了袋鼠云基于开源二开后的Trino/Flink/Spark组件作为湖仓架构的数据处理层, 将数据的入湖效率大幅度提升,同时基于颠覆传统“insert-overwrite”模式的增量计算数据处理方式,来提高运行任务的效率,并降低不必要的资源开销。
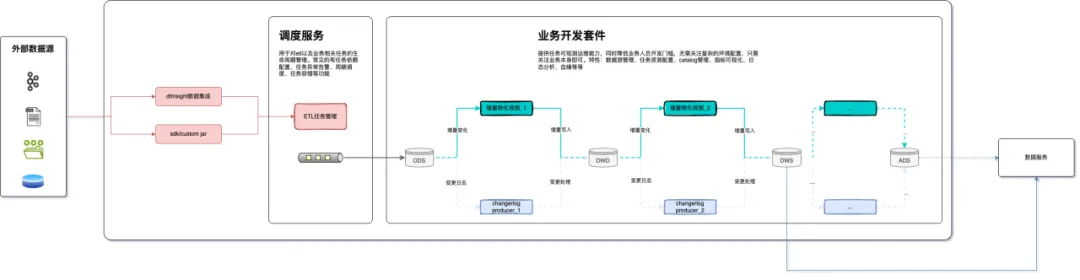
- 2、数据存储层* 在构建带有附加事务层的数据存储层时,DataLake采用了Paimon+ORC+HDFS/S3这样一套组合。 选择Paimon之前,我们进行了广泛的对比评估。从功能和性能方面来看,需要一个能够支持大批量实时入湖更新、分析性能不那么差且易于拓展的表格式。尽管Hudi提供了丰富的功能选项,但其使用过程相对复杂。在数据实时入湖方面,对比了云栖大会上给出的Paimon和Hudi的入湖更新性能:
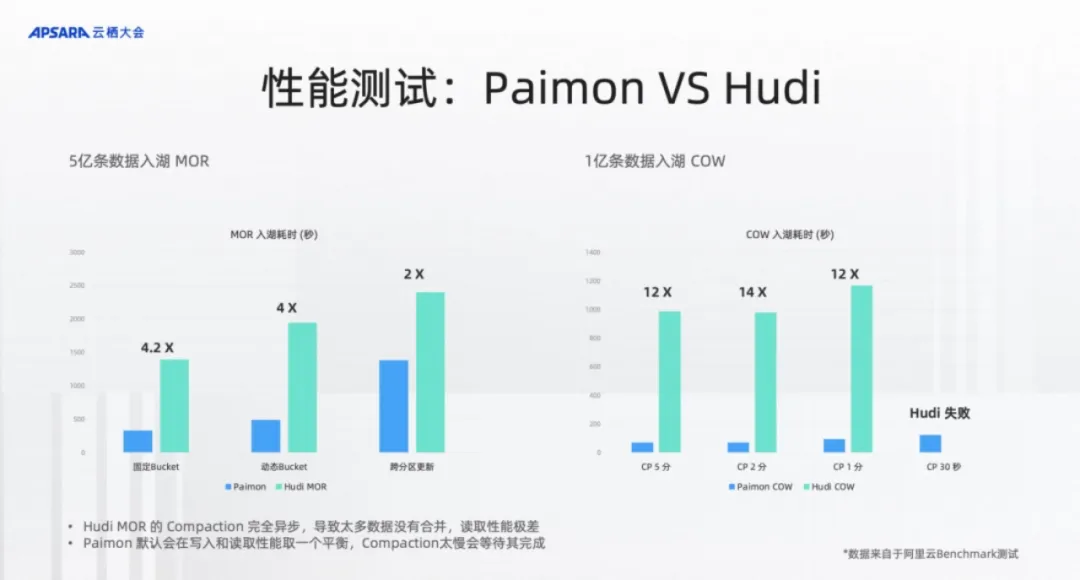 如图所示,针对大约5亿条记录的入湖操作,在相似配置及相同索引条件下进行测试,结果显示Paimon在吞吐量或耗时上达到了Hudi的四倍效率;而在查询性能上,Paimon的表现更是Hudi的10到20倍。此外,我们还观察到了Hudi在面对较小内存时无法读取数据的问题,深入分析后发现Hudi MOR是纯Append,虽然后台有compaction,也不会等待该过程完成,导致测试中Hudi的Compaction仅部分完成,进而影响了读取性能。 基于此,我们也做了图右的benchmark,就是1亿条数据的CopyOnWrite,来测试CopyOnWrite情况下的 compaction 性能。结果表明,无论是2分钟、1分钟还是30秒间隔,Paimon都表现出显著优势,性能差距达到12倍之多。特别是在30秒间隔下,Hudi无法正常运行,而Paimon仍能顺利完成任务。 另外,虽然Iceberg具有强大的扩展能力,并为其他计算引擎提供了许多优化接口,但它目前主要聚焦于离线处理场景,侧重于离线数据湖的分析处理。相比之下,Paimon在实时数据处理场景中展现了更优的整体表现。
如图所示,针对大约5亿条记录的入湖操作,在相似配置及相同索引条件下进行测试,结果显示Paimon在吞吐量或耗时上达到了Hudi的四倍效率;而在查询性能上,Paimon的表现更是Hudi的10到20倍。此外,我们还观察到了Hudi在面对较小内存时无法读取数据的问题,深入分析后发现Hudi MOR是纯Append,虽然后台有compaction,也不会等待该过程完成,导致测试中Hudi的Compaction仅部分完成,进而影响了读取性能。 基于此,我们也做了图右的benchmark,就是1亿条数据的CopyOnWrite,来测试CopyOnWrite情况下的 compaction 性能。结果表明,无论是2分钟、1分钟还是30秒间隔,Paimon都表现出显著优势,性能差距达到12倍之多。特别是在30秒间隔下,Hudi无法正常运行,而Paimon仍能顺利完成任务。 另外,虽然Iceberg具有强大的扩展能力,并为其他计算引擎提供了许多优化接口,但它目前主要聚焦于离线处理场景,侧重于离线数据湖的分析处理。相比之下,Paimon在实时数据处理场景中展现了更优的整体表现。 - 3、Catalog元数据统一管理* “UnitMetadata Service”是DataLake的Catalog表管理服务,本质上是对底层数据源实体在元数据层面的逻辑关系进行抽象的逻辑统一层。 在进行湖仓构建时,UnitMetadata Service会将构建的元数据信息缓存并持久化,随后自动根据当前服务中元数据的逻辑关系分别在对应计算引擎(通过数栈进行绑定的计算引擎)中建立与底层数据源实体的元数据的关系映射,以此来屏蔽不同计算引擎带来的Catalog难以管理的问题,同时,作为Catalog表管理的统一入口,规范化湖仓构建方式,避免同一Entry在引擎切换后进行查询带来的元数据不一致问题。
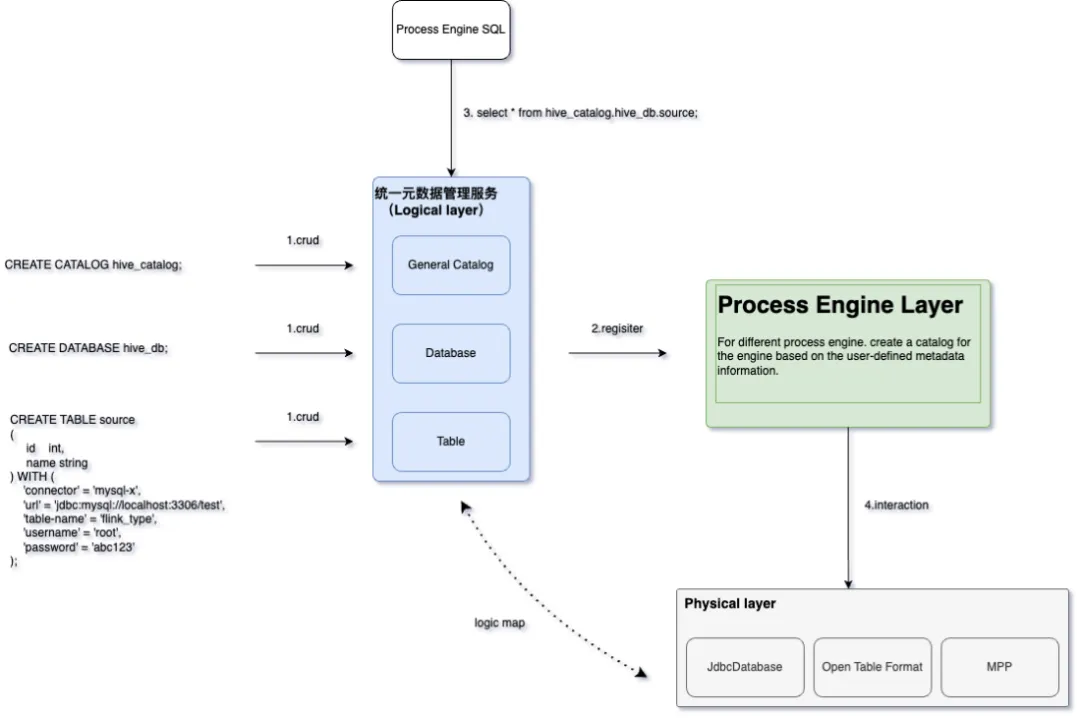
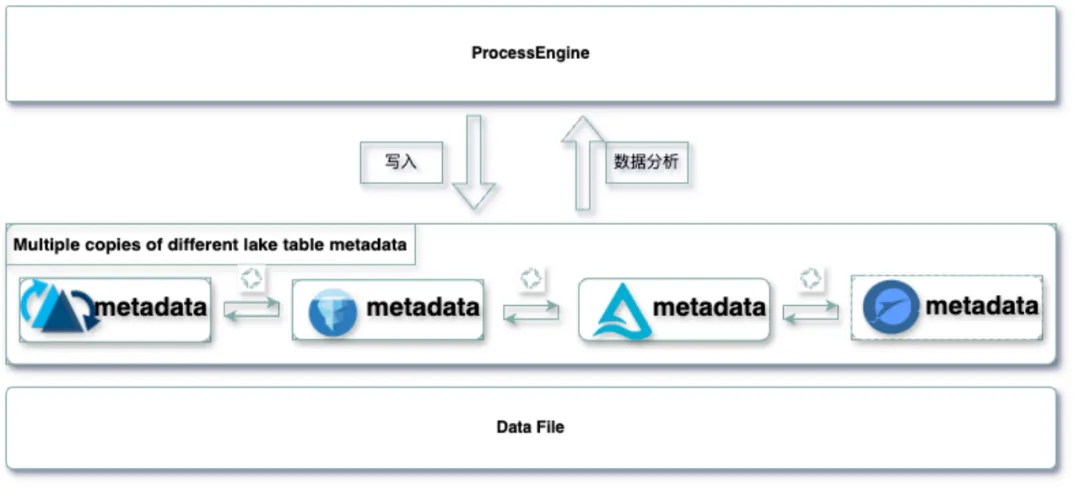
- 4、湖表格式元数据统一* “UnitTableForm Service”是DataLake的湖表元数据统一服务。Paimon作为与DataLake绑定的湖表格式,UnitTableForm能够使得通过其他湖表格式摄取的表转换为Paimon表,并支持其他湖表格式之间的元数据一键互转。这样用户无需复制或者移动湖表对应的底层数据文件,大幅度减少了数据的存储成本的同时还增强了与外部的“互操作性”,使得用户根据自己的历史技术架构选择对接合适的表格式,无需被束缚。
04写在最后
实现湖表格式和Catalog元数据的统一,仅仅是DataLake在湖仓架构下“大一统”的第一步。我们的长远目标是进一步开发带有HBO的极致统一查询能力,这将极大提升数据处理效率与查询性能,为企业提供更加高效、灵活的数智解决方案,帮助企业更好地利用数据资源,加速业务增长,在竞争激烈的市场环境中保持领先优势。 感兴趣的朋友可以点击DataLake了解更多关于详细内容。
参考文献: What is Lakehouse? 新型大数据架构之湖仓一体(Lakehouse)架构特性说明——Lakehouse 架构(一)
《数据资产管理白皮书》下载地址:https://www.dtstack.com/resources/1073/?src=szsm
《行业指标体系白皮书》下载地址:https://www.dtstack.com/resources/1057/?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001/?src=szsm
《数栈V6.0产品白皮书》下载地址:https://www.dtstack.com/resources/1004/?src=szsm
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szsm
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术群」,交流最新开源技术信息,群号码:30537511,项目地址:https://github.com/DTStack