ESPNet 系列
本文将会介绍 ESPNet 系列,该网络主要应用在高分辨率图像下的语义分割,在计算内存占用、功耗方面都非常高效,重点介绍一种高效的空间金字塔卷积模块(ESP Module);而在 ESPNet V2 上则是会更进一步给大家呈现如何利用分组卷积核,深度空洞分离卷积学习巨大有效感受野,进一步降低浮点计算量和参数量。
ESPNet V1 模型
ESPNet V1:应用在高分辨图像下的语义分割,在计算、内存占用、功耗方面都非常高效。主要贡献在于基于传统卷积模块,提出高效空间金子塔卷积模块(ESP Module),有助于减少模型运算量和内存、功率消耗,来提升终端设备适用性,方便部署到移动端。
ESP 模块
基于卷积因子分解的原则,ESP(Efficient spatial pyramid)模块将标准卷积分解成 point-wise 卷积和空洞卷积金字塔(spatial pyramid of dilated convolutions)。point-wise 卷积将输入的特征映射到低维特征空间,即采用 K 个 1x1xM 的小卷积核对输入的特征进行卷积操作,1x1 卷积的作用其实就是为了降低维度,这样就可以减少参数。空洞卷积金字塔使用 K 组空洞卷积的同时下采样得到低维特征,这种分解方法能够大量减少 ESP 模块的参数和内存,并且保证了较大的感受野(如下图 a 所示)。

上图 (b) 展示了 ESP 模块采用的减少-分裂-转换-合并策略。下面来计算下一共包含的参数,其实在效果上,以这种轻量级的网络作为 backbone 效果肯定不如那些参数量大的网络模型,比如 Resnet,但是在运行速度上有很大优势。
如上图所示,对 ESP 模块的第一部分来说, d d d 个 1 × 1 × M 1\times 1\times M 1×1×M 的卷积核,将 M 维的输入特征降至 d 维。此时参数为: M ∗ N / K M*N/K M∗N/K,第二部分参数量为 K ∗ n 2 ∗ ( N / K ) 2 K*n^{2}*(N/K)^{2} K∗n2∗(N/K)2,和标准卷积结构相比,参数数量降低很多。
为了减少计算量,又引入了一个简单的超参数 K,它的作用是统一收缩网络中各个 ESP 模块的特征映射维数。Reduce 对于给定 K,ESP 模块首先通过逐点卷积将特征映射从 m 维空间缩减到 N / K N/K N/K 维空间(上图 a 中的步骤 1)。通过 Split 将低维特征映射拆分到 K 个并行分支上。
然后每个分支使用 2 k − 1 , k = 1 , . . . , k − 1 2^{k-1},k=1,...,k-1 2k−1,k=1,...,k−1 给出的 n × n n\times n n×n 个扩张速率不同的卷积核同时处理这些特征映射(上图 a 中的步骤 2)。最后将 K 个并行扩展卷积核的输出连接起来,产生一个 n 维输出特征图。
下面代码使用 PyTorch 来实现具体的 ESP 模块:
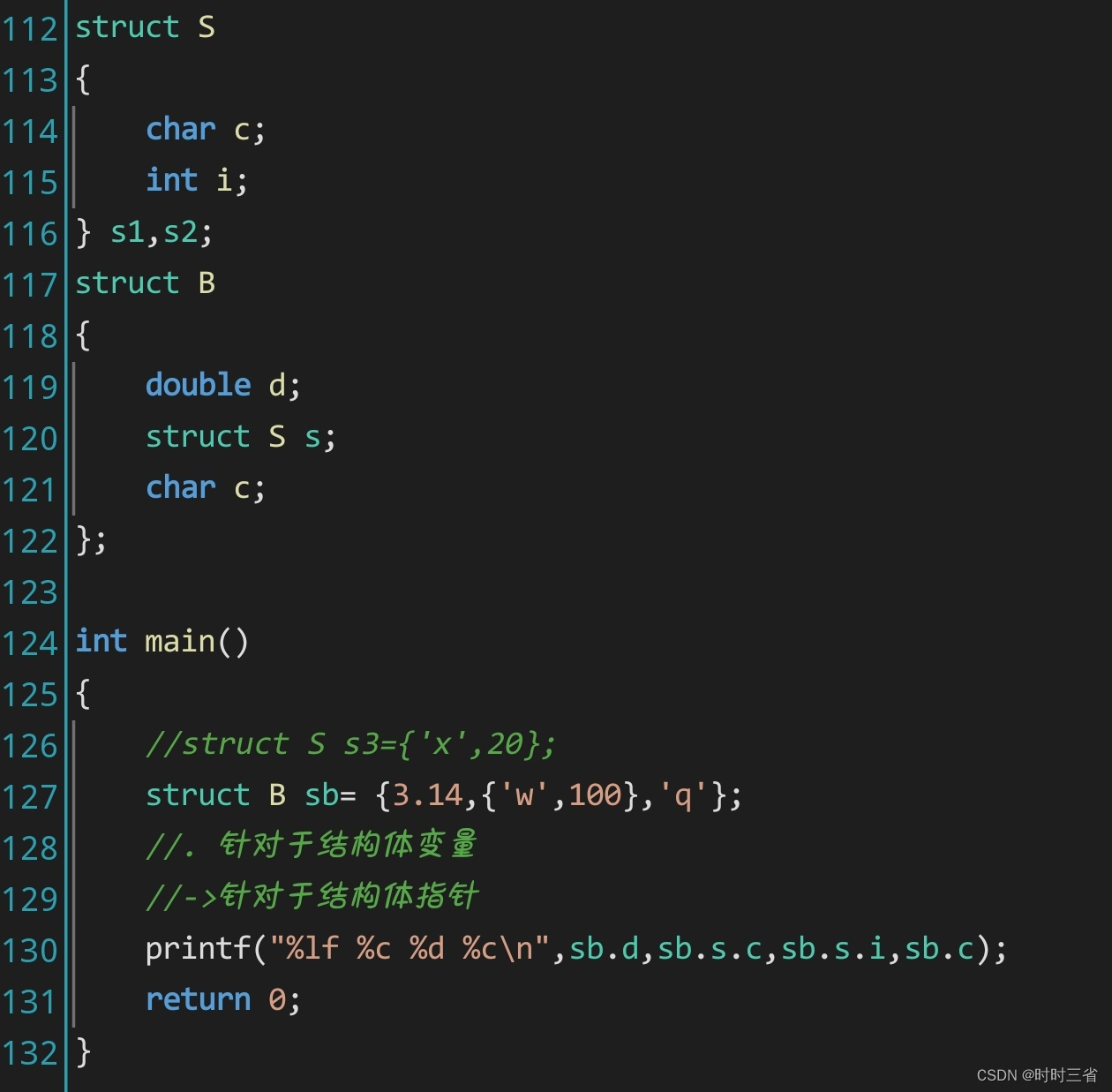
class ESPModule(nn.Module):def __init__(self, in_channels, out_channels, K=5, ks=3, stride=1,act_type='prelu',):super(ESPModule, self).__init__()self.K = Kself.stride = strideself.use_skip = (in_channels == out_channels) and (stride == 1)channel_kn = out_channels // Kchannel_k1 = out_channels - (K -1) * channel_knself.perfect_divisor = channel_k1 == channel_knif self.perfect_divisor:self.conv_kn = conv1x1(in_channels, channel_kn, stride)else:self.conv_kn = conv1x1(in_channels, channel_kn, stride)self.conv_k1 = conv1x1(in_channels, channel_k1, stride)self.layers = nn.ModuleList()for k in range(1, K+1):dt = 2**(k-1) # dilationchannel = channel_k1 if k == 1 else channel_knself.layers.append(ConvBNAct(channel, channel, ks, 1, dt, act_type=act_type))def forward(self, x):if self.use_skip:residual = xtransform_feats = []if self.perfect_divisor:x = self.conv_kn(x) # Reducefor i in range(self.K):transform_feats.append(self.layers[i](x)) # Split --> Transformfor j in range(1, self.K):transform_feats[j] += transform_feats[j-1] # Merge: Sumelse:x1 = self.conv_k1(x) # Reducexn = self.conv_kn(x) # Reducetransform_feats.append(self.layers[0](x1)) # Split --> Transformfor i in range(1, self.K):transform_feats.append(self.layers[i](xn)) # Split --> Transformfor j in range(2, self.K):transform_feats[j] += transform_feats[j-1] # Merge: Sumx = torch.cat(transform_feats, dim=1) # Merge: Concatif self.use_skip:x += residualreturn x
HFF 特性
虽然将扩张卷积的输出拼接在一起会给 ESP 模块带来一个较大的有效感受野,但也会引入不必要的棋盘或网格假象,如下图所示。

上图(a)举例说明一个网格伪像,其中单个活动像素(红色)与膨胀率 r = 2 的 3×3 膨胀卷积核卷积。
上图(b)具有和不具有层次特征融合(Hierarchical feature fusion,HFF)的 ESP 模块特征图可视化。ESP 中的 HFF 消除了网格伪影。彩色观看效果最佳。
为了解决 ESP 中的网格问题,使用不同膨胀率的核获得的特征映射在拼接之前会进行层次化添加(上图 b 中的 HFF)。该解决方案简单有效,且不会增加 ESP 模块的复杂性,这与现有方法不同,现有方法通过使用膨胀率较小的卷积核学习更多参数来消除网格误差[Dilated residual networks,Understanding convolution for semantic segmentation]。为了改善网络内部的梯度流动,ESP 模块的输入和输出特征映射使用元素求和[Deep residual learning for image recognition]进行组合。
网络结构与实现
ESPNet 使用 ESP 模块学习卷积核以及下采样操作,除了第一层是标准的大步卷积。所有层(卷积和 ESP 模块)后面都有一个批归一化和一个 PReLU 非线性,除了最后一个点卷积,它既没有批归一化,也没有非线性。最后一层输入 softmax 进行像素级分类。
ESPNet 的不同变体如下图所示。第一个变体,ESPNet-A(图 a),是一种标准网络,它以 RGB 图像作为输入,并使用 ESP 模块学习不同空间层次的表示,以产生一个分割掩码。第二种 ESP - b(图 b)通过在之前的跨步 ESP 模块和之前的 ESP 模块之间共享特征映射,改善了 ESPNet-A 内部的信息流。第三种变体,ESPNet-C(图 c),加强了 ESPNet-B 内部的输入图像,以进一步改善信息的流动。这三种变量产生的输出的空间维度是输入图像的 1 / 8。第四种变体,ESPNet(图 d),在 ESPNet- c 中添加了一个轻量级解码器(使用 reduceupsample-merge 的原理构建),输出与输入图像相同空间分辨率的分割 mask。

从 ESPNet- a 到 ESPNet 的路径。红色和绿色色框分别代表负责下采样和上采样操作的模块。空间级别的 l 在(a)中的每个模块的左侧。本文将每个模块表示为(#输入通道,#输出通道)。这里,conv-n 表示 n × n 卷积。
为了在不改变网络拓扑结构的情况下构建具有较深计算效率的边缘设备网络,超参数α控制网络的深度;ESP 模块在空间层次 l 上重复 α l α_{l} αl 次。在更高的空间层次(l = 0 和 l = 1),cnn 需要更多的内存,因为这些层次的特征图的空间维数较高。为了节省内存,ESP 和卷积模块都不会在这些空间级别上重复。
ESPNet V2 模型
ESPNet V2:是由 ESPNet V1 改进来的,一种轻量级、能耗高效、通用的卷积神经网络,利用分组卷积核深度空洞分离卷积学习巨大有效感受野,进一步降低浮点计算量和参数量。同时在图像分类、目标检测、语义分割等任务上检验了模型效果。
ESPNet V2 与 V1 版本相比,其特点如下:
-
将原来 ESPNet 的 point-wise convolutions 替换为 group point-wise convolutions;
-
将原来 ESPNet 的 dilated convolutions 替换为 depth-wise dilated convolution;
-
HFF 加在 depth-wise dilated separable convolutions 和 point-wise (or 1 × 1)卷积之间,去除 gridding artifacts;
-
使用 group point-wise convolution 替换 K 个 point-wise convolutions;
-
加入平均池化(average pooling ),将输入图片信息加入 EESP 中;
-
使用级联(concatenation)取代对应元素加法操作(element-wise addition operation )
DDConv 模块
深度分离空洞卷积(Depth-wise dilated separable convolution,DDConv)分两步:
-
对每个输入通道执行空洞率为 r 的 DDConv,从有效感受野学习代表性特征。
-
标准 1x1 卷积学习 DDConv 输出的线性组合特征。
深度分离空洞卷积与其他卷积的参数量与感受野对比如下表所示。
| Convolution type | Parameters | Eff.receptive field |
|---|---|---|
| Standard | n 2 c c ^ n^{2}c\hat{c} n2cc^ | n × n n\times n n×n |
| Group | n 2 c c ^ g \frac{n^{2}c\hat{c}}{g} gn2cc^ | n × n n\times n n×n |
| Depth-wise separable | n 2 c + c c ^ n^{2}c+c\hat{c} n2c+cc^ | n × n n\times n n×n |
| Depth-wise dilated separable | n 2 c + c c ^ n^{2}c+c\hat{c} n2c+cc^ | n r × n r n_{r}\times n_{r} nr×nr |
EESP 模块
EESP 模块结构如下图,图 b 中相比于 ESPNet,输入层采用分组卷积,DDConv+Conv1x1 取代标准空洞卷积,依然采用 HFF 的融合方式,(c)是(b)的等价模式。当输入通道数 M=240,g=K=4, d=M/K=60,EESP 比 ESP 少 7 倍的参数。

描述了一个新的网络模块 EESP,它利用深度可分离扩张和组逐点卷积设计,专为边缘设备而设计。该模块受 ESPNet 架构的启发,基于 ESP 模块构建,使用了减少-分割-变换-合并的策略。通过组逐点和深度可分离扩张卷积,该模块的计算复杂度得到了显著的降低。进一步,描述了一种带有捷径连接到输入图像的分层 EESP 模块,以更有效地学习多尺度的表示。
如上图中 b 所示,能够降低 M d + n 2 d 2 K M d g + ( n 2 + d ) d K \frac{Md+n^{2}d^{2}K}{\frac{Md}{g}+(n^{2}+d)dK} gMd+(n2+d)dKMd+n2d2K 倍计算复杂度,K 为空洞卷积金字塔层数。考虑到单独计算 K 个 point-wise 卷积等同于单个分组数为 K 的 point-wise 分组卷积,而分组卷积的在实现上更高效,于是改进为上图 c 的最终结构。
class EESP(nn.Module):'''按照 REDUCE ---> SPLIT ---> TRANSFORM --> MERGE '''def __init__(self, nIn, nOut, stride=1, k=4, r_lim=7, down_method='esp'): super().__init__()self.stride = striden = int(nOut / k)n1 = nOut - (k - 1) * nassert down_method in ['avg', 'esp']assert n == n1, "n(={}) and n1(={}) should be equal for Depth-wise Convolution ".format(n, n1)self.proj_1x1 = CBR(nIn, n, 1, stride=1, groups=k)#3x3 核的膨胀率和感受野之间的映射map_receptive_ksize = {3: 1, 5: 2, 7: 3, 9: 4, 11: 5, 13: 6, 15: 7, 17: 8}self.k_sizes = list()for i in range(k):ksize = int(3 + 2 * i)# 达到感受野极限后,回落到 3x3,膨胀率为 1 的基础卷积ksize = ksize if ksize <= r_lim else 3self.k_sizes.append(ksize)#根据感受野对这些核大小进行排序(升序)#这使我们能够忽略分层中具有相同有效感受野的核(在我们的例子中为 3×3)# 特征融合,因为 3x3 感受野的核不具有网格伪影。self.k_sizes.sort()self.spp_dw = nn.ModuleList()for i in range(k):d_rate = map_receptive_ksize[self.k_sizes[i]]self.spp_dw.append(CDilated(n, n, kSize=3, stride=stride, groups=n, d=d_rate))self.conv_1x1_exp = CB(nOut, nOut, 1, 1, groups=k)self.br_after_cat = BR(nOut)self.module_act = nn.PReLU(nOut)self.downAvg = True if down_method == 'avg' else Falsedef forward(self, input):# Reduce --> 将高维特征映射投影到低维空间output1 = self.proj_1x1(input)output = [self.spp_dw[0](output1)]# 计算每个分支的输出并分层融合它们# i.e. Split --> Transform --> HFFfor k in range(1, len(self.spp_dw)):out_k = self.spp_dw[k](output1)# HFF#我们不组合具有相同感受野的分支(在我们的例子中是 3x3)out_k = out_k + output[k - 1]#融合后应用批量定额,然后添加到列表中output.append(out_k)# Mergeexpanded = self.conv_1x1_exp( self.br_after_cat( torch.cat(output, 1) ))del output# 如果下采样,则返回连接的向量# 因为下采样功能会将其与 avg 合并。合并特征图,然后对其进行阈值处理if self.stride == 2 and self.downAvg:return expanded# 如果输入向量和连接向量的维数相同,则将它们相加 (RESIDUAL LINK)if expanded.size() == input.size():expanded = expanded + input# 使用激活函数对特征图进行阈值处理 (PReLU in this case)return self.module_act(expanded)
Strided EESP 模块
为了在多尺度下能够有效地学习特征,对上图 1c 的网络做了四点改动(如下图所示):
1.对 DDConv 添加 stride 属性。
2.右边的 shortcut 中带了平均池化操作,实现维度匹配。
3.将相加的特征融合方式替换为 concat 形式,增加特征的维度。
4.融合原始输入图像的下采样信息,使得特征信息更加丰富。具体做法是先将图像下采样到与特征图的尺寸相同的尺寸,然后使用第一个卷积,一个标准的 3×3 卷积,用于学习空间表示。再使用第二个卷积,一个逐点卷积,用于学习输入之间的线性组合,并将其投影到高维空间。

class DownSampler(nn.Module):'''具有两个并行分支的下采样功能:平均池和步长为 2 的 EESP 块。然后,使用激活函数将这些分支的输出特征图连接起来并进行阈值处理,以产生最终输出。'''def __init__(self, nin, nout, k=4, r_lim=9, reinf=True):super().__init__()nout_new = nout - ninself.eesp = EESP(nin, nout_new, stride=2, k=k, r_lim=r_lim, down_method='avg')self.avg = nn.AvgPool2d(kernel_size=3, padding=1, stride=2)if reinf:self.inp_reinf = nn.Sequential(CBR(config_inp_reinf, config_inp_reinf, 3, 1),CB(config_inp_reinf, nout, 1, 1))self.act = nn.PReLU(nout)def forward(self, input, input2=None):avg_out = self.avg(input)eesp_out = self.eesp(input)output = torch.cat([avg_out, eesp_out], 1)if input2 is not None:w1 = avg_out.size(2)while True:input2 = F.avg_pool2d(input2, kernel_size=3, padding=1, stride=2)w2 = input2.size(2)if w2 == w1:breakoutput = output + self.inp_reinf(input2)return self.act(output)
如果您想了解更多AI知识,与AI专业人士交流,请立即访问昇腾社区官方网站https://www.hiascend.com/或者深入研读《AI系统:原理与架构》一书,这里汇聚了海量的AI学习资源和实践课程,为您的AI技术成长提供强劲动力。不仅如此,您还有机会投身于全国昇腾AI创新大赛和昇腾AI开发者创享日等盛事,发现AI世界的无限奥秘~