本项目目标在于针对边缘场景实现P2P的分布式训练过程,设计方案为将神经网络训练过程对应的裸机程序部署在了PS端的ARM Cortex-A72核上,传输方案采用开发板板载的GTM收发器硬件资源通过外部QSFP-DD光模块光传输至对端,最终完成了设计目标。
整个项目的实现细节可分为如下几个重要部分,同时整个系统的实现框图及实际部署图如下图所示:
欲部署神经网络模型的介绍及相关公式的推导;
PS端ARM Cortex-A72裸机训练程序部署;
PL端基于aurora64b66b自定义协议的GTM板间光传输工程搭建;
PL与PS间通过AXI-FULL总线进行数据交互。


内部模块系统框图如下:

接下来,将按照整个项目几个重要部分详细论述:
一、神经网络模型的介绍及相关公式的推导
1.1 神经网络模型相关介绍
本次推导的网络模型结构如下,其中模型层数共3层,各层神经元个数可重定义。以输入层神经元2个,隐藏层神将元3个,输出层神将元1个为例,对应模型图如下:


1.2 反向传播过程公式推导




二、PS端ARM Cortex-A72裸机训练程序部署
对应代码如下所示:
#include <stdio.h>
#include <stdlib.h>
#include "platform.h"
#include "xil_printf.h"
#include "xgpio.h"
#include "xparameters.h"
#include "xstatus.h"
#include "math.h"
#include "string.h"
#include "xtimer_config.h"
#include "xiltimer.h"
#include "xil_types.h"
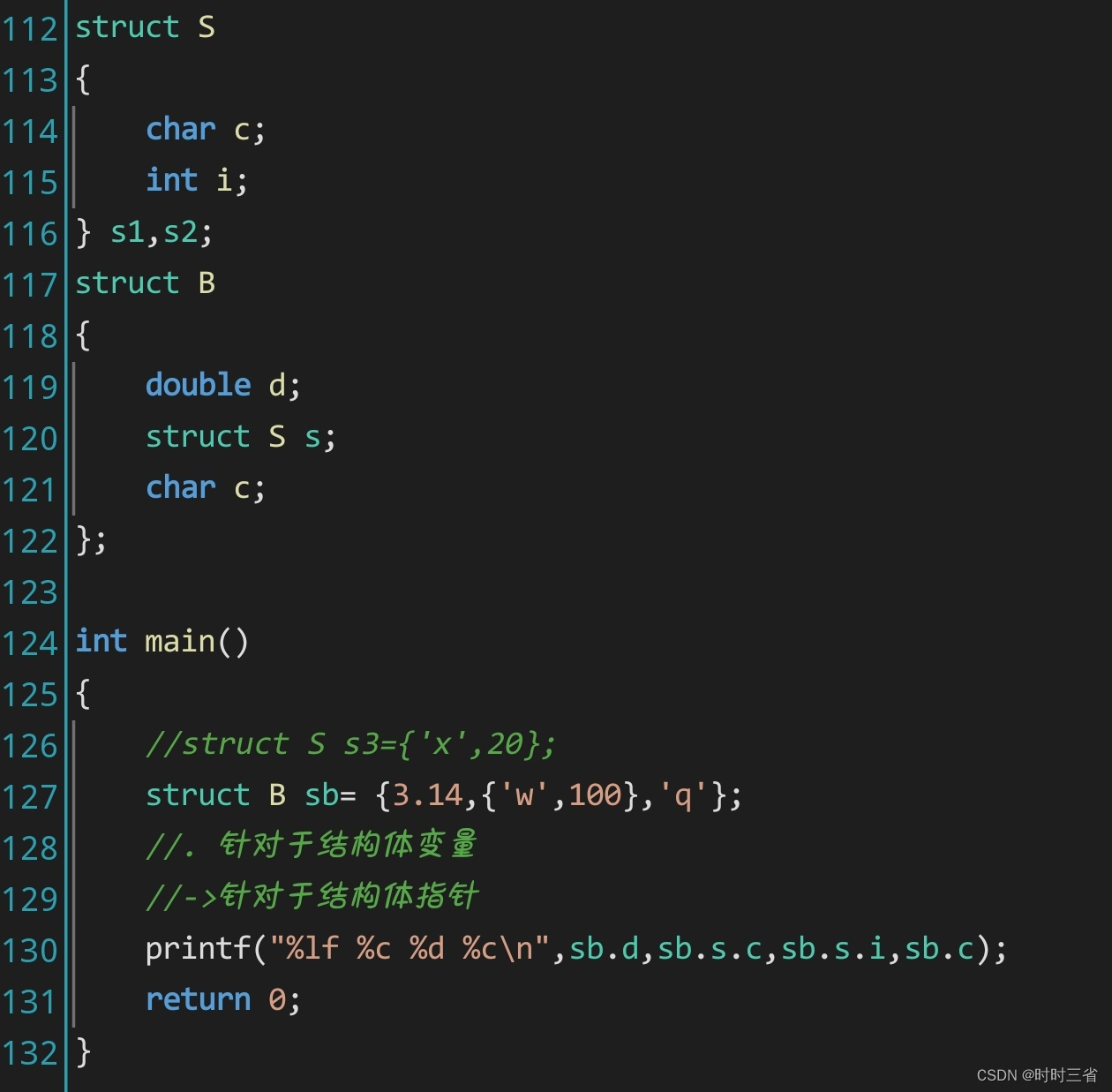
#include "time.h"// 模型参数结构体
typedef struct {int input_size; // 输入层的大小int hidden_size; // 隐藏层的大小int output_size; // 输出层的大小double *W1; // 第一层的权重double *b1; // 第一层的偏置double *W2; // 第二层的权重double *b2; // 第二层的偏置
} NeuralNet;//函数声明
double sigmoid(double x);
void init_net(NeuralNet *net);
void forward(NeuralNet *net, double *input, double *output);
void backward(NeuralNet *net, double *input, double *target, double learning_rate);
void train(NeuralNet *net, double *inputs, double *targets, int num_epochs, int num_inputs, double learning_rate);
void predict(NeuralNet *net, double *input, double *output);//gpio0 baseaddr
//gpio0用了两个通道,通道一作为输入用于传输channel_up的拉高情况
//gpio0的通道二作为输出,用于传输将参数写到Bram完成的标志
#define XPAR_AXI_GPIO_0_BASEADDR 0x80000000
//gpio1 baseaddr
//gpio1只用了一个通道,作为输入,用于传输将参数写到另一块板子BRAM中完成的标志
#define XPAR_XGPIO_1_BASEADDR 0x80010000
//AXI_Bram baseaddr
#define XPAR_AXI_BRAM_0_BASEADDRESS 0x80020000 //结束地址为0x80022000 //gpio初始化用到的结构体变量
XGpio Axi_gpio0;
XGpio_Config *Xgpio_cfgptr0;
XGpio Axi_gpio1;
XGpio_Config *Xgpio_cfgptr1;//gpio初始化函数声明
void gpio_init();int main()
{init_platform();gpio_init();//u32 *LitePtr = (u32*) XPAR_AXI_BRAM_0_BASEADDRESS;//u32 wrdata = 0;while(XGpio_DiscreteRead( &Axi_gpio0, 1) == 0x00){}//channel_up link flagprintf("Aurora is linked!\n\r");u64 begin_time;u64 end_time;long int time_dif;float time_cost;XTime_GetTime(&begin_time);//计时开始时间NeuralNet net;net.input_size = 2;net.hidden_size = 3;net.output_size = 1;init_net(&net);double inputs[] = {0,0,0,1,1,0,1,1};//训练数据集double targets[] = {0,1,1,0};//将数据集分成两份//double inputs[]={0,0,0,1};//double targets[]={0,1};train(&net, inputs, targets, 1, 4, 0.001);//训练一次 //打印各层参数,共有13个参数for(int i=0;i<net.input_size*net.hidden_size;i++){printf("The first layer of training weight parameters are as follows:W1[%d]=%f\n\r",i,net.W1[i]);//6个参数}for(int i=0;i<net.hidden_size;i++){printf("The first layer training bias parameters are as follows:b1[%d]=%f\n\r",i,net.b1[i]);//3个参数}for(int i=0;i<net.hidden_size*net.output_size;i++){printf("The second layer training weight parameters are as follows:W2[%d]=%f\n\r",i,net.W2[i]);//3个参数}for(int i=0;i<net.output_size;i++){printf("The second layer training bias parameters are as follows:b2[%d]=%f\n\r",i,net.b2[i]);//1个参数}// //对训练完的参数进行量化,量化成32位有符号定点数*8192// int w1_storage[6]={0,0,0,0,0,0};// int b1_storage[3]={0,0,0};// int w2_storage[3]={0,0,0};// int b2_storage[1]={0};int32_t *LitePtr = (u32*) XPAR_AXI_BRAM_0_BASEADDRESS;//将存储空间指向BRAM的基地址// //w1量化// for(int i=0;i<net.input_size*net.hidden_size;i++){// w1_storage[i] = net.W1[i]*8192;// }// //w1写入Bram 0-5地址// for(int i=0;i<net.input_size*net.hidden_size;i++){// *(LitePtr+i) = w1_storage[i];//0-5// }// //b1量化// for(int i=0;i<net.hidden_size;i++){// b1_storage[i] = net.b1[i]*8192;// }// //b1写入BRAM 6-8地址// *(LitePtr+6) = b1_storage[0];// *(LitePtr+7) = b1_storage[1];// *(LitePtr+8) = b1_storage[2];// //w2量化// for(int i=0;i<net.hidden_size*net.output_size;i++){// w2_storage[i] = net.W2[i]*8192;// }// //w2写入Bram 9-11地址// *(LitePtr+9) = w2_storage[0];// *(LitePtr+10) = w2_storage[1];// *(LitePtr+11) = w2_storage[2];// //b2量化// for(int i=0;i<net.output_size;i++){// b2_storage[i] = net.b2[i]*8192;// }// //将量化完的b2写入12地址// *(LitePtr+12) = b2_storage[0];*LitePtr = net.W1[0]*8192;*(LitePtr+1) = net.W1[1]*8192;//利用AXI_GPIO通知PL端已写完XGpio_DiscreteWrite(&Axi_gpio0, 2, 0x01);//另外一块板已收到数据,并将数据写入PS中while(XGpio_DiscreteRead( &Axi_gpio1, 1) == 0x00){}//write to ps end//这部分会将收到的数据存到指定的地址,接着来作reduce操作,做完reduce操作计数结束// //read data from Bram// LitePtr = (u32*) XPAR_AXI_BRAM_0_BASEADDRESS;// for(int i=9;i<18;i++){// printf("write data is %d",*(LitePtr+i));// }XTime_GetTime(&end_time);time_dif = end_time - begin_time;time_cost =(float)(time_dif)/COUNTS_PER_SECOND;printf("time_cost = %.4fs",time_cost);// for(int i=0;i<9;i++){// *LitePtr++ = wrdata++;//0-9// }// XGpio_DiscreteWrite(&Axi_gpio0, 2, 0x01);// while(XGpio_DiscreteRead( &Axi_gpio1, 1) == 0x00){}//write to ps end// //read data from Bram// LitePtr = (u32*) XPAR_AXI_BRAM_0_BASEADDRESS;// for(int i=9;i<18;i++){// printf("write data is %d",*(LitePtr+i));// }cleanup_platform();return 0;
}//gpio init
void gpio_init(){Xgpio_cfgptr0 = XGpio_LookupConfig(XPAR_AXI_GPIO_0_BASEADDR);XGpio_CfgInitialize(&Axi_gpio0,Xgpio_cfgptr0,Xgpio_cfgptr0->BaseAddress);XGpio_SetDataDirection(&Axi_gpio0, 1,1);//channel 1:inputXGpio_SetDataDirection(&Axi_gpio0, 2,0);//channel 2:outputXgpio_cfgptr1 = XGpio_LookupConfig(XPAR_AXI_GPIO_1_BASEADDR);XGpio_CfgInitialize(&Axi_gpio1,Xgpio_cfgptr1,Xgpio_cfgptr1->BaseAddress);XGpio_SetDataDirection(&Axi_gpio1, 1,1);//channel 1:input//XGpio_SetDataDirection(&Axi_gpio0, 2,0);//channel 2:output
}double sigmoid(double x) {return 1 / (1 + exp(-x));
}// 初始化权重和偏置参数
void init_net(NeuralNet *net) {net->W1 = (double*) malloc(net->input_size * net->hidden_size * sizeof(double));net->b1 = (double*) malloc(net->hidden_size * sizeof(double));net->W2 = (double*) malloc(net->hidden_size * net->output_size * sizeof(double));net->b2 = (double*) malloc(net->output_size * sizeof(double));//srand(time(NULL));for (int i = 0; i < net->input_size * net->hidden_size; i++) {net->W1[i] = (double)rand()/RAND_MAX;}for (int i = 0; i < net->hidden_size * net->output_size; i++) {net->W2[i] = (double)rand()/RAND_MAX;}for (int i = 0; i < net->hidden_size; i++) {net->b1[i] = (double)rand()/RAND_MAX;}for (int i = 0; i < net->output_size; i++) {net->b2[i] = (double)rand()/RAND_MAX;}
}//前向传播
void forward(NeuralNet *net, double *input, double *output) {double *h1 = (double*) malloc(net->hidden_size * sizeof(double));double *h2 = (double*) malloc(net->output_size * sizeof(double));// 第一层的计算for (int i = 0; i < net->hidden_size; i++) {h1[i] = 0;for(int j = 0; j < net->input_size; j++){h1[i] += input[j] * net->W1[j*net->hidden_size+i];}h1[i] += net->b1[i];h1[i] = tanh(h1[i]);}// 第二层的计算for (int i = 0; i < net->output_size; i++) {h2[i] = 0;for (int j = 0; j < net->hidden_size; j++) {h2[i] += h1[j] * net->W2[j*net->output_size+i];}h2[i] += net->b2[i];}// 输出的激活函数 for (int i = 0; i < net->output_size; i++) {output[i] = sigmoid(h2[i]);}free(h1);free(h2);
}// 反向传播
void backward(NeuralNet *net, double *input, double *target, double learning_rate) {double *h1 = (double*) malloc(net->hidden_size * sizeof(double));double *h2 = (double*) malloc(net->output_size * sizeof(double));double *delta1 = (double*) malloc(net->hidden_size * sizeof(double));double *delta2 = (double*) malloc(net->output_size * sizeof(double));// 第一层的计算for (int i = 0; i < net->hidden_size; i++) {h1[i] = 0;for (int j = 0; j < net->input_size; j++) {h1[i] += input[j] * net->W1[j*net->hidden_size+i];}h1[i] += net->b1[i];h1[i] = tanh(h1[i]);}// 第二层的计算for (int i = 0; i < net->output_size; i++) {h2[i] = 0;for (int j = 0; j < net->hidden_size; j++) {h2[i] += h1[j] * net->W2[j*net->output_size+i];}h2[i] += net->b2[i];}// 输出激活函数 for (int i = 0; i < net->output_size; i++) {h2[i] = sigmoid(h2[i]);delta2[i] = h2[i] * (1-h2[i]) * (target[i]-h2[i]);}// 第一层的误差传递 for (int i = 0; i < net->hidden_size; i++) {delta1[i] = 0;for (int j = 0; j < net->output_size; j++) {delta1[i] += delta2[j] * net->W2[i*net->output_size+j];}delta1[i] *= (1-h1[i]) * (1+h1[i]);}// 权重和偏置的更新for (int i = 0; i < net->hidden_size; i++) {for (int j = 0; j < net->input_size; j++) {net->W1[j*net->hidden_size+i] += learning_rate * delta1[i] * input[j];}net->b1[i] += learning_rate * delta1[i];}for (int i = 0; i < net->output_size; i++) {for (int j = 0; j < net->hidden_size; j++) {net->W2[j*net->output_size+i] += learning_rate * delta2[i] * h1[j];}net->b2[i] += learning_rate * delta2[i];}free(h1);free(h2);free(delta1);free(delta2);
}// 训练神经网络
void train(NeuralNet *net, double *inputs, double *targets, int num_epochs, int num_inputs, double learning_rate) {for (int i = 0; i < num_epochs; i++) {for (int j = 0; j < num_inputs; j++) {double *input = &inputs[j*net->input_size];double *target = &targets[j*net->output_size];backward(net, input, target, learning_rate);}}
}// 使用神经网络进行预测
void predict(NeuralNet *net, double *input, double *output) {forward(net, input, output);
}
三、PL端基于aurora64b66b自定义协议的GTM板间光传输工程搭建
这部分采用xilinx官方提供的aurora64B66B IP,IP配置如下:

配置完成后点击run block automation后的界面如下:

通过阅读官方手册可知,CIPS与ZYNQ系列不同点在于即使不同PS端也要将其加入工程,因为由它启动硬件系统的初始化工作。
这里主要注意在example基础上,将参考时钟、初始化时钟及复位信号处理好,对QSFP-DD模块自回环测试或者仿真观察lane_up及channel_up信号拉高即完成对aurora64b66b自定义协议的配置工作。拉高界面如下:

四、PL与PS间通过AXI-FULL总线进行数据交互
同ZYNQ系列芯片类似,PL与PS端交互有对应的AXI接口,本次选用主机LPD接口:

整个数据交互通过AXI-GPIO IP和AXI BRAM Controller配合真双端口RAM实现(一侧连接到PS,另一端连接到PL),整个交互流程为PL端channel up信号拉高后,通过AXI-GPIO发送给PS端;PS端收到channel up信号并判断本机训练完后,将梯度数据存入BRAM中,存完告知PL端;PL端收到反馈信号后,将读出的数据传给aurora顶层模块,同时通过fifo进行跨时钟域,并在握手成功的情况下与上~empty信号启动读数据;对板收到数据后同样写入BRAM,并由PS读出,读取数据完成后,将数据做reduce操作,完成后继续训练,这样整个过程便完成了。
对应的模块框图及中间结果记录如下:

建链成功标志:

ps向BRAM写完的标志:

存入参数:

五、训练时间对比
训练时间统计如下:
2个数据集单板训练时间为0.000006s,4个数据集单板训练时间为0.0000095S。训练完写入bram过程时间为:0.0000006s。通过回环将数据传入另一块板子ram中整个通讯过程消耗的时间为:0.0000020s。则说明即使在数据量较小的情况下,两板间通信带来的开销仍对分布式训练时间加速有益处。