RoBoflow数据集的介绍
https://public.roboflow.com/object-detection(该数据集的网址)
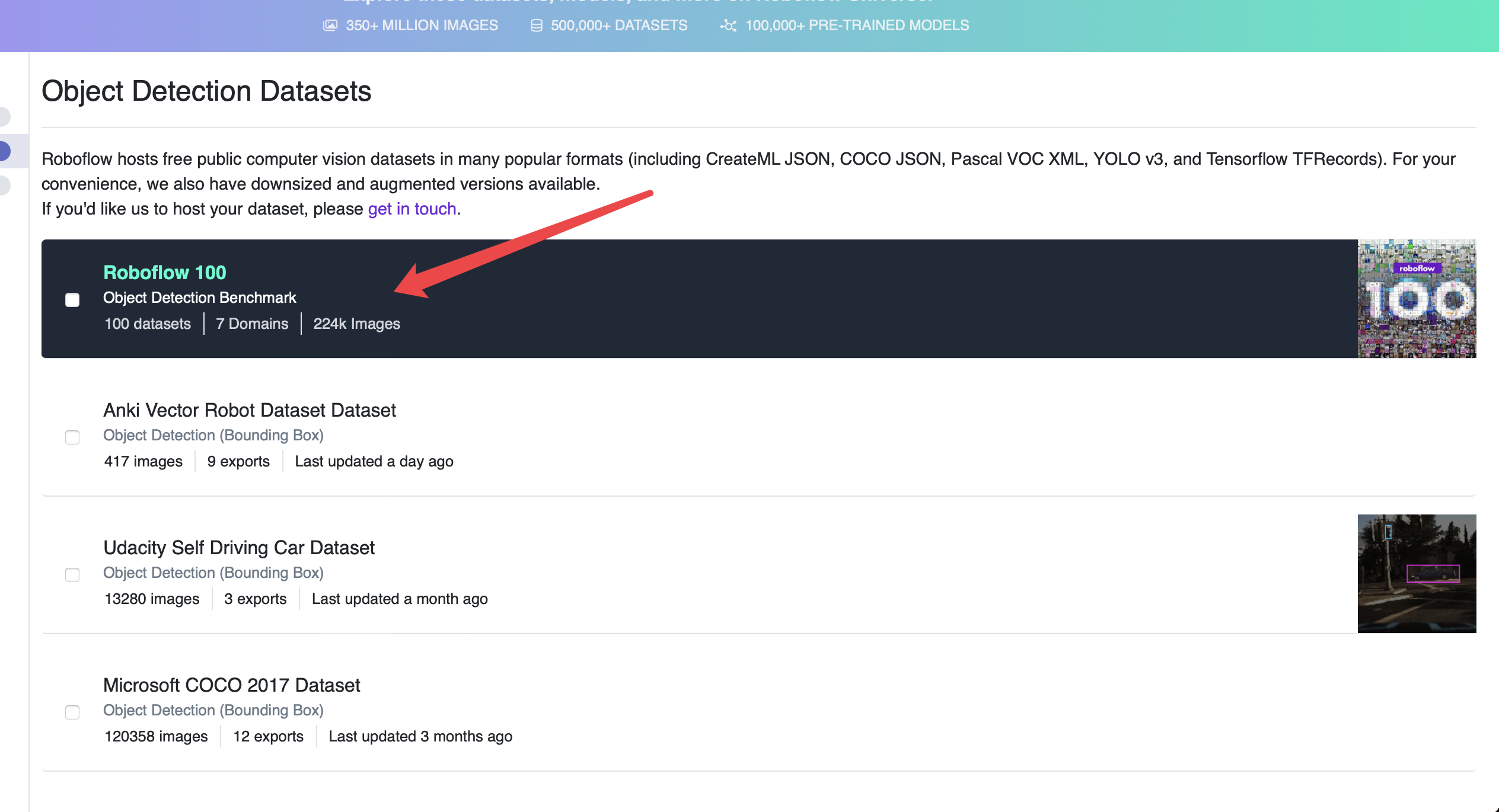
可以看到一些基本情况
如果我们想要下载,直接点击
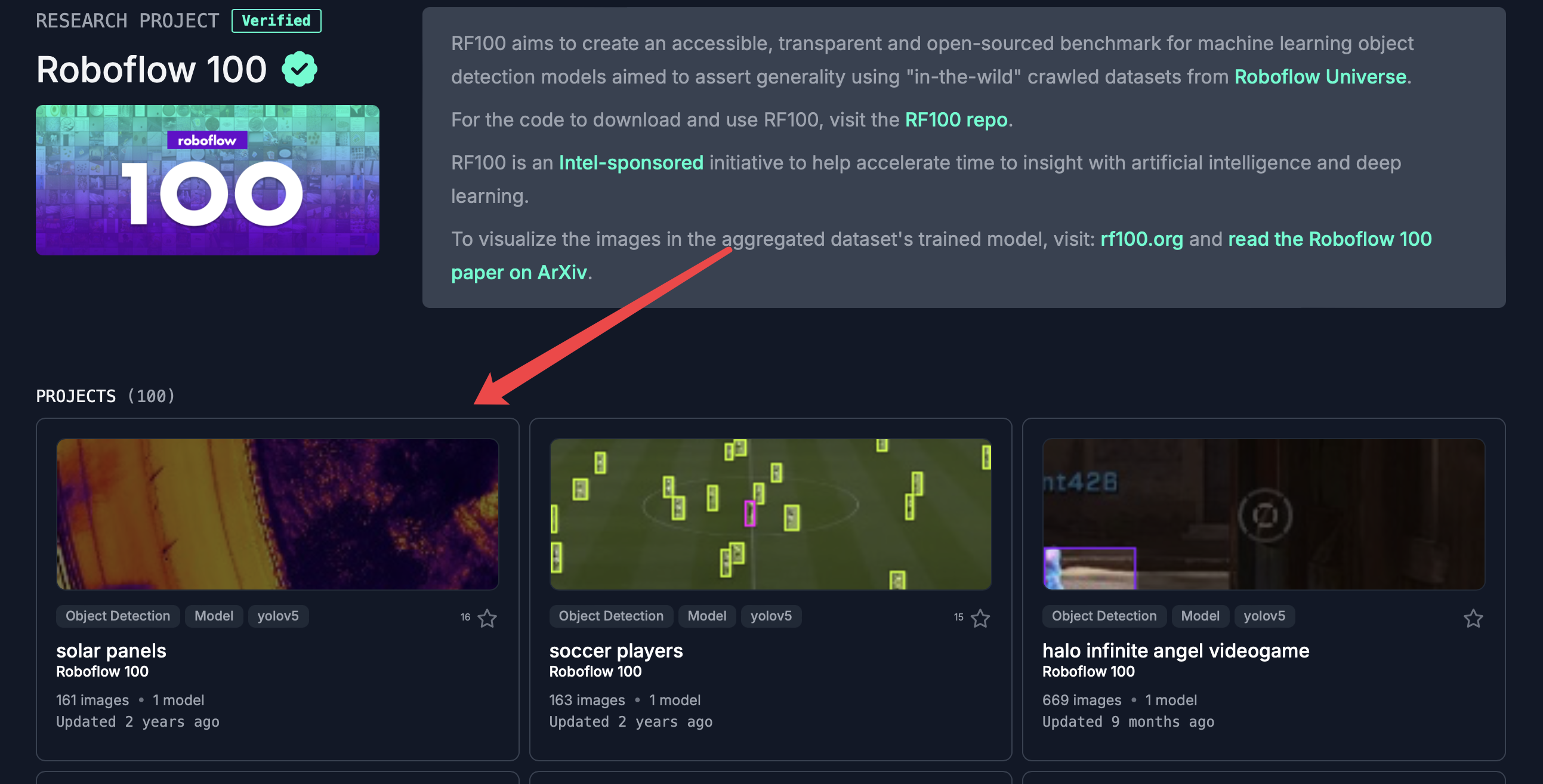
点击图像可以看到一些基本情况
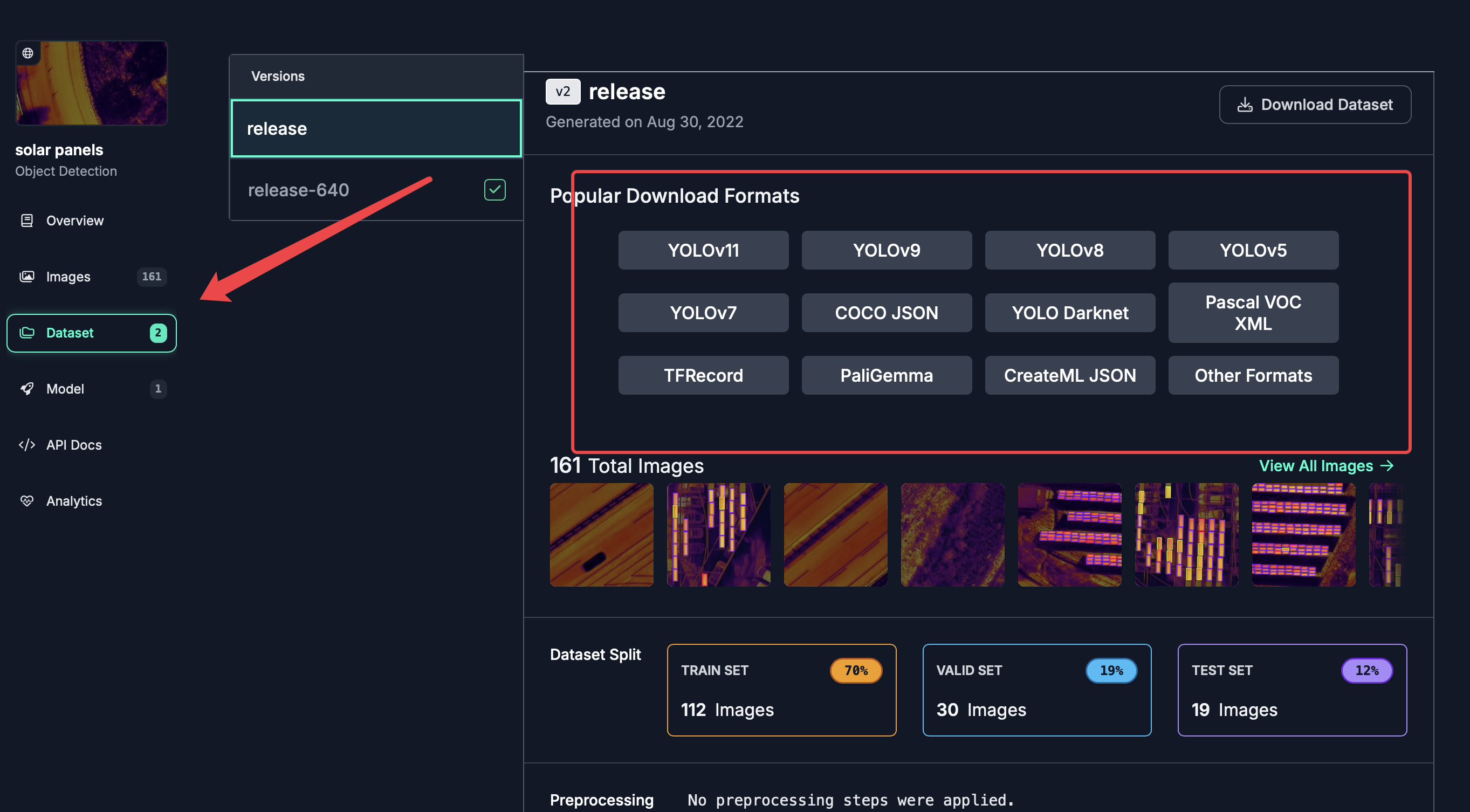
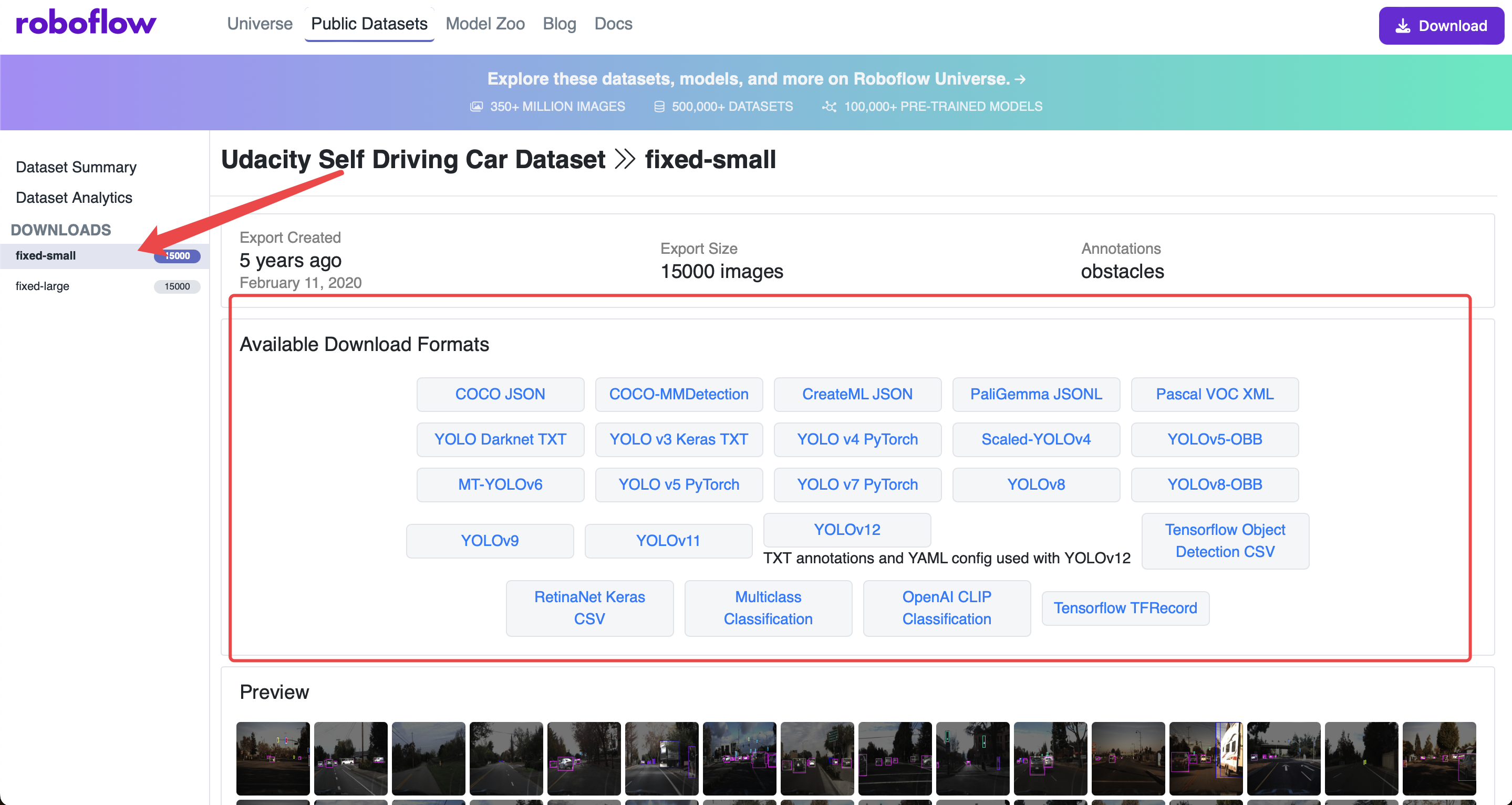
可以点击红色箭头所指,右边是可供选择的一些yolo模型的格式
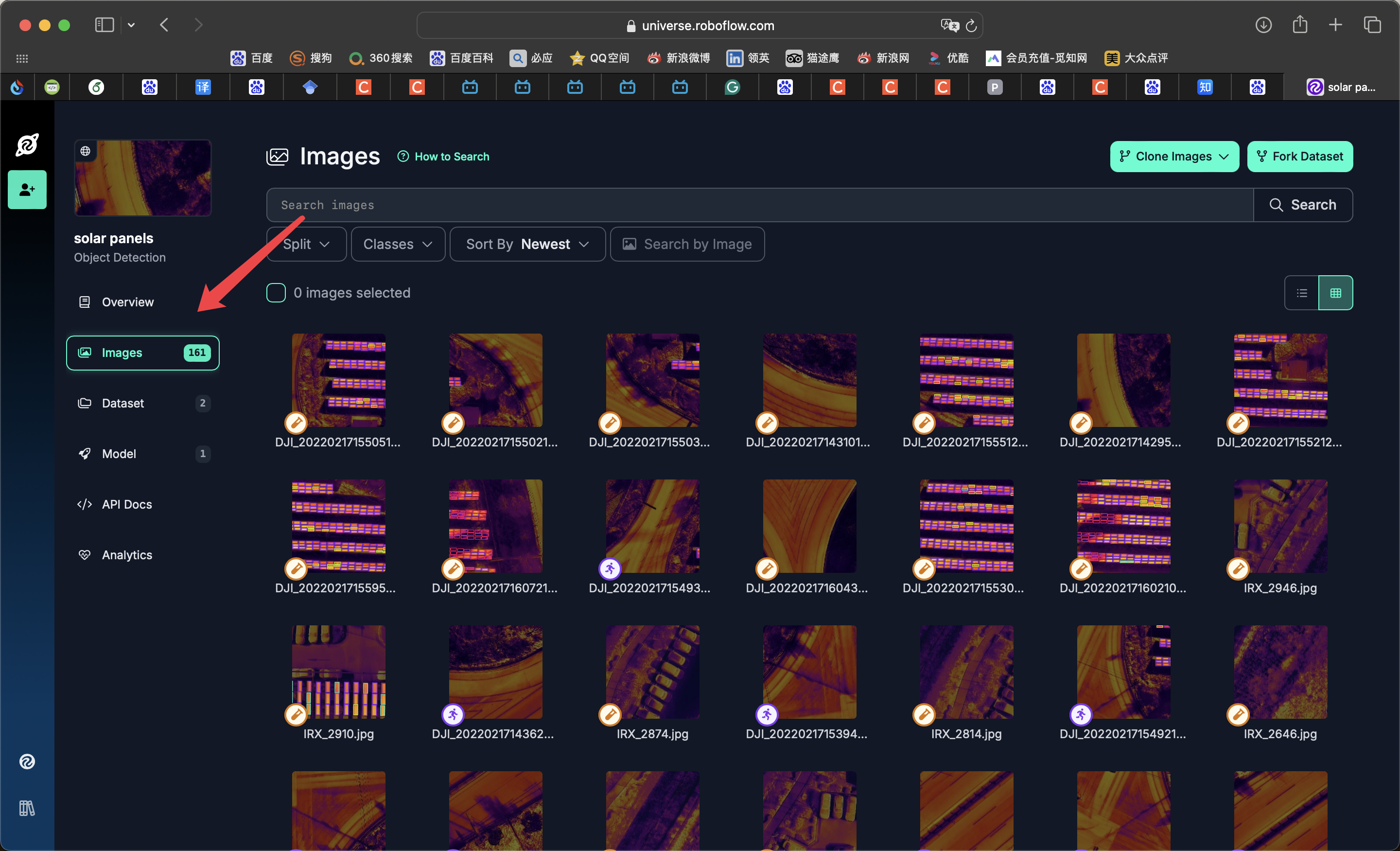
如果你想下载其他数据集
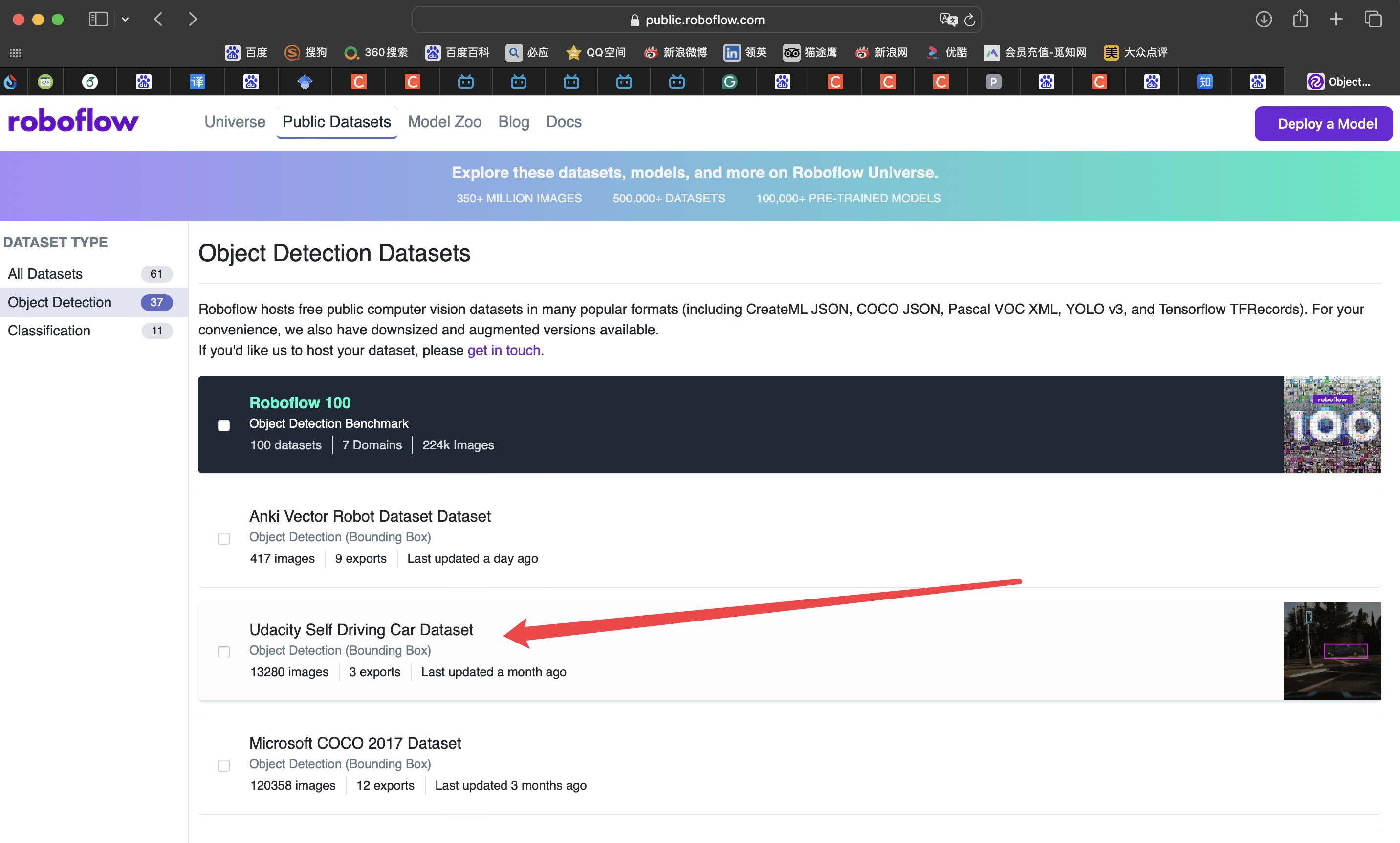
点击红色箭头所指,也可以选择
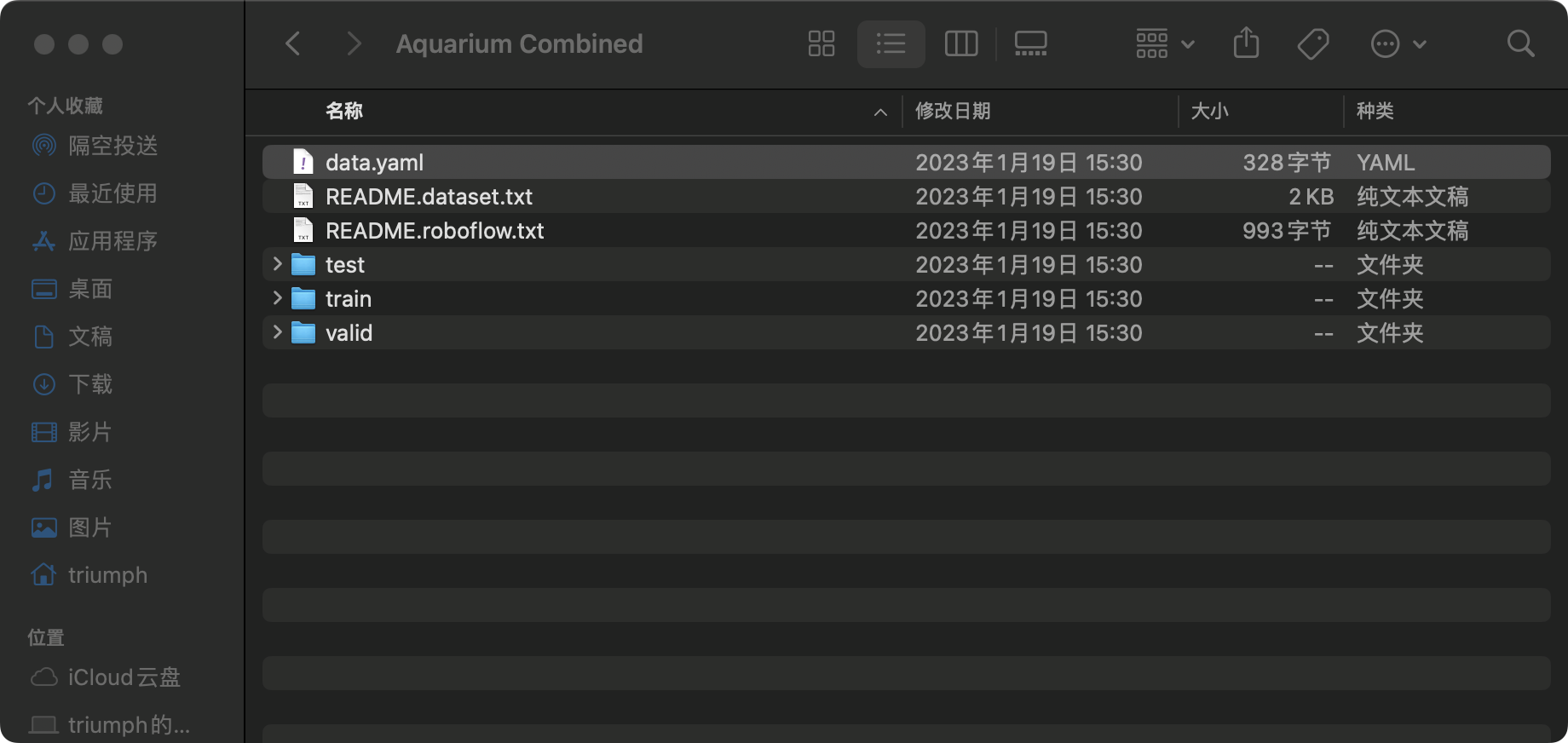
选择下载了一个,可以看到数据文件
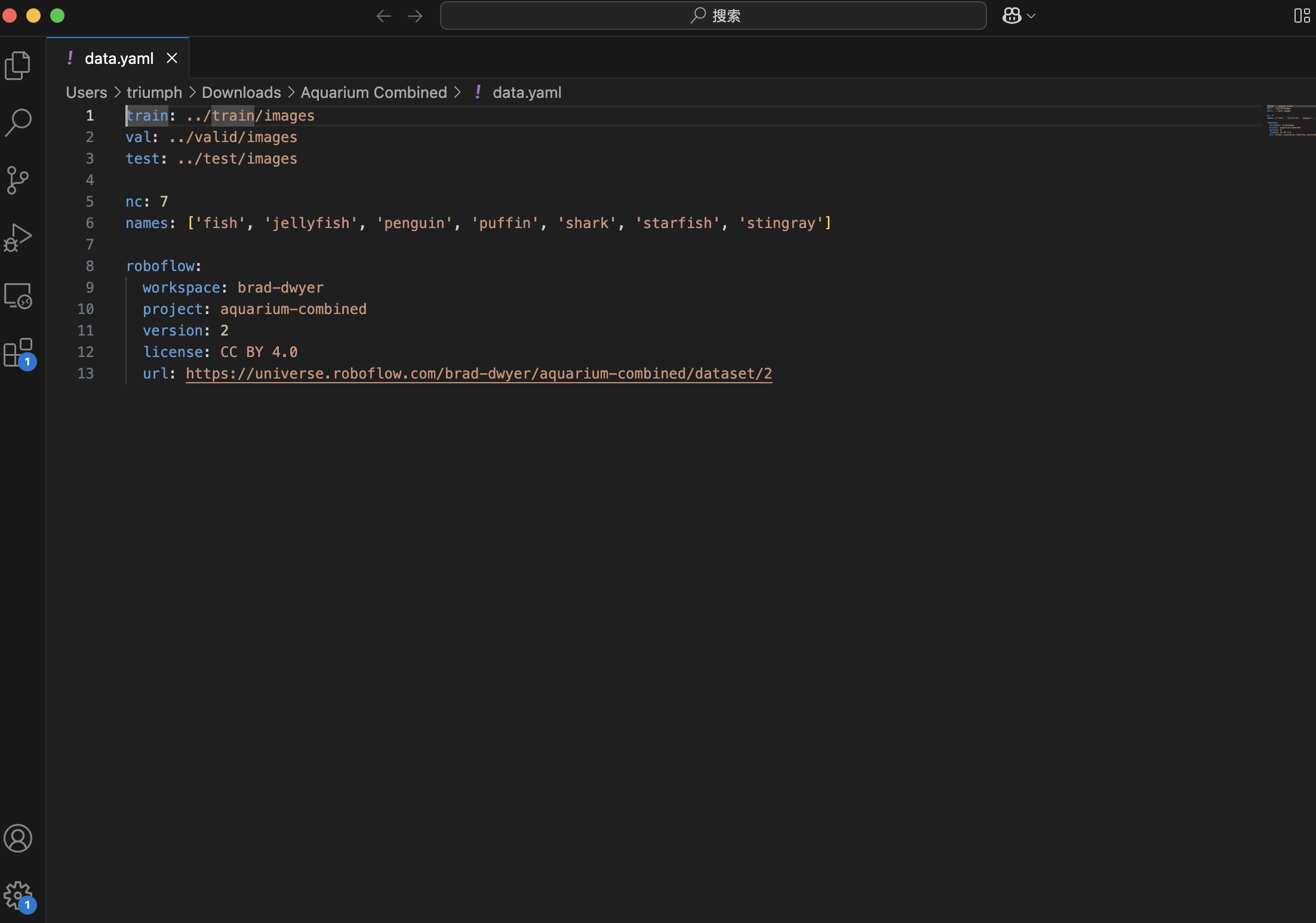
具体的类别可以从data.yaml里面看
https://public.roboflow.com/object-detection(该数据集的网址)
可以看到一些基本情况
如果我们想要下载,直接点击
点击图像可以看到一些基本情况
可以点击红色箭头所指,右边是可供选择的一些yolo模型的格式
如果你想下载其他数据集
点击红色箭头所指,也可以选择
选择下载了一个,可以看到数据文件
具体的类别可以从data.yaml里面看