【AI量化第24篇】KhQuant 策略框架深度解析:让策略开发回归本质——基于miniQMT的量化交易回测系统开发实记
我是Mr.看海,我在尝试用 信号处理的知识积累和思考方式做量化交易,应用深度学习和AI实现股票自动交易,目的是实现财务自由~
目前我正在开发基于 miniQMT的量化交易系统——看海量化交易系统。
日志系统是任何复杂软件不可或缺的组成部分,它记录着软件运行过程中的关键信息、用户交互、潜在问题以及发生的错误。尤其在量化交易这样对稳定性、精确性和可追溯性有着严苛要求的领域,一个设计精良的日志系统更是至关重要。
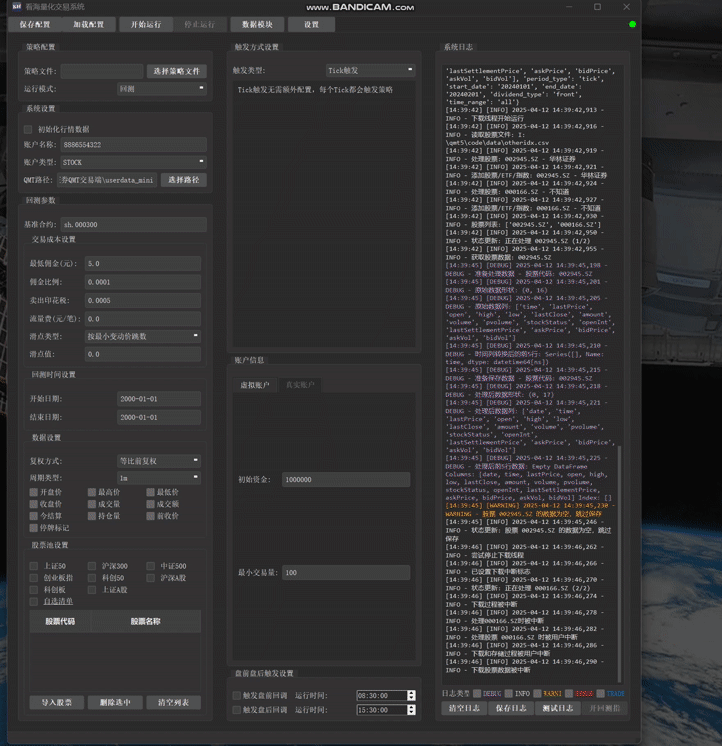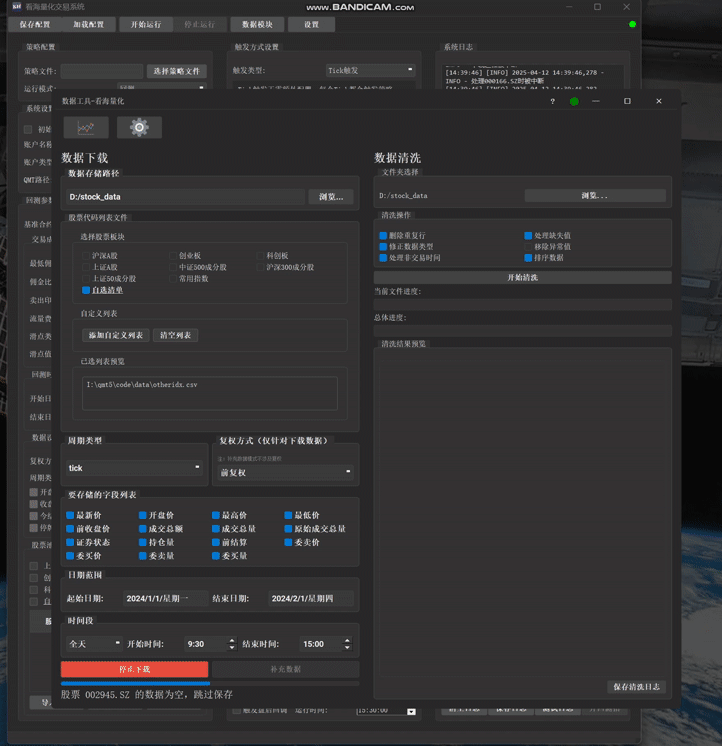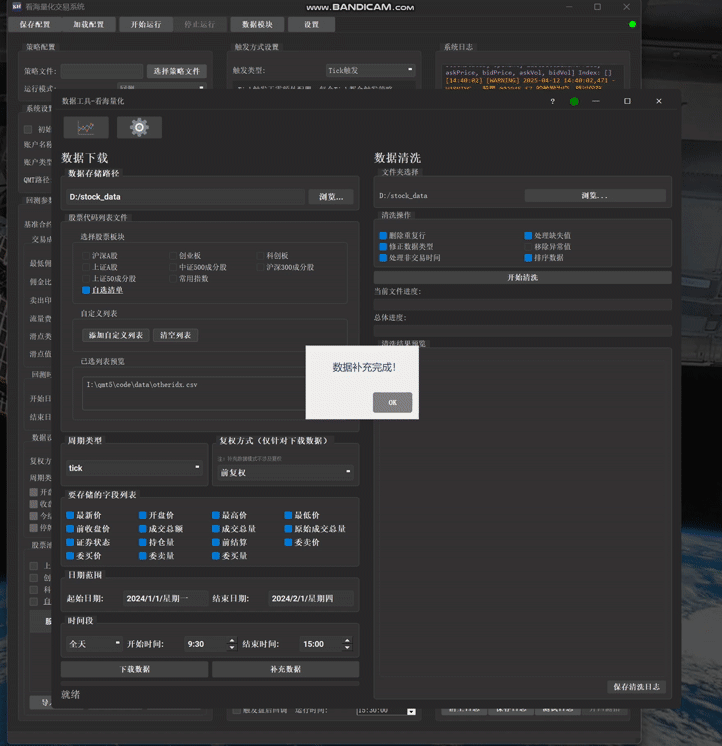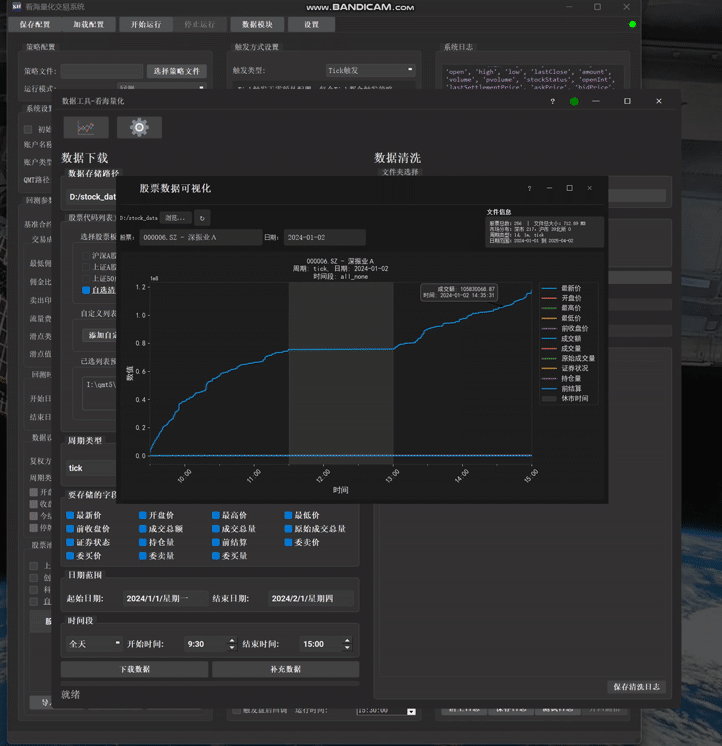
看海量化交易系统(KhQuant)构建了一套全面且用户友好的日志体系,旨在帮助用户实时监控策略动态、高效诊断系统问题,并为优化交易流程提供数据支持。
一、 日志系统的核心构成
本软件的日志系统设计围绕两大核心组件展开,两者相辅相成,共同构成了完整的日志监控体系:
- 后台文件日志 (
app.log):作为最详尽的记录载体,它捕捉软件运行期间的各类事件,包括启动、配置、策略执行及错误信息,为深度问题排查提供依据。 - 前台界面日志:一个可视化的窗口,实时展示关键的运行状态、策略输出和交易活动,提供直观的监控体验。
1.1 后台文件日志:完整记录运行轨迹
软件在启动时,会自动在程序根目录下的 logs 文件夹内创建或覆盖一个名为 app.log 的文本文件。这个文件是系统运行状态最详尽的记录载体。它会捕捉软件从启动到退出的整个生命周期内的各类事件,包括但不限于配置文件的加载与保存动作、策略脚本的启动指令、运行过程中的状态变化以及最终的停止信号。更重要的是,当软件遭遇预期之外的异常情况时,详细的错误信息和程序执行堆栈(Traceback)会被完整地记录下来,为问题排查提供了关键线索。
为了确保信息的全面性,文件日志默认设定为记录 DEBUG 及以上所有级别的信息,这意味着即使是一些用于开发调试的细节也会被包含在内,便于进行深度分析。每条日志条目都遵循着统一的格式规范,清晰地标明了事件发生的时间戳、信息的严重级别(如 INFO, DEBUG, WARNING, ERROR)以及具体的描述内容,需要注意的是,该日志文件在每次软件重新启动时会被重写,因此只保留当前运行周期的日志。若需长期存档,建议在关闭软件前手动备份该文件,或利用稍后介绍的界面功能进行保存。


1.2 前台界面日志:实时状态的可视化窗口
为了让用户能够直观、实时地掌握软件的运行状态和策略执行情况,后台记录的关键日志信息会被同步呈现在软件主界面的右侧"系统日志"面板中。这个面板是用户观察软件内部活动的主要窗口,它会实时显示核心的运行状态更新、策略通过 print 或日志模块输出的信息、发生的交易行为以及重要的系统警告与错误提示。相较于后台纯文本的日志文件,界面日志在呈现方式上做了优化,提供了更佳的可视化效果和交互体验。

二、 界面日志的特性与交互功能
用户界面的日志显示区域并非仅仅是后台日志的简单复刻,它融入了多项旨在提升用户体验和信息获取效率的设计。
2.1 日志级别与颜色区分:快速识别信息优先级
为了帮助用户在信息流中快速抓住重点,不同重要程度的日志被赋予了不同的颜色标识。这种直观的颜色编码机制,使得用户能够迅速定位到关键的错误警报或重点关注交易活动。具体的颜色与级别对应关系如下:
- DEBUG (浅紫色): 主要用于开发者调试,信息较为冗余。
- INFO (白色): 常规运行信息,如启动/停止、配置更改等。
- WARNING (橙色): 潜在问题或需要用户注意的情况。
- ERROR (红色): 发生了错误,可能影响正常运行。
- TRADE (蓝色): 特殊的日志类型,专门用于记录交易相关的委托和成交信息。

2.2 日志过滤:聚焦核心信息
随着软件运行时间的增长,日志信息可能会变得非常庞杂。为了解决信息过载的问题,界面日志区域下方提供了一组复选框,允许用户根据日志级别进行动态过滤。默认情况下,所有级别的日志都会被显示。如果用户当前只关心策略的运行结果和潜在错误,可以取消勾选 DEBUG 级别的复选框,界面上便不再显示冗余的调试信息。同样,可以根据需要自由组合勾选 INFO、WARNING、ERROR 和 TRADE 级别,定制个性化的日志视图。每次勾选状态的改变都会即时生效,日志显示区域会自动刷新,仅呈现满足当前过滤条件的条目,让关键信息一目了然。

筛选仅显示交易日志
2.3 日志管理工具:便捷的操作支持
除了显示和过滤,界面日志区域还配备了几个实用的管理按钮,以简化用户的日常操作:
- 清空日志: 点击可以迅速清除当前界面上显示的所有日志内容,还原一个干净的视图(此操作不影响后台的
app.log文件)。 - 保存日志: 点击后,系统会将当前界面显示的(已应用过滤规则的)日志内容导出到一个用户指定的文本文件中,方便存档或分享。
- 测试日志: 点击会生成几条不同级别的模拟日志,用于快速验证日志系统的显示和颜色功能是否正常。

2.4 特殊日志的差异化处理——增加回测进度条显示
系统对特定类型的日志进行了特殊处理,以优化信息呈现。例如,所有与交易下单、撤单、成交相关的回报信息,都被归类为 TRADE 级别,并以独特的蓝色显示,这使得用户在滚动浏览日志时能非常容易地追踪到交易活动。另一方面,对于回测过程中的进度反馈(例如,"回测进度: 55.3%"),这类信息虽然也会在后台日志中记录,但在界面上并不会直接逐条打印,而是被用来驱动主窗口底部状态栏中的进度条进行实时更新。这种处理方式避免了大量进度信息刷屏,同时提供了更为直观、集中的进度展示。

三、 在策略中使用日志
为了方便调试和监控策略的内部状态,您可以在策略代码中直接调用日志输出功能,将信息发送到看海量化交易系统的日志系统(包括界面和文件)。
您可以根据需要输出不同级别的日志信息,这些级别与界面上显示的颜色直接对应:
- 普通信息 (INFO): 使用
self.log("进入长仓条件判断", "INFO")或类似语句输出常规的流程信息或变量状态。这对应界面上的 白色 文本。 - 调试信息 (DEBUG): 如果需要输出更详细的、仅在调试时关心的变量值或中间计算结果,可以使用
self.log("当前ATR值", "DEBUG")。这对应界面上的 浅紫色 文本。 - 警告信息 (WARNING): 当策略遇到一些非致命但需要注意的情况时,比如某个数据获取失败但有备用方案,可以使用
self.log("无法获取最新行情,使用上一周期数据代替", "WARNING")。这对应界面上的 橙色 文本,比较醒目。 - 错误信息 (ERROR): 当策略发生严重错误,可能导致后续逻辑无法正常执行时,应使用
self.log("计算指标时出现除零错误", "ERROR")。这对应界面上最醒目的 红色 文本,强烈提示需要检查问题。 - 交易信息 (TRADE): 虽然系统会自动记录委托和成交回报,但如果您想在策略逻辑中额外标记关键的交易决策点或记录自定义的交易相关信息,也可以使用
self.log(f"信号触发,准备买入", "TRADE")。这对应界面上的 蓝色 文本。
如何输出醒目的内容?
如果您希望某条日志信息在界面上特别突出,最直接的方式是使用 WARNING 或 ERROR 级别。ERROR 级别(红色)最为醒目,通常用于指示发生了必须处理的问题。WARNING 级别(橙色)也比较突出,适合用于提示潜在风险或需要关注的状态。请根据信息的重要性和紧急程度,审慎选择合适的级别进行输出。
四、下一步考虑
后边还有几件事要做,做完后回测系统就可以跟大家见面了:
- 策略的项目化管理设置
- 与成熟的回测软件(比如QMT)进行相同策略的对比,以验证软件的有效性
因此,目前的回测系统还不满足放出来给大家使用的状态,待测试稳定后,快捷的安装包版本以及全部开源代码都会放出来给读者朋友们使用。
近期我尽量加快软件和文章更新的频率,尽早让朋友们使用上这个软件。
end、开通miniQMT
升级后的数据下载模块会随着后续回测系统的发布一同更新发布。
上述讲到的系统是基于miniQMT,很多券商都可以开通miniQMT,不过门槛各有不同,很多朋友找不到合适的券商和开通渠道。这里我可以联系券商渠道帮忙开通,股票交易费率是万1,开通成功的朋友都可以免费使用上边开发的“看海量化交易系统”。这个系统还在持续开发的过程中,数据下载的功能已经可以使用,回测部分正在加紧开发,大家可以先开通MiniQMT的权限,这样回测部分的功能放出后就能第一时间用上了~
对于想要开通miniQMT、使用上边开发的“看海量化交易系统”的朋友们,请大家关注一下我的公众号“看海的城堡”,在公众号页面下方点击相应标签即可获取。

相关文章
【深度学习量化交易1】一个金融小白尝试量化交易的设想、畅享和遐想
【深度学习量化交易2】财务自由第一步,三个多月的尝试,找到了最合适我的量化交易路径
【深度学习量化交易3】为了轻松免费地下载股票历史数据,我开发完成了可视化的数据下载模块
【深度学习量化交易4】 量化交易历史数据清洗——为后续分析扫清障碍
【深度学习量化交易5】 量化交易历史数据可视化模块
【深度学习量化交易6】优化改造基于miniQMT的量化交易软件,已开放下载~(已完成数据下载、数据清洗、可视化模块)
【深度学习量化交易7】miniQMT快速上手教程案例集——使用xtQuant进行历史数据下载篇
【深度学习量化交易8】miniQMT快速上手教程案例集——使用xtQuant进行获取实时行情数据篇
【深度学习量化交易9】miniQMT快速上手教程案例集——使用xtQuant获取基本面数据篇
【深度学习量化交易10】miniQMT快速上手教程案例集——使用xtQuant获取板块及成分股数据篇
【深度学习量化交易11】miniQMT快速上手教程——使用XtQuant进行实盘交易篇(一万七千字超详细版本)
【深度学习量化交易12】基于miniQMT的量化交易框架总体构建思路——回测、模拟、实盘通吃的系统架构
【深度学习量化交易13】继续优化改造基于miniQMT的量化交易软件,增加补充数据功能,优化免费下载数据模块体验!
【深度学习量化交易14】正式开源!看海量化交易系统——基于miniQMT的量化交易软件
【深度学习量化交易15】基于miniQMT的量化交易回测系统已基本构建完成!AI炒股的框架初步实现
【深度学习量化交易16】韭菜进阶指南:A股交易成本全解析
【深度学习量化交易17】触发机制设置——基于miniQMT的量化交易回测系统开发实记
【深度学习量化交易18】盘前盘后回调机制设计与实现——基于miniQMT的量化交易回测系统开发实记
【深度学习量化交易19】行情数据获取方式比测(1)——基于miniQMT的量化交易回测系统开发实记
【深度学习量化交易20】量化交易策略评价指标全解析——基于miniQMT的量化交易回测系统开发实记
【深度学习量化交易21】行情数据获取方式比测(2)——基于miniQMT的量化交易回测系统开发实记
【AI量化第22篇】如何轻松看懂回测结果——基于miniQMT的量化交易回测系统开发实记
【AI量化第23篇】数据下载/补充模块升级,并与回测系统正式集成——基于miniQMT的量化交易回测系统开发实记
【AI量化第24篇】KhQuant 策略框架深度解析:让策略开发回归本质——基于miniQMT的量化交易回测系统开发实记