【Netty篇】ByteBuf 详解 (下)

目录
- 一、ByteBuf的“读心术”——读取数据!
- 二、ByteBuf的“生命魔法”—— retain & release!🧙♂️✨
- 三、ByteBuf的“分身术”—— slice!🔪👯
- 四、ByteBuf的“克隆术”—— duplicate!👯♂️👯♀️
- 五、ByteBuf的“影分身之术”—— copy!👯♂️
- 六、ByteBuf的“合体术”—— CompositeByteBuf!🤝🔗
- 七、ByteBuf的“独门秘籍”—— Unpooled!📜
🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支持一下,感谢🤗!
🌟了解 Netty 的 线程模型 请看 : 【Netty篇】Netty的线程模型
其他优质专栏: 【🎇SpringBoot】【🎉多线程】【🎨Redis】【✨设计模式专栏(已完结)】…等
如果喜欢作者的讲解方式,可以点赞收藏加关注,你的支持就是我的动力
✨更多文章请看个人主页: 码熔burning
各位观众老爷,今天咱们来聊聊 Netty 里的“管道工”—— Channel。幽默风趣的讲解方式,让您听得懂,记得住!🤣
看之前可以先看看Netty的入门:【Netty篇】幽默的讲解带你入门 Netty !建议收藏
精彩继续!各位观众,欢迎回到“Netty奇妙夜”之“ByteBuf探秘”下半场!🕵️♂️ 今晚,我们要继续深入挖掘ByteBuf的各种神奇技能!首先,让我们聚焦它的“读心术”——读取数据!📖
一、ByteBuf的“读心术”——读取数据!
写入数据就像我们往ByteBuf这个“百宝箱”里塞东西,而读取数据呢,就是我们从这个“百宝箱”里往外掏东西。ByteBuf提供了一系列的读取方法,让我们能够按照不同的数据类型和方式,将箱子里的宝贝取出来。
与写入方法类似,ByteBuf的读取方法也分为按字节、按基本数据类型以及按块读取等。读取操作的关键在于Reader Index(读指针),每次读取成功后,读指针都会自动向后移动,指向下一个待读取的字节。这就像我们从一个装满零食的罐子里拿东西,拿走一个,手就会伸向下一个。🍬➡️😋
下面我们来演示一下读取过程,看看ByteBuf是如何把我们之前写入的数据“吐”出来的!👅
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import java.nio.charset.StandardCharsets;public class ByteBufReadExample {public static void main(String[] args) {// 创建一个堆缓冲区,并写入一些数据,就像往罐子里塞各种零食ByteBuf buffer = ByteBufAllocator.DEFAULT.heapBuffer(32);buffer.writeByte(100); // 'd' - 一块巧克力 🍫buffer.writeBoolean(true); // true - 一颗软糖 buffer.writeShort(256); // 一个小饼干 🍪buffer.writeInt(65535); // 一根棒棒糖 🍭buffer.writeCharSequence("Netty", StandardCharsets.UTF_8); // 一包印着 "Netty" 的薯片 🍟buffer.writeBytes(new byte[]{'b', 'u', 'f'}); // 三颗花生豆 🥜🥜🥜System.out.println("写入数据后的 ByteBuf 状态:");printBufferDetails(buffer);System.out.print("\n开始读取数据,看看我们掏出了什么:");// 读取一个字节,掏出一块巧克力byte readByte = buffer.readByte();System.out.println("\n读取一个字节: " + readByte + " (char: " + (char) readByte + ")");printBufferDetails(buffer); // 读指针向后移动了一位// 读取一个布尔值,掏出一颗软糖boolean readBoolean = buffer.readBoolean();System.out.println("\n读取一个布尔值: " + readBoolean);printBufferDetails(buffer); // 读指针又向后移动了一位// 读取一个短整型,掏出一个小饼干short readShort = buffer.readShort();System.out.println("\n读取一个短整型: " + readShort);printBufferDetails(buffer); // 读指针向后移动了两// 读取一个整型,掏出一根棒棒糖int readInt = buffer.readInt();System.out.println("\n读取一个整型: " + readInt);printBufferDetails(buffer); // 读指针向后移动了四位// 读取一个字符串,掏出一包 "Netty" 薯片CharSequence readCharSequence = buffer.readCharSequence(5, StandardCharsets.UTF_8);System.out.println("\n读取一个字符串 (5 字节): " + readCharSequence);printBufferDetails(buffer); // 读指针向后移动了五位// 读取剩余的字节数组,掏出三颗花生豆byte[] remainingBytes = new byte[buffer.readableBytes()];buffer.readBytes(remainingBytes);System.out.print("\n读取剩余的字节数组: [");for (int i = 0; i < remainingBytes.length; i++) {System.out.print((char) remainingBytes[i] + (i == remainingBytes.length - 1 ? "" : ", "));}System.out.println("]");printBufferDetails(buffer); // 读指针移动到了写指针的位置// 读取完毕,readerIndex 等于 writerIndex,罐子空了!System.out.println("\n读取完毕后的 ByteBuf 状态:");printBufferDetails(buffer);buffer.release(); // 吃完零食,记得清理罐子(释放 ByteBuf)!🧹}private static void printBufferDetails(ByteBuf buffer) {System.out.print(" Capacity: " + buffer.capacity());System.out.print(" \tReader Index: " + buffer.readerIndex());System.out.print(" \tWriter Index: " + buffer.writerIndex());System.out.print(" \tReadable Bytes: " + buffer.readableBytes());System.out.print(" \tWritable Bytes: " + buffer.writableBytes());}
}
运行结果
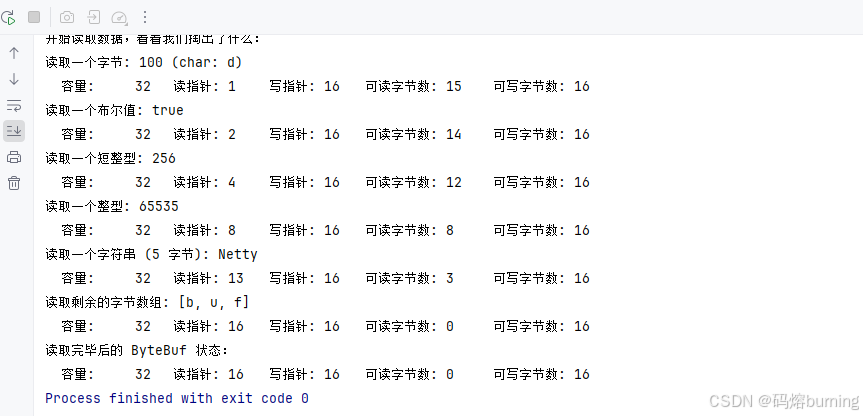
你会看到随着我们使用 readByte(), readBoolean(), readShort(), readInt(), readCharSequence(), readBytes() 等方法读取数据,readerIndex 会不断向后移动,而 readableBytes 则相应减少。就像我们从“百宝箱”里一件件地掏出宝贝,箱子里剩下的东西就越来越少啦!📦➡️
接下来,我们将学习ByteBuf的“生命魔法”和各种“分身术”!😉
二、ByteBuf的“生命魔法”—— retain & release!🧙♂️✨
在Netty的世界里,ByteBuf是一个需要我们手动管理生命周期的资源,特别是对于使用了内存池的 ByteBuf。retain() 和 release() 就是管理ByteBuf引用计数的两个关键方法,它们就像给ByteBuf施加了“生命魔法”!
-
retain(): 这个方法会增加 ByteBuf 的引用计数。想象一下,你手里拿着一个珍贵的魔法卷轴📜(ByteBuf),如果你想把这个卷轴借给多个魔法师🧙♂️🧙♀️一起研习,但又不想让它消失,你就可以复制几份“引用”(增加引用计数)。每个魔法师都持有一份“引用”,表示他们正在使用这个卷轴。 -
release(): 这个方法会减少 ByteBuf 的引用计数。当魔法师研习完毕,不再需要这个卷轴时,他们就会归还他们的“引用”(减少引用计数)。只有当所有魔法师都归还了他们的“引用”,即引用计数降为 0 时,这个卷轴才会被送回魔法图书馆(内存池)或者被销毁(非池化)。如果你忘记release(),就相当于魔法卷轴被某个魔法师永远占用了,其他魔法师就无法使用,最终导致魔法世界的资源枯竭(内存泄漏!😱)。
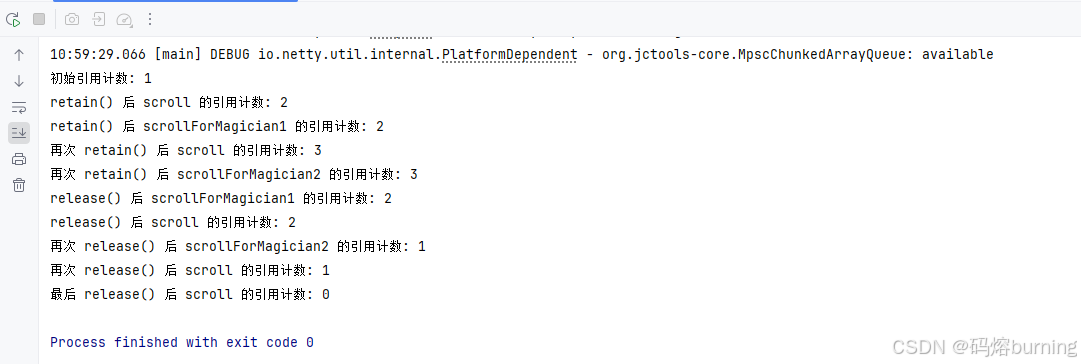
代码演示:retain & release
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;public class ByteBufRetainReleaseExample {public static void main(String[] args) {// 从魔法泉水(ByteBufAllocator)中获取一个魔法卷轴(directBuffer)ByteBuf scroll = ByteBufAllocator.DEFAULT.directBuffer();System.out.println("初始引用计数: " + scroll.refCnt()); // 初始引用计数为 1,表示我们拥有这个卷轴// 第一个魔法师(main 方法)想要继续持有这个卷轴,增加引用计数ByteBuf scrollForMagician1 = scroll.retain();System.out.println("retain() 后 scroll 的引用计数: " + scroll.refCnt()); // 变为 2System.out.println("retain() 后 scrollForMagician1 的引用计数: " + scrollForMagician1.refCnt()); // 也为 2,它们指向同一个卷轴// 第二个魔法师也想看看这个卷轴,再次增加引用计数ByteBuf scrollForMagician2 = scroll.retain();System.out.println("再次 retain() 后 scroll 的引用计数: " + scroll.refCnt()); // 变为 3System.out.println("再次 retain() 后 scrollForMagician2 的引用计数: " + scrollForMagician2.refCnt()); // 也为 3// 第一个魔法师研习完毕,归还他的“引用”scrollForMagician1.release();System.out.println("release() 后 scrollForMagician1 的引用计数: " + scrollForMagician1.refCnt()); // 变为 2System.out.println("release() 后 scroll 的引用计数: " + scroll.refCnt()); // 仍然是 2// 第二个魔法师也研习完毕,归还他的“引用”scrollForMagician2.release();System.out.println("再次 release() 后 scrollForMagician2 的引用计数: " + scrollForMagician2.refCnt()); // 变为 1System.out.println("再次 release() 后 scroll 的引用计数: " + scroll.refCnt()); // 仍然是 1// 最后,我们(main 方法)也用完了,归还我们的“引用”scroll.release();System.out.println("最后 release() 后 scroll 的引用计数: " + scroll.refCnt()); // 变为 0,卷轴被送回魔法图书馆或销毁// 尝试操作引用计数为 0 的卷轴通常会引发异常// try {// scrollForMagician1.writeByte(0);// } catch (io.netty.util.IllegalReferenceCountException e) {// System.err.println("\n尝试操作已释放的卷轴: " + e.getMessage());// }}
}
运行结果:
三、ByteBuf的“分身术”—— slice!🔪👯
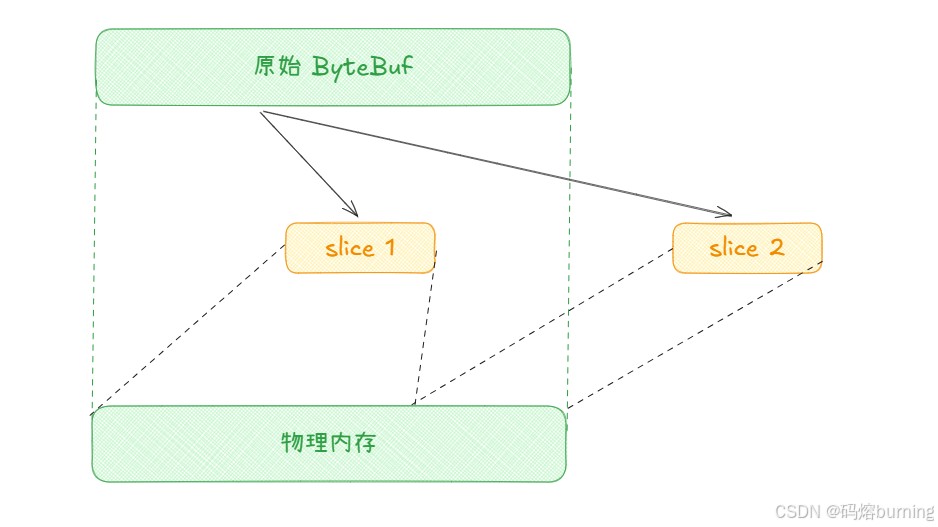
想象一下,我们有一个大披萨(原始 ByteBuf),上面有各种美味的馅料。slice() 操作就像从这个大披萨上切下几块小披萨。每一小块都共享着大披萨的馅料,但每一块都有自己的“起点”和“可食用”范围。
代码演示:slice
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import java.nio.charset.StandardCharsets;public class ByteBufSlicePizzaExample {public static void main(String[] args) {// 我们的原始大披萨,上面写着 "DeliciousPizza"ByteBuf bigPizza = ByteBufAllocator.DEFAULT.heapBuffer(15);bigPizza.writeCharSequence("DeliciousPizza", StandardCharsets.UTF_8);System.out.println("原始大披萨: " + bigPizza.toString(StandardCharsets.UTF_8));printBufferDetails("大披萨", bigPizza);// 切下第一块:从索引 0 开始,长度为 5,内容是 "Delic"ByteBuf slice1 = bigPizza.slice(0, 5);System.out.println("\n切下的第一块 (0, 5): " + slice1.toString(StandardCharsets.UTF_8));printBufferDetails("第一块披萨", slice1);// 切下第二块:从索引 5 开始,长度为 7,内容是 "iousPiz"ByteBuf slice2 = bigPizza.slice(5, 7);System.out.println("\n切下的第二块 (5, 7): " + slice2.toString(StandardCharsets.UTF_8));printBufferDetails("第二块披萨", slice2);// 切下第三块:从索引 12 开始,到末尾,内容是 "za"ByteBuf slice3 = bigPizza.slice(12, bigPizza.writerIndex() - 12);System.out.println("\n切下的第三块 (12, end): " + slice3.toString(StandardCharsets.UTF_8));printBufferDetails("第三块披萨", slice3);// 在第一块披萨上“加点辣” (修改数据)slice1.setByte(0, 'J'); // 将 'D' 改为 'J'System.out.println("\n在第一块披萨上加辣后,第一块披萨的内容: " + slice1.toString(StandardCharsets.UTF_8));System.out.println("加辣后,原始大披萨的内容: " + bigPizza.toString(StandardCharsets.UTF_8)); // 大披萨也变“辣”了!printBufferDetails("加辣后的第一块披萨", slice1);System.out.println();printBufferDetails("加辣后的大披萨", bigPizza);System.out.println();printBufferDetails("第二块披萨 (未受影响)", slice2);System.out.println();printBufferDetails("第三块披萨 (未受影响)", slice3);bigPizza.release();}private static void printBufferDetails(String name, ByteBuf buffer) {System.out.print(" --- " + name + " ---");System.out.print(" 容量: " + buffer.capacity());System.out.print(" \t读指针: " + buffer.readerIndex());System.out.print(" \t写指针: " + buffer.writerIndex());System.out.print(" \t可读字节数: " + buffer.readableBytes());System.out.print(" \t可写字节数: " + buffer.writableBytes());System.out.print(" \t字符串的值: " + buffer.toString(StandardCharsets.UTF_8));}
}
运行结果:

四、ByteBuf的“克隆术”—— duplicate!👯♂️👯♀️
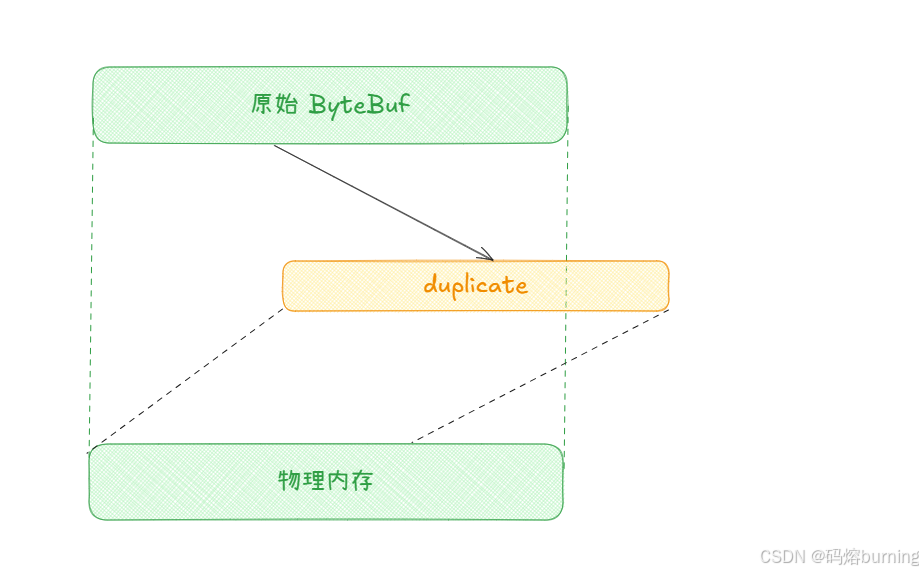
想象一下,我们有一份重要的原始文件(原始 ByteBuf),上面记录了一些关键信息,并且我们已经阅读到了一部分,也记录了一部分(移动了 readerIndex 和 writerIndex)。现在,我们想要创建一个这份文件的副本,让另一个人也从我们阅读和记录的位置开始查看。duplicate() 操作就像复印了这份文件,副本的内容和当前的阅读/记录状态都与原件保持一致,但它们是两个独立的文件对象。
代码演示:duplicate
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import java.nio.charset.StandardCharsets;public class ByteBufDuplicateFileExample {public static void main(String[] args) {// 原始的重要文件,内容是 "ConfidentialData"ByteBuf originalFile = ByteBufAllocator.DEFAULT.heapBuffer(16);originalFile.writeCharSequence("ConfidentialData", StandardCharsets.UTF_8);originalFile.readerIndex(5); // 假设我们已经阅读到 "ential" 的位置originalFile.writerIndex(12); // 假设我们已经记录了 "Confidential" 这部分System.out.println("原始文件内容: " + originalFile.toString(StandardCharsets.UTF_8));printBufferDetails("原始文件", originalFile);// 复印一份文件ByteBuf duplicateFile = originalFile.duplicate();System.out.println("\n复印的文件内容: " + duplicateFile.toString(StandardCharsets.UTF_8));printBufferDetails("复印的文件", duplicateFile); // 注意 readerIndex 和 writerIndex 也被复制了// 在复印件上“高亮”一部分内容 (修改数据)duplicateFile.setByte(duplicateFile.readerIndex(), '*'); // 在复印件当前阅读位置添加高亮System.out.println("\n在复印件上高亮后,复印件的内容: " + duplicateFile.toString(StandardCharsets.UTF_8));System.out.println("在复印件上高亮后,原始文件的内容: " + originalFile.toString(StandardCharsets.UTF_8)); // 原始文件也被修改了!printBufferDetails("高亮后的复印文件", duplicateFile);System.out.println();printBufferDetails("高亮后的原始文件", originalFile);originalFile.release();}private static void printBufferDetails(String name, ByteBuf buffer) {System.out.print(" --- " + name + " ---");System.out.print(" 容量: " + buffer.capacity());System.out.print(" \t读指针: " + buffer.readerIndex());System.out.print(" \t写指针: " + buffer.writerIndex());System.out.print(" \t可读字节数: " + buffer.readableBytes());System.out.print(" \t可写字节数: " + buffer.writableBytes());System.out.print(" \tbuffer的值: " + buffer.toString(StandardCharsets.UTF_8));}
}
运行结果:

五、ByteBuf的“影分身之术”—— copy!👯♂️
想象一下,我们有一张珍贵的照片(原始 ByteBuf),记录着一段美好的回忆。我们想要复制一张完全一样的照片留作纪念,即使在复制的照片上涂鸦或修改,也不会影响到原始的照片。copy() 操作就像拍摄了一张照片的副本,副本拥有与原件完全相同的内容和状态,但它们是两张独立的照片。
代码演示:copy
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;public class ByteBufCopyPhotoExample {public static void main(String[] args) {// 原始的珍贵照片,记录着 "HappyMemory"ByteBuf originalPhoto = ByteBufAllocator.DEFAULT.heapBuffer(12);originalPhoto.writeCharSequence("HappyMemory", StandardCharsets.UTF_8);originalPhoto.readerIndex(2); // 假设我们正在查看从 'p' 开始的部分originalPhoto.writerIndex(10); // 假设照片的有效信息到 'r' 结束System.out.println("原始照片内容: " + originalPhoto.toString(StandardCharsets.UTF_8));printBufferDetails("原始照片", originalPhoto);// 拍摄一张照片的副本ByteBuf copiedPhoto = originalPhoto.copy();System.out.println("\n复制的照片内容: " + copiedPhoto.toString(StandardCharsets.UTF_8));printBufferDetails("复制的照片", copiedPhoto); // readerIndex 和 writerIndex 也被复制了// 在复制的照片上“涂鸦” (修改数据)copiedPhoto.setByte(copiedPhoto.readerIndex(), 'X'); // 在复制的照片当前查看位置涂鸦System.out.println("\n在复制的照片上涂鸦后,复制的照片内容: " + copiedPhoto.toString(StandardCharsets.UTF_8));System.out.println("在复制的照片上涂鸦后,原始照片的内容: " + originalPhoto.toString(StandardCharsets.UTF_8)); // 原始照片完好无损!printBufferDetails("涂鸦后的复制照片", copiedPhoto);System.out.println();printBufferDetails("原始照片", originalPhoto);originalPhoto.release();}private static void printBufferDetails(String name, ByteBuf buffer) {System.out.print(" --- " + name + " ---");System.out.print(" 容量: " + buffer.capacity());System.out.print(" \t读指针: " + buffer.readerIndex());System.out.print(" \t写指针: " + buffer.writerIndex());System.out.print(" \t可读字节数: " + buffer.readableBytes());System.out.print(" \t可写字节数: " + buffer.writableBytes());System.out.print(" \tbuffer的值的值: " + buffer.toString(StandardCharsets.UTF_8));}
}
运行结果:

六、ByteBuf的“合体术”—— CompositeByteBuf!🤝🔗
CompositeByteBuf 就像乐高积木一样,它允许我们将多个不同的 ByteBuf 逻辑上组合成一个单一的 ByteBuf。这样做的好处是可以避免不必要的数据拷贝,特别是在处理由多个独立的数据块组成的消息时(比如消息头和消息体)。CompositeByteBuf 对外表现得像一个连续的缓冲区,但其内部是由多个小的 ByteBuf 组成的。这就像我们把几段绳子连接起来,虽然每段绳子是独立的,但连接后可以当作一根更长的绳子使用。
代码演示:CompositeByteBuf
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import io.netty.buffer.CompositeByteBuf;
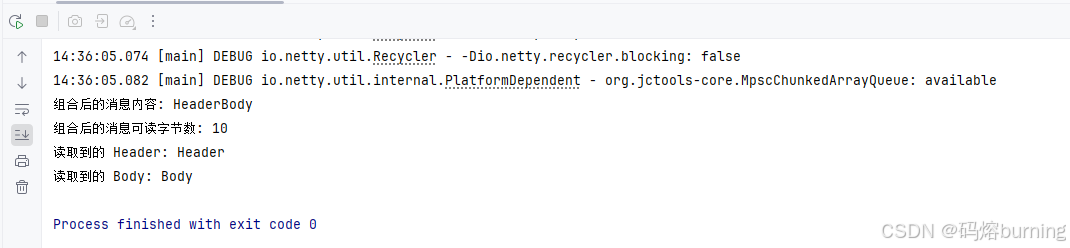
import java.nio.charset.StandardCharsets;public class CompositeByteBufExample {public static void main(String[] args) {// 创建消息头ByteBuf headerBuf = ByteBufAllocator.DEFAULT.heapBuffer(10);headerBuf.writeCharSequence("Header", StandardCharsets.UTF_8);// 创建消息体ByteBuf bodyBuf = ByteBufAllocator.DEFAULT.heapBuffer(10);bodyBuf.writeCharSequence("Body", StandardCharsets.UTF_8);// 将消息头和消息体“连接”成一个 CompositeByteBufCompositeByteBuf messageBuf = ByteBufAllocator.DEFAULT.compositeBuffer();messageBuf.addComponents(true, headerBuf, bodyBuf); // true 表示在 release() messageBuf 时也 release() 这些组件System.out.println("组合后的消息内容: " + messageBuf.toString(StandardCharsets.UTF_8));System.out.println("组合后的消息可读字节数: " + messageBuf.readableBytes());// 像操作一个普通的 ByteBuf 一样读取组合后的消息CharSequence header = messageBuf.readCharSequence(6, StandardCharsets.UTF_8);CharSequence body = messageBuf.readCharSequence(4, StandardCharsets.UTF_8);System.out.println("读取到的 Header: " + header);System.out.println("读取到的 Body: " + body);messageBuf.release(); // 释放组合缓冲区会自动释放其组件 (因为 addComponents 的第一个参数是 true)}
}
运行结果:
七、ByteBuf的“独门秘籍”—— Unpooled!📜
我们之前已经接触过 Unpooled 类,它提供了一些静态方法来创建非池化的 ByteBuf 实例。这些方法通常用于一些特殊的场景或者简单的测试,因为非池化的 ByteBuf 每次都会分配新的内存,在高并发环境下可能会影响性能。这就像我们每次需要用笔都买一支新笔,而不是用完墨水就换笔芯,有点浪费资源。
代码演示:Unpooled
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
import java.nio.charset.StandardCharsets;
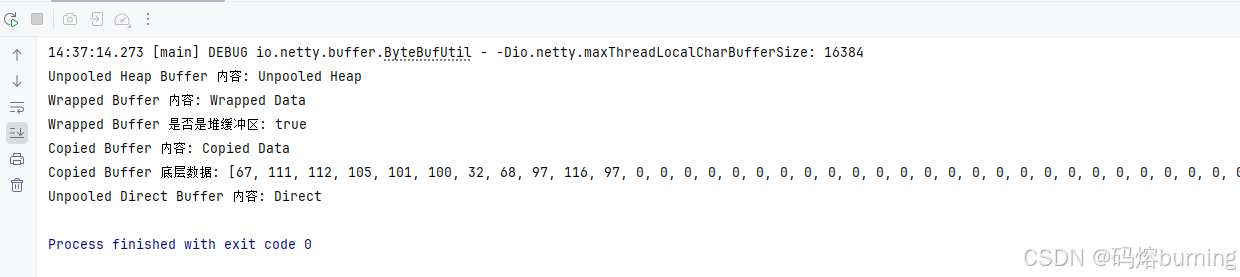
import java.util.Arrays;public class UnpooledExample {public static void main(String[] args) {// 创建一个非池化的堆缓冲区ByteBuf unpooledHeapBuf = Unpooled.buffer(16);unpooledHeapBuf.writeCharSequence("Unpooled Heap", StandardCharsets.UTF_8);System.out.println("Unpooled Heap Buffer 内容: " + unpooledHeapBuf.toString(StandardCharsets.UTF_8));unpooledHeapBuf.release(); // 用完也要记得 release()// 创建一个包含已有数据的非池化堆缓冲区 (wrapped buffer)byte[] data = "Wrapped Data".getBytes(StandardCharsets.UTF_8);ByteBuf wrappedBuffer = Unpooled.wrappedBuffer(data);System.out.println("Wrapped Buffer 内容: " + wrappedBuffer.toString(StandardCharsets.UTF_8));System.out.println("Wrapped Buffer 是否是堆缓冲区: " + wrappedBuffer.hasArray());wrappedBuffer.release();// 创建一个直接包含字节数组的非池化堆缓冲区 (copied buffer)ByteBuf copiedBuffer = Unpooled.copiedBuffer("Copied Data", StandardCharsets.UTF_8);System.out.println("Copied Buffer 内容: " + copiedBuffer.toString(StandardCharsets.UTF_8));System.out.println("Copied Buffer 底层数据: " + Arrays.toString(copiedBuffer.array()));copiedBuffer.release();// 创建一个空的非池化直接缓冲区ByteBuf unpooledDirectBuf = Unpooled.directBuffer(8);unpooledDirectBuf.writeCharSequence("Direct", StandardCharsets.UTF_8);System.out.println("Unpooled Direct Buffer 内容: " + unpooledDirectBuf.toString(StandardCharsets.UTF_8));unpooledDirectBuf.release();}
}
运行结果::
好了,各位观众!今晚的“ByteBuf变形记”就到