数据表示与运算
在计算机中,数据需要按照一定的规则表示、存储和计算,常见的数据表示方法包括二进制表示、八进制表示和十六进制表示。编程语言中支持的数据类型也很多,一般分为基本数据类型和引用数据类型。其中基本数据类型是直接存储数值的,包括字符型char、布尔值、整型(signed,unsigned int,short,long)和浮点类型(float、double)。引用类型则一般存储对应的地址如数组、字符串、结构体和对象等。一些高级编程语言还支持空类型和函数类型等数据类型。
1 数制与编码
1.1 进位计数制
1)进位计数法
日常生活中人们常用的数制是十进制,在计算机中则通常使用二进制、八进制和十六进制数。对于不同的进制,可以采用进位计数法统一的表示。基数是指每个数位可以获取的不同数码的个数,如二进制就是0和1,八进制就是0~7,十进制是0~9,十六进制就是0~9,A~F(A=10,以此类推)。位权是指所在数位上的一个常数,取值为进制数值的n-1次幂,n为从低位向高位方向数的数位,n从0开始,对于小数部分,n从小数点后依次减一。具体如下,对于一个r进制的数其大小可以表示为
K的取值在0~r-1之间任意一个数。
2)进制转换
a. 十进制与任意进制转换
对于任意进制转化为十进制,只需要将各个数位的值乘以对应的权值,然后相加就可以得到对应十进制值。对于十进制转其他进制,则需要将整数和小数部分分别处理。对于整数部分采用除基取余法,小数部分则采用乘基取整法,最后将两部分结果拼接。
二进制转十进制
十进制转二进制
将123.6875转化为二进制,整数部分采用除基取余法,不断除以2,直到商为0,每次的余数先填充低位即先余为低,后余为高,商0结束。
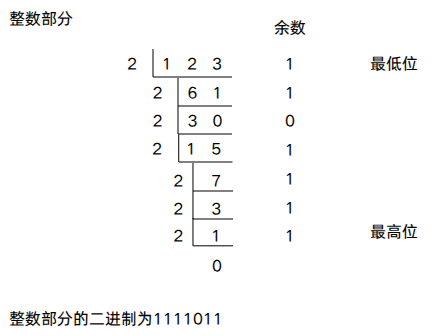
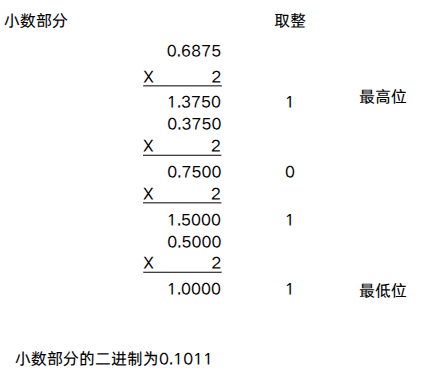
小数部分则通过乘基取整法,不断给小数部分乘以2,然后取整数部分,先满足高位,直到乘积为1时结束。每次取正整需要把整数部分拿掉,只留小数部分做下一次乘积。
b. 二进制与八进制/十六进制转换
一个八进制的数位转化到二进制长度为3位,十六进制转为二进制一个数对应4位二进制数,因此在二进制转八或十六进制时,可以每3为或4位的取数并转化。方法如下,以小数点为起点,整数部分从右向左,每3或4选一组数,然后转化为对应的8或16进制数,位数不足的高位(最左边)补0。小数部分则从左向右,位数不足的低位(最右边)补0。

八进制或十六进制转二进制则简单些,只需要将各个位数上的0~7的八进制数或0~F的十六进制转化为二进制数然后拼接即可。
1.2 定点数编码表示
计算机中的数据表示方法根据小数点的位置是否固定可以分为定点数表示和浮点数表示。事实上,在机器内部并没有小数点,只是人为约定了小数点的位置。因此,在定点数的编码和运算中不用考虑对应的定点数是小数还是整数,而只需关心它们的符号位和数值位即可。定点小数是纯小数,小数点规定在符号位之后,数值部分最高位之前。定点整数是纯整数,约定小数点位置在有效数值部分最低位之后。
1.2.1 定点数的表示方法
定点数的编码表示法主要有以下4种:原码、补码、反码和移码。之所以弄这么多种表示方式是为了提高运算效率,减轻硬件的设计负担,简化电路设计,让符号位也参与运算。通常用补码整数表示整数,用原码小数表示浮点数的尾数部分,用移码表示浮点数的阶码部分。
1)原码表示法
给定字长,最高位为符号为,0为正,1为负,其余数位存储机器数的绝对值二进制数,从低位开始存,高位不足补0。零的原码表示有正零和负零两种形式, [+0]=00000000 和 [-0]=10000000。原码表示范围为,n为字长。
原码实现乘除运算比较简单,但是加减运算比较复杂。由于符号位的影响,先要比较两个数的绝对值大小,然后用绝对值大的数减去绝对值小的数,最后还要为结果选择合适的符号。
2)反码表示法
正数的反码就是其原码,负数的反码就是除符号位,其余各位取反。反码解决了原码做减法的问题,但是0存在两种表示,计算复杂性会增加。反码表示范围与原码相同。反码几乎不同。
3)补码表示法
正数补码就是其原码,负数的补码除符号位外,其余数位取反加一。补码统一了0的表示方式,只有[+0] = [-0] = 00000000,同时简化了运算,将减法转化为加法。补码表示范围,因为相较于原码多了一个[-0],可以用于表示最小数。
4)移码表示法
移码就是在真值X上加上一个常数,通常这个常数取2^(n-1)”,相当于X在数轴上向正方向偏移了若干单位,这就是“移码”一词的由来。具体操作,不管正负数,只要将其补码的符号位取反即可。移码与补码取值范围相同。
移码中零的表示唯一即[+0]=[-0]=10000000。移码与补码只差一个符号位。移码保持了数据原有的大小顺序,移码大真值就大,移码小真值就小。
1.2.2 定点数的运算
1.2.2.1 定点数的移位运算
对于任意二进制整数,左移一位,若不产生溢出,相当于乘以2;右移一位,若不考虑因移出而舍去的末位尾数,相当于除以2。
逻辑移位将操作数视为无符号整数。逻辑移位的规则:左移时,高位移出,低位补0;右移时,低位移出,高位补0。对于无符号整数的逻辑左移,若高位的1移出,则发生溢出。算术移位需要考虑符号位的问题,对于有符号整数的移位操作应采用补码算术移位方式。算术移位的规则:左移时,高位移出,低位补0,若移出的高位不同于移位后的符号位,即左移前后的符号位不同,则发生溢出;右移时,低位移出,高位补符号位,若低位的1移出,则影响精度。
1.2.2.2 定点数的加减运算
1)补码的加减运算
补码的加减运算规则简单,若做加法,个数的补码直接相加;若做减法,则将被减数与减数的负数补码相加。符号位与数值位一起参与运算,运算结果的符号位也在运算中直接得出。最终运算结果的高位丢弃,保留n位(字长为n),运算结果亦为补码。
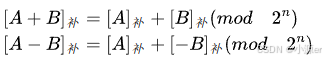
2)判断溢出
仅当两个符号相同的数相加或两个符号相异的数相减才可能产生溢出。补码定点数加减运算溢出判断的方法如采用一位符号位,参加操作的两个数的符号相同,结果又与原操作数的符号不同,则表示结果溢出。
3)原码加减运算
计算机采用的大多是补码加减运算。
在原码加减运算中,将符号位和数值位分开处理,具体的规则如下。
加法规则:遵循“同号求和,异号求差”的原则,先判断两个操作数的符号位。具体来说,符号位相同,则数值位相加,结果符号位不变,若最高数值位相加产生进位,则发生溢出;符号位不同,则做减法,绝对值大的数减去绝对值小的数,结果符号位与绝对值大的数相同。
减法规则:先将减数的符号取反,然后将被减数与符号取反后的减数按原码加法进行运算。
1.2.2.3 定点数的乘除运算
1)定点乘法运算
原码乘法的特点是符号位与数值位是分开求的,原码乘法运算分为两步:①乘积的符号位由两个乘数的符号位“异或”得到;②乘积的数值位是两个乘数的绝对值之积。乘法运算可用加法和移位运算来实现(乘以2相当于做一次右移),两个n位无符号数相乘共需进行n次加法和n次移位运算。

2)定点除法运算
原码的除法运算也是一种移位和加减运算迭代的过程。对于n位定点数的除法运算,需要对被除数进行扩展,统一为一个2n位的数除以一个n位的数,得到一个n位的商。对于定点正小数(即原码小数),只需在被除数低位添n个0即可。对于定点正整数(即无符号数),只需在被除数高位添n个0即可。做整数除法时,若除数为0,则发生“除数为0”异常,此时需调出操作系统相应的异常处理程序进行处理。
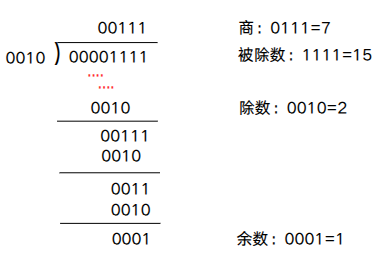
原码除法运算也要将符号位和数值位分开处理,商的符号位是两个数的符号位的“异或”结果,商的数值位是两个数的绝对值之商。除法运算的过程可归纳如下,被除数与除数相减,够减则上商为1,不够减则上商为0。每次得到的差为中间余数,用中间余数减除数,够减则上商为1,不够减则上商为0。如此重复,直到商的位数满足要求为止。
1.2.3 整数的表示
C语言中的整型数据就是定点整数,根据位数的不同,可分为字符型(char,8位)、短整型(short或shortint,16位)、整型(int,32位)、长整型(long或l,在32位机器中为32位,在64位机器中为64位)。char是整型数据中比较特殊的一种,其他如 short/int/long等不指定signed/unsigned时都默认是有符号整数,但char默认是无符号整数。
1)无符号整数表示
当一个编码的全部二进制位均为数值位而没有符号位时,该编码表示就是无符号整数,简称无符号数。由于没有符号位,所以默认为正数。无符号整数一般应用在不出现负数的场景下如地址运算等。取值范围为。
2)有符号整数表示
最高位作为符号位,0正1负,有效数字为n-1位,n为字长。有符号整数可以用原码、补码、反码和移码任意一种来表示。但补码有优势,0的表示唯一,运算规则简单,符号位可一起参与运算且比原码多表示一个最小负数。故计算机中的有符号整数都用补码表示。
1.3 浮点数编码表示
定点数中小数点位置固定,只能表示纯小数或整数,而浮点数则是允许小数点的位置根据需要而浮动。在位数有限的情况下,既扩大了数的表示范围,又保持了数的有效精度。
1.3.1 浮点数表示
浮点数通常表示为
S决定浮点数的符号,取值0或1;M是二进制定点小数,用原码表示,称作尾数;R是基数;E是二进制定点整数,用移码表示,称作阶码或指数。
按照IEEE754标准,浮点数的存储格式如下:
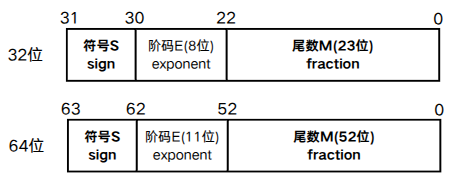
32位单精度浮点数float和64位双精度浮点数double分别用8位和11位数表示阶码,阶码的值反映浮点数的小数点的实际位置;阶码的位数反映浮点数的表示范围;尾数的位数反映浮点数的精度。
IEEE754标准中规格化单精度浮点数真值为,阶码取值范围为1~254,规格化双精度浮点数的真值为
,阶码取值范围为1~2046。

浮点数的范围就是指数的范围乘以小数的范围。比如正数的最小为2^Emin,最大值为2^Emax,小数最小为0,最大为1-2^(-n),
1.3.2 浮点数规格化
规格化操作是指通过调整一个非规格化浮点数的尾数和阶码的大小,使非零浮点数的尾数的最高数位上保证是一个有效值(非零)。其目的是使有效数字尽量占满尾数数位。简单来说,因为尾数是由原码表示的定点小数,有效值的高位可以有若干个零,这些零不影响有效值的实际大小,可以通过移动小数点,同时改变阶数来保证数据大小不变的同时且减少零的存储。举个例子,以基数为2为例,尾数M的绝对值取值范围为,当尾数为“0.0...0××”的形式时(定点小数实际上没有小数点和前面的0),可以通过左规,即将尾数不断左移,同时阶码不断减一,来实现小数点后第一位为非零数且数据大小不变。右规同理,即尾数的有效数中小数点前面有非零值,需要将小数点左移,同时阶码加1。
对于规格化的二进制浮点数,尾数的最高位总是1即M=1.f,为了能使尾数多表示一位有效位,将这个1隐藏,称为隐藏位,因此23位尾数实际表示了24位有效数字。IEEE754规定隐藏位1的位置在小数点之前,例如,,将它规格化后结果为
,其中整数部分的“1”将不存储在23位尾数内。此时,阶码字段被解释为以偏置形式表示的有符号整数,即E=e - bias,e是无符号数,真值就是二进制原码表示的无符号数(指数(阶码)转化为移码形式需要加一个偏置项,一般为
,n为有效位长度。偏移量(Bias)是一个固定的数值,用于调整指数部分的表示范围,使得浮点数能够表示正指数和负指数)。在IEEE754中,由于有一个隐藏位,指数对应应该减一位,但是指数的值并没有减,而是在偏执项中减一。因此,单精度和双精度浮点数的偏置值分别为127和1023。故阶码值为3时,在单精度浮点数中,移码表示的阶码为127+3=130(82H)。
非规格化浮点数一般用于表示数值0或者非常接近0.0的数。
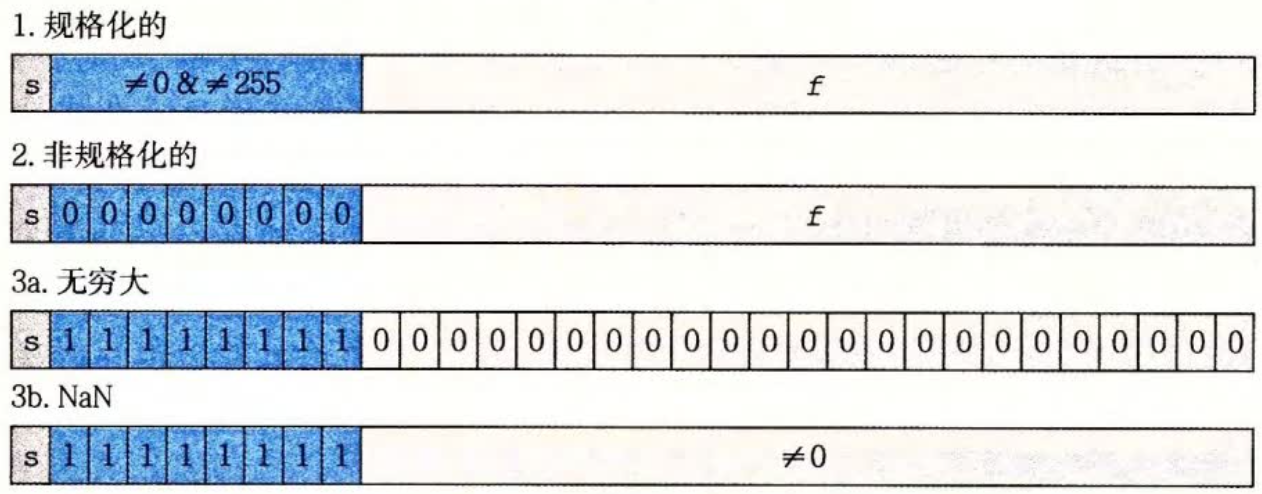
对于IEEE754格式的浮点数,阶码全为0或全为1时,有其特别的解释,
1)全0阶码全0尾数:+0/-0。零的符号取决于符号s,一般情况下+0和-0是等效的。
2)全1阶码全0尾数: +∞ 在数值上大于所有有限数,-则小于所有有限数。引入无穷大数的目的是,在计算过程出现异常的情况下使得程序能继续进行下去。
3)全1阶码非0尾数:NaN(Not a Number)。表示一个没有定义的数,称为非数。
4)全0阶码非0尾数:非规格化数。非规格化数的特点是阶码为全0,尾数高位有一个或几个连续的0,但不全为0。因此,非规格化数的隐藏位为0,且单精度和双精度浮点数的指数分别为-126或-1022。非规格化数可以用于处理阶码下溢。
1.3.3 浮点数运算
1.3.3.1 浮点数加减运算
浮点数运算的特点是阶码运算和尾数运算分开进行,浮点数加减运算分为以下几步。
首先是对阶,即让两个阶码相等,这样在计算时就只需计算尾数的加减,并且此时两个数的小数点的位置是固定的。对齐的过程就是让小阶码(绝对值)向大阶码看齐,将阶码小的尾数右移一位(基数为2),阶码加1,直到两个数的阶码相等为止。尾数右移时,若舍弃有效位会产生误差,影响精度。若采用大阶码向小阶码看齐的原则,则尾数需要左移,最高有效位被移出,导致结果出错。
然后对尾数部分按照定点小数原码表示进行加减运算。因为IEEE754浮点数尾数中有一个隐藏位,因此在进行尾数加减时,必须将隐藏位还原到尾数部分。运算后的尾数不一定是规格化的,因此,浮点数的加减运算需要进一步进行规格化处理。
尾数规格化可能会右移造成数据丢失精度下降,为保证运算精度,一般将移出的部分低位保留下来,参加中间过程的运算,最后再将运算结果进行舍入,还原表示成IEEE754格式。IEEE754有四种舍入模式即就近舍入、正向舍入、负向舍入和截断所需数位。
若一个正指数超过了最大允许值(127或1023),则发生指数上溢,产生异常。若一个负指数超过了最小允许值,则发生指数下溢,通常把结果按机器零处理。
1.3.3.2 浮点数乘除运算
浮点数的乘除运算和加减运算类似,都需要首先判断乘数和被乘数是否为零,然后对阶码进行加减,乘法则加,除法则减。然后尾数部分进行定点数的乘除操作,最后对结果进行规格化处理和溢出判断。
1.3.4 定点 VS 浮点表示
(1)数值的表示范围
若定点数和浮点数的字长相同,则浮点表示法所能表示的数值范围远大于定点表示法。浮点数取字长的一部分作为阶码,所以表示范围比定点数要大,而取一部分作为阶码也就代表着尾数部位的有效位数减少,而定点数字长的全部位都用来表示数值本身,精度要比同字长的浮点数更大。
可表示的数据个数取决于编码所采用的位数,对于位数相同的定点数和浮点数,所表示的数据个数一样多。
(2)精度
对于字长相同的定点数和浮点数来说,浮点数虽然扩大了数的表示范围,但精度降低了。
(3)数的运算
浮点数包括阶码和尾数两部分,运算时不仅要做尾数的运算,还要做阶码的运算,而且运算结果要求规格化,所以浮点运算比定点运算复杂。
(4)溢出问题
在定点运算中,当运算结果超出数的表示范围时,发生溢出;在浮点运算中,运算结果超出尾数表示范围却不一定溢出,只有规格化后阶码超出所能表示的范围时,才发生溢出。
1.3.5 数据的大小端存储和对齐存储
1.3.5.1 大小端存储
在存储数据时,数据从低位到高位可以按从左到右排列,也可以按从右到左排列。因此,无法用最左或最右来表征数据的最高位或最低位,通常用最低有效字节(LSB)和最高有效字节(MSB)来分别表示数据的低位和高位。现代计算机基本都采用字节编址,即每个地址编号中存放1字节。不同类型的数据占用的字节数不同,根据数据中各字节在连续字节序列中的排列顺序不同,可以采用两种排列方式:大端方式(bigendian)和小端方式(littleendian)。
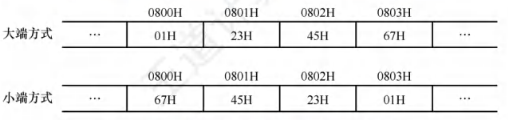
大端方式:先存储高位字节,后存储低位字节。字中的字节顺序和原序列的相同。小端方式:先存储低位字节,后存储高位字节。字中的字节顺序和原序列的相反。
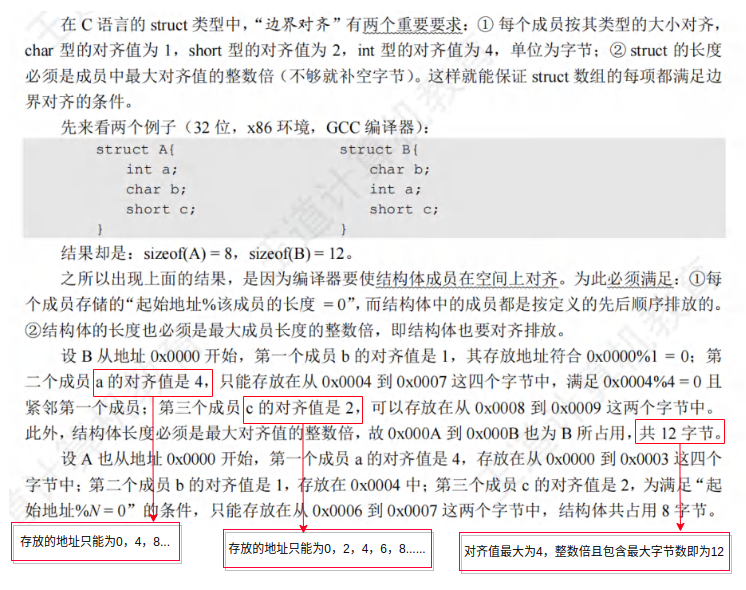
1.3.5.2 对齐存储
数据按边界对齐方式存放要求其存储地址是自身大小的整数倍,当所存数据不满足上述要求时,可通过填充空白字节使其符合要求。当数据不按边界对齐方式存储时,半字长或字长的数据可能在两个存储字中,此时需要两次访存,并对高低字节的位置进行调整后才能得到所需数据,从而影响了系统的效率。
王道中的例子:
2 长度/精度不同的数据表示
2.1 C/C++语言中各数据表示的大小
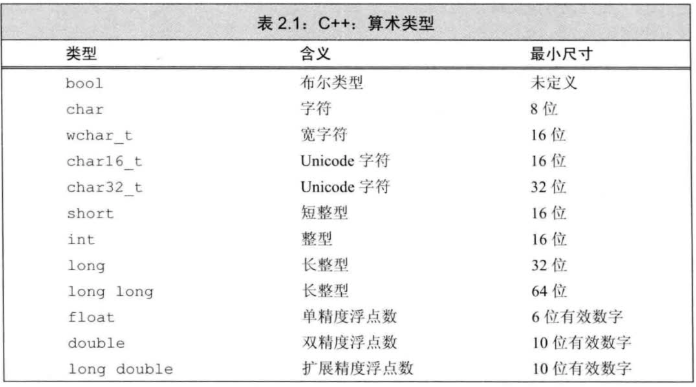
每台机器都有一个字长,用于指明指针数据的大小。字长决定了虚拟地址空间的大小。对于32位程序和64位的程序,区别在于该程序如何编译而不是所运行的机器类型。计算机和编译器支持多种不同方式编码的数字格式,如不同长度的整数和浮点数。C/C++标准规定了尺寸的最小值,同时允许编译器赋予类型更大的尺寸,某一类数据所占的比特数不同,对应能表示的数据范围也不同。对于有符号整型,C/C++标准并没有规定如何表示,但约定表示范围内正负数应该平衡,但实际以硬件为准。
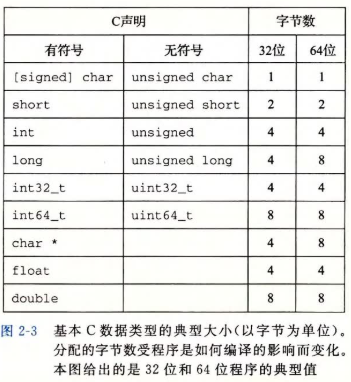
有些数据类型的确切字节数依赖与程序是如何编译的。C的数据类型“char”因存储单个字符而得名但是它也能存储整数值。一个char的空间应确保可以存放机器基本字符集中任意字符对应的数字值,即一个char的大小和一个机器字节一样。其他字符类型用于扩展字符集,如wchar_t、char16_t、char32_t。wchar_t类型用于确保可以存放机器最大扩展字符集中的任意一个字符,类型char16_t和char32_t则Unicode字符集服务。
short、int在不同位数的编译环境所占字节数是固定的,而long一般在32位程序中占4个字节,在64位程序中占8个字节。long long是C++11中新定义的,C++规定其大小至少和一个long一样大。同样,一个int至少和一个short一样大,一个long至少和一个int一样大。数据类型int32_t和int64_t是ISO C99在文件<stdint.h>中引入的一类数据类型,其数据大小固定,不随编译器和机器设置而变化,分别占4个字节和8个字节。intN_t和uintN_t对不同N值指定N位有符号和无符号整数,N的具体值与实现相关。使用确定大小的整数类型是程序员准确控制数据表示的最佳途径。指针占一个全字长度。
size_t 是一个在 C/C++ 标准库中定义的数据类型,主要用于计数,通常在 stddef.h 头文件中找到。它是一个与平台相关的无符号整数类型,用于表示任何对象的最大可能大小。在 32 位系统中,size_t 通常定义为 unsigned int,而在 64 位系统中定义为 unsigned long。
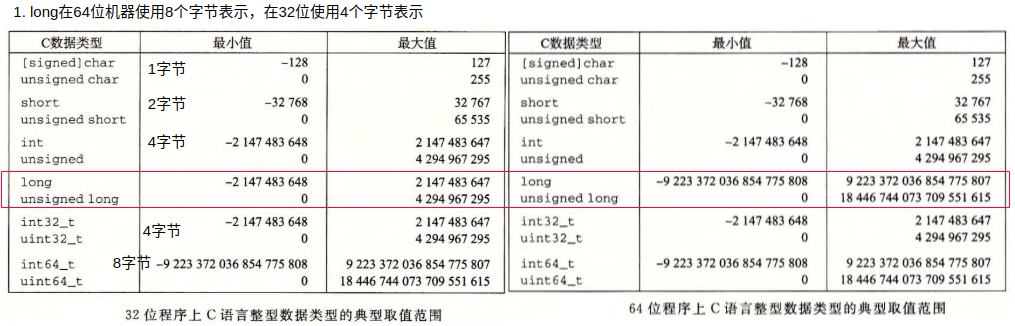
实际上C语言标准只指定了每种数据类型的最小范围,而不是确定的范围。在C库文件<limits.h>中定义了一组常量,来限定编译器运行的这台机器的不同整型数据类型的取值范围。常量(宏)INT_MAX、INT_MIN和UINT_MAX,描述了有符号和无符号整数的范围。
除去布尔型和扩展的字符型之外,其他整型可以划分为带符号signed和无符号unsigned两种。无符号只能代表大于0的数,带符号的正负都可以代表。int、short、long、long long都是带符号的,给前面加unsigned就是无符号。与其他整型不同,字符型分为char、signed char和unsigned char,具体用那个由编译器决定。
在C语言中做数据类型转化,一般是隐式转换是低精度向高精度转换,通过高位补0实现;对于低精度转高精度通过截断实现,会有精度丢失或这错误。对于有符号和无符号转化,数据不变,解释方式改变了。如果给无符号数赋值超出其表示范围,结果取所赋值取模后的余数。当给带符号的数赋超出范围的值,结果是未定义。当带符号数与无符号数运算时,带符号数会自动转化为无符号数。由于无符号数必须大于0,所以无符号与带符号的运算一定要小心。两个无符号数相减或者无符号加负数时,最终负数会向无符号转化,需要取模得余。
2.2 量化中涉及的不同精度的数据表示
参数所占内存大小等于表示数据的位宽(64/32/16/8/4)除以字节长度8再乘以参数数量。
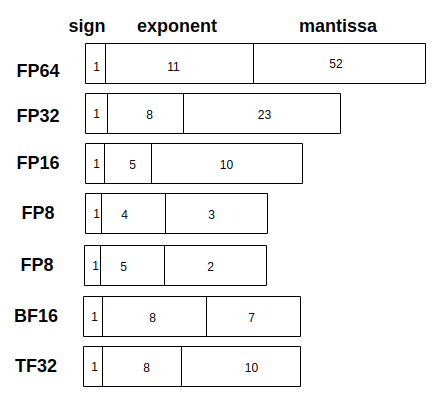
量化通过映射函数将高位宽的数据映射到低位宽的数据表示中,实际操作中无需对整个数据范围做映射,比如无需将完成的FP32的范围映射到INT8,只需要将参数实际范围映射到INT8即可。量化数据按照类型分为整数和浮点数,每个都有不同的位宽特例。对于INT类型,INT64占8个字节,INT32占4个字节,INT占4个字节,INT8占1个字节8位(一个符号为,七个树值位),INT4占4个位宽(一个符号位和三个数值位),也可以表示无符号整数。对于浮点数,由符号位S,占一位,阶码E和尾数M表示,其中阶码控制的是表示范围,尾数影响的是数的精度。深度学习看重浮点数的表示范围,不看重有效数字。量化中各个浮点数变体就是在改变E和M的长度来权衡计算性能、存储利用率和准确率。
FP32是按照IEEE754表示的单精度浮点数,深度学习训练常用的类型。FP16是精度截断,范围缩小,但是计算效率高于FP32。FP8是各个厂家还在研究的数据,没有官方标准,Nvidia支持的分为E4M3和E5M2。TF32(Tensor-float)是19位长度的浮点数,E长8位,M长10位,是英伟大设计用于替代FP32的数据类型,其精度与FP16一致,表示范围与FP32一致。FP32转TF32只需截断尾数部分即可。BF16(Brain-float)是google brain设计的,长度与FP16一致但表示范围与FP32相同。
参考
- 王道计算机组成原理
- 深入理解计算机系统,兰德尔E.布莱恩特
- C++ Primer 第五版
- https://zhuanlan.zhihu.com/p/673708074