快速掌握向量数据库-Milvus探索2_集成Embedding模型
一、前言
向量数据库的核心能力在于存储和检索非结构数据,如文本、图像、音频。多用于RAG(检索增强生成)、推荐系统、多媒体检索等应用场景。
bge-large-zh模型是专为中文文本设计的,同尺寸模型中性能优异的开源Embedding模型,凭借其中文优化、高效检索、长文本支持和低资源消耗等特性,成为中文Embedding领域的标杆模型。
本篇要实现的目标:通过bge-large-zh向量模型生成写作内容的embedding向量(1024维度),并将结果存储在Milvus向量数据库中,然后对文本内容进行向量的相似性查询。
本专栏最终要实现的架构为:
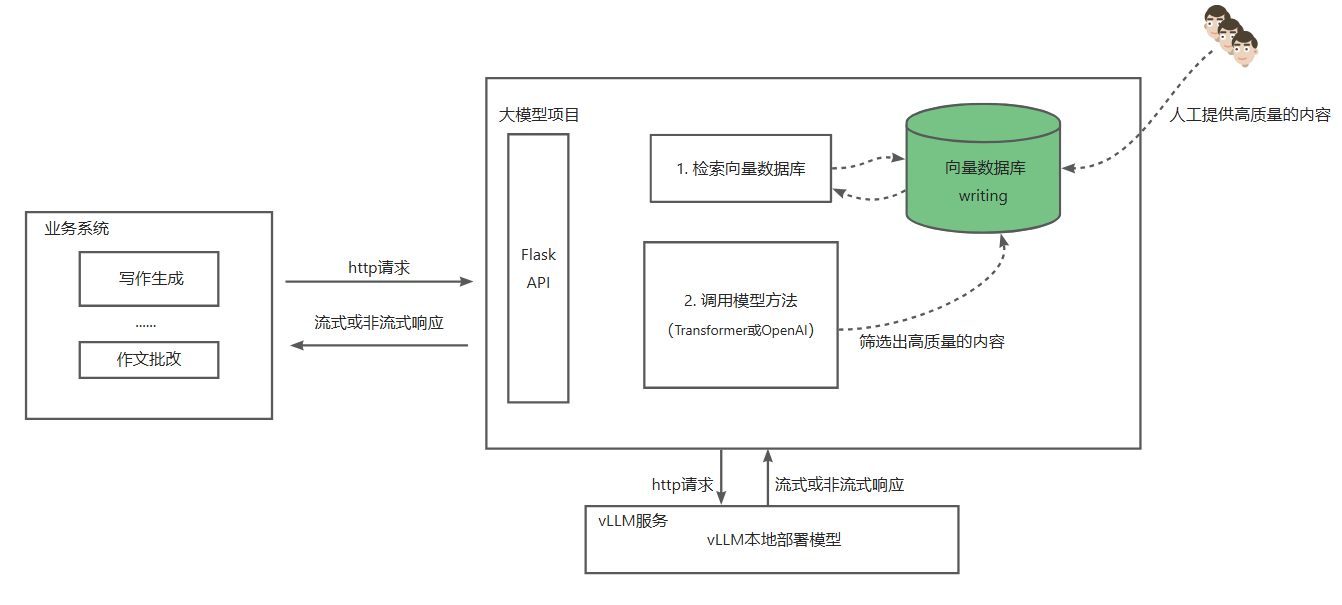
上一篇文章(Milvus环境搭建和基础开发):
快速掌握向量数据库-Milvus探索1-CSDN博客
二、术语
2.1 向量
在AI领域,向量特指向量嵌入 (Vector Embeddings),即通过机器学习模型将非结构化数据(如文本、图像、音频等)转换为高维数值向量,以捕捉其语义或特征信息。 非结构化数据通过向量化,除了具备语义捕捉能力、还能借助向量数据库专门的索引技术(如近似最近邻搜索)快速处理海量非结构化数据的相似性查询,这是传统数据库难以实现的。
2.2 Milvus
Milvus是一个专为处理高维向量数据设计的开源向量数据库,支持数百亿级数据规模,在多数开源向量数据库中综合表现突出(一般是其他的2~5倍)。
提供三种部署方式:本地调试Milvus Lite、企业级小规模数据的Milvus Standalone(一亿以内向量)、企业级大规模数据的Milvus Distributed (数百亿向量)。
2.3 ModelScope
阿里巴巴达摩院推出的开源模型服务平台,提供开源模型下载、CPU和GPU限时免费资源,我们将基于该平台部署大语言模型进行推理。
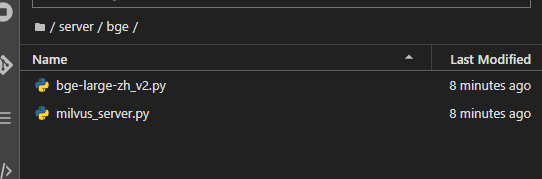
三、代码
代码文件包括milvus_server.py、bge-large-zh_v2.py
3.1bge-large-zh生成embedding向量
通过modelScope提供的免费GPU服务,将bge-large-zh下载到GPU服务器中。
下载命令: modelscope download --model AI-ModelScope/bge-large-zh --local_dir ./
细节参考往期博客模型部署部分:快速掌握大语言模型-Qwen2-7B-Instruct落地1-CSDN博客
def get_embedding_list(text_list):"""输入文本列表,返回文本的embedding向量:param text_list: 待获取embedding的文本集合:return: ebedding向量集合"""# 编码输入(自动截断和填充)encoded_input = tokenizer(text_list, padding=True, truncation=True, return_tensors='pt')# 调用大模型得到文本的embeddingwith torch.no_grad():model_output = model(**encoded_input)sentence_embeddings = model_output[0][:, 0] # bdge-large-zh 模型的输出是一个元组,第一个元素是句子的嵌入向量,1024维print(f"sentence_embeddings:{ len(sentence_embeddings[0])}")# 归一化处理:可以提高模型的稳定性和收敛速度,尤其在处理向量相似度计算时非常有用sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)# 转换嵌入向量为列表embeddings_list = sentence_embeddings.tolist()return embeddings_list3.2 获取写作内容向量并保存到Milvus中
def insert_writing_embeddings(text_list):"""获取写作生成内容的文本的embedding向量,并写入到milvus中:param text_list: 待获取embedding的写作生成内容集合:return: 写入到到milvus结果,ebedding向量集合"""# 获取embedding embeddings_list = get_embedding_list(text_list)print(f"embeddings_list:{len(embeddings_list)}")# 写作记录合集writing_list = []for i, embedding in enumerate(embeddings_list):writingDTO = WritingDTO(embedding, text_list[i], random.randint(500,9999)) #组装对象数据,其中biz_id是业务ID,这里这里方便说明暂设为随机数字writing_list.append(writingDTO.to_dict()) # 将对象转换为字典,并添加到集合中# 插入数据到 Milvusres = insert_data_to_milvus(writing_collection_name,writing_list)return res,embeddings_list
写入结果:


3.3 根据写作内容进行向量的相似性搜索
def search_writing_embeddings(text):"""获取写作内容的embedding向量,并从milvus中搜索"""# 获取embeddingembeddings_list = get_embedding_list([text])# 搜索数据res = search_data_from_milvus(writing_collection_name,embeddings_list,3)return res
搜索结果:

3.4 milvus_server完整代码
from pymilvus import MilvusClient, db
import numpy as np
from pymilvus.orm import collection
from typing import Iterable# 定义 Milvus 服务的主机地址
host = "阿里云公网IP"# 创建一个 Milvus 客户端实例,连接到指定的 Milvus 服务
client = MilvusClient(uri=f"http://{host}:19530",db_name="db001") # 连接到 Milvus 服务并选择数据库 "db001"
# collection_name = "writing" # 指定要连接的集合名称 "writing"# 写作生成对象
class WritingDTO:def __init__(self, content_vector, content_full, biz_id):self.content_vector = content_vectorself.content_full = content_fullself.biz_id = biz_iddef to_dict(self):"""将 WritingDTO 对象转换为字典。:return: 包含 WritingDTO 对象属性的字典"""return {"content_vector": self.content_vector,"content_full": self.content_full,"biz_id": self.biz_id}def insert_data_to_milvus(collection_name,data):"""将对象集合中的数据插入到 Milvus 集合中。:param data: 字典对象集合:return: 插入操作的结果"""print(f"insert_data_to_milvus:{collection_name}")print(f"insert_data_to_milvus:{len(data)}")res = client.insert(collection_name=collection_name,data=data)return resdef search_data_from_milvus(collection_name,query_vector,output_fields, top_k=10):"""从 Milvus 集合中搜索与查询向量最相似的向量。:param query_vector: 查询向量:param top_k: 返回的最相似向量的数量:return: 搜索结果"""res = client.search(collection_name= collection_name, # 合集名称data=query_vector, # 查询向量search_params={"metric_type": "COSINE", # 向量相似性度量方式,COSINE 表示余弦相似度(适用于文本/语义相似性场景); 可选 IP/COSINE/L2 "params": {"level":1}, }, # 搜索参数limit=top_k, # 查询结果数量output_fields= output_fields, # 查询结果需要返回的字段consistency_level="Bounded" # 数据一致性级别,Bounded允许在有限时间窗口内读取旧数据,相比强一致性(STRONG)提升 20 倍查询性能,适合高吞吐场景; )return res3.5 bge-large-zh_v2.py完整代码
from re import search
from transformers import AutoTokenizer, AutoModel
import torch
import random
from milvus_server import WritingDTO, insert_data_to_milvus,search_data_from_milvus# 加载模型和分词器
model_path = "/mnt/workspace/models/bge-large-zh" # 根据实际情况修改
model = AutoModel.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 推理模式
model.eval() # 写作生成合集名称
writing_collection_name = "writing"def get_embedding_list(text_list):"""输入文本列表,返回文本的embedding向量:param text_list: 待获取embedding的文本集合:return: ebedding向量集合"""# 编码输入(自动截断和填充)encoded_input = tokenizer(text_list, padding=True, truncation=True, return_tensors='pt')# 调用大模型得到文本的embeddingwith torch.no_grad():model_output = model(**encoded_input)sentence_embeddings = model_output[0][:, 0] # bdge-large-zh 模型的输出是一个元组,第一个元素是句子的嵌入向量,1024维print(f"sentence_embeddings:{ len(sentence_embeddings[0])}")# 归一化处理:可以提高模型的稳定性和收敛速度,尤其在处理向量相似度计算时非常有用sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)# 转换嵌入向量为列表embeddings_list = sentence_embeddings.tolist()return embeddings_listdef insert_writing_embeddings(text_list):"""获取写作生成内容的文本的embedding向量,并写入到milvus中:param text_list: 待获取embedding的写作生成内容集合:return: 写入到到milvus结果,ebedding向量集合"""# 获取embedding embeddings_list = get_embedding_list(text_list)print(f"embeddings_list:{len(embeddings_list)}")# 写作记录合集writing_list = []for i, embedding in enumerate(embeddings_list):writingDTO = WritingDTO(embedding, text_list[i], random.randint(500,9999)) #组装对象数据,其中biz_id是业务ID,这里这里方便说明暂设为随机数字writing_list.append(writingDTO.to_dict()) # 将对象转换为字典,并添加到集合中# 插入数据到 Milvusres = insert_data_to_milvus(writing_collection_name,writing_list)return res,embeddings_listdef search_writing_embeddings(text):"""获取写作内容的embedding向量,并从milvus中搜索"""# 获取embeddingembeddings_list = get_embedding_list([text])# 搜索数据res = search_data_from_milvus(writing_collection_name,embeddings_list,["id","content_full","biz_id"],3)return res# if __name__ == "__main__":
# # 输入文本
# sentences = ["广州好玩的地方有广州塔,长隆野生动物世界,沙面岛......","广州好吃的有经典粤菜菜,传统的美食,还有各种美食的店......"]
# # 将文本转eembedding向量并写入到milvus中
# res = insert_writing_embeddings(sentences)
# print("Insert result:", len(res[0]))
# print("Sentence embeddings:", len(res[1]))if __name__ == "__main__":# 输入文本content = "推荐广州有哪些好玩的地方"# 将文本转eembedding向量并写入到milvus中res = search_writing_embeddings(content)print("Search result:", res)