Dia-1.6B 在 Windows 系统下的成功部署及多人情景对话克隆实践
在人工智能语音技术蓬勃发展的当下,Nari Labs 精心研发的 Dia-1.6B 模型脱颖而出,迅速成为行业焦点。该模型具备极为卓越的超逼真对话生成能力,自开源于 GitHub 平台以来,热度一路飙升,短短几天便收获了超过 13K 的 Star,吸引了众多开发者与技术爱好者的目光,在业界引发了广泛讨论。
Dia-1.6B 生成的音频对话,在语音质量上堪称出色,不仅如此,其对情绪与语速的把控达到了惊人的精准度。这种高度拟真的特性,让它在影视配音等领域展现出巨大的应用潜力,为相关行业开拓了全新的发展思路与可能性。
项目的 GitHub 开源地址为:
nari-labs/dia:一种能够一次性生成超逼真对话的 TTS 模型。
依照项目官方 README.MD 文档中的部署步骤操作,理论上能够顺利完成部署流程。
但在实际的 Windows 系统部署过程中,许多用户遭遇了一些难题,其中尤以 torch 相关问题最为棘手。
接下来,本文将详细梳理成功部署后的复盘步骤,为大家提供具有价值的参考。

一、Python 版本选择
经过实际验证,Dia-1.6B 项目可稳定支持至 Python 3.12 版本。而 Python 3.13 版本由于尚未经过充分测试,其与项目的兼容性暂不明确。
因此,在着手项目部署时,建议优先选用 Python 3.9~3.12 版本,以保障部署过程的稳定性与流畅性。

二、Windows 部署详细步骤
(一)步骤总览
git clone https://github.com/nari-labs/dia.git
cd dia
python -m venv .venv
source .venv/bin/activate
python -m pip install --upgrade pip setuptools wheel
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu126
pip install -e . -i https://mirrors.aliyun.com/pypi/simple/
python app.py
(二)步骤拆分详解
1、克隆项目源代码
执行git clone https://github.com/nari-labs/dia.git命令,该操作会从 GitHub 仓库中将 Dia-1.6B 项目的源代码完整克隆至本地,为后续的部署工作奠定坚实的基础。
git clone https://github.com/nari-labs/dia.git2、进入项目目录
运行cd dia命令,进入已克隆好的项目目录。只有在此目录下,后续的一系列部署操作才能准确无误地执行,确保所有命令都在项目的正确环境中运行。
cd dia
3、新建本地虚拟环境
使用python -m venv .venv命令,创建一个名为.venv的本地虚拟环境。虚拟环境能够为项目提供独立的 Python 运行空间,有效规避不同项目之间的依赖冲突,为项目的部署与稳定运行提供有力保障。
python -m venv .venv
4、激活虚拟环境
通过source .venv/bin/activate命令激活刚刚创建的虚拟环境。激活后,后续安装的所有 Python 包都将被安装至该虚拟环境中,与系统环境实现有效隔离。
source .venv/bin/activate
5、升级包管理和构建工具
执行python -m pip install --upgrade pip setuptools wheel命令,对 pip、setuptools 和 wheel 等包管理与构建工具进行升级。这一步对于后续安装项目依赖包至关重要,能够确保使用最新的功能与修复的漏洞,大幅提升安装的成功率与稳定性。
python -m pip install --upgrade pip setuptools wheel
6、安装 torch
安装
在部署过程中,当执行到pip install -e.这一步时,系统报错提示存在包冲突问题。
经过仔细查看报错信息,发现项目运行所需的torch版本为torch==2.6.0 ,然而直接使用pip install -e.命令进行安装,可能由于各个依赖安装顺序的原因,自动安装完成后会出现一些包冲突的报错信息。
鉴于项目对 torch 版本有明确要求,在部署过程中需手动安装 torch。
首先,前往 PyTorch 官网,依据自己系统中安装的 CUDA 版本查找对应的安装命令。
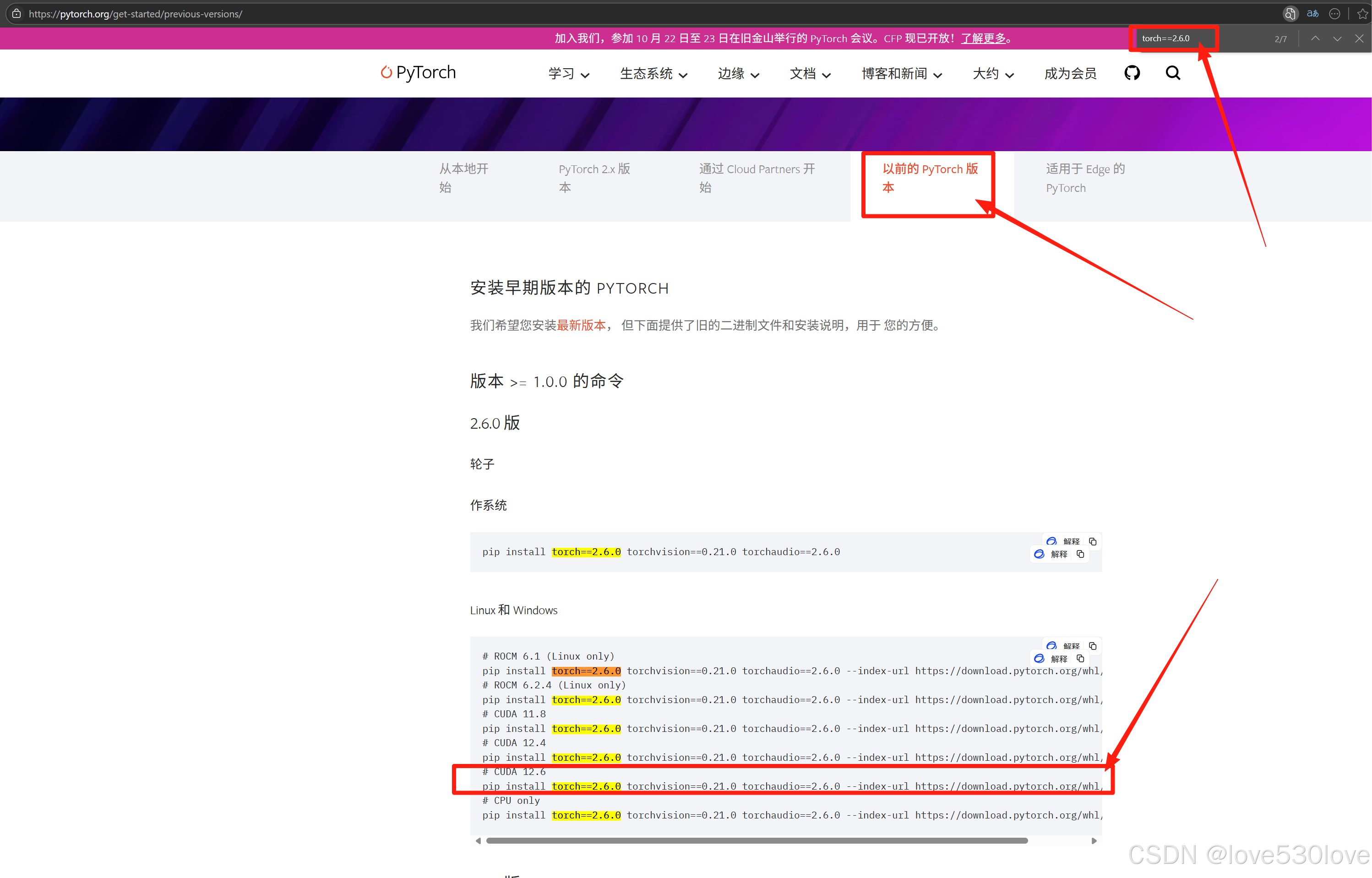
例如,若系统中安装的是 CUDA 12.8,那么选择安装≤CUDA 12.8 版本的 torch 均可,因为这些版本能够向下兼容虚拟环境中的 CUDA 版本。
以 CUDA 12.6 为例,安装命令为:
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu126验证
安装完成后,可通过以下代码验证 torch 的安装情况
import torch # 导入PyTorch库print("PyTorch版本:", torch.__version__) # 打印PyTorch的版本号# 检查CUDA是否可用,并设置设备("cuda:0"或"cpu")device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("设备:", device) # 打印当前使用的设备print("CUDA可用:", torch.cuda.is_available()) # 打印CUDA是否可用print("cuDNN已启用:", torch.backends.cudnn.enabled) # 打印cuDNN 是否已启用# 打印PyTorch支持的CUDA和cuDNN版本print("支持的CUDA版本:", torch.version.cuda)print("cuDNN版本:", torch.backends.cudnn.version())# 创建两个随机张量(默认在CPU上)x = torch.rand(5, 3)y = torch.rand(5, 3)# 将张量移动到指定设备(CPU或GPU)x = x.to(device)y = y.to(device)# 对张量进行逐元素相加z = x + y# 打印结果print("张量z的值:")print(z) # 输出张量z的内容验证PyTorch深度学习环境Torch和CUDA还有cuDNN是否正确配置的命令_验证pytorch和cuda的命令-CSDN博客
7、开始安装部署
执行pip install -e .或pip install -e . -i https://mirrors.aliyun.com/pypi/simple/
命令,完成项目的安装部署。
pip install -e .或:
pip install -e . -i https://mirrors.aliyun.com/pypi/simple/其中,-e选项表示以可编辑模式安装项目,便于后续对项目进行修改与调试;
-i https://mirrors.aliyun.com/pypi/simple /选项则指定从阿里云的 PyPI 镜像源安装包,可显著加快下载速度。
若前面的步骤均正确执行,这一步通常能够顺利完成安装。
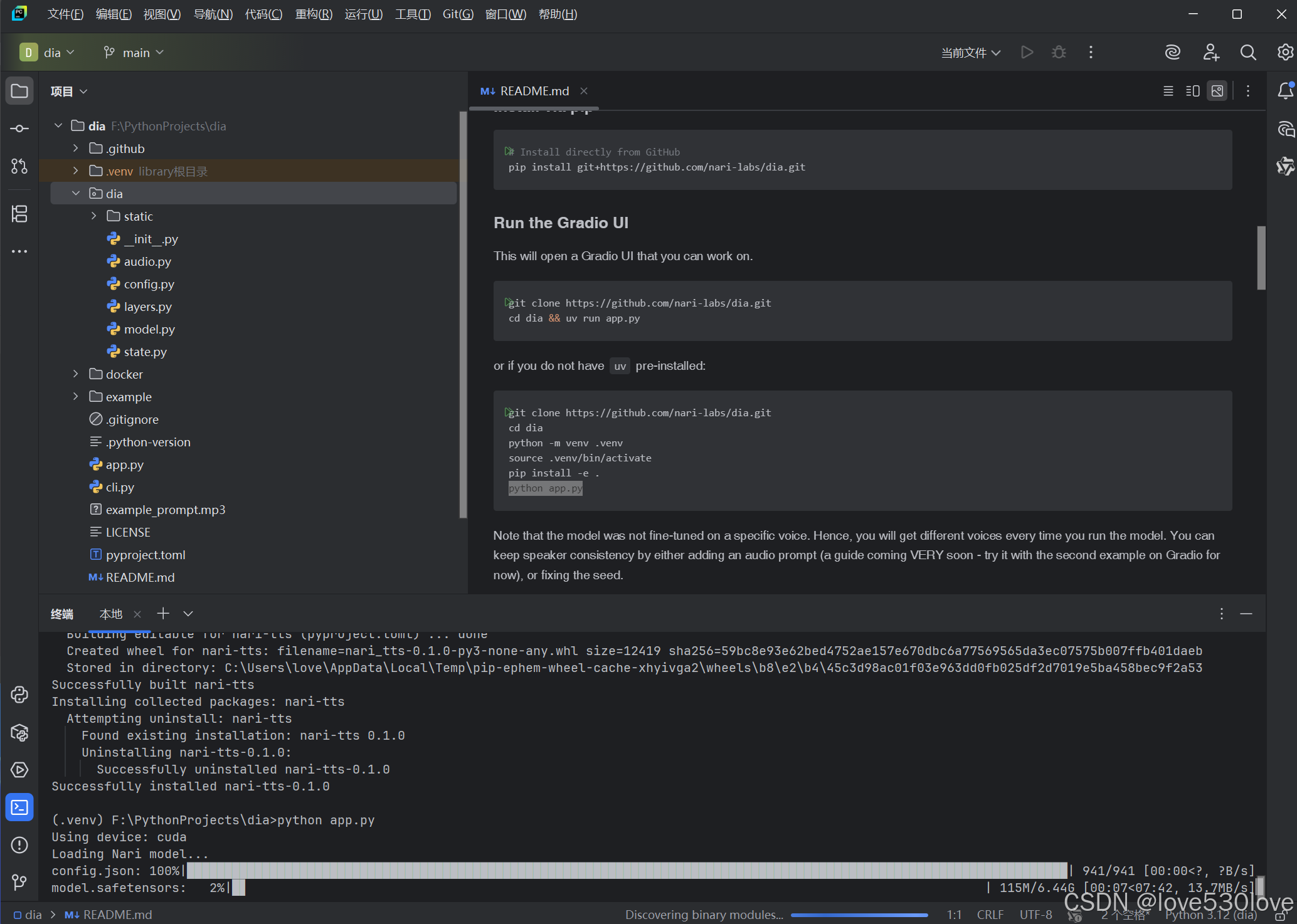
8、运行项目
使用python app.py命令运行项目。在首次运行时,程序会自动下载一些必要的模型文件。待下载完成并出现链接后,点击该链接即可在浏览器中打开项目界面。
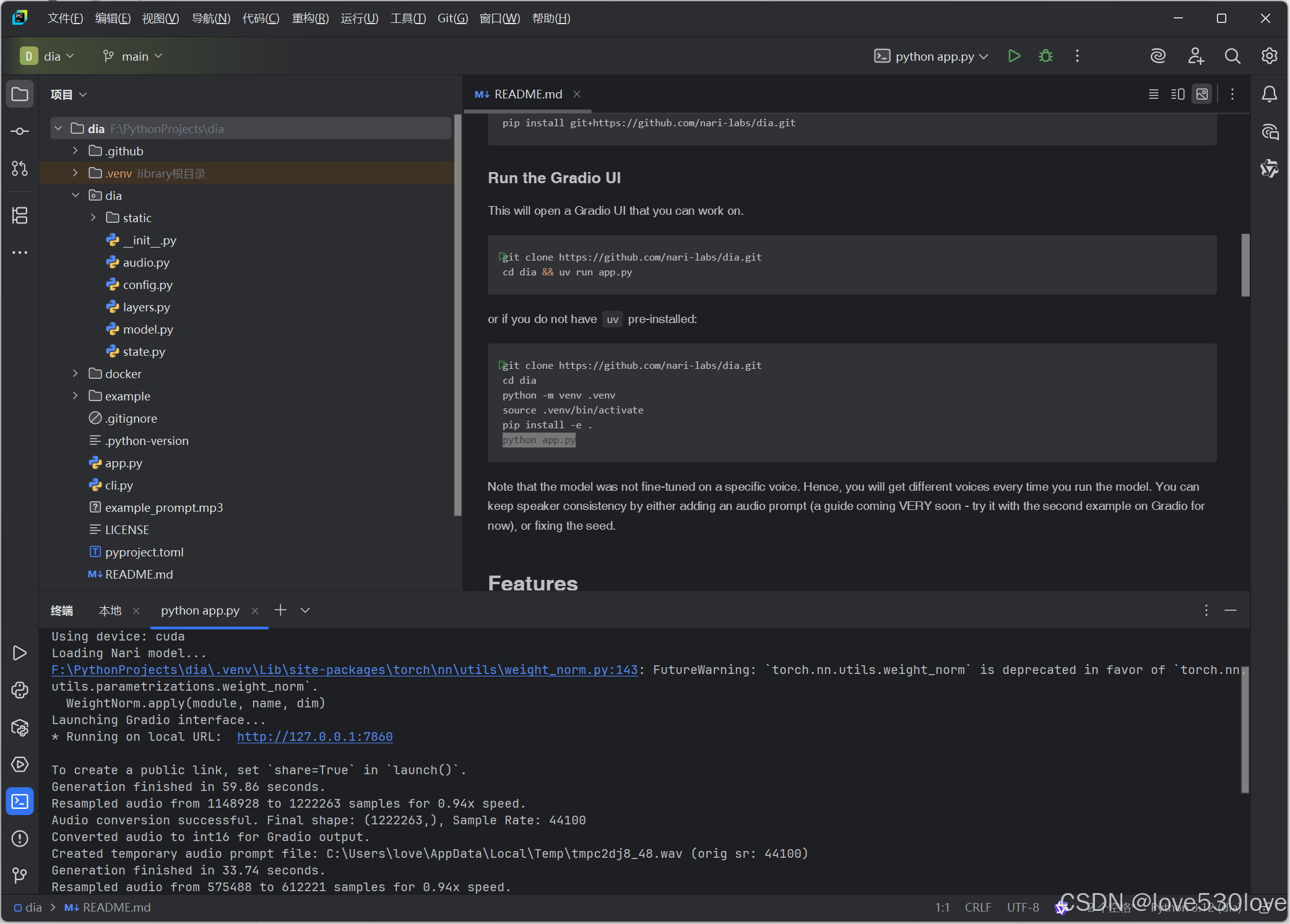
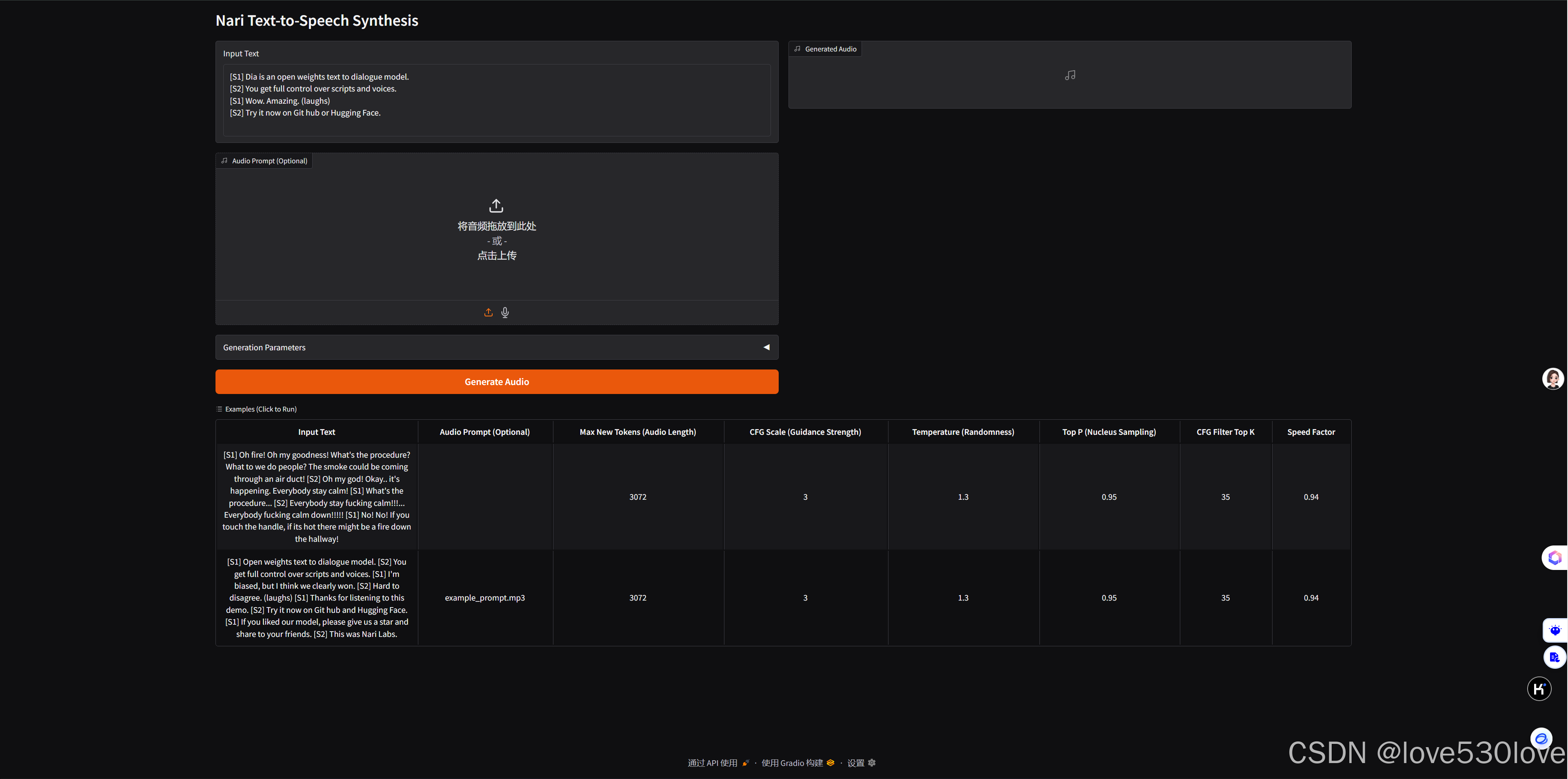
三、测试运行状态
测试一
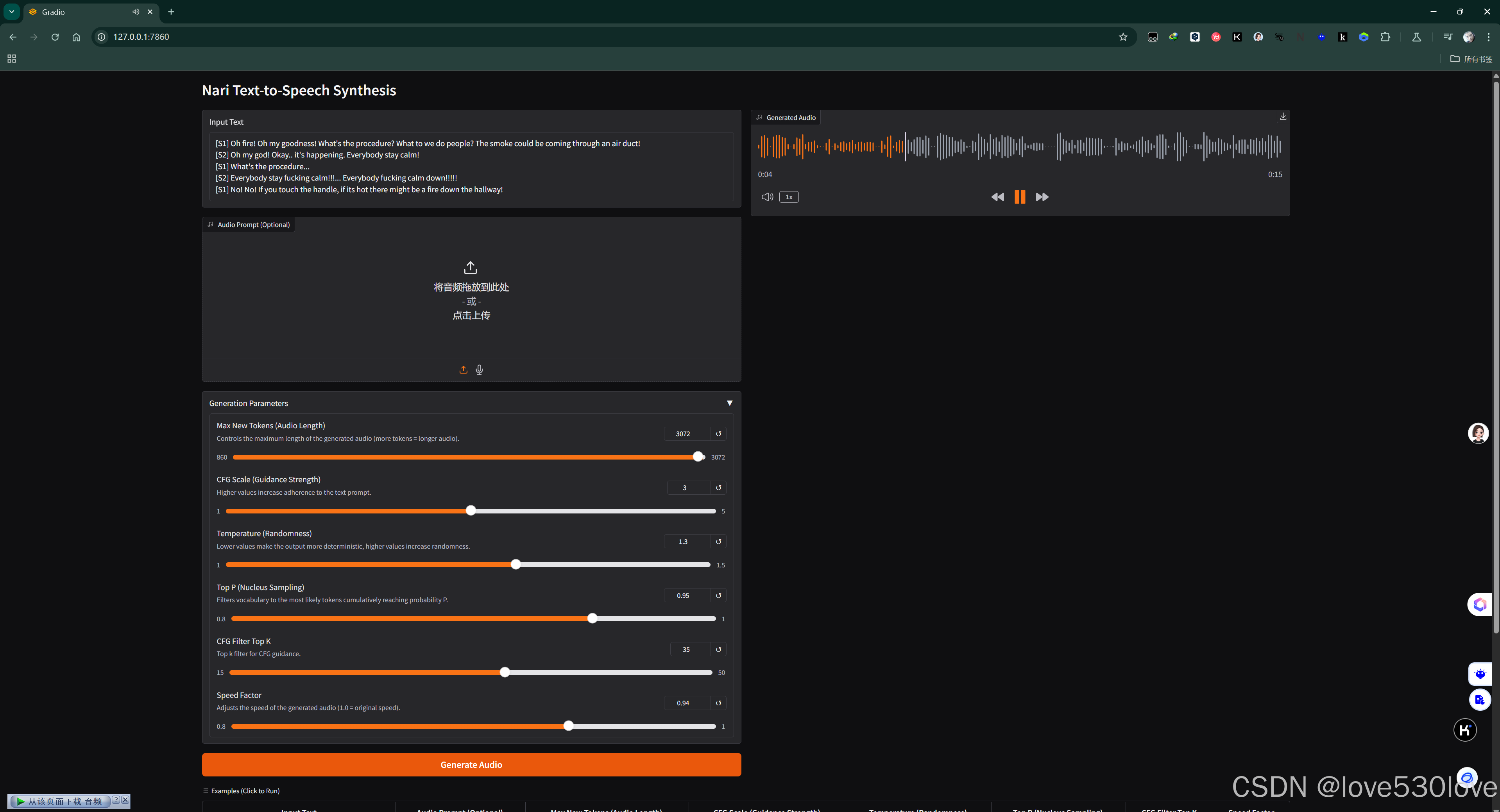
自带的多人情景对话生成:
在项目浏览器界面中,点击下方第一行英文对话示例,随后点击 “Generate Audio” 按钮,即可对项目自带音色的情景对话生成功能进行测试,以此检验项目是否能够正常生成对话音频。
测试二
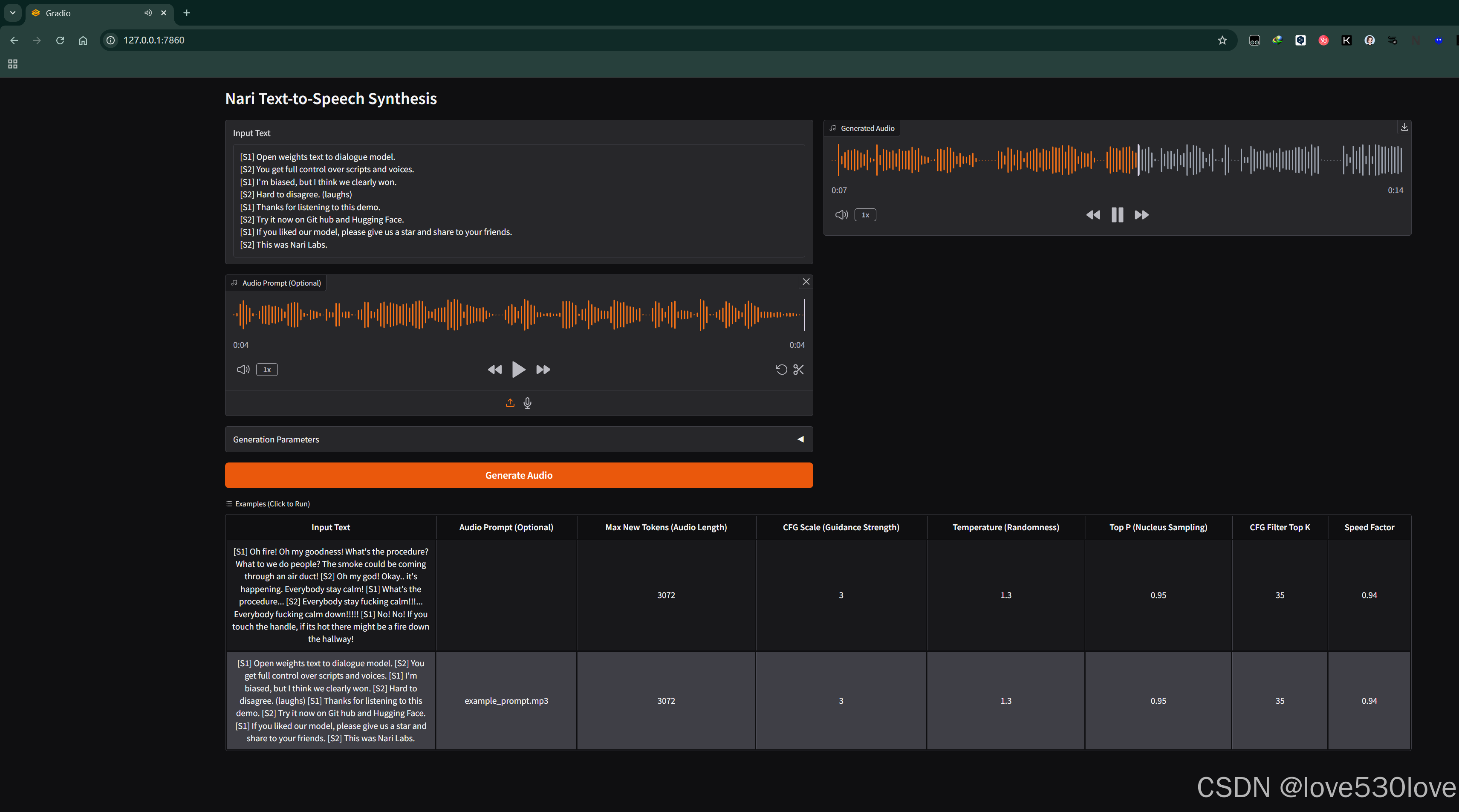
克隆多人对话音色的声纹生成:
上传项目目录中的示例音频 “example_prompt.mp3”(该音频时长 4s,包含 2 人音色),接着点击第二行的英文示例,最后点击 “Generate Audio” 按钮,通过此操作测试对话音色的克隆功能,查看项目是否能够精准克隆音频中的音色。
总结
请项目官方 README.MD 文档,包括项目的免责声明