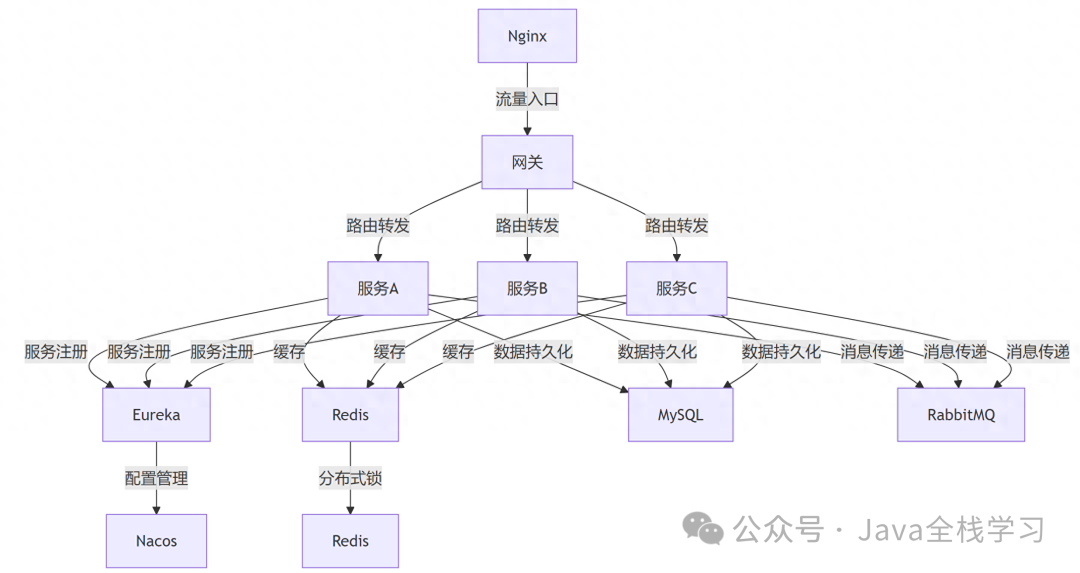
我自己的原文哦~ https://blog.51cto.com/whaosoft/11536996
#Arc2Face
身份条件化的人脸生成基础模型,高一致性高质量的AI人脸艺术风格照生成
将人脸特征映射到SD的CLIP的编码空间,通过微调SD实现文本编码器转换为专门为将ArcFace嵌入投影到CLIP潜在空间而定制的人脸编码器
文章地址: https://arxiv.org/abs/2403.11641
项目地址: https://github.com/foivospar/Arc2Face
01 导言
今天分享一个人脸合成基础模型,主要是考虑到未来可能需要合成人脸数据或者基于此做高质量一致性的人脸生成,先Mark。
Arc2Face是一种身份条件化人脸基础模型,给定一个人的 ArcFace 嵌入,该模型可以生成多样化的照片般逼真的图像,其人脸相似度远超现有模型(比如FaceSwap、InstantID等)。
Arc2Face 以预训练的稳定扩散模型为基础,仅以 ID 向量为条件,使其适应 ID 到人脸生成的任务。训练数据上精心上采样了 WebFace42M (最大的人脸识别 (FR) 公共数据集)数据库的很大一部分,该数据集具有一致的身份和源自WebFace42M的类内变异性,然后基于此微调SD,并使用了FFHQ和CelebA-HQ微调以提高质量。
相比于最近将 ID 与文本嵌入相结合以实现文本到图像模型的零样本个性化的方法,Arc2Face强调 FR 特征的紧凑性,它可以充分捕捉人脸的本质,而不是手工制作的文本提示。
另一方面,文本增强模型很难将身份与文本区分开来,通常需要对给定的人脸进行某种描述才能实现令人满意的相似度。然而,Arc2Face 只需要 ArcFace 的判别特征来指导生成,为大量 ID 一致性至关重要的任务提供了强大的先验。例如,在Arc2Face 模型中的合成图像上训练 FR 模型,实现了优于现有合成数据集的性能。
亮点:
将人脸特征映射到SD的CLIP的编码空间,通过微调SD实现文本编码器转换为专门为将ArcFace嵌入投影到CLIP潜在空间而定制的人脸编码器
02 方法

图2 Arc2Face模型框架
Arc2Face框架如上,使用一个简单的设计来条件ID特征上的稳定扩散。预训练的SD作为模型的先验,ArcFace嵌入由使用冻结伪提示符的文本编码器进行处理,投影到CLIP潜在空间以进行交叉注意控制。编码器和UNet都在百万尺度FR数据集上进行了优化在上采样之后),然后在高质量数据集上进行了额外的微调,没有任何文本注释。模型生成完全遵循id嵌入,忽略了文本Promt指导。
2.1 身份条件控制
先验模型使用stable-diffusion-v1-5,它使用CLIP文本编码器来指导图像合成。本文人脸合成的目标是在ArcFace嵌入条件下,同时直接利用其UNet的生成能力。因此,有必要将ArcFace嵌入投影到原始模型使用的CLIP嵌入的空间中。作者通过将它们输入到相同的编码器中并对其进行微调以迅速适应ArcFace输入来实现这一点
该方法提供了比用MLP代替CLIP更无缝的投影。为了确保与CLIP的兼容性,使用了一个简单的提示,“一个<id>人的照片”。
在标记化之后, 将占位符标记嵌入替换为 ArcFace 向量 , 生成一系列标记嵌入 。在这里, 为匹配 的维度, 是 经过零填充后得到的, 生成的序列被馈送到编码器 , 该编码器将其映射到 CLIP输出空间 (其中 表示标记器的最大句子长度), 如图2所示。ID信息在7的输出中的多个嵌入中共享, 为UNet提供了更详细的指导。在训练期间, 始终对所有图像使用这个默认的伪提示符。这种有意的选择将编码器的注意力完全集中在ID向量上, 而忽略了任何无关的上下文信息。因此,通过广泛的微调, 可以有效地将文本编码器转换为专门为将ArcFace嵌入投影到CLIP潜在空间而定制的人脸编码器。
2.2 数据集
使用了WebFace42M,因为它的巨大尺寸和类内可变性,然而,它受到低分辨率数据和紧面部裁剪的影响。更重要的是,预训练的SD主干是为512×512的分辨率而设计的,并且需要类似的分辨率来微调Arc2Face。为了缓解这种情况,使用GFPGAN (v1.4)对它们进行了精心的上采样,执行降解去除和4倍放大到448 × 448。考虑到计算限制,在原始数据库的很大一部分上遵循这个过程,以448 × 448像素获取1M身份的大约21M张图像,使用恢复后的图像训练Arc2Face。
尽管该数据集的质量更高,但用于FR训练的数据集仍然局限于严格裁剪的面部区域。虽然它允许预先学习一个鲁棒的ID,但通常更喜欢完整的人脸图像。因此,在FFHQ和CelebA-HQ上进一步微调,它们由较少约束的面部图像组成。最终模型生成了512 × 512像素的与ffhq对齐的图像。
03 实验结果
- 定量比较

- 可视化比较

- 不同合成方法的FR模型准确率比较

#BlazeBVD
盲视频去闪烁通用方法BlazeBVD来了,美图&国科大联合提出
近年,短视频生态的赛道迅猛崛起,围绕短视频而生的创作编辑工具在不断涌现,美图公司旗下专业手机视频编辑工具 ——Wink,凭借独创的视频画质修复能力独占鳌头,海内外用户量持续攀升。
Wink 画质修复功能火爆的背后,是美图在视频编辑应用需求加速释放背景下,对用户视频画面模糊不清、噪点严重、画质低等视频创作痛点的洞察,与此同时,也建立在美图影像研究院(MT Lab)强有力的视频修复与视频增强技术支持下,目前已推出画质修复 - 高清、画质修复 - 超清、画质修复 - 人像增强、分辨率提升等功能。
日前,美图影像研究院(MT Lab)联合中国科学院大学更突破性地提出了基于 STE 的盲视频去闪烁 (blind video deflickering, BVD) 新方法 BlazeBVD,用于处理光照闪烁退化未知的低质量视频,尽可能保持原视频内容和色彩的完整性,已被计算机视觉顶会 ECCV 2024 接收。
- 论文链接:https://arxiv.org/pdf/2403.06243v1
BlazeBVD 针对的是视频闪烁场景,视频闪烁容易对时间一致性造成影响,而时间一致性是高质量视频输出的必要条件,即使是微弱的视频闪烁也有可能严重影响观看体验。究其原因,一般是由拍摄环境不佳和拍摄设备的硬件限制所引起,而当图像处理技术应用于视频帧时,这个问题往往进一步加剧。此外,闪烁伪影和色彩失真问题在最近的视频生成任务中也经常出现,包括基于生成对抗网络 (GAN) 和扩散模型 (DM) 的任务。因此在各种视频处理场景中,探索通过 Blind Video Deflickering (BVD) 来消除视频闪烁并保持视频内容的完整性至关重要。
BVD 任务不受视频闪烁原因和闪烁程度的影响,具有广泛的应用前景,目前对此类任务的关注,主要包括老电影修复、高速相机拍摄、色彩失真处理等与视频闪烁类型、闪烁程度无关的任务,以及仅需在单个闪烁视频上操作,而不需要视频闪烁类型、参考视频输入等额外指导信息的任务。此外,BVD 现主要集中在传统滤波、强制时序一致性和地图集等方法,所以尽管深度学习方法在 BVD 任务中取得了重大进展,但由于缺乏先验知识,在应用层面上受到较大阻碍,BVD 仍然面临诸多挑战。
BlazeBVD: 有效提高盲视频去闪烁效果
受经典的闪烁去除方法尺度时间均衡 (scale-time equalization, STE) 的启发,BlazeBVD 引入了直方图辅助解决方案。图像直方图被定义为像素值的分布,它被广泛应用于图像处理,以调整图像的亮度或对比度,给定任意视频,STE 可以通过使用高斯滤波平滑直方图,并使用直方图均衡化校正每帧中的像素值,从而提高视频的视觉稳定性。虽然 STE 只对一些轻微的闪烁有效,但它验证了:
- 直方图比像素值紧凑得多,可以很好地描绘光亮和闪烁信息。
- 直方图序列平滑后的视频在视觉上没有明显的闪烁。
因此,利用 STE 和直方图的提示来提高盲视频去闪烁的质量和速度是可行的。
BlazeBVD 通过对这些直方图进行平滑处理,生成奇异帧集合、滤波光照图和曝光掩码图,可以在光照波动和曝光过度或不足的情况下实现快速、稳定的纹理恢复。与以往的深度学习方法相比,BlazeBVD 首次细致地利用直方图来降低 BVD 任务的学习复杂度,简化了学习视频数据的复杂性和资源消耗,其核心是利用 STE 的闪烁先验,包括用于指导消除全局闪烁的滤波照明图、用于识别闪烁帧索引的奇异帧集,以及用于识别局部受过曝或过暗影响的区域的曝光图。
与此同时,利用闪烁先验,BlazeBVD 结合了一个全局闪烁去除模块 (GFRM) 和一个局部闪烁去除模块 (LFRM),有效地矫正了个别相邻帧的全局照明和局部曝光纹理。此外,为了增强帧间的一致性,还集成了一个轻量级的时序网络 (TCM),在不消耗大量时间的情况下提高了性能。

图 1:BlazeBVD 方法与已有方法在盲视频去闪烁任务上的结果对比
具体而言,BlazeBVD 包括三个阶段:
- 首先,引入 STE 对视频帧在光照空间下的直方图序列进行校正,提取包括奇异帧集、滤波后的光照图和曝光图在内的闪烁先验。
- 其次,由于滤波后的照明映射具有稳定的时间性能,它们将被用作包含 2D 网络的全局闪烁去除模块 (GFRM) 的提示条件,以指导视频帧的颜色校正。另一方面,局部闪烁去除模块 (LFRM) 基于光流信息来恢复局部曝光图标记的过曝或过暗区域。
- 最后,引入一个轻量级的时序网络 (TCM) 来处理所有帧,其中设计了一个自适应掩模加权损失来提高视频一致性。
通过对合成视频、真实视频和生成视频的综合实验,展示了 BlazeBVD 优越的定性和定量结果,实现了比最先进的模型推理速度快 10 倍的模型推理速度。

图 2:BlazeBVD 的训练和推理流程
实验结果
大量的实验表明,盲视频闪烁任务的通用方法 ——BlazeBVD,在合成数据集和真实数据集上优于先前的工作,并且消融实验也验证了 BlazeBVD 所设计模块的有效性。

表 1:与基线方法的量化对比

图 3:与基线方法的可视化对比

图 4:消融实验
以影像科技助力生产力
该论文提出了一种用于盲视频闪烁任务的通用方法 BlazeBVD,利用 2D 网络修复受光照变化或局部曝光问题影响的低质量闪烁视频。其核心是在照明空间的 STE 滤波器内预处理闪烁先验;再利用这些先验,结合全局闪烁去除模块 (GFRM) 和局部闪烁去除模块 (LFRM),对全局闪烁和局部曝光纹理进行校正;最后,利用轻量级的时序网 (TCM) 提高视频的相干性和帧间一致性,此外在模型推理方面也实现了 10 倍的加速。
作为中国影像与设计领域的探索者,美图不断推出便捷高效的 AI 功能,为用户带来创新服务和体验,美图影像研究院(MT Lab)作为核心研发中枢,将持续迭代升级 AI 能力,为视频创作者提供全新的视频创作方式,打开更广阔的天地。
#Crowd-SAM
基于 SAM 框架,用于目标检测和分割,简化标注过程 !
本文提出了一种用于标注密集数据集的自我提示分割方法Crowd-SAM,只需几个示例即可产生精确和准确的结果。
在计算机视觉领域,目标检测是一项重要的任务,它在许多场景中都有应用。然而,特别是在拥挤的场景中,获取广泛的标签可能具有挑战性。
最近,提出了一种名为Segment Anything Model(SAM)的强大零样本分割器,为实例分割任务提供了一种新颖的方法。但是,在处理拥挤和遮挡场景中的物体时,SAM及其变体的准确性和效率往往受到影响。
在本文中,作者介绍了Crowd-SAM,这是一个基于SAM的框架,旨在通过少量可学习参数和最小量的标记图像,提升在拥挤和遮挡场景中的性能。作者引入了一个高效的提示采样器(EPS)和一个部分-整体判别网络(PWD-Net),以提高在拥挤场景中的 Mask 选择和准确性。
尽管Crowd-SAM的设计简单,但它与包括CrowdHuman和CityPersons在内的几个基准测试中的全监督目标检测方法的最新技术(SOTA)相媲美。作者的代码可在https://github.com/FelixCaae/CrowdSAM获取。
1
Introduction
在人群密集场景中的目标检测已成为计算机视觉领域的一项挑战性任务,广泛应用于交通管理、自动驾驶和监控等领域。主要关注点是识别和定位像行人这样密集排列的常见物体,其中遮挡和聚集带来了重大挑战。近年来已取得显著进展,包括两阶段方法[43, 57]和基于 Query 的方法[8, 21, 60]。然而,这些方法遵循监督方式,需要大量的标注训练样本,导致每个目标的标注成本高达约42.4秒[36]。人群密集场景的密度和复杂性进一步加剧了标注负担。
收集目标标注的高昂成本促使探索替代方法,如少样本学习[32, 37, 42],弱监督学习[39, 50],半监督学习[27, 28, 40, 47]和无监督学习[1, 6, 20, 24, 46]。表现最佳的方法,即半监督目标检测(SSOD),利用未标注数据进行训练,在PASCAL VOC[14]和COCO[23]等常见基准测试上取得了巨大成功。然而,SSOD引入了额外的复杂性,如复杂的增强和在线伪标注。
近年来,基于提示的分割模型因其灵活性和可扩展性而受到广泛关注。特别是,Segment-Anything Model(SAM)[19]可以有效地、准确地预测由提示指定的区域的 Mask ,这些提示可以是点、框、 Mask 或文本描述的任何形式。认识到其非凡潜力,研究行人已努力将其适应于各种视觉任务,如医学图像识别[29],遥感[4],工业缺陷检测[49]等。
尽管在SAM[17, 44, 51]之后已取得巨大进步,但当前大多数工作忽视了在人群密集场景中应用SAM进行目标检测任务的潜力。在本文中,作者研究在人群密集场景中应用SAM进行检测的潜力,其动机如下:首先,SAM在包含大多数常见物体的大型数据集上进行了预训练,即SA-1B。利用所学的知识来减轻大规模数据标注和训练全新检测器的难度是合理的。其次,SAM在处理由遮挡和聚集物体组成的复杂场景时展现出强大的分割能力,这对于从零开始训练的目标检测器可能是困难的。
在本文中,作者提出了Crowd-SAM,这是一个由SAM赋能的、用于人群密集场景中目标检测的智能标注器。如图1所示,作者引入了一种基于DINOv2的自我推广方法,以减轻人工提示的成本。作者的方法采用密集网格并配备了高效提示采样器(EPS),以在适度成本下覆盖尽可能多的物体。为了在遮挡场景中精确区分多个输出的 Mask ,作者提出了一个称为部分-整体区分网络(PWD-Net)的 Mask 选择模块,该模块学习区分输出质量最高的结果。凭借其轻量级设计和快速训练计划,它在包括CrowdHuman[35]和CityPersons[55]在内的基准测试中取得了相当的性能。

作者的贡献可以总结如下:
- 作者介绍了Crowd-SAM——一种用于标注密集数据集的自我提示分割方法,只需几个示例即可产生精确和准确的结果。
- 作者设计了Crowd-SAM的两个新组件,即EPS和PWD-Net,它们可以有效发挥SAM在密集场景中的能力。
- 作者在两个基准测试上进行了全面实验,以证明Crowd-SAM的有效性和通用性。
2
Related Work
目标检测。 通用目标检测旨在识别并定位物体,主要分为两类:一类是单阶段检测器,另一类是双阶段检测器。单阶段检测器直接从图像特征预测边界框和类别分数[22, 25, 33],而双阶段检测器首先生成区域 Proposal ,然后对这些 Proposal 进行分类和细化[9, 10, 34]。最近,端到端的检测器如DETR[2, 52, 61]通过在训练阶段采用一对一匹配,取消了非最大抑制(NMS)等人工作模块,在各个领域显示出巨大的潜力。
然而,由于行人通常密集且被遮挡,直接将这些检测器应用于行人检测任务将导致性能下降。早期工作[30]提出将额外的特征集成到行人检测器中以探索低级视觉线索,而后续方法[5, 53]尝试利用 Head 区域进行更好的表征学习。[53]中,将 Anchor 点与两个目标相关联,即整个身体和 Head 部分,通过联合训练实现更鲁棒的检测器。其他方法专注于损失函数的设计以改进训练过程。例如,RepLoss[43]鼓励同一目标的预测一致性,同时排斥不同目标。最近,Zheng等人[60]对 Query 之间的关系进行建模,以改进在拥挤场景中的DETR-based检测器,并取得了显著成功。尽管这些工作将拥挤场景中的目标检测推向了新阶段,但它们都依赖于大量的标注样本进行训练,这需要投入大量人力。这一局限促使作者开发标签高效的检测器和自动标注工具,借助SAM的帮助。
小样本目标检测(FSOD)。 该任务旨在从有限样本中检测新类别的物体。FSOD方法可以大致分为基于元学习[15, 48]和基于微调[32, 42, 37]的方法。Meta-RCNN[48]通过Siamese网络并行处理 Query 和支持图像。Query 的兴趣区域(ROI)特征与类原型融合,以有效地将从支持集学到的知识转移。TFA[42]提出了一种简单的两阶段微调方法,只微调检测器的最后几层。FSCE[37]在微调阶段引入了监督对比损失,以减轻误分类问题。De-FRCN[32]停止了来自RPN的梯度,并放大了来自R-CNN的梯度,随后通过原型校准块来细化分类分数。

图2:Crowd-SAM的 Pipeline 显示了不同模块之间的交互。DINO编码器和SAM在训练过程中保持冻结。*表示共享的参数。为了简化,省略了DINO的投影 Adapter 。
分割任何模型(SAM)。 SAM[19]作为一个分割任务的视觉基础模型,采用半监督学习范式在SA-1B数据集上进行训练。它接触到这个庞大的训练样本库,使其成为一个高度能干的类不可知模型,有效地处理了世界上的广泛物体。尽管它在解决分割任务方面表现出色,但它存在一些问题,如域偏移、低效、类不可知设计等。HQ-SAM[17]提出通过学习轻量级 Adapter 来提高其分割质量。Fast-SAM[59]和Mobile-SAM[51]专注于通过知识蒸馏加快SAM的推理速度。RSprompt[4]通过生成适当的提示,使SAM能够为远程感知图像生成语义上不同的分割结果。Med-SA[45]提出了一种空间-深度转置方法,将2D SAM适配到3D医疗图像,并通过超提示 Adapter 实现条件提示适配。不幸的是,这些方法需要相当数量的标注数据才能有效适配,使得它们在标注成本高昂的拥挤场景中不切实际。与它们不同,Per-SAM[54]和Matcher[26]仅用一个或少量实例就让SAM识别特定物体,通过提取无需训练的相似性先验。SAPNet[44]提出了一种针对实例分割的弱监督 Pipeline 。尽管这些方法减少了数据需求,但它们仍不能满足拥挤场景(如行人检测,特别是在遮挡场景中)的需求。
3
作者的方法Preliminaries
SAM[19]是一种前景看好的分割模型,它包含三个主要组成部分:
(a)负责特征提取的图像编码器;
(b)用于编码用户提供的几何提示的提示编码器;
(c)一种轻量级的 Mask 解码器,它根据给定的提示预测 Mask 。通过利用大量的训练数据,SAM在各类基准测试中展示了卓越的零样本分割性能。特别是,SAM使用点和框作为提示来指定感兴趣的区域。
DINO[3]是一系列为通用应用设计的自监督视觉 Transformer [7]的代表作。在其训练过程中,DINO采用了一种类似于BYOL[11]的自蒸馏方法,以促进学习鲁棒的特征表示。DINOv2[31]通过整合额外的预训练任务,增强了DINO的基础,提高了其可扩展性和稳定性,特别是在拥有10亿参数的大型模型如ViT-H中。得益于这种增强,DINOv2在特征表示能力上表现出色,特别是在语义分割任务中。
Problem Definition and Framework
如图1所示,作者的目标是使用少量标注数据在拥挤场景中检测行人。作者将此问题公式化为单类少样本检测任务。一种常见的少样本方法是将近似数据分为基础集和新型集。与此不同,作者直接使用目标类别数据来训练作者的模型,因为基础模型已经在大量数据上进行训练。特别是,作者使用分割 Mask 作为中间结果,这些结果可以轻松转换为边界框。在训练和评估过程中,仅提供框标注。
对SAM自动生成器的初步研究。 在作者介绍方法之前,作者深入探讨了提示数量如何影响SAM在拥挤场景中的性能。为此,作者在CrowdHuman [35] 上使用SAM的自动生成器进行了一些初步研究,该生成器利用网格点搜索每个区域。
表1传达了三个关键观察结果:(1) 拥挤场景需要密集网格;(2) 点提示的不明确性和类无关提示分布导致许多假阳性(FPs);(3) 当网格尺寸较大时,解码时间是不可忽视的负担。作者得出结论,密集提示和去除FP 是设计适用于拥挤场景中检测/分割任务的SAM基础方法的关键方面。

框架。 受到上述研究的启发,作者在SAM [19] 中配备了几个适当的组件,以实现准确且高效的标注框架,如图2所示。为了准确定位行人,作者采用基础模型DINOv2 [31] 来预测语义 Heatmap ,这是一个可以由简单的二分类器公式化的任务。为了区分输出的 Mask 混合了正确 Mask 、背景和部分级 Mask ,作者采用了部分-整体判别网络,它将来自SAM的学习 Token 和来自DINOv2的富含语义的 Token 作为输入,以重新评估所有输出。最后,为了处理由密集网格使用带来的冗余,作者提出了一个高效的提示采样器(EPS),以适中的成本解码 Mask 。
作者在以下各节中介绍作者方法的细节。
Class-specific Prompts Generation
为密集场景中的每个行人生成独特的点提示实际上是一个非平凡的问题。因此,作者后退一步,研究如何通过多个提示检测到一个行人,并随后使用适当的后期处理方法去除重复项。为此,作者采用了一种基于 Heatmap 的提示生成 Pipeline ,该 Pipeline 首先对区域进行分类,然后从阳性区域生成提示。
对于输入图像 , 作者首先使用预训练的图像编码器 提取丰富的语义特征。为了更好地将预训练特征转移到行人分割上, 作者在最后一层输出后添加了一个MLP块, 从而得到了调整后的特征 , 其中 是DINOv2 [31] 的 Patch 大小, 是输出通道数。然后, 作者使用一个分割头 Head 对 进行逐像素分类, 产生一个 Heatmap , 指示行人的位置, 即 。
在只有边界框标注 的情况下, 其中 是目标数量, 这个二值分割头可以通过边界框 Level 的监督进行优化。然而, 粗糙的边界会在背景区域引起相当多的点散射。为了减轻这个问题, 作者使用 SAM [19] 获取高质量的 Mask Level 伪标签, 如图4所示, 与 GT 值 (GT) 一起。解码后的 Mask 随后合并为一个单一的前景 Mask 。作者使用骰子损失来训练 Adapter 和分割头, 生成的伪 Mask 如下:

其中 是一个上采样函数, 用于将 调整为 尺寸。在推理过程中, 作者使用一个阈值 进行 Mask 二值化, 在实验中简单地设置为 0.5 。二值化的 Mask 映射到点提示 , 这些点提示只包含阳性区域内的那些。
语义引导的 Mask 预测
在本节中,鉴于第3.3节生成的 Proposal ,作者旨在高效地解码密集提示,并准确区分生成的 Mask 。如图3所示,由于网格的密集性,每个实例包含许多提示。假设对于SAM来说,只需要一个位置正确的提示来进行 Mask 预测,那么解码所有提示不仅会浪费计算资源,还可能因为一些位置不佳的提示导致更多的假阳性(FPs)。

高效的提示采样器(EPS)。 为了应对这一挑战,作者引入了高效的提示采样器(EPS), 它根据解码 Mask 的置信度动态地剪枝提示。这种方法在算法1中详细阐述。从生成的点提示列表 开始, EPS在每个迭代中使用统一随机抽样的方式从 中抽取一批提示 。然后将采样的提示 附加到输出点列表 中。随后, 作者使用带有批量提示 的SAM生成器来生成 Mask 。此外, 作者从PWD-Net中汇总判别置信度分数 , 这些分数用于使用分数阈值 选择有效的 Mask , 即 。PWD-Net的详细说明将在下一节中提供。有效 Mask 代表被认为是良好分割的区域,因此作者从提示列表 中移除已经被 中任何 Mask 覆盖的点。当 为空时, 迭代停止。此外, EPS通过设置参数 建立一个停止标准, 一旦总采样数达到这个限制, 就终止采样过程。这个参数对于管理整体解码成本非常有用。

部分-整体判别网络。 鉴于SAM根据采样提示批次预测的原始 Mask ,作者设计了一个自动选择器,以选择最适合的 Mask 。它应在以下两个方面改进输出:(i) 根据相关 Mask 的质量帮助细化输出交并比(IoU)分数,如果它们是阳性样本;(ii) 帮助抑制落在背景区域样本的分数。
如图2所示, 对于对应于 个提示生成的 Mask, 作者利用了SAM Mask 解码器中的_Mask Tokens_和_IoU Tokens_, 以及由自监督预训练模型DINOv2 [31]提取的高级特征。M 和U分别负责SAM Mask 解码器中的 Mask 解码和IoU预测。因此, 作者认为它们包含有助于区分 Mask 的形状感知信息。这些组件使作者能够在几次射击的方法中计算每个特定提示的判别置信度分数 。最初, 细化后的loU分数 计算如下:
通过利用自监督预训练模型DINOv2中嵌入的语义特征以及 Mask 数据 , 作者计算判别得分 :
在这里, 作者使用 来表示提取的_语义 Token _, 和 分别代表由SAM [29]生成的 Mask 和DINOv2 [31]模型提取的特征。作者用 表示一个下采样函数, 它将 Mask 的大小调整为 以与 保持一致。Pool是一个全局池化函数, 它在 轴和 轴上进行均值池化。判别得分 预测 Mask 属于前景还是背景。Head 与第 3.3 节中引入的二分类器共享相同的参数。最后, 作者通过简单地将这两个得分相乘来计算判别和估计质量的联合得分: 。
在训练过程中,使用真实 Mask 内采样的提示作为输入。对于前景内的提示,判别置信分数应准确预测生成 Mask 和真实 Mask 之间的交并比(IoU)。相反,对于背景内的提示,理想情况下得分应输出0,表示它们与背景相关。因此,这一方面的损失函数制定如下:
在这里, 表示由第 个提示生成的 Mask 的目标分数, 且 ; 。其中,
在这里, 表示由第 个提示生成的 Mask 的目标分数。 是由所有 个提示生成的目标分数集合, 是由所有 个提示生成的 Mask 集合, 而 是由所有 个真实 Mask 组成的集合,它由背景真实 Mask 集合 和前景真实 Mask 集合 组合而成。
以下是具体的定义:
- 如果真实 Mask 属于背景真实 Mask 集合 , 则目标分数 是由生成的 Mask 和对应的真实 Mask 计算的交并比 ( mloU );
- 如果真实 Mask 属于前景真实 Mask 集合 , 则目标分数 设置为 0 。(mse) 。
Training and Inference
在作者的框架中,总训练损失是方程(1)与方程(5)的组合:
在推理过程中, 作者在 4 个 Mask 中选择置信度得分 最高的 Mask 作为PWD-Net的输出, 作者将其表示为 和 。为了在小目标上获得更好的性能, 作者采用了文献 [19]中的窗口裁剪策略。这种策略将整张图像切割成重叠的裁剪区域,每个裁剪区域单独处理。最终的检测结果是从每个裁剪区域的输出合并得到的。作者对最终输出应用非极大值抑制以移除重复的 Proposal 。
4 Expe
riments
数据集。 按照文献[60]的做法,作者采用CrowdHuman [35]作为基准进行主要实验和消融研究。CrowdHuman [35]从互联网上收集并标注了包含密集人群的图像。其中,训练、验证和测试的图像数量分别为15,000、4,370和5,000张。作者还将在CityPersons [55]数据集上测试作者的方法,以进行真实城市场景的评估。此外,为了进一步研究作者的方法,作者使用OCC-Human [58]进行评估,该数据集专为被遮挡的人设计。对于这些行人数据集,作者使用可见标注(仅包括目标的可见区域)进行训练和评估。为了验证Crowd-SAM的可扩展性,作者还设计了一个多类版本的Crowd-SAM,通过增加一个多类分类器。作者使用COCO [23]_trainval_集合的0.1%进行训练,使用COCO _val_集合进行验证。作者还将在COCO的一个遮挡子集COCO-OCC [16]上验证作者的方法,该子集是通过选择目标重叠比例高的图像提取得到的。
实现细节。 在所有实验中, 作者使用SAM(ViT-L)[19]和DINOv2(ViT-L)[31]作为基础模型。在微调阶段, 它们的参数全部冻结以避免过拟合。作者不是使用真实的GT, 而是使用 SAM(ViT-L)生成的伪 Mask 作为 来指导PWD-Net在方程(5)中的学习。如图4(c)所示, 这些生成的伪标签质量很高。作者从伪 Mask 中随机挑选点作为正训练样本, 从背景部分挑选点作为负训练样本。在训练过程中, 作者使用Adam [18]进行优化, 学习率为 , 权重衰减为 。作者在一个GTX 3090 Ti GPU上以批量大小为 1 训练作者的模块2000次迭代,只需几分钟即可完成。更多细节请参考附录。

表2:在CrowdHuman [35]_val_集合上的结果。所有基于SAM的方法采用ViT-L [7]作为预训练的主干网络。SRCNN表示[38]中的Sparse R-CNN,它是[60]的一个 Baseline 。*表示使用多裁剪技巧。
评估指标。按照文献[60],作者使用IoU阈值为0.5的AP、MR和召回率作为作者的评估指标。通常,更高的AP、召回率和更低的MR表示更好的性能。
在行人检测上的实验结果
为了进行公平的比较,作者使用CrowdHuman [35] 和 CityPersons [55] 数据集中的可见标注重新实现了涉及的方法 [32, 41, 52, 56, 60],并采用了的训练计划。
主要结果。 作者将Crowd-SAM与大多数相关方法进行了比较,包括_完全监督的目标检测器_[41, 52, 56, 60],_小样本目标检测器_[32]以及_SAM基础方法_[19, 26],以获得全面的理解。注意,作者使用了可见标注,其结果与完整边界框标注的结果有所不同。
如表2所示,仅使用10张标注图像,作者的方法与_完全监督的目标检测器_取得了可比较的性能,后者最佳的结果是86.7%的AP,由DINO [52]取得。特别是,Crowd-SAM比先进的 Anchor-Free 点检测器FCOS [41]高出2.1%的AP。这些结果表明,在适当的适配技术下,SAM可以在复杂的行人检测数据集如CrowdHuman上取得极具竞争力的性能。另一方面,在少样本检测设置上,Crowd-SAM取得了最新的性能,并且大幅领先所有_小样本目标检测器_。DeFRCN [32]是一种装备了ResNet-101 [13]的成熟小样本目标检测器,其AP为46.4%。值得注意的是,作者的方法比其高出32%,这表明在少样本检测设置中Crowd-SAM具有优越性。作者的方法与De-FRCN的定性比较如图4所示。对于_SAM基础方法_,作者的方法在召回率上大幅领先SAM Baseline ,分别高出6%(使用多裁剪)和18.3%(不使用多裁剪)。Crowd-SAM也比其他方法如Matcher [26]更为优越。
在OccHuman和CityPersons上的结果。 为了研究Crowd-SAM在遮挡场景中的性能,作者将它与先进的监督方法Pose2Seg [58]进行了比较,结果如表3所示。值得注意的是,Pose2Seg是一种完全监督的检测器,而Crowd-SAM是一种少样本检测器。从结果可以看出,Crowd-SAM在AP上领先Pose2Seg 9.2%,这证明了其在遮挡场景中的鲁棒性。此外,作者将作者的方法应用于一个不那么拥挤但更现实的都市数据集CityPersons [55],结果如表4所示。Crowd-SAM在AP上比TFA [42]高出2.7%,比FSCE [37]高出1.1%,比De-FRCN [32]高出7.8%。总之,与先进的少样本目标检测器相比,作者的方法仍然具有竞争力,尽管它并非专门为稀疏场景设计。


这些结果说明,作者的方法已经充分释放了视觉基础模型(如SAM和DINO)在所有拥挤、遮挡以及城市场景中的潜力。
Experimental Results on Multi-class Object Detection
为了进一步探索作者的方法在更流行环境下的可扩展性,作者设计了一个多类别的Crowd-SAM。多类别版本的Crowd-SAM与二分类版本略有不同,主要是将二分类器替换为多分类器。作者在COCO [23]上进行多类别Crowd-SAM的验证,这是一个广泛采用的目标检测基准,以及主要由高遮挡比例图像组成的COCO-OCC [16]。
作者将作者的方法与两种有监督检测器(Faster R-CNN [34] 和 BCNet [16])进行了比较,并在表5中报告了结果。从表中可以看出,在两个数据集上,作者的Crowd-SAM与有监督检测器相当,当比较COCO和COCO-OCC时,AP值仅下降了1.4 AP%。这个微小的降幅表明作者的方法对遮挡具有鲁棒性。

Ablation Studies
模块消融研究。 作者对Crowd-SAM的关键组成部分——前景定位、EPS和PWD-Net——进行了消融研究,以验证它们的有效性。在表6中,当移除前景定位时,AP的性能显著下降了7.4%,召回率下降了8.5%,这表明限制前景区域的重要性。至于EPS,一旦移除,AP下降了0.6%。作者推测EPS不仅加速了密集提示的采样过程,还帮助聚焦于图像中难以理解的、语义含糊的部分。作者在表7中比较了EPS与其他批量迭代器。此外,作者发现PWD-Net是不可或缺的,当移除时,AP急剧下降至仅17.0%。最后,作者指出多裁剪是一种增强性能的强大方法,对最终性能的贡献为7.4% AP。总的来说,这些结果证明所有组件都是至关重要的。


所有三种采样器。然而,当网格大小达到128时,默认采样器遇到内存不足错误,阻止了它在这一设置中的采用。至于随机采样器,其性能受到K的限制,且大于64的网格大小仅带来有限的改进,例如0.1% AP。相反,作者的EPS可以从更大的网格大小中受益,尤其是在网格大小较大时性能更好。
PWD-Net消融研究。 作者将PWD-Net与用全零占位符替换某些标记的变体进行了比较。作者还比较了两种设计,直接调整IoU头或者学习一个并行的IoU头。如表8所示,所有三种标记,即 Mask 标记、IoU标记和语义标记,对最终结果都有贡献。特别是,一旦移除,AP下降了40.0%,这是一个灾难性的下降。这种退化表明, Mask 标记包含了对整体-部分区分任务至关重要的形状感知特征。值得注意的是,当作者调整预训练的IoU头时,AP下降了2.8%,这表明它可能对少量标注图像过拟合。作者相信,通过冻结SAM的IoU头,PWD-Net可以更多地从在大量分割数据上学到的形状感知知识中受益。

5 Conclusion
本文介绍了Crowd-SAM,一个基于SAM的框架,用于在拥挤场景中进行目标检测和分割,旨在简化标注过程。
对于每张图像,Crowd-SAM生成密集提示以获得高召回率,并使用EPS剪除冗余提示。为了在遮挡情况下实现精确检测,Crowd-SAM采用了PWD-Net,该网络利用多个信息性标记来选择最佳适配的 Mask 。
结合所提出的方法,Crowd-SAM在Crowd Human数据集上达到78.4 AP,与全监督检测器相当,这验证了在拥挤场景中的目标检测可以从像SAM这样的基础模型中在数据效率方面受益。
#S2Fusion
基于VR上半身稀疏信号的全身动作生成框架
在虚拟现实/增强现实(VR/AR)环境中,如何利用稀疏信号进行场景感知的人体运动估计?本文提出了基于条件扩散模型的动作生成框架 ,通过融合场景信息与稀疏追踪信号,实现对人体运动的准确估算。
本文介绍我们发表在CVPR 2024上的工作《A Unified Diffusion Framework for Scene-aware Human Motion Estimation from Sparse Signals》。本工作旨在稀疏动捕场景下,通过VR/AR设备提供的上半身追踪信号对人体全身动作进行重建还原,在虚拟现实、游戏交互中有着广泛应用。本工作上海科技大学2022级研究生唐江南为第一作者,由汪婧雅教授以及石野教授共同指导完成。
论文地址:https://openaccess.thecvf.com/content/CVPR2024/papers/Tang_A_Unified_Diffusion_Framework_for_Scene-aware_Human_Motion_Estimation_from_CVPR_2024_paper.pdf
代码链接:https://github.com/jn-tang/S2Fusion
视频链接:https://www.youtube.com/watch?v=f0y2Dv2kJcY
摘要
在增强现实与虚拟现实(AR/VR)应用中,基于头戴式显示器和手持控制器所捕获的稀疏追踪信号来估算全身人体运动具有至关重要的意义。在这一挑战中,核心难题在于如何将稀疏观测数据映射到复杂的全身运动,这一映射过程本身充满了歧义性。
为解决这一问题,我们提出了基于条件扩散模型(Conditional Diffusion Model)的动作生成框架 ,通过融合场景信息与稀疏追踪信号,实现对人体运动的准确估算。 首先利用周期性自动编码器提取稀疏信号中的时空关系,然后生成时间对齐特征作为附加输入。在此基础上, 继续融合场景几何和稀疏跟踪信号作为条件,使用条件扩散对从预训练的先验中提取的初始噪声运动进行多步采样,以生成准确的全身场景感知运动。
此外,我们设计场景穿透损失(Scene-penetration loss)和相位匹配损失(Phase-matching loss)来引导
的采样过程,使下半身在没有任何跟踪信号的情况下也能生成合理连贯的动作。实验结果表明,我们提出的在估计质量和平滑度等方面均优于最先进的技术。
背景:稀疏动捕场景下的人体运动生成
随着先进的 AR/VR 技术的出现,虚拟会议和游戏等应用中对生成逼真的虚拟人的需求不断增长。然而,常见的 AR/VR 设备,如 HTC Vive 和 Meta Quest Pro,仅提供来自单个头戴式显示器(HMD)和手持控制器内置惯性测量单元(IMU)的稀疏追踪信号。利用这些稀疏追踪信号生成密集的全身运动涉及到具有固有歧义的一对多映射,这使得该问题成为一个具有挑战性的任务。为了解决这个问题,研究者们采用了结合大规模运动捕捉数据和 AR/VR 设备提供的稀疏信号的数据驱动方法。
尽管先前的工作提出了各种各样的模型,如回归方法、变分自编码器(VAE)和归一化流(Normalizing flow),但是它们没有考虑周围的环境,因此都未能很好地解决一对多歧义问题,从而生成了不真实且不协调的运动。
方法
既然人体运动与周围环境密切相关,那么为什么不引入场景感知信息来减少从稀疏追踪信号估计全身运动的不确定性,从而提供更多有价值的线索呢?
因此,我们提出了 ( a unified framework fusing Scene and sparse Signals with a conditional difFusion model),一种融合场景信息与稀疏追踪信号的扩散模型框架。
给定 帧稀疏(头部以及双手)的追踪信号 以及场景点云 , 我们想要预测全身动作信号 。其中 和 分别表示输入和输出的维度, 表示场景点云中的点数。因此,
接受的条件输入为:
其中, 为使用 PointNet++ 从场景点云 提取的场景特征。 为使用周期自编码器(Periodic Autoencoder, PAE)从稀疏信号中提取的动作周期特征,虽然这些信号来自于不同的传感器,但它们的周期性变化可以反映出潜在的时间运动模式。
在
其中 是用来学习生成第 步中干净运动的网络, 表示添加的高斯噪声。为了提升采样速度,本文中使用的初始样本分布并非采样自标准高斯噪声, 而是来源于在 AMASS 数据集上预训练的基于 VAE 的动作先验模型。通过该先验模型, 我们可以将稀疏跟踪信号作为条件来采样得到初始运动样本, 这使得 Fusion 能够更快完成采样过程:
此外,我们发现缺乏下半身追踪信号会导致生成的腿部动作不真实,并且与上半身动作不协调。因此,我们设计了两个损失函数来引导 的采样过程,实现对下半身运动的灵活控制:
其中, 场景穿透损失 用来避免不真实的穿模效应, 例如人体直接穿过墙体; 相位匹配损失 通过对齐动作相位来使上半身和下半身的动作更加协调。这是因为人类倾向于同步上半身和下半身的运动以在日常活动(例如散步、跑步、跳舞等)中保持平衡。从图中, 我们可以观察到上半身和下半身的运动之间存在明显的相关性。
采样阶段的整体损失函数如下:
其中, 和 是控制损失函数强度的比例因子。在获得干净的运动样本后, 我们通过注入 的梯度来指导采样过程, 以规范下半身的运动
完整的采样算法流程如下, 其中
实验结果
我们的方法分别在 GIMO 和 CIRCLE 等不同的数据集上取得了更好的生成效果。
我们展示了两个不同场景中生成的运动序列的结果,并在红框中突出显示了不合理的运动。可以看出,我们的方法可以生成更多相关的腿部运动,并尽可能避免不合理的场景穿透现象。
消融实验
为了验证中各组成部分对性能的作用,我们还设计了额外的实验进行研究探讨:
首先,对模型中各个组件进行消融。其中,MP 表示预先训练的运动先验,Scene 表示模型是否接收场景信息作为额外输入,PAE 表示周期性自动编码器。从结果中可以看出,当三个组件都具备时,模型达到了最好的性能。
下面是探究两种损失函数的影响。从结果中可以看出, 虽然 和 可以提高运动估计质量, 但它们可能会在生成的运动中引入抖动运动。与 相比, 加入 在产生精确运动方面更有效。相反, 相较于 可以避免人体错误地接触地面。
#Inf-CLIP
无限批扩展可能么?达摩院Inf-CL打破对比学习显存瓶颈,提效100倍!
该方案突破了领域内“Contrastive loss 由于显存限制不能放大 batch size”的“共识”,实现了对比损失的 batch size 近乎无限的扩展。
达摩院研究员提出了一种对比损失(Contrastive Loss)的高效实现方式(Inf-CL),通过分块计算策略,在单台 A800 机器上就能把 batch size 扩展到 400万。该方案突破了领域内“Contrastive loss 由于显存限制不能放大 batch size”的“共识”,实现了对比损失的 batch size 近乎无限的扩展。
论文标题:
Breaking the Memory Barrier: Near Infinite Batch Size Scaling for Contrastive Loss
论文链接:
https://arxiv.org/pdf/2410.17243
代码链接:
https://github.com/DAMO-NLP-SG/Inf-CLIP
先看显著结果:

▲ 图1:Inf-CL 与现有方法(CLIP 和 OpenCLIP)的 GPU 显存使用对比。
图中标出了常见的 GPU 显存限制。对于超过 80GB A800 显存瓶颈 的情况,通过曲线拟合估算显存消耗。
- 左图:在 8×A800 GPU 配置下,CLIP 和 OpenCLIP 的显存消耗呈 二次增长,而 Inf-CL 实现了 线性增长。在 256k batch size 下,Inf-CL 将显存消耗降低了 78 倍。
- 右图:在 1024k batch size 下,即使使用 128 块 GPU,CLIP 和 OpenCLIP 的显存仍然会炸。而 Inf-CL 将显存需求减少了 281 倍。
01 背景
1.1 对比损失
对比学习从 20 年以来开始爆火,从那个时代走过来的小伙伴,应该还记得这个简单的损失函数绽放了多大的光彩。
在图像自监督领域 SimCLR 和 MoCo 两大模型系列相互争锋,跨模态检索领域,开启图文检索预训练的 CLIP 模型,在 NLP 和信息检索领域,大家耳熟能详的 SimCSE 和 DPR 等模型,都采用了 Contrastive Loss 作为训练损失。
以 CLIP 中的实现为例简单回顾一下 Contrastive loss。假设 batch size 为 , 图像和文本特征的维度为 , 则 CLIP 中的图像到文本的 Contrastive Loss 公式如下:

其中 是第 个图像和第 个文本之间的余弦相似度, 这里 是匹配样本(正样本对)的相似度。为了简化讨论, 公式中省略了温度因子。
从公式中可以看到,对比损失会将 batch 内非匹配的文本作为负样本,来计算匹配图文对(正样本对)归一化的概率。这个就叫做 In-batch negative 策略——即将 batch 内的所有其他样本视作负样本。
这种策略的优点在于,batch size 越大,模型就能接触到更多的负样本,从而学到更具判别性的特征。因此,了解对比学习的同学们都知道,batch size 理论上越大,效果就越好,这点也有很多文章从理论上进行分析。
那么一个直观地想法是,我们直接 batch size 扩大不就好了,就像别的分类,回归,或者文本生成的任务一样,把梯度累积步数多开一些,batch size 不就能一直增大了吗?
但遗憾的是,对比学习的 batch size 方法一直是一个比较蛋疼的问题。实现过对比损失的同学都知道,核心限制主要是“增大 batch size / 负样本,GPU 显存会炸”。接下来我们来分析显存消耗到了什么地方。
1.2 显存限制

▲ 图1.(a)Vanilla 实现的 Contrastive Loss:将所有特征广播到所有显卡,并同时将完整的相似度矩阵实例化到显存中。存储复杂度为(2),且在所有显卡上重复存储该矩阵。(b)Inf-CL 方法:采用分块-串行累加的策略减少显存占用。
在经典的对比损失实现中(如 CLIP),首先需要构建相似度矩阵,并将其存储在高带宽内存(HBM)中。然后对相似度矩阵应用 Softmax 归一化和负对数似然计算来完成损失计算。
然而, 相似度矩阵 及其归一化结果的显存需求, 会随着 batch size 呈二次方增长, 即显存复杂度是 , 这意味着当 batch size 较大时, 显存占用会变得非常庞大。
例如即使在采用 ViT-B/16 这种轻量化模型的情况下,当 batch size 达到 64k 时,Loss 计算部分的 GPU 显存消耗仍然极为惊人。如图 2(a)所示,尽管模型自身的显存开销仅为 5.24GB,但损失计算所需的显存却高达 66GB。
这个例子可以清楚看到,在 scaling batch size 时,显存瓶颈主要集中在损失计算上。现有的方法,如 Gradient Cache 和 BASIC 等,虽在一定程度上优化了模型的显存占用,但依然未能突破 loss 计算过程中显存二次增长的限制。
02 方法
2.1 分块计算策略
从上文的分析中我们可以看到,显存消耗的核心问题在于相似度矩阵 X 的完全实例化。那么有没有办法避免将它存储到显存里呢?为了达到这个效果,我们首先分析这个矩阵是用来计算什么的,所以先将对比损失的公式进行拆解分析:

公式分解后,我们可以将 contrastive loss 的计算拆解为两部分:
- 第一部分 :计算所有正样本对的相似度 并累加。这部分的计算复杂度是 ,即线性增长,因此不会造成显存瓶颈。
- 第二部分 : 计算 Log-Sum-Exp (LSE), 即所有负样本对的相似度的对数-指数和。这部分是由全局相似度矩阵 计算得到的,如果直接计算并存储整个矩阵,就会导致显存开销迅速增加。
将公式拆解后我们发现,原来相似度矩阵 X 的完全实例化是为了计算 LSE 这一项,其实也就是 Softmax 操作的分母部分。
看到这里,熟悉 on-line Softmax 和FlashAttention 技术的同学们可能已经秒懂了,本质问题是一样的:如果我们能通过分块计算避免一次性存储整个矩阵,LSE 的计算也就不会消耗很多的显存。
既然大模型的输入长度都能扩展到百万级别(例如 FlashAttention 支持的超长序列),那么对比损失的 **batch size scaling **问题自然也可以迎刃而解。
前向传播过程:
具体来说,分块策略的前向传播计算过程如下:

其中, 和 分别表示行和列方向上的分块数量。通俗的说, 就是不把矩阵 -次性计算并存储下来, 而是将矩阵 的计算划分为多个块(即子矩阵) , 并在每个块内部计算局部 LSE 值 , 之后沿着行方向逐步合并每列块的 LSE 值, 最终得到全局 LSE向量 。
这种分块计算方法显著减少了对显存的需求,因为每次只需计算和存储相似度矩阵的一部分,而不是整个 矩阵。此外,在列方向的运算支持并行,能够很好适应多 GPU 或 GPU 内部多芯片的并行架构,
防溢出策略:
为了避免在合并过程中出现数值不稳定或溢出,采用如下稳定的数值计算公式:

其中初始值 。每次迭代维护列方向的 LSE 向量 , 将中间值 累积到 中, 完成行方向所有块的计算后,得到最终的全局 LSE 向量 。
此外, 在计算 时, 直接对矩阵求指数可能导致数值溢出。为此, 我们采用以下稳定的公式进行计算:

其中 是一个行最大值向量, 每个元素代表 中对应行的最大值, 用作确保指数计算不会溢出。
反向传播过程:
其实在传统实现方式的前向传播过程中,相似度矩阵 X 会存储在计算图内,能够直接调用 pytorch 的 autograd 机制来计算梯度。既然我们在前向过程中仅仅存储了最终得到的 LES 向量 l,那么就需要自定义实现反向传播的算子。
体运算过程如下, 假设已经计算得到 loss 的结果, 要计算对于图像特征输入 和文本特征 的梯度:

根据 2.1 小节拆解的公式,以 为例,完整的梯度公式为:

从该公式可以看出,第二项计算依赖于相似度矩阵的值。我们在反向计算中也采用与前向过程相同的分块计算策略:
- 在前向传播时, 仅存储大小为 的向量 。
- 在反向传播时,逐块累积计算梯度:

其中 是用于累积的临时变量。通过这种分块计算, 我们在反向传播中同样避免了完整存储矩阵 的需求, 进一步降低了显存开销, 并实现了高效的梯度计算。详细的算法步骤在论文中可以找到。
2.2 Multi-Level Tiling**
看到这里的小伙伴们可能会产生疑问,分块累加这种操作本质上是将并行计算的过程用串行合并来替代了,也是一种时间换空间的策略,而且反向传播的 recompute 过程也会带来额外的计算,难道不会很慢吗?
其实问题的答案是:整体计算量会增加,但我们可以通过 GPU 的分布式运算特性来加速这个过程,运算速度却并不会减慢很多。加速过程主要是两块,即跨 GPU 的通讯和 GPU 内显存的 IO 加速。我们将其称为多层级分块策略。该策略将 LSE 的计算分配为粗粒度的跨 GPU 分块和细粒度的单 GPU 分块,以最大化计算效率。

▲ 图3. 多层级分块策略示意图。上:在 跨 GPU 分块中,每个 GPU 被分配多行数据,并负责对应行的 LSE 计算。计算与列方向的通信采用 异步 方式执行。下:在 单 GPU 分块 中,将行方向的计算任务分配给多个 CUDA 核心。每行的累积操作在一个 kernel 中执行,以减少 SRAM 和 HBM 之间 I/O 次数。
跨 GPU 分块(Cross-GPU Tile)
在并行训练中, 假设有 个 GPU, 每个 GPU 处理一部分图像和文本数据, 分别生成视觉特征 和文本特征 , 其中 表示单个 GPU 上的 batch size。计算对比损失时, 我们将不同行的数据分配给不同的 GPU, 并逐步同步各 GPU 之间的列数据。
具体而言, 第 个 GPU 负责相似度矩阵的第 行子块的 :及其对应的 LSE 向量 。为了降低显存开销, 结合分块策略, 每个行块 可以进一步拆分为 步小块 来计算 LSE, 具体过程可以在论文中算法 1 中找到。每个小块 的 LSE 计算采用单 GPU 分块策略 (详见下节)。
由于计算 (当 时)需要访问其他 GPU 上的文本特征 , 这不可避免地会带来通信开销。
为此,我们采用环形拓扑结构来尽可能减少通信时间。具体而言,每个 GPU 利用当前文本特征进行计算时,会异步地将其发送给下一个 GPU,并异步地从上一个 GPU 接收新的文本特征,如此循环执行。通过这种方式,通信时间可以与计算时间重叠,实现更高的效率。
单 GPU 分块(In-GPU Tile)
尽管跨 GPU 分块已经降低了显存复杂度至 , 但由于 GPU 数量有限的, 我们进一步引入单 GPU 分块策略, 将显存开销进一步降至 。具体而言, 我们将 细分为更小的块:

其中 和 分别表示在行和列方向的块数量, 和 是单个 块的大小。
在实现中,我们将这些 tile 的计算任务分配给多个 CUDA 核心,以充分利用 GPU 的并行计算能力。每个内核中,对每个 的行块进行串行计算,并应用 2.1 小节中的公式循环累积计算 LSE 的值 。
熟悉 flash attention 的同学们都知道,显卡计算的核心消耗在于 HBM 和 SRAM 的来回数据传输过程。为避免频繁的 HBM(高带宽内存)与 SRAM(片上内存)之间的数据交换带来的高昂开销,我们将行方向的迭代计算合并到一个 kernel 中执行。
通过这种方式,图像特征在计算开始时只需要加载到 SRAM 一次,而累积的 LSE 结果 l~i 仅在计算结束时写回 HBM 一次。这种仅把最终结果写入到 HBM 的 fused 操作,会极大提升算子优化性能。对比实例化整个相似度矩阵 X~ 写入 HBM 里,在运算时又进行取出的传统实现,这种 fused 的操作虽然行方向进行了串行计算,但整体速度几乎相当。
03 实验效果
显存开销对比

现有方法在 batch size 放大时计算 loss 的显存开销急剧增长,很快超出硬件限制,而 Inf-CL 即使在 batch size 很大时仍然可以将 loss 的显存开销控制在很小的范围内。
训练效率对比

与现有的对比学习损失计算实现相比,Inf-CL 不会明显增加计算时间,且随着 batch size 不断增大,计算效率也不会明显下降。
精度验证

由于数学上的等价性,使用 Inf-CL 不会损失精度,同时也验证了一定范围内放大 batch size 对模型性能有增益。
关于 scaling batch size 的讨论:

虽然理论上预计更大的批次大小会提高性能,但我们的实验结果与这一预期有偏差,有几方面原因:
首先,为保证训练时间不变,当前设定下增大 batch size 伴随着更少的迭代次数,可能需要对学习率、迭代次数等超参数进一步优化以确保模型收敛。其次,更大的数据集更准确地捕捉现实世界的分布,因此在大规模数据集上放大 batch size 的收益更为明显。
我们在不同数据规模(CC3M、CC12M 和 Laion400M)上的实验表明,最佳的batch size随数据集规模的增加而增加,体现了 Inf-CL 在 scaling law 下的长远意义。
04 总结
对比学习有多炸不用多说,在图文检索(CLIP为代表),图像自监督学习(SimCLR,MoCo 等),文本检索(DPR 等)是核心地位。该领域的共识都是“增大 batch size / 负样本很有用,但 GPU 显存会炸”,比如早期 MoCo 提出用 “momenturm encoder” 和 “memory bank” 来规避这个问题。
这个工作直面该问题,将对比损失的显存消耗打到底,且额外时间开销极少,为对比损失相关辐射领域提供了新的 scaling 机会。
#一文网尽CV/Robotics顶会论文常用高级词汇/句式!
写论文也有一些小套路?本文总结了尽可能多地CV/Robitcs领域的顶会文章中常出现的比较高级的词汇、好用的句式。
初入学术圈的小伙伴在写论文时一定有过一个烦恼:看大佬们的论文写的行云流水、文笔华丽,顿时激情澎湃,到了自己下笔却总是词不达意、句式散乱,翻来覆去就是那么几个重复的词,仿佛飞哥(我是小飞哥,不要搞混)附身.
其实我在去年刚开始读博时也有这个困扰,写文章曾经自闭到抓耳挠腮、撸秃秀发。后来我发现,写文章这事,光去读还不行,看到好的词语、句式一定要记下来,然后到自己写论文不知该如何写时拿来参考,效果非常好:读博前我一二作最好也就是投个workshop, ICPR这种水会,后来用了这种方式后写论文忽然得心应手,一路连中ITSC、IOTJ、ICRA、ECCV这些质量较高的会议和期刊。所以在这篇文章里,尽可能多地将CV/Robitcs领域的顶会文章中常出现的比较高级的词汇、好用的句式总结下来,并记录下每个词的出处和原文用法。
高级CV词汇:
leverage: 使用,利用,这个非常常见。例句:By leveraging the Vehicle-to-Vehicle (V2V) communication technology, different Connected Automated Vehicles (CAVs) can share their sensing information and thus provide multiple viewpoints for the same obstacle to compensate each other [1].
heterogeneous: 异向的,不同的,在graph里经常用到,例句:V2X-Vit is composed of alternating layers of heterogeneous multi-agent self-attention and multi-scale window self-attention, capturing inter-agent interaction and per-agent spatial relationships [2].
adverse: 不利的,例句:Our experiments show that multi-camera configurations are critical in overcoming adverse conditions in large-scale outdoor scenes [3].
streamline: 精简,例子:We streamline the training pipeline by viewing object detection as a direct set prediction problem [4].
reason, 常用在关系推导,比如:DETR reasons about the relations of the objects and the global image context to directly output the final set of predictions in parallel [4].
bypass, 跳过
invariant, 不变的, 例子:a point cloud is just a set of points and therefore invariant to permutations of its members(PointNet). Since the transformer architecture is permutation-invariant [4].
omit,忽略
auxiliary loss: 辅助损失
philosophy: 理念 This end-to-end philosophy has led to significant advances for ... [4].
fidelity: 逼真度,常用于simulation里, 例句:However, this can be a complex and costly endeavor that requires constructing realistic virtual worlds and developing high-fidelity sensor simulators [5].
full autonomy stack: 全栈自动驾驶系统,包含perception, localization, planning, control, [5].
gauge: 测量, downstream task/experiment: 自动驾驶下游任务,常见的如motion planning和control, 例句:To gauge the usefulness of using our simulations to test motion planning, we conduct downstream experiments with two motion planners [5].
sparse sensor measurements: 稀疏的传感器数据, 这个常在检测遮挡物体的话题里出现 [1][2]。
design ethos: 设计理念, 例子:The design ethos of DETR easily extend to more complex tasks [3].
ingredients: 要素, 例子:Two ingredients are essential for direct set predictions in detection [3].
reliance: 依赖,例子:We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks [6].
fashion: 风格,例子:We train the model on image classificaECCV2022tion in supervised fashion [6].
trump: 打败, 例子:We find that large scale training trumps inductive bias [6].
inductive biases: 归纳偏置,可以理解为对现实现象进行观察后进行一些总结,对模型进行约束,比如CNN是可以保持spatial relationship信息的,这是因为我们观察到图片每个pixel之间的位置关联很重要,所以这样设计了CNN。例句:Transformers lack some of the inductive biases inherent(这个词也常出现,表示内在属性) to CNNs, such as translation equivariance and locality.
alternating: 交互的,经常用来表示某几种module在模型里循环交叉出现,例子:The Transformer encoder consists of alternating layers of multiheaded selfattention and MLP blocks [6].
representation learning capabilities: 模型学习鲁棒feature的能力,经常出现。
appetite: 需求, 例子:This appetite for data has been successfully addressed in natural language processing (NLP) by self-supervised pretraining [7].
harness:驾驭,经常用于某种模型或方法没有被完全利用好,例如:However, its full power remains to be harnessed through the advent of new smart technologies, such as self-driving vehicles [8].
indispensable: 不可或缺的, 例如:Detecting objects such as cars and pedestrians in 3D plays an indispensable role in autonomous driving [9].
alleviate: 减轻,例如:To alleviate the local misalignment, we use a 2D-3D bounding box consistency constraint [10].
account for: 占据,例如:Consequently, errors in depth estimation account for the major part of the gap between pseudo-lidar and lidar-based detectors [10].
consensus: 共识, 例如:Hence, we propose a novel neural reasoning(这个词再次出现) framework that learns to communicate, to estimate potential errors, and finally, to reach a consensus about those errors [11].
surrogate: 代理,常用在adversarial attack中,例子:. In this setting, the attacker trains a surrogate model that imitates the target model [12].
degrade: 降低,损害,和performance联系紧密,常见的还有damage, decrease, drop. 例句:In addition, we also aim to minimize the intersection-over-union (IoU) of the bounding box proposals to further degrade performance by producing poorly localized objects [12].
hallucinating/hallucination: 原意是幻想,在CV里常用于amodal detection, 表示输入信息不直接含有某物体,但通过网络推理可以判断出物体在那。例句:We dub this problem amodal scene layout estimation, which involves hallucinating scene layout for even parts of the world that are occluded in the image [13].
defacto: 实际的:这个单词本身是拉丁语,但很多论文会用到,而且要用斜体。例句:We thus argue that MetaFormer is our de facto need for vision models that deserved more future research [14].
empirically 实操地,一般是想说用实验证明的意思,例句:we empirically demonstrate that the success of the transformer model is largely attributed to the MetaFormer architecture [14].
rudimentary 基本的,初级的。Currently, rudimentary resizing methods such as nearest neighbor, bilinear, and bicubic are among the top adopted image resizers visual recognition systems. [16]
off-the-shelf 现成的 The proposed resizer, therefore, can be an alternative to the offthe-shelf resizers to effectively reduce the expected drop in the recognition performance. [16]
常见CV句型:
表示xxx模型很流行:xxx have become the model of choice in some area.
解決某個問題:To ameliorate these issues
为了某个目的:Towards the goal of xxx
利用優點:leveraged the advantages of
表示转折:whereas
表示有些问题被解决,但还有一些被人们忽视:While much of the research into xxx(the certain area) have focused on (已解决的问题), an equally important yet underexplored problem is how to (还没有被解决的问题)。例句:While much of the research into microscopic traffic simulation have focused on modeling actors’ behaviors, an equally important yet underexplored problem is how to generate realistic snapshots of traffic scenes. (出处:SceneGen: Learning to Generate Realistic Traffic Scenes, CVPR)
表示实验证明某种想法的重要性:Our experiments emphasize/demonstrate the necessity/importance of xxx [3].
以xxx的形式:in the context of, 例子:In this paper, we consider the collaborative perception in the context of a heterogeneous multi-agent system [15].
表示某个元素起到关键作用:xxx play a critical role/ the success of something is attributed to xxx
#利用一致光传输提升图像照明编辑效果
本文提出了一种新的方法——一致光传输(IC-Light),通过物理原理确保在修改图像照明的同时保持其内在属性不变。
在当今数字图像处理的背景下,图像照明编辑成为了一个重要且充满挑战的领域。传统的计算机图形学方法通常依赖于物理照明模型来模拟图像的外观,这种方法强调了光源与物体之间的相互作用与反射。
然而,随着深度学习和生成模型的发展,基于扩散的图像生成方法逐渐成为处理照明编辑问题的新兴手段。这些方法不仅可以应对更为复杂的“野外”照明效果,还能在图像中灵活地生成各种光照变化,如反向照明、边缘光源、光晕效果等。通过这些技术,艺术家和设计师能够在保持一致的照明条件下修改前景或背景,进而提升视觉内容的创作和操控能力。
尽管基于扩散的照明编辑方法展示了巨大潜力,进行大规模训练并利用强大的模型架构仍然面临诸多挑战。尤其是在处理多样和复杂的数据集时,如何保持模型的期望行为,确保其能够实现准确的照明操作而不是偏离到无序的随机行为,就显得尤为重要。
数据集的增大及多样性是一个双刃剑,它往往会导致学习目标的模糊和不确定性,使教导模型学习到照明的映射变得困难。为了应对这些挑战,本文提出了一种新的方法——一致光传输(IC-Light),通过物理原理确保在修改图像照明的同时保持其内在属性不变。
论文标题:
Scaling In-the-Wild Training for Diffusion-based Illumination Harmonization and Editing by Imposing Consistent Light Transport
论文地址:
https://openreview.net/forum?id=u1cQYxRI1H
一致光传输的核心思想是,通过确保物体在不同照明条件下的外观的线性叠加与其在混合照明条件下的外观保持一致,从而为模型提供一个强有力的物理约束。
这种一致性不仅支持模型在超过 1000 万张多样化样本上进行稳定的可扩展训练,也为图像的内在属性保持提供了保障。这种方法的有效性和灵活性使得其在多种数据来源的处理上具备广泛的应用潜力,包括真实照明阶段、渲染样本以及合成的野外数据。

▲ 用户为对象图像和照明描述提供输入,我们的方法生成相应的对象外观和背景。
通过大量的实验证明,IC-Light 方法在降低不确定性、减轻材料不匹配和反射色改变等伪影方面表现出色。这些进展为照明编辑的工业应用提供了坚实基础,预示着基于扩散的图像生成技术在创意领域的无限可能。
02 相关工作
在过去十年中,基于深度学习的图像照明编辑方法逐渐成熟,这些方法不仅改进了传统计算机图形学技术,还利用神经网络学习复杂的照明模型。
研究者们首先利用深度神经网络从光阶段数据中提取先验知识(Sun et al., 2019),随后有研究针对神经网络的能力进行了增强,使用物理先验进行训练(Nestmeyer et al., 2020)。此外,Pandey et al. (2021) 利用高动态范围(HDR)照明图来训练重照明模型,显式优化 Phong 模型的先验。
近年来,扩散模型在图像生成和操控方面展现出了巨大的潜力(Dhariwal & Nichol, 2021;Ho et al., 2020)。这些模型能够有效地处理图像编辑任务(Ho & Salimans, 2021),并基于文本生成高质量的图像(Rombach et al., 2022)。例如,Relightful Harmonization(Ren et al., 2024)方法将前景照明的操控与背景条件相结合,成功实现了照明的调整。
类似的,DilightNet(Zeng et al., 2024)、FlashTex(Deng et al., 2024)和Neural Gaffer(Jin et al., 2024)等方法主要基于三维渲染数据进行物体外观操控。
除了基于深度学习的模型,传统的计算机图形学技术仍然在照明编辑界占据重要地位。许多研究(Dorsey et al., 1995;Debevec et al., 2000)展示了如何在图像渲染中准确模拟照明效果,包括光源类型和背景影响等因素。这些研究为本研究提供了理论基础,使得结合扩散模型和物理背景的照明编辑变得可行。
尽管已有大量研究在图像照明编辑领域取得了显著进展,但这些方法仍存在一定的局限性,如在复杂场景中保持内在属性(如反射率和细致的图像细节)的能力较弱。
本研究将通过一致光传输(IC-Light)的方法进行扩展和完善,以确保照明操控精准且不影响图像的其他内在属性。这一方法的提出不仅填补了现有研究的空白,也为未来的图像编辑技术发展提供了新的视角和思路。
03 方法论
在本节中,研究团队提出了一种称为一致光传输(IC-Light)的方法,旨在处理图像的照明编辑问题。该方法基于光传输的物理原理,确保在修改图像照明时能够保留图像的内在属性,例如反照率(albedo)和细节。
3.1 一致光传输的原理
一致光传输的核心理念是,物体在不同照明条件下的外观线性混合,总体上能够与在混合照明条件下的外观保持一致。即对于给定的任意外观 和关联的环境照明 , 存在一个矩阵 使得:
这里, 可以视为数据格式中的 。
这种线性关系阐明了根据不同光源条件下物体外观的混合表现与在合成照明下的外观是等效的。这一现象得到现实世界测量的验证(例如,Haeberli, 1992)。通过这种观点,研究者能够确保模型在训练过程中只修改图像的照明,而不改变其内在属性,进而引入了一致性损失函数来保持这种线性关系:
其中, 是一组掩膜, 表示在该区域有效, 仅在有光照的部分计算一致性损失, 是一个可学习的多层感知机 (MLP), 旨在替代总和项。
3.2 方法流程
研究团队的训练目标结合了两个主要的损失函数:一个是基础图像重采样损失 和一致性损失 的加权组合。最终的学习目标可以写成:
在这一目标中, 使用的默认为权重设置为 和 。
通过实施上述一致光传输约束,模型不仅能驰骋于光照编辑的各类任务,还能在进行图像内容生成时较好地保持细节和内在属性。关键的一点是,模型在随机选择不同的环境光源时,依然能够保持对变换前后的色彩、亮度以及细节的控制。
在图 3 中,以图 [3-(a)] 作为基础,仅使用标准的图像条件扩散模型进行照明学习,并与图 [3-(b)] 中的光传输一致性实施方案进行对比,可以看出在保持图像细节的同时更为有利于生成一致性的光照效果。

▲ 学习目标
通过这种方法,IC-Light 实现了更稳定的训练表现,能够处理大规模、复杂的和噪声数据,确保模型可以广泛应用于真实场景的照明编辑。
04 实验设计
本节详细描述了实验的设置、数据来源以及模型训练的细节。研究团队旨在通过大规模数据集采集和优化算法的应用,以测量一致光传输(IC-Light)方法在照明编辑中的表现。
4.1 数据来源
在本研究中,数据集主要来源于以下几个部分:
- 野外图像数据:通过在大约 5000 万张图像中进行筛选,最终选择了 6 百万张图像来进行训练。这一过程涉及到与“美丽照明”、“光线”和“照明”等关键词的 CLIP 视觉相似性比较,确保所选图像具有较高的照明质量。
- 3D 渲染数据:使用 Objaverse 数据集进行渲染,采取了一种基于图像的渲染管线以提高速度,最终形成约 400 万张图像。
- 光阶段数据:从多个光阶段数据集中提取,汇总了 20,000 个光阶段样本。这些数据被预处理成统一格式,以便训练模型时使用。
通过整合来自不同来源的数据,研究团队确保模型能够接触到多样化的照明场景,进而提升模型的泛化能力。
4.2 优化算法和模型训练
模型训练过程中,研究团队使用 AdamW 优化器,并设置学习率为 1e-5。预训练好的 Stable Diffusion 模型包括 SD 1.5、SDXL 和 Flux.1.0-dev。训练过程在 8台 H100 80GB NVLink GPU 上进行,最大化批处理大小以提高训练效率。
此外,针对每个模型的训练时长也被精确记录:
- SD 1.5 模型训练耗时约 100 小时。
- SDXL 模型首先在 512 分辨率下训练 80 小时,然后在 1024 分辨率下微调 60 小时。
- 对于 Flux 模型,采用了多阶段的训练策略,为了应对模型的复杂性,研究团队分别训练了双流和单流部分,并对部分梯度图进行了冻结。
4.3 数据集平衡
为确保训练效果,研究团队在训练早期采用调度概率来平衡各数据集的贡献。具体来说,通过调整初期阶段野外图像数据和 3D 渲染数据的出现概率为 0.5,而光阶段数据的出现概率为 0.0。在经过 10 万次迭代后,随着训练的深入,光阶段数据的出现概率逐步增加到 0.3,确保在最终模型中包含一定比例的高质量光阶段数据。
这种动态调整的方式,使得模型不仅能在初期获得对多种数据来源的理解,同时在后期也能够借助高质量的数据提升最终性能。
在模型训练过程中,核心损失函数的形式如下:
其中, 表示综合损失, 和 分别对应于基础图像条件扩散模型的损失和一致光传输的损失函数。
4.5 实验流程图
如下图所示,研究团队在训练过程中融合了数据来源与模型架构,以确保输出的图像保持内在属性的一致性:

▲ Dataset collection
通过以上详细的实验设计,研究团队旨在验证一致光传输方法在大规模、多样化图像照明编辑中的有效性,期望该方法能够为后续的实际应用奠定坚实基础。
05 实验结果与讨论
本节将呈现对比实验的结果,展示提出的方法在光照编辑任务中的优势与局限性。通过定量指标与定性结果的综合分析,旨在探讨影响模型表现的关键因素。
5.1 实验结果
采用多种评价指标对模型表现进行量化评估,包括峰值信噪比(PSNR)、结构相似性指数(SSIM)以及学习感知图像块相似性(LPIPS)等。这些指标用于量化模型在生成图像上的保真度和视觉质量。表 1 展示了不同实验组的定量评估结果。

▲ 表1: 定量测试的评估结果
如表中所示,完整的方法在所有指标上均表现出色,尤其在 LPIPS 指标上,表明其生成的图像具有优越的感知质量。相比之下,仅依赖 3D 渲染数据训练的模型在 PSNR 上表现最佳,但显然存在评估偏差。
5.2 定性结果
除了定量结果外,定性分析也显示了所提出方法的优势。通过与其他现有方法的视觉比较,如图 6 所示,本研究的方法在处理复杂阴影和光照变化上表现出更强的鲁棒性。具体来说,生成的图像更好地保留了原始图像中的细节与色彩,尤其是在光源及材质变化的场景中。

▲ 图6: 视觉比较。这一图展示了本研究方法与其他方法在处理光照情况下的表现。
5.3 影响因素分析
在实验过程中,模型表现受多个因素的影响,特别是在数据源丰富性和训练目标一致性上。通过消除在野外的图像增广数据,模型的泛化能力显著下降。例如,在处理复杂图像(如肖像照片)时,模型往往不能正确渲染附加的物体(如帽子),非常明显的色彩失真。
同样,当去除光传输一致性约束时,模型在生成一致的光照和保持内在属性(如反射率)方面的能力显著下降。在此情况下,图像中不同颜色的差异可能消失,并因色彩饱和度的问题出现明显的视效缺陷。
结合以上定量与定性分析,投射式光传输一致性与多样的训练数据源结合使用,是确保模型在各种光照情况下表现优越的关键因素。
06 结论
在本研究中,作者提出了一种名为一致光传输(IC-Light)的方法,以扩展基于扩散的照明编辑模型的训练。通过利用物理原理,IC-Light确保了在进行图像照明操控的同时,图像的内在属性如反射率和细节得以保持。
多项实验证明,这一方法不仅提高了模型在多样化照明环境中的鲁棒性和表现,还有效降低了由于在训练过程中数据的复杂性和噪声带来的不确定性。
综上所述,一致光传输方法在照明编辑领域展示了显著的潜力和应用价值。它使得在处理超过一千万张的多样化样本时,模型仍然能保持较高的精确度与一致性,大幅提升了生成结果的视觉质量。
特别是在处理复杂背景或艺术性照明效果时,这一方法显示出了独特的优势。未来的研究方向可能包括进一步提升模型的泛化能力,并探索将其应用于实时图像处理和更加复杂的视觉生成任务。
此外,研究者计划通过引入更多种类的输入和优化算法,进一步改善模型在不同光照条件下的表现,以实现更加自适应、高效的照明编辑。在此过程中,期待 IC-Light 方法能够更进一步地推动图像生成与编辑技术的发展,并为视觉内容的创造提供创新工具和手段。
#目标检测的未来是什么?
你或许很好奇,现在目标检测都在干啥?在大模型时代有啥花样可以做的?作为研究者还有啥可以挖的吗?作为从业者有没有好的东西可以借鉴?
如果你有这些疑问,那么这篇文章很适合你。
其实这篇文章是想说明下从我们常见的目标检测到现在 MLLM 盛行的时代,和 Object Detection 任务有哪些?目前又涌现了哪些新的任务?是否有很大的实际价值?希望能够打开下大家思路!!!
1 Object Detection
经典目标检测大家应该非常熟悉了,一般指的就是闭集固定类别的检测。
2 Open Set/Open World/OOD
这个任务是指在实际应用上可以检测任何前景物体,但是有些不需要预测类别,只要检测出框就行。在很多场合也有应用场景,有点像类无关的增量训练。
unknown 就是模型预测的不知道类别的检测结果。
3 Open Vocabulary
也是开放集任务,相比于 open set,需要知道不在训练集类别中的新预测物体类别。这类模型通常都需要接入文本作为一个模态输入,因为开放词汇目标检测的定义就是给定任意词汇都可以检测出来。
训练时候通常是要确保训练集和测试集的类别不能重复,否则就是信息泄露了,但是训练和测试集图片是否重复其实也没有强制限制。
可以看出 OVD 任务更加贴合实际应用,文本的描述不会有很大限制,同一个物体你可以采用多种词汇描述都可以检测出来。OVD 任务是一个比较实用的,但是目前还没有出现开源的超级强的 OVD 算法(这个超强是指的对比 SAM 来说,极强的 open 检测能力)
4 Phrase Grounding
这个任务也叫做 phrase localization。给定名词短语,输出对应的单个或多个物体检测框。如果是输入一句话,那么就是定位这句话中包括的所有名词短语。在 GLIP 得到了深入的研究。
从上图可以看出,Phrase Grounding 任务是包括了 OVD 任务的。常见的评估数据集是 Flickr30k Entities
5 Referring Expression Comprehension
简称 REC,有时候也称为 visual grounding。给定图片和一句话,输出对应的物体坐标,通常就是单个检测框。
常用的是 RefCOCO/RefCOCO+/RefCOCOg 三个数据集。是相对比较简单的数据集。这个任务侧重理解。
6 Description Object Detection
描述性目标检测也可以称为广义 Referring Expression Comprehension。为何叫做广义,这就要说道目前常用的
Referring Expression Comprehension 存在的问题了:
- REC 数据集通常都是指代一个物体,不太符合实际
- REC 数据集没有负样本,也就是每句话一定对应了图片中的物体,这样训练的模型会存在很大的幻觉
- REC 数据集通常都是正向描述,例如上图的一条在图片左边的狗,但是没有反向描述,例如一条没有被绳子牵引着在外面的狗
基于此,Described Object Detection 论文提出了这个新的数据集,命名为 DOD。类似还有 gRefCOCO
其实还有一个更细致的任务叫做 :Open-Vocabulary Visual Grounding 和 Open-Vocabulary Phrase Grounding,来自论文 OV-VG
可以看出这个任务重点是想特意区分类别泄露问题,但是由于大数据集训练时代,这个情况是无法避免的。
7 Caption with Grounding
这个任务的含义是:给定图片,要求模型输出图片描述,同时对于其中的短语都要给出对应的 bbox
有点像 Phrase Grounding 的反向过程。这个任务可以方便将输出的名称和 bbox 联系起来,方便后续任务的进行。
8 Reasoning Intention-Oriented Object Detection
意图导向的目标检测,和之前的 DetGPT 提出的推理式检测,我感觉非常类似。
DetGPT 中的推理式检测含义是:给定文本描述,模型要能够进行推理,得到用户真实意图。
例如 我想喝冷饮,LLM 会自动进行推理解析输出 冰箱 这个单词,从而可以通过 Grounding 目标检测算法把冰箱检测出来。模型具备推理功能。
而 RIO 我觉得也是一样,来自论文 RIO: A Benchmark for Reasoning Intention-Oriented Objects in Open Environments,想做的事情也是一样
9 基于区域输入的理解和 Grounding
这个是一个非常宽泛的任务,表示不仅可以输入图文模态,还可以输入其他任意你能想到的模态,然后进行理解或者定位相关任务。
最经典的任务是 Referring expression generation:给定图片和单个区域,对该区域进行描述。常用的评估数据集是 RefCOCOg
现在也有很多新的做法,典型的如 Shikra 里面提到的 Referential dialogue,包括 REC,REG,PointQA,Image Caption 以及 VQA 5 个任务
Apple 也提出了新的可交互的设计
其实文本、bbox 和图片配合,还可以实现很多任务,但是由于都是比较特殊或者不是很主流,这里就没有写了。
10 结尾
可能还漏掉了一些,欢迎大家留言评论。后续可以讲讲这些任务应该如何解决?每个任务到底是咋评测的,通常的做法是咋样的。
现在都是大数据训练时代,评测虽然非常有用,但是很难避免数据泄露问题,如果作者不开源,你根本无法知道到底是模型性能还是数据泄露,这个一个值得思考的问题...,而这个问题也很难解,因为作者不开源,你也没有精力去做复现...
#CoTracker3
用于卓越点跟踪的最新 AI 模型
Meta 的 CoTracker3 最近以一种新的点跟踪方法进入了 AI 领域,这是计算机视觉的核心任务。无论是跟踪视频中跨帧的点、分析运动镜头,还是处理遮挡和快速移动,CoTracker3 都能使工作更轻松、更快速、更准确。该模型基于 TAPIR 和 BootsTAPIR 等早期版本构建,但因使用伪标记来提高性能而脱颖而出。
那么,是什么让 CoTracker3 值得您关注呢?让我们来看看它的核心功能以及它如何超越其前辈。
什么是 CoTracker3
CoTracker3 是一种尖端的 AI 模型,专为跟踪视频中多帧的点而设计。它对于三维重建、视频编辑甚至动作捕捉等应用程序非常有用。如果您曾经处理过视频,您就会知道跟踪点是多么具有挑战性,尤其是当它们快速移动或消失在物体后面时。CoTracker3 旨在通过更高效、更准确的解决方案来解决这个问题。
“CoTracker3 通过利用伪标记简化了点跟踪,减少了对手动标记数据的需求。”
CoTracker3 的主要特点
CoTracker3 具有一些突出的功能,使其不同于其他点跟踪模型。让我们分解主要元素:
1. 伪标签 — 游戏规则改变者
伪标签允许 CoTracker3 使用未标记的视频数据并生成合成标签。这可以节省大量时间,因为您无需手动标记大型数据集。此外,该模型通过随着时间的推移优化这些伪标签来改进自身,从而实现更准确的跟踪。
2. 前沿高效的架构
CoTracker3 采用更简单的架构设计,但精度高。它可以并行处理多个帧,这意味着实时或近乎实时的应用程序可以更快地获得结果。其轻巧的设计使其即使在资源有限的项目中也易于使用。
3. 处理遮挡和复杂移动
点跟踪中最棘手的挑战之一是当一个对象消失在另一个对象后面(遮挡)或移动太快以至于模型无法跟随时。CoTracker3 可以预测点会重新出现的位置,使其在复杂的场景(如运动镜头或拥挤的环境)中高度可靠。
CoTracker3 有什么新功能?
CoTracker3 通过添加新功能并使跟踪过程更顺畅,改进了 TAPIR 等旧模型。一些最新功能包括:
改进的多对象跟踪:现在,跟踪同一场景中的多个点变得更加容易。无论您是在场上关注多名运动员,还是在繁忙的视频中关注多个对象,CoTracker3 都能无缝处理。
对低质量素材的适应性:并非所有视频都是以高清拍摄的,CoTracker3 考虑到了这一点。即使在低分辨率或抖动的视频上,它也能表现良好,使其成为各种行业的多功能工具。
“CoTracker3 旨在在高质量和低质量视频环境中都表现出色,使其成为当今 AI 领域适应性最强的模型之一。”
为什么CoTracker3脱颖而出?
与其前代产品不同,CoTracker3 在不牺牲性能的情况下消除了点跟踪的复杂性。以下是它脱颖而出的一些原因:
更快的处理速度:该模型针对速度进行了优化,处理帧的速度比以前的版本更快。
对遮挡更稳健:CoTracker3 可预测隐藏点将再次出现的位置,从而提高困难情况下的跟踪准确性。
减少对人工标记数据的依赖:由于伪标记,模型可以自我训练,从而减少手动数据标记所需的时间和成本。
CoTracker3 是点跟踪领域的一项突破,提供了比以往任何时候都更高效、更准确和用户友好的方法。
#LAUDNet
清华黄高团队提出:高效图像识别的统一动态网络
本文提出了一种名为LAUDNet的延迟感知统一动态网络,该网络通过综合空间自适应计算、动态层跳过和动态通道跳过三种动态推理范式,实现了高效图像识别,并在多个硬件平台上显著降低了实际延迟。
题目:Latency-aware Unified Dynamic Networks for Efficient Image Recognition
延迟感知的统一动态网络用于高效图像识别
作者:Yizeng Han; Zeyu Liu; Zhihang Yuan; Yifan Pu; Chaofei Wang; Shiji Song; Gao Huang
https://www.github.com/LeapLabTHU/LAUDNet
论文创新点
统一动态推理框架(LAUDNet):提出了一个综合框架,将空间自适应计算、动态层跳过和动态通道跳过三种代表性的动态推理范式统一在一个框架下,以提高深度网络的推理效率。
延迟感知的算法设计与调度优化:通过一个延迟预测模型,准确估计不同动态操作员在各种计算平台上的实际延迟,并将此延迟预测结果用于指导算法设计和调度优化,以实现理论与实际效率之间的有效匹配。
粗粒度动态网络和批量推理:提出了粗粒度动态网络设计,通过在块/组级别而不是单个像素/通道级别上做出“是否计算”的决策,以减少内存访问延迟,并允许批量推理,进一步提升了网络的实际加速性能。
摘要
动态计算已成为提高深度网络推理效率的有前途策略。它允许选择性激活各种计算单元,如层或卷积通道,或自适应分配计算到图像特征中的高信息空间区域,从而显著减少每个输入样本的条件不必要计算。然而,动态模型的实际效率并不总是与理论结果相对应。这种差异源于三个关键挑战:1)由于研究领域的分散,各种动态推理范式缺乏统一的公式;2)过分强调算法设计,而忽视了调度策略,这对于优化CUDA启用GPU环境中的计算性能和资源利用至关重要;3)评估实际延迟的繁琐过程,因为大多数现有库都是为静态操作员量身定制的。为了解决这些问题,我们引入了延迟感知统一动态网络(LAUDNet),这是一个综合框架,将三种基石动态范式——空间自适应计算、动态层跳过和动态通道跳过——统一在一个统一的公式下。为了协调理论和实际效率,LAUDNet将算法设计与调度优化相结合,辅以一个延迟预测器,该预测器准确高效地衡量动态操作员的推理延迟。这个延迟预测器协调了算法、调度策略和硬件属性的考虑。我们在一系列视觉任务中,包括图像分类、目标检测和实例分割,验证了LAUDNet框架内的各种动态范式。我们的实验证实LAUDNet有效地缩小了理论与现实世界效率之间的差距。例如,LAUDNet可以在V100、RTX3090和TX2等硬件平台上将其静态对应物ResNet-101的实际延迟降低50%以上。此外,LAUDNet在准确性和效率之间的权衡中超过了竞争方法。代码可在:https://www.github.com/LeapLabTHU/LAUDNet 获取。
关键字
- 动态网络
- 高效推理
- 卷积神经网络
- 视觉Transformers
1 引言
深度神经网络在计算机视觉[1]、[2]、[3]、[4]、[5]、自然语言处理[6]、[7]、[8]、[9]和多模态理解/生成[10]等多个领域展现出了卓越的能力。尽管它们表现出色,但这些深度网络的密集计算需求常常限制了它们在资源受限平台(如移动电话和IoT设备)上的部署,突显了对更高效深度学习模型的需求。与统一处理所有输入的传统静态网络[2]、[3]、[4]不同,动态模型[11]以数据依赖的方式自适应地分配计算。这种自适应性涉及有条件地绕过某些网络层[12]、[13]、[14]、[15]或卷积通道[16]、[17],并执行空间自适应推理,将计算工作集中在图像的最信息区域[18]、[19]、[20]、[21]、[22]、[23]。随着该领域的不断发展,各种动态模型显示出了希望,这就引出了一个问题:我们如何为实际使用设计一个动态网络?
解决这个问题是具有挑战性的,因为很难公平地比较不同的动态计算范式。这些挑战分为三类:1)缺乏一个统一的框架来包含不同的范式,因为这一领域的研究通常是分散的;2)专注于算法设计,这通常导致实际效率与它们的理论计算潜力不匹配,因为调度策略和硬件属性对实际延迟有重大影响;3)在不同硬件平台上评估动态模型的延迟是一项繁琐的任务,因为常见的库(例如cuDNN)不是为加速许多动态操作员而构建的。作为回应,我们引入了一个延迟感知统一动态网络(LAUDNet),一个统一框架,它统一了三种代表性的动态推理范式。具体来说,我们检查了层跳过、通道跳过和空间动态卷积的算法设计,通过一个“掩码和计算”方案(图1(a))将它们整合在一起。接下来,我们深入探讨了将理论效率转化为实际加速的挑战,特别是在多核处理器如GPU上。传统文献通常采用与硬件无关的FLOPs(浮点操作)作为粗略的效率度量,未能为算法设计提供延迟感知指导。在动态网络中,自适应计算与次优调度策略相结合,加剧了FLOPs和延迟之间的差距。此外,大多数现有方法在最细粒度上执行自适应推理。例如,在空间动态推理中,对每个特征像素是否计算的决定是独立的[19]、[20]、[21]。这种细粒度的灵活性导致非连续内存访问[21],需要专门的调度策略(图1(b))。鉴于动态操作员显示出独特的内存访问模式和调度策略,为静态模型设计的库,如cuDNN,无法有效优化动态模型。缺乏库支持意味着每个动态操作员需要单独的调度优化、代码改进、编译和部署,使得在硬件平台上评估网络延迟变得劳动密集。为了解决这个问题,我们提出了一个新颖的延迟预测模型,通过考虑算法设计、调度策略和硬件属性,有效地估计网络延迟。与传统的硬件不可知FLOPs相比,我们预测的延迟提供了动态模型效率的更现实表示。在延迟预测模型的指导下,我们在延迟感知统一动态网络(LAUDNet)框架内解决了上述挑战。对于给定的硬件设备,我们使用预测的延迟作为算法设计和调度优化的指导指标,而不是传统使用的FLOPs(图1(c))。在这种情况下,我们提出了粗粒度动态网络,其中“是否计算”决定是在块/组级别而不是单个像素/通道级别上做出的。尽管这种方法在灵活性方面不如先前工作中的像素/通道级适应性[16]、[17]、[19]、[20]、[21],但这种方法鼓励连续内存访问,增强了硬件上的实际加速。我们的改进调度策略进一步允许批量推理。我们研究了动态推理范式,重点关注准确性-延迟权衡。值得注意的是,先前的研究已经建立了CPU上延迟和FLOPs之间的相关性[21]、[23],因此本文主要针对GPU平台,这是一个更具挑战性但较少探索的环境。

LAUDNet被设计为一个通用框架,有两种方式:1)多种自适应推理范式可以轻松实现在各种视觉骨干网络中,如ResNets[2]、RegNets[24]和视觉Transformers[25]、[26];2)延迟预测器作为一个现成的工具,可以立即应用于各种计算平台,如服务器端GPU(Tesla V100、RTX3090)、桌面级GPU(RTX3060)和边缘设备(Jetson TX2、Nvidia Nano)。我们评估了LAUDNet在多个骨干网络上的性能,包括图像分类、目标检测和实例分割。我们的结果表明,LAUDNet在理论和实践上都显著提高了深度CNN的效率。例如,ResNet-101在ImageNet[1]上的推理延迟在不同类型的GPU上(例如V100、RTX3090和TX2)减少了超过50%,而没有牺牲准确性。此外,我们的方法在低FLOPs场景中超过了各种轻量级网络。尽管这部分工作最初在会议版本[27]中发表,但本文在几个关键领域显著扩展了我们之前的工作:
- 提出了一个统一的动态推理框架。虽然初步论文[27]主要关注空间自适应计算,本文深入研究了两个额外的重要动态范式,特别是动态层跳过和通道跳过(图1和第3.1节)。此外,我们将这些范式整合到一个统一的框架中,并提供了更全面的架构设计和复杂性分析(第3.2节)。
- 延迟预测器已增强,以支持包括层跳过和通道跳过在内的更广泛的动态操作员集合(第3.3节)。此外,我们采用Nvidia Cutlass[28]来优化调度策略。硬件评估表明,我们的延迟预测器可以准确预测实际硬件上的延迟(图5)。
- LAUDNet框架已扩展以适应Transformers架构,如第3.2节所述。这一扩展显著增强了通过实现动态令牌跳过(空间自适应计算)、头部(通道)跳过和层跳过来优化延迟。这些改进显著扩大了LAUDNet的适用性。实证评估,如图10(c)和第4.3.2节所讨论的,为高效Transformers的设计提供了有价值的见解,支撑了框架的多功能性和有效性。
- 我们首次将批量推理纳入我们的动态操作员(第3.4节)。这一创新导致了更一致的预测结果和在GPU平台上增强的加速比(图8、12)。
- 我们对各种动态粒度(图9)和范式(图10、11、13、表2、3)进行了详尽的分析,涵盖了不同的视觉任务和平台,并在当代GPU如RTX3060和RTX3090上增加了评估。我们相信我们的结果将为研究人员和实践者提供宝贵的见解。
III. 方法
本节首先介绍三个动态推理范式的基本概念(第3.1节)。然后,我们提出了我们的LAUDNet框架的架构设计,该框架将这些范式统一在一个连贯的掩码和计算公式下(第3.2节)。接下来,我们解释了延迟预测模型(第3.3节),该模型指导确定粒度设置和调度优化(第3.4节)。最后,我们描述了我们的LAUDNet的训练策略(第3.5节)。
3.1 准备工作
空间自适应计算。现有的空间动态网络通常在CNN骨干网络的每个卷积块中包含一个掩码器Ms。给定一个输入x ∈ RH×W×C到一个块,其中H和W分别表示特征高度和宽度,C表示通道数。假设卷积步长为1,掩码器Ms以x为输入并生成一个二进制空间掩码Ms = Ms(x) ∈ {0, 1}H×W。Ms中的每个元素决定是否在相应的输出位置执行卷积操作。未选择的区域用跳跃连接[19]、[20]的值填充。在推理过程中,空间动态卷积的当前调度策略通常涉及三个步骤[52](图1(b)):1)收集,它沿着批量维度重新组织选定的像素(如果卷积核大小大于1×1,还需要邻居);2)计算,对收集的输入执行卷积;3)分散,将计算出的像素填充到输出特征的相应位置。与传统的在整个特征图上执行卷积相比,这种调度策略减少了计算,但增加了掩码生成和非连续内存访问的开销。因此,总体延迟甚至可能增加,特别是在动态卷积的粒度在像素级别(图6)时。动态层跳过[14]、[15]、[53]自适应地确定是否执行每个层或块,利用深度模型的结构冗余实现数据依赖的网络深度。动态层跳过的实现与空间自适应推理类似,但是使用标量0, 1决策变量Ml而不是空间H×W掩码。与空间自适应推理相比,层跳过提供了较少的灵活性但更规则的计算模式。此外,它通常不需要特殊的调度策略,因为原始的卷积操作保持不变。动态通道跳过[16]、[17]、[54]采用了一种更保守的方法来动态架构,与完全层跳过相比。它使用C维向量Mc ∈ {0, 1}C来自适应地确定卷积层的运行时宽度,C表示输出通道数。例如,仅当Mc_i = 1时,才计算第i个(1 ≤ i ≤ C)通道。动态通道跳过的调度通常需要收集卷积核,而不是像空间动态计算中那样收集特征像素(比较图2(b)和(c))。

3.2 LAUDNet架构
概述
我们在第3.1节中的分析表明,三种动态推理范式共享一个共同的"掩码和计算"方案,关键区别在于掩码的形状。利用这一洞见,我们提出了一个统一框架(图2),其中轻量级模块生成通道掩码 和空间/层掩码 。值得注意的是, 层跳过可以被视为空间自适应推理的特殊情况, 通过引入动态计算中的粒度概念来实现。
动态粒度
如第3.1节所述, 使用像素级动态卷积[19]、[20]、[21]对多核处理器上的实际加速提出了实质性挑战,因为非连续内存访问。为了解决这个问题,我们提出了优化动态计算的粒度。对于空间自适应推理,我们不是直接产生一个 掩码,而是首先生成一个低分辨率掩码 ,其中 是空间粒度。 中的每个元素决定对应 特征块的计算。例如,在第一阶段的ResNet中处理56×56特征。然后 的有效选择是 。然后, 掩码 上采样到 的大小。值得注意的是, 对应于像素级粒度[19]、[20]、[21],而 自然实现了层跳过。同样,我们为通道跳过引入了通道粒度 。 中的每个元素决定了 个特征通道的计算。每个块的空间粒度 和通道粒度 的选择将由我们的延迟预测器(第3.3节)指导,以平衡灵活性和效率。请注意,我们将通道掩码应用于块内的前两个卷积层。这种设计与各种骨干架构兼容, 包括那些具有任意瓶颈比或组卷积[24]的架构。
掩码器设计
我们为空间(层)和通道动态计算设计了不同的结构。如图3 (a) 所示, 空间掩码器使用自适应池化层将输入 下采样到 的大小, 然后是一个 卷积层产生软 logits 。对于通道掩码器, 我们使用一个 2 层MLP(图3(b))来产生通道跳过决策。给定输入通道 和目标掩码维度 ,我们将MLP中的隐藏单元设置为 ,其中 表示向下取整操作。附录C.1显示这种设计有效地减少了通道掩码器的延迟,特别是在具有更多通道的后期阶段。

计算复杂性
我们首先指出, 与骨干卷积相比, 掩码器的FLOPs可以忽略不计。因此, 我们主要分析标准卷积块的复杂性。对于空间自适应计算,我们定义激活比率 来表示计算像素的分数。遵循[20], 我们进一步计算 一个膨胀空间掩码的激活比率, 以表示块中第一个卷积的激活比率。我们的实验观察到 通常接近 。给定三个卷积层的FLOPs , 理论加速比是 。对 于 通 道 跳 过 , 激 活 比 率 是 。在3 3卷积之前和之后应用掩码使其复杂性与 成二次关系。整体加速比是 。
3.3 延迟预测器
如前所述,在不同硬件平台上评估动态操作员的延迟是一项繁琐的任务。为了有效地寻找任何目标设备上的首选动态范式和粒度设置,我们提出了一个延迟预测模型G。给定硬件属性H、层参数P、动态范式D、空间/通道粒度S/C和激活率rs/rc,G直接预测块执行延迟ℓ = G(H, P, D, S, C, rs, rc)。
硬件建模
我们用多个并行计算的处理引擎(PEs)来建模一个设备(图4)。内存系统有三个级别[58]:1)离芯片内存,2)芯片上的全局内存,以及3)PE中的内存。在实践中,延迟主要来自两个过程:数据移动和并行计算:
其中ℓConst是一个特定于硬件的常数。这个模型准确地预测了ℓdata和ℓcomputation,比FLOPs提供了更实际的效率度量。

延迟预测
给定硬件属性和模型参数,采用适当的调度策略是关键,以便通过增加并行性和减少内存访问来最大化资源利用。我们使用Nvidia Cutlass[28]来寻找动态操作的最优调度(平铺和PE内并行性配置)。数据移动延迟可以从数据形状和目标设备带宽轻松获得。此外,计算延迟从硬件属性中得出。更多细节请参考附录A。实证验证。我们使用RTX3090 GPU上的ResNet-101块评估我们的延迟预测器的性能,改变激活率r。蓝色曲线代表预测值,散点图是通过使用Nvidia Cutlass[28]寻找适当的调度策略(用自定义CUDA代码实现)获得的。测试了所有三种动态范式。图5比较了预测值和实际GPU测试延迟,显示出在广泛的激活率范围内的准确估计。

3.4 调度优化
我们使用一般优化方法,如将激活函数和批量归一化(BN)层融合到卷积层中。我们还包括以下优化我们的动态卷积块。空间掩码器的操作融合。如第3.2节所述,空间掩码器的计算可以忽略不计,但是它们以完整的特征图为输入,使它们受到内存限制(延迟主要由内存访问主导)。由于掩码器与第一个1×1卷积(图2(b)中的MaskerConv1×1)共享其输入,融合它们避免了重复的输入读取。然而,这使得卷积在空间上变为静态,可能会增加计算。为了简单起见,我们在所有测试模型中采用这种操作融合。实际上,我们发现操作融合在大多数情况下都有助于提高效率。收集和动态卷积的融合。传统方法首先收集块中第一个动态卷积的输入像素。收集操作也是一个受内存限制的操作。此外,当内核大小超过1×1时,输入补丁重叠,导致重复的加载/存储。我们将收集融合到动态卷积中以减少内存访问(图2(b)中的Gather-Conv3x3)。请注意,对于动态通道跳过(图2(c)),收集是在卷积核上进行的,而不是在特征上。我们的调度优化也将权重收集操作与卷积融合。融合分散和添加。传统方法在分散最终卷积输出之前进行元素-wise添加。我们将这两个操作融合在一起(图2(b)中的Scatter-Add),以减少内存访问成本。第4.2节的消融研究验证了所提出的融合方法的有效性。批量推理通过记录收集和分散期间的补丁、位置和样本对应关系来启用。使用更大的批量大小进行推理有助于并行计算,使延迟更多地依赖于计算而非内核启动或内存访问。附录C.1提供了实证分析。
3.5 训练
非可微掩码器的优化。掩码器模块为离散决策产生二进制变量,不能直接通过反向传播优化。遵循[20]、[21]、[23],我们采用直通Gumbel Softmax[55]、[56]进行端到端训练。以空间动态推理为例,让˜Ms ∈RH×W×2表示空间掩码生成器Ms的输出。决策是在推理期间使用argmax函数获得的。训练使用不同的Softmax近似:

其中τ是Softmax温度。类似地,通道掩码器Mc产生一个2C维向量˜Mc ∈ R2C,其中C是块中3×3卷积的通道数。我们首先将˜Mc重塑为C×2的大小,并沿第二维应用Gumbel Softmax以产生ˆMc ∈ [0, 1]C。遵循[20]、[23],我们让τ从5.0指数衰减到0.1以促进掩码器的优化。训练目标。如第3.2节所分析的,每个动态卷积块的FLOPs可以根据我们定义的激活率rs(或rc)计算。让Fdyn和Fstat分别表示整体动态和静态网络FLOPs。我们优化它们的比率以近似目标0 < t < 1:LFLOPs = (Fdyn / Fstat − t)^2。此外,我们定义Lbounds如[20]所述,以约束早期训练周期的上下界。我们进一步提出利用动态网络的静态对应物作为“教师”来指导优化过程。让y和y'分别表示动态“学生”模型和其静态“教师”的输出logits。我们的最终损失可以写成:

其中Ltask代表与任务相关的损失,例如分类中的交叉熵损失。KL(·||·)表示Kullback–Leibler散度,α、β是平衡这些项的系数。我们用σ表示log-Softmax函数,T是计算KL散度的温度。
IV. 实验
在本节中,我们首先介绍实验设置(第4.1节)。然后分析不同粒度设置的延迟(第4.2节)。进一步评估LAUDNet在ImageNet上的性能(第4.3节),随后是可视化结果(第4.4节)。我们最后在目标检测和实例分割任务上验证我们的方法(第4.5节)。为了简单起见,我们在模型名称前加上“LAUDs/c/l-”来表示我们的LAUDNet具有不同的动态范式(s代表空间,c代表通道,l代表层),例如LAUDs-ResNet-50。
4.1 实验配置
图像分类实验在ImageNet[1]数据集上进行。我们在五种代表性架构上实现我们的LAUDNet,涵盖了广泛的计算成本:四个CNN(ResNet-50, ResNet-101[2], RegNetY-400M, RegNetY-800M[24])和一个视觉Transformers,T2T-ViT[26]。CNN和Transformers使用不同的训练设置。对于CNN,按照[20]中建立的方法,我们从torchvision预训练检查点(https://pytorch.org/vision/stable/models.html)初始化骨干参数,并使用方程(3)中的损失函数微调整个网络100个周期。对于所有动态模型,我们固定α=10, β=0.5和T=4.0。请注意,我们采用预训练-微调范式主要是为了减少训练成本,因为Gumbel Softmax通常需要更长的训练时间才能收敛。对于T2T-ViT的研究,我们使用AdaViT[57]中描述的相同设置,并通过我们的延迟预测器评估其各种动态推理方法的效率。延迟预测。我们在各种类型的硬件平台上评估我们的LAUDNet,包括两个服务器GPU(Tesla V100和RTX3090)、一个桌面GPU(RTX3060)和两个边缘设备(例如,Jetson TX2和Nvidia Nano)。我们的延迟预测模型考虑的主要属性包括处理引擎的数量(#PE)、处理引擎中的浮点计算(#FP32)、频率和带宽。从表4可以看出,服务器GPU通常比IoT设备拥有更多的#PE。除非另有说明,否则V100、RTX3090和RTX3060 GPU的批量大小设置为128。在边缘设备TX2和Nano上,测试批量大小固定为1。更多细节请参见附录B。
4.2 延迟预测结果
本小节展示了使用两种不同的骨干网:ResNet-50[2](在V100上)和RegNetY-800MF[24](在TX2上)的动态卷积块的延迟预测结果。每个块都具有不同的通道数和卷积组的瓶颈结构,RegNetY采用Squeeze-and-Excitation (SE) [59]模块。我们定义ℓdyn作为动态卷积块的延迟,ℓstat作为静态块的延迟。两者的比率表示为rℓ = ℓdyn / ℓstat,当rℓ < 1时实现实际加速。空间粒度的影响。这里的主要目标是研究动态计算的粒度如何影响延迟比率rℓ。我们探索了不同粒度设置下rℓ与激活率rs(参见第3.2节)之间的关系。图6a(V100上的ResNet)和图6c(TX2上的RegNetY-800M)的结果表明:
- 尽管实施了我们的优化调度策略,像素级动态卷积(S=1)并不总是增强实际效率。这种细粒度自适应推理方法在以前的工作[20]、[21]、[60]中被采用。我们的发现有助于阐明为什么这些研究只在性能较低的CPU[21]或专用设备[60]上实现了实际加速;
- 相比之下,粗粒度设置(S > 1)在两个设备上显著缓解了这一问题。当S > 1时,可以在更大的激活值(rs)下获得实际加速(rℓ < 1)。

延迟预测结果进一步用于确定前三个阶段的首选空间粒度设置。注意,对于特征分辨率为7×7的最后阶段,S =1和S =7对应两种不同的动态范式(空间自适应推理和层跳过)。图6b(V100上的ResNet)和图6d(TX2上的RegNetY-800M)中rℓ与S之间的关系曲线揭示了以下内容:
- 对于给定的r,延迟比率rℓ通常随着S的增加而减少在V100上;
- 过大的S(表示适应性推理不够灵活)在两个设备上提供了微不足道的改进。特别是,在TX2上,将LAUD-RegNetY-800MF的第二阶段的S从7增加到14对效率产生了负面影响。这可能是由于过大的补丁大小在该设备上引起了额外的内存访问成本,该设备的处理引擎(PEs)较少;
- 层跳过(用⋆标记)始终优于空间动态计算(用•标记)。我们将在第4.3节和第4.5节中分析它们在不同视觉任务中的性能。
基于这些结果,我们可以通过为不同的模型和设备选择适当的S来在灵活性和效率之间取得平衡。例如,我们可以简单地将Snet设置为44-2-13,以实现LAUDs-ResNet-50的实际加速。
通道粒度的影响。我们进一步研究通道粒度G对通道跳过动态模型的实际延迟的影响。以LAUDc-ResNet为例,图7中的结果表明通道跳过的性能对通道粒度G不太敏感。在更深的阶段,将G设置为2可以提高效率,而将G扩展到2以上则收益递减。这与我们的理解相符,即通道跳过需要比空间稀疏卷积更规则的操作,意味着G = 1已经可以产生显著的加速。此外,图7a中的曲线通常是凸的,因为3 × 3卷积的计算与rc呈二次关系(第3.2节)。操作融合的消融研究。在探索我们操作融合的影响时,如第3.4节所述,我们关注LAUDs-ResNet-50的初始阶段的卷积块(S=4, rs=0.6)作为案例研究。发现,如表1所示,操作融合在不同计算环境中一致有助于降低实际延迟,通过最小化内存访问开销。值得注意的是,掩码器和第一个卷积的融合在服务器端V100上显著降低了延迟。相比之下,在边缘设备TX2上,结合散射和添加操作在降低延迟中发挥了关键作用。


批量大小的消融研究。为了建立合适的测试批量大小,我们为LAUD-ResNet-50绘制了每图像延迟与批量大小之间的关系图(见图8),测试了两个服务器端GPU(V100和RTX3090)。结果突出显示,随着批量大小的增加,延迟减少,当批量大小超过128时,在两个平台上延迟达到稳定平台。这是可以理解的,因为更大的批量大小有利于增强计算并行性,使延迟更多地依赖于理论计算。桌面级GPU RTX3060(图12,附录C.1)的结果也显示了类似的现象。基于这些观察,我们在此后的报告中使用服务器端和桌面级GPU上的批量大小128的延迟。

4.3 ImageNet 分类4.3.1 空间/通道粒度的对比
我们首先比较空间和通道动态计算的不同粒度。基于第4.2节的分析, 空间和通道粒度的候选者分别为 和 。我们选择ResNet-50和RegNetY-800M作为骨干网,并在TX2和V100上比较各种设置。图9的结果表明:
- 关于空间动态计算,最优粒度Snet取决于网络结构和硬件设备。例如,Snet=8-4-7-1在V100上对两个模型都实现了更好的性能,但在TX2上却造成了大量效率低下。这与我们在图6中的结果相符;
- 将通道粒度G从1提高到2确实为ResNet-50提供了一定程度的加速,但在RegNetY-800M的情况下性能相当。我们假设更大的G只对具有更多通道数的模型有益,这也与图7中的观察结果一致。
- 4.3.2 动态范式比较
在确定了最优粒度之后,我们将不同的动态范式进行更详细的比较。此外,我们的LAUDNet与各种竞争基线进行比较。结果如图10所示。标准基线比较:ResNets。比较的基线包括各种类型的动态推理方法:1)层跳过(SkipNet [14]和Conv-AIG [15]);2)通道跳过(BAS [17]);3)像素级空间动态网络(DynConv [20])。对于我们的LAUDNet,我们为空间动态和通道动态推理选择了最佳粒度设置。我们还包括了在框架中实现的层跳过。我们为动态模型设置了训练目标(参见第3.5节)t ∈ {0, 4, · · · , 0.8},以评估它们在不同稀疏性下的性能。我们统一应用调度优化(第3.4节)[15]、[20],以进行公平比较。结果在图10(a)中展示。我们在左侧绘制了准确性与FLOPs之间的关系图。很明显,我们的LAUD-ResNets,具有各种粒度设置,大大超过了竞争动态网络。此外,在ResNet-101上,三种范式看起来相当可比,而在ResNet-50上,层跳过落后,特别是当训练目标很小的时候。这是可以理解的,因为层跳过对于更浅的模型可能过于激进。有趣的是,当我们探索实际延迟时(TX2上的中间和V100上的右侧),情况发生了变化。在性能较低的TX2上,延迟通常与理论FLOPs显示出更强的相关性,因为在这种IoT设备上它是计算受限的(即,延迟主要围绕计算)。然而,在服务器端GPU V100上,不同的动态范式产生了不同的加速影响,因为延迟可能受到内存访问成本的影响。例如,在更深的ResNet-101上,层跳过优于其他两种范式。在目标激活率为t = 0.4时,我们的LAUDl-ResNet-101将其静态对应物的推理延迟减少了约53%。在较浅的ResNet-50上,通道跳过在一些低FLOPs模型上与层跳过保持同步。尽管我们提出的粗粒度空间自适应推理落后于其他两种方案,但它明显优于使用像素级动态计算的先前工作[20]。附录C.2中的额外结果也展示了层跳在RTX3060和RTX3090上的优势。通道跳过仅在边缘设备Nvidia Nano上优于其他两种范式。轻量级基线比较:RegNets。我们进一步在轻量级CNN架构中评估我们的LAUDNet,即RegNets-Y[24]。测试了两个不同大小的模型:RegNetY-400MF和RegNetY-800MF。比较的基线包括其他类型的高效模型,例如MobileNets-v2[30]、ShuffletNets-v2[32]和CondenseNets[35]。结果在图10(b)中展示。我们观察到,尽管通道跳过在准确性-FLOPs权衡中大大超过了其他两种范式,但在大多数模型上它不如层跳过高效,除了RegNetY-800M。值得注意的是,层跳过成为了最占优势的范式。我们认为,这是因为RegNet-Y的模型宽度(通道数)有限,推理延迟仍受内存访问限制。此外,层跳过能够跳过内存受限的SE操作[59]。桌面级和服务器端GPU(附录C.2)的结果进一步展示了层跳过的优势。在视觉Transformers上的实验。基于第3.2节的基础,我们的LAUDNet可以无缝地使用AdaViT[57]框架与视觉Transformers集成。尽管现有研究中没有直接比较三种动态范式,[57]同时使用了所有三种,留下了哪种范式在准确性和效率之间提供最佳平衡的问题。我们通过展示LAUD-T2T-ViT在各种平台(TX2、RTX3060和V100)上的准确性-延迟权衡曲线来解决这个问题(RTX3090上的性能与V100相似)-图10(c)。发现几个关键见解:
- 层跳过和头部(通道)跳过在高激活率时更有利于保持高准确性,尽管两者在降低激活率时都会经历显著的准确性下降。
- 当评估实际延迟和准确性之间的平衡时,层跳过在所有平台上始终优于头部(通道)跳过。
- 尽管理论上的准确性上限较低,空间自适应计算(令牌跳过)可能在较低激活率时超过其他范式,这归因于在GPU上执行索引和选择操作的实际延迟优势,而无需像CNN中那样需要专门的操作。
- 综合应用所有三种范式进一步提升了准确性-效率权衡,展示了每种方法的互补优势。
4.4 可视化和可解释性
我们呈现了LAUDNet的可视化结果,从网络结构冗余和图像空间冗余的角度深入探讨其可解释性。激活率。图11(a)显示了LAUDs/c/l-ResNet-101(t=0.5)在ImageNet验证集上每个块的平均激活率rs/c/l。结果揭示了:
- 空间动态卷积和层跳过的激活率模式相似。激活率rs和rl在第1、2和4阶段似乎更加二值化(接近0或1)。动态区域/层选择主要发生在第3阶段;
- 这两种范式倾向于在第2、3和4阶段的第一个块中保持整个特征图(rs/l=1.0),其中卷积步长为1。这与[15]、[54]中的设置一致,这些研究中这些块的训练目标手动设置为1。值得注意的是,我们训练我们的LAUDNet以满足整体计算目标,而不是像[15]、[54]那样限制不同块的目标;
- 通道跳过导致的激活率在整个网络中更集中在0.5左右。
动态补丁选择。我们在图11(b)中可视化了LAUDs-ResNet-101(Snet=4-4-2-1)的第三块生成的空间掩码。突出显示的区域表示掩码中1元素的位置,而暗淡区域的计算被我们的动态模型跳过。很明显,掩码器擅长定位与任务相关的区域,甚至是图像角落的小型飞机等细节,从而减少了背景区域的不必要计算。这些发现意味着,S=4的粒度足够灵活,能够识别关键区域,为准确性和效率之间的和谐平衡铺平了道路。有趣的是,掩码器能够挑选出未标记的物体-例如,蜂鸟旁边的花或紧握相机的人。这表明我们的空间动态网络能够识别富含语义的区域,其能力不受分类标签的限制。这种特性对于一系列下游任务来说是无价的,如目标检测和实例分割(第4.5节),这些任务需要在图像中识别多个类别和对象。有关更多可视化结果,读者可参考附录C.3。
4.5 密集的预测任务
我们的LAUDNet进一步在下游任务上进行测试,即COCO[61]目标检测(见表2)和实例分割(见表3)。对于目标检测,平均精度均值(mAP)作为网络效能的衡量标准。对于实例分割,APmask进一步深入测量密集预测的细微差别。平均骨干FLOPs和验证集上的平均骨干延迟用于测量网络效率。由于LAUDNet的多功能性,我们可以无缝替换各种检测和分割框架中的骨干网络,用我们在ImageNet上的预训练模型,然后在COCO数据集上进行微调,标准协议为12个周期-除了基于Mask2Former[62]的模型,这些模型按照基线配置训练50个周期(详细设置在附录B.3中详细说明)。在目标检测领域,我们的实验涵盖了三个框架:带有特征金字塔网络[64]的两阶段Faster R-CNN[63]、单阶段RetinaNet[65]和基于DETR的模型,即Dense Distinct Query (DDQ)-DETR[67]。我们将结果与一系列最新进展进行比较,如Deformable DETR[68]、DINO-DETR[69]、RankDETR[70]和Stable-DINO[71]。对于实例分割,我们使用成熟的Mask R-CNN[72]和基于查询的Mask2Former[62]。结果在表2(目标检测)和表3(实例分割)中展示,明确表明LAUDNet在经典和最先进的(SOTA)框架中持续提高mAP和效率。值得注意的是,尽管通道跳过和层跳过通常在效率上超过了空间动态计算,但理想的动态范式可能因具体检测框架、骨干架构和硬件平台而异。


5 结论
在本文中,我们提出了在延迟预测模型的指导下构建延迟感知统一动态网络(LAUDNet)。通过综合考虑算法、调度策略和硬件属性,我们可以准确估计不同动态操作员在任何计算平台上的实际延迟。基于对空间和通道自适应推理粒度与延迟之间相关性的实证分析,优化了算法和调度策略,以在一系列多核处理器上实现实际加速,如Tesla V100和Jetson TX2。我们在图像分类、目标检测和实例分割任务上的实验证实,所提出的方法显著提高了深度CNN的实际效率,并超过了众多竞争方法。我们相信我们的研究为动态网络的设计提供了有用的见解。未来的工作包括探索更多类型的模型架构(例如Transformers、大型语言模型)和任务(例如低级视觉任务和视觉-语言任务)。