OpenSPG/KAG V0.7发布,多方面优化提升,事实推理效果领先且构建成本降至11%
总体摘要
我们正式发布KAG 0.7版本,本次更新旨在持续提升大模型利用知识库推理问答的一致性、严谨性和精准性,并引入了多项重要功能特性。
首先,我们对框架进行了全面重构。新增了对static和iterative两种任务规划模式的支持,同时实现了更严谨的推理阶段知识分层机制。此外,新增的multi-executor扩展机制以及MCP协议的接入,使用户能够横向扩展多种符号求解器(如math-executor和cypher-executor等)。这些改进不仅帮助用户快速搭建外挂知识库应用以验证创新想法或领域解决方案,还支持用户持续优化KAG Solver的能力,从而进一步提升垂直领域应用的推理严谨性。
其次,我们对产品体验进行了全面优化:在推理阶段新增"简易模式"和"深度推理"双模式,并支持流式推理输出,显著缩短了用户等待时间;特别值得关注的是,为更好的促进KAG的规模化业务应用,同时也回应社区最为关切的知识构建成本高的问题,本次发布提供了"轻量级构建"模式,如图1中KAG-V0.7LC列所示,我们测试了7B模型做知识构建、72B模型做知识问答的混合方案,在two_wiki、hotpotqa和musique三个榜单上的效果仅小幅下降1.20%、1.90%和3.11%,但十万字文档的构建token成本(参考阿里云百炼定价)从4.63¥减少到0.479¥, 降低89%,可大幅节约用户的时间和资金成本;我们还将发布KAG专用抽取模型和分布式离线批量构建版本,持续压缩模型尺寸提升构建吞吐,以实现单场景百万级甚至千万级文档的日构建能力。
最后,为了更好地推动大模型外挂知识库的业务应用、技术进步和社区交流,我们在KAG仓库的一级目录中新增了open_benchmark目录。该目录内置了各数据集的复现方法,帮助用户复现并提升KAG在各类任务上的效果。未来,我们将持续扩充更多垂直场景的任务数据集,为用户提供更丰富的资源。
除了上述框架和产品优化外,我们还修复了推理和构建阶段的若干Bug。本次更新以Qwen2.5-72B为基础模型,完成了各RAG框架及部分KG数据集的效果对齐。发布的整体榜单效果可参考图1和图2,榜单细节详见open_benchmark部分。
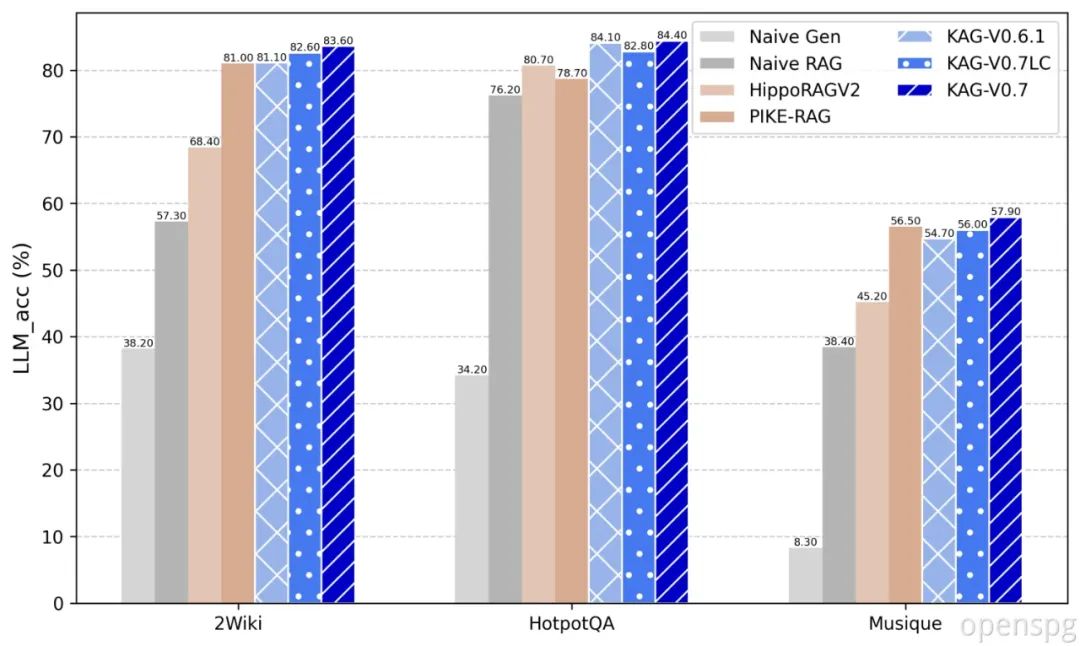
图1 Performance of KAG V0.7 and baselines on Multi-hop QA benchmarks
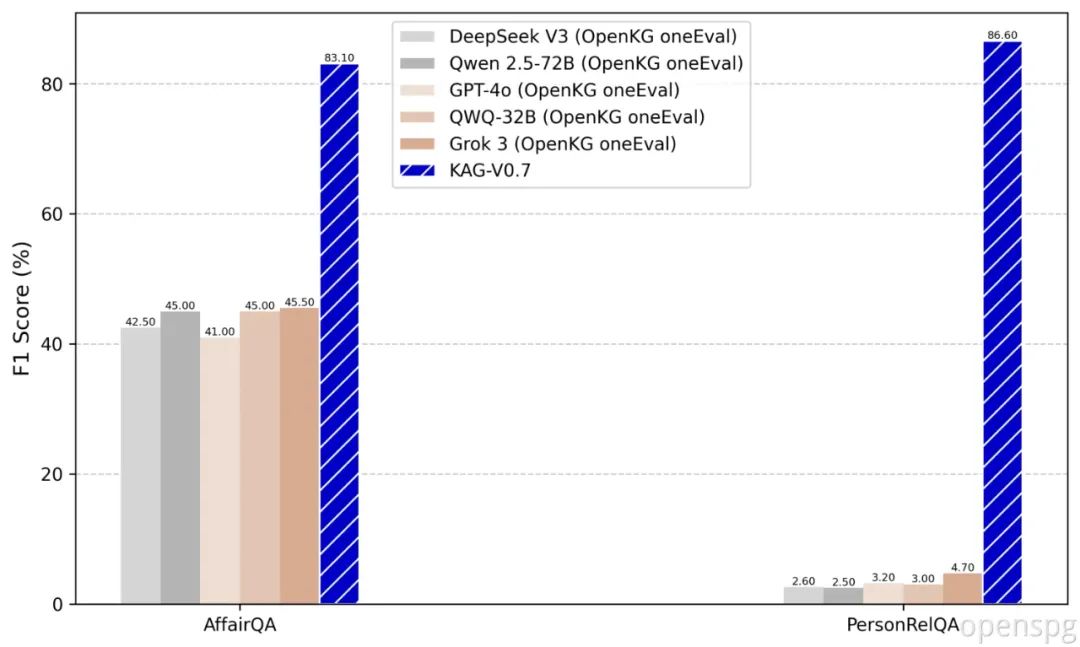
图2 Performance of KAG V0.7 and baselines(from OpenKG OneEval) on Knowledge based
QA benchmarks
框架优化
1.静态与动态结合的任务规划
本次发布对KAG-Solver框架的实现进行了优化,为“边推理边检索”、“多场景算法实验”以及“大模型与符号引擎结合(基于MCP协议)”提供了更加灵活的框架支持。
通过Static/Iterative Planner,复杂问题可以被转换为多个Executor之间的有向无环图(DAG),并根据依赖关系逐步求解。框架内置了Static/Iterative Planner的Pipeline实现,并预定义了NaiveRAG Pipeline,方便开发者灵活自定义求解链路。
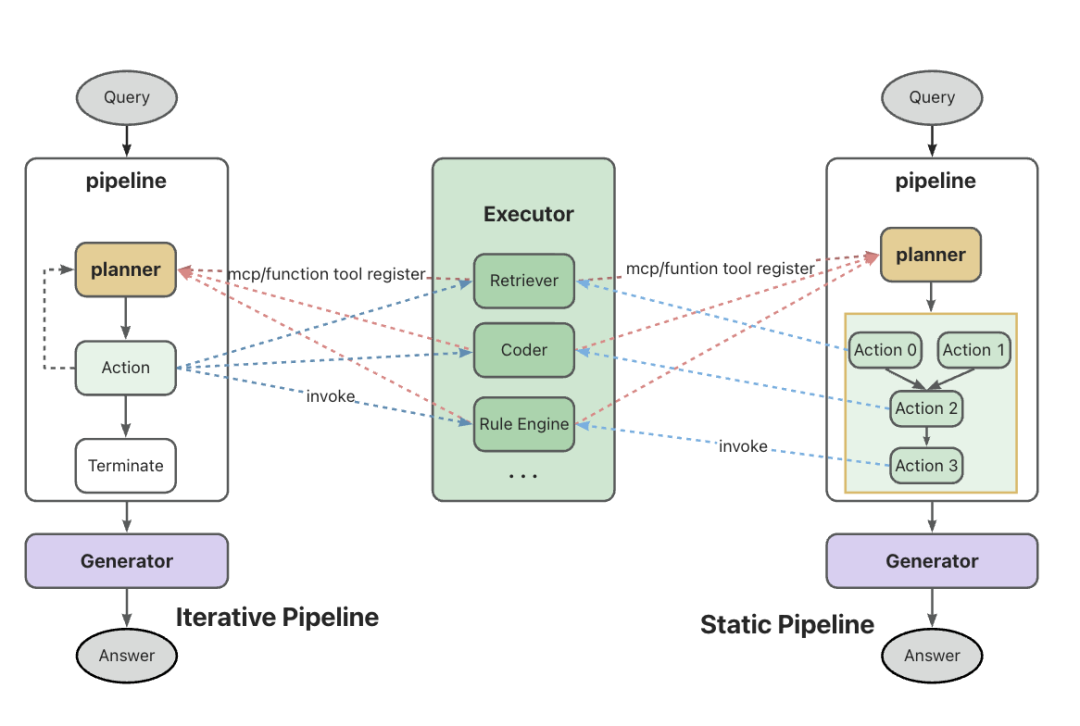
2.支持可扩展的符号求解器
基于LLM对FunctionCall的支持,我们优化了符号求解器(Executor)的设计,使其在复杂问题规划时能够更合理地匹配相应的求解器。本次更新内置了kag_hybrid_executor、math_executor、cypher_executor等求解器,同时提供了灵活的扩展机制,支持开发者定义新的求解器以满足个性化需求。
3.显性知识分层及分层检索、推理策略优化
基于优化后的KAG-Solver框架,我们重写了kag_hybrid_executor的逻辑,实现了更严谨的推理阶段知识分层机制。根据业务场景对知识精准性的要求,按照KAG的知识分层定义,依次检索三层知识:(基于schema-constraint)、
(基于schema-free)和
(原始上下文),并在此基础上进行推理生成答案
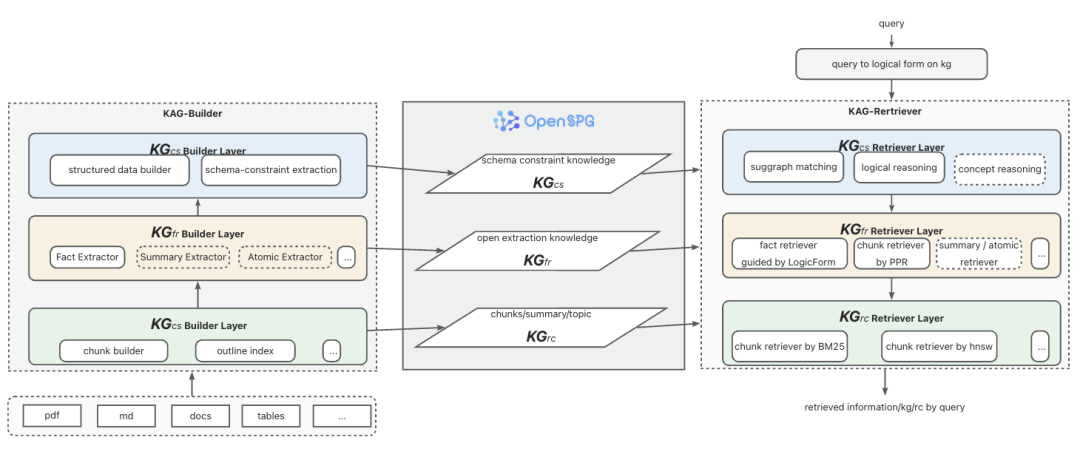
4.拥抱MCP协议
KAG本次发版实现了对MCP协议的兼容,支持在KAG框架中通过MCP协议引入外部数据源和外部符号求解器。在example目录中,我们内置了baidu_map_mcp示例,供开发者参考使用。
OpenBenchmark
为更好地促进学术交流,加速大模型外挂知识库在企业中的落地和技术进步,KAG在本次发版中发布了更详细的Benchmark复现步骤,并开源了全部代码和数据。这将方便开发者和科研人员复现并对齐各数据集的结果。为了更准确地量化推理效果,我们采用了EM(Exact Match)、F1和LLM_Accuracy等多项评估指标。在原有TwoWiki、Musique、HotpotQA等数据集的基础上,本次更新新增了OpenKG OneEval知识图谱类问答数据集(如AffairQA和PRQA),以分别验证cypher_executor及KAG默认框架的能力。
搭建Benchmark是一个耗时且复杂的工程。在未来的工作中,我们将持续扩充更多Benchmark数据集,并提供针对不同领域的解决方案,进一步提升大模型利用外部知识的准确性、严谨性和一致性。我们也诚邀社区同仁共同参与,携手推进KAG框架在各类任务中的能力提升与实际应用落地。
1.多跳事实问答数据集
1.1 benchMark
- musique
| Method | EM | F1 | llm_accuracy |
| Naive Gen | 0.033 | 0.074 | 0.083 |
| Naive RAG | 0.248 | 0.357 | 0.384 |
| HippoRAGV2 | 0.289 | 0.404 | 0.452 |
| PIKE-RAG | 0.383 | 0.498 | 0.565 |
| KAG-V0.6.1 | 0.363 | 0.481 | 0.547 |
| KAG-V0.7LC | 0.379 | 0.513 | 0.560 |
| KAG-V0.7 | 0.385 | 0.520 | 0.579 |
- hotpotqa
| Method | EM | F1 | llm_accuracy |
| Naive Gen | 0.223 | 0.313 | 0.342 |
| Naive RAG | 0.566 | 0.704 | 0.762 |
| HippoRAGV2 | 0.557 | 0.694 | 0.807 |
| PIKE-RAG | 0.558 | 0.686 | 0.787 |
| KAG-V0.6.1 | 0.599 | 0.745 | 0.841 |
| KAG-V0.7LC | 0.600 | 0.744 | 0.828 |
| KAG-V0.7L | 0.603 | 0.748 | 0.844 |
- twowiki
| Method | EM | F1 | llm_accuracy |
| Naive Gen | 0.199 | 0.310 | 0.382 |
| Naive RAG | 0.448 | 0.512 | 0.573 |
| HippoRAGV2 | 0.542 | 0.618 | 0.684 |
| PIKE-RAG | 0.63 | 0.72 | 0.81 |
| KAG-V0.6.1 | 0.666 | 0.755 | 0.811 |
| KAG-V0.7LC | 0.683 | 0.769 | 0.826 |
| KAG-V0.7 | 0.684 | 0.770 | 0.836 |
1.2 各种方法的参数配置
| Method | 数据集 | 基模(构建/推理) | 向量模型 | 参数设置 |
| Naive Gen | hippoRAG 论文提供的1万 docs、1千 questions; | qwen2.5-72B | bge-m3 | 无 |
| Naive RAG | 同上 | qwen2.5-72B | bge-m3 | num_docs: 10 |
| HippoRAGV2 | 同上 | qwen2.5-72B | bge-m3 | retrieval_top_k=200 linking_top_k=5 max_qa_steps=3 qa_top_k=5 graph_type=facts_and_sim_passage_node_unidirectional embedding_batch_size=8 |
| PIKE-RAG | 同上 | qwen2.5-72B | bge-m3 | tagging_llm_temperature: 0.7 qa_llm_temperature: 0.0 chunk_retrieve_k: 8 chunk_retrieve_score_threshold: 0.5 atom_retrieve_k: 16 atomic_retrieve_score_threshold: 0.2 max_num_question: 5 num_parallel: 5 |
| KAG-V0.6.1 | 同上 | qwen2.5-72B | bge-m3 | 参见https://github.com/OpenSPG/KAG/tree/v0.6 examples 各子目录的kag_config.yaml |
| KAG-V0.7LC | 同上 | 构建:qwen2.5-7B 问答:qwen2.5-72B | bge-m3 | 参见https://github.com/OpenSPG/KAG open_benchmarks 各子目录kag_config.yaml |
| KAG-V0.7 | 同上 | qwen2.5-72B | bge-m3 | 参见https://github.com/OpenSPG/KAG open_benchmarks 各子目录kag_config.yaml |
2.结构化数据集
PeopleRelQA(人物关系问答) 和 AffairQA(政务问答) 分别是OpenKG OneEval榜单上阿里云天池大赛和浙江大学提供的数据集。KAG通过“语义化建模 + 结构化构图 + NL2Cypher检索”的方式,为垂直领域应用提供了一个简洁的落地范式。未来,我们将围绕大模型与知识引擎的结合,持续优化结构化数据问答的效果。
OpenKG OneEval 榜单的重点在于评估大语言模型(LLM)对各类知识的理解与运用能力。参考OpenKG官方描述,该榜单在知识检索方面采用了较为简单的策略,引入了较多噪声。KAG在这些场景中的指标提升得益于有效的检索策略保证了检索结果与问题之间的相关性。
本次更新中,KAG在AffairQA和PRQA数据集上验证了其针对传统知识图谱类任务的检索与推理能力。未来,KAG将进一步推动Schema的标准化和推理框架的对齐,并发布更多测试指标以支持更广泛的应用场景。
- PeopleRelQA(人物关系问答)
| Method | EM | F1 | llm_accuracy | 方法论 | 指标 来源 |
| deepseek-v3 (OpenKG oneEval)) | - | 2.60% | - | Dense Retrieval+LLM Generation |
|
| qwen2.5-72B (OpenKG oneEval) | - | 2.50% | - | Dense Retrieval+LLM Generation |
|
| GPT-4o (OpenKG oneEval) | - | 3.20% | - | Dense Retrieval+LLM Generation |
|
| QWQ-32B (OpenKG oneEval) | - | 3.00% | - | Dense Retrieval+LLM Generation |
|
| Grok 3 (OpenKG oneEval) | - | 4.70% | - | Dense Retrieval+LLM Generation |
|
| KAG-V0.7 | 45.5% | 86.6% | 84.8% | 基于KAG 框架自定义AffairQA pipeline+ cypher_solver | 蚂蚁KAG 团队 |
- AffairQA(政务信息问答)
| Method | EM | F1 | llm_accuracy | 方法论 | 指标提供者 |
| deepseek-v3 | - | 42.50% | - | Dense Retrieval + LLM Generation |
|
| qwen2.5-72B | - | 45.00% | - | Dense Retrieval + LLM Generation |
|
| GPT-4o | - | 41.00% | - | Dense Retrieval + LLM Generation |
|
| QWQ-32B | - | 45.00% | - | Dense Retrieval + LLM Generation |
|
| Grok 3 | - | 45.50% | - | Dense Retrieval + LLM Generation |
|
| KAG-V0.7 | 77.5% | 83.1% | 88.2% | 基于KAG 框架自定义AffairQA pipeline | 蚂蚁KAG 团队 |
产品及平台优化
本次更新优化了知识问答的产品体验,用户可访问 KAG 用户手册,在快速开始->产品模式一节,获取我们的语料文件以复现以下视频中的结果。
- 知识构建Demo
知识构建demo
- 知识问答Demo
知识问答Demo
1.问答体验优化
通过优化KAG-Solver框架的规划、执行与生成功能,基于Qwen2.5-72B和DeepSeek-V3模型的应用,可实现与DeepSeek-R1相当的深度推理效果。在此基础上,产品新增三项能力:支持推理结果的流式动态输出、实现Markdown格式的图索引自动渲染,以及生成内容与原始文献引用的智能关联功能。
2.支持深度推理与普通检索
新增深度推理开关功能,用户可根据需求灵活启用或关闭,以平衡回答准确率与计算资源消耗;联网搜索的能力当前测试中,请关注KAG框架的后续版本更新。
3.索引构建能力完善
本次更新提升结构化数据导入能力,支持从 CSV、ODPS、SLS 等多种数据源导入结构化数据,优化数据加载流程,提升使用体验;可同时处理"结构化"和"非结构化"数据,满足多样性需求。同时,增强了知识构建的任务管理能力,提供任务调度、执行日志、数据抽样 等功能,便于问题追踪与分析。
后续计划
近期版本迭代中,我们持续致力于持续提升大模型利用外部知识库的能力,实现大模型与符号知识的双向增强和有机融合,不断提升专业场景推理问答的事实性、严谨性和一致性等,我们也将持续发布,不断提升能力的上限,不断推进垂直领域的落地。
致谢
本次发布修复了分层检索模块中的若干问题,在此特别感谢反馈这些问题的社区开发者们。
此次框架升级得到了以下专家和同仁的鼎力支持,我们深表感激:
- 同济大学:王昊奋教授、王萌教授
- 中科院计算所:白龙博士
- 湖南科创信息:研发专家刘玲
- 开源社区:资深开发者李云鹏
- 交通银行:研发工程师高晨星
目前 KAG 还处于早期阶段,诚邀对知识服务和知识图谱技术感兴趣的用户和开发者加入我们,共建新一代 AI 引擎框架。我们建立了 OpenSPG 技术交流群,欢迎大家添加小助手微信加入:jqzn-robot。
GitHub
1、OpenSPG github 地址:https://github.com/OpenSPG/openspg
2、KAG github 地址:https://github.com/OpenSPG/KAG
3、KAG 官网文档:https://openspg.github.io/v2/
OpenSPG 和KAG 关系:OpenSPG 是语义增强的可编程知识图谱,KAG 是一个知识增强生成的专业领域知识服务框架,KAG 依赖 OpenSPG 提供的引擎依赖适配、知识索引、逻辑推理等能力。
🌟 欢迎大家 Star 关注~
蚂蚁集团-基础智能-知识引擎团队