【学习笔记】Py网络爬虫学习记录(更新中)
目录
一、入门实践——爬取百度网页
二、网络基础知识
1、两种渲染方式
2、HTTP解析
三、Request入门
1、get方式 - 百度搜索/豆瓣电影排行
2、post方式 - 百度翻译
四、数据解析提取三种方式
1、re正则表达式解析
(1)常用元字符
(2)常用量词
(3)贪婪匹配和惰性匹配
(4)re模块
(5)re实战1:自定义爬取豆瓣排行榜
(6)re实战2:爬取电影天堂
一、入门实践——爬取百度网页
from urllib.request import urlopenurl = "http://www.baidu.com"
resp = urlopen(url)with open("mybaidu.html", mode="w",encoding="utf-8") as f:# 使用with语句打开(或创建)一个名为"mybaidu.html"的文件# 打开模式为写入("w"),编码为UTF - 8("utf-8")# 文件对象被赋值给变量f# with语句确保文件在代码块结束后会自动关闭f.write(resp.read().decode("utf-8"))
这段代码的功能是从百度首页获取HTML内容,并将其保存到本地文件"mybaidu.html"中
爬取结果 ↓(被禁了哈哈)

二、网络基础知识
1、两种渲染方式
服务器渲染:
- 在服务器就直接把数据和html整合在一起,统一返回给浏览器在页面源代码中能看到数据
客户端渲染:
- 第一次请求只要一个html骨架
- 第二次请求拿到数据,进行数据展示在页面源代码中,看不到数据
2、HTTP解析
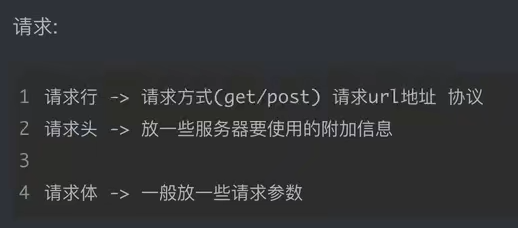
请求头中最常见重要内容(爬虫需要)
- User-Agent身份标识:请求载体的身份标识(用啥发送的请求)
- Referer防盗链:(这次请求是从哪个页面来的?反爬会用到)
- cookie:本地字符串数据信息(用户登录信息,反爬的token)
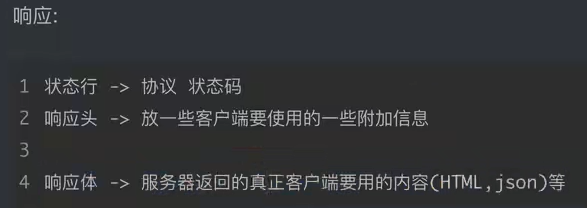
响应头中一些重要的内容
- cookie:本地字符串数据信息(用户登录信息,反爬的token)
- 各种莫名其妙的字符串(这个需要经验了,一般都是token字样,防止各种攻击和反爬)
三、Request入门
1、get方式 - 百度搜索/豆瓣电影排行
import requests
query = input("请输入想查询的内容!")
url = f"https://www.baidu.com/s?wd={query}"resp = requests.get(url)dic = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.2081 SLBChan/103 SLBVPV/64-bit"
}resp = requests.get(url=url, headers=dic) #伪装成浏览器
print(resp.text)
resp.close()
爬了一下百度,成功啦!
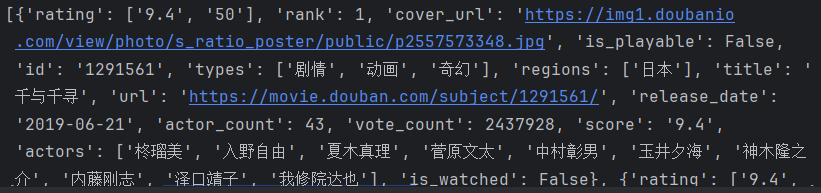
import requestsurl = f"https://movie.douban.com/j/chart/top_list"parm= {"type": 25,"interval_id": "100:90","action":"","start": 0,"limit": 20,
}dic={
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.2081 SLBChan/103 SLBVPV/64-bit"
}resp = requests.get(url=url,params=parm,headers=dic)
print(resp.json())
resp.close()
2、post方式 - 百度翻译
发送post请求,发送的数据必须放在字典里,通过data参数进行传递
import requests
s = input("请输入想查询的内容!")
url = f"https://fanyi.baidu.com/sug"dat = {"kw":s
}
resp = requests.get(url)#发送post请求,发送的数据必须放在字典里,通过data参数进行传递
resp = requests.post(url=url,data=dat)
print(resp.json())
resp.close()

四、数据解析提取三种方式
上述内容算入门了抓取整个网页的基本技能,但大多数情况下,我们并不需要整个网页的内容,只是需要那么一小部分,这就涉及到了数据提取的问题。
三种解析方式:
- re解析
- bs4解析
- xpath解析
1、re正则表达式解析
正则表达式是一种使用表达式的方式对字符串进行匹配的语法规则
抓取到的网页源代码本质上就是一个超长的字符串,想从里面提取内容,用正则再合适不过
在线正则表达式测试
(1)常用元字符
. 匹配除换行符以外的任意字符 \w 匹配字母或数字或下划线 \s 匹配任意的空白符 \d 匹配数字 \n 匹配一个换行符 \t 匹配一个制表符 ^ 匹配字符串的开始 $ 匹配字符串的结尾 \W 匹配非字母或数字或下划线 \D
匹配非数字 \S 匹配非空白符 a|b 匹配字符a或字符b () 匹配括号内的表达式,也表示一个组 [...] 匹配字符组中的字符 [a-zA-Z0-9] [^...] 匹配除了字符组中字符的所有字符
(2)常用量词
* 重复零次或更多次 + 重复一次或更多次 ? 重复零次或一次 {n} 重复n次 {n,} 重复n次或更多次 {n,m} 重复n到m次
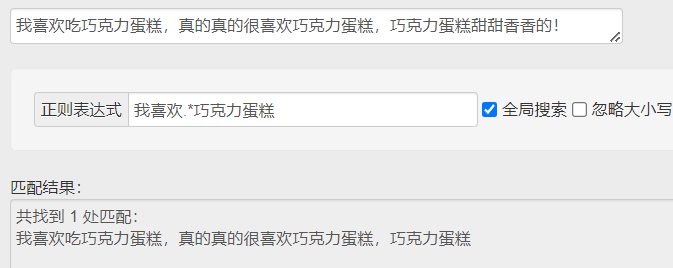
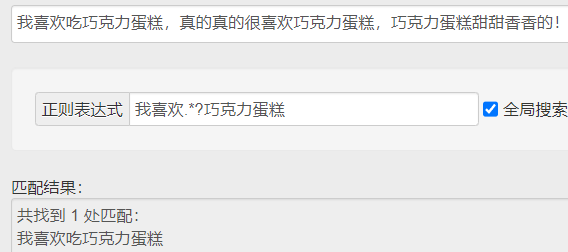
(3)贪婪匹配和惰性匹配
.* 贪婪匹配(尽可能多的匹配) .*? 惰性匹配(尽可能少的匹配)
↑ 贪婪匹配就是尽可能长地匹配
↑ 惰性匹配就是尽可能短地匹配
(4)re模块
- findall:匹配字符串中所有符合正则的内容
- finditer:匹配字符串中所有内容【返回的是迭代器】,从迭代器中拿到内容要.group
import re#findall:匹配字符串中所有符合正则的内容 list = re.findall(r"\d+","我的学号是20250102,他的学号是20240105") print(list)#finditer:匹配字符串中所有内容【返回的是迭代器】,从迭代器中拿到内容要.group it = re.finditer(r"\d+","我的学号是20250102,他的学号是20240105") for i in it:print(i.group())
- search:找到一个结果就返回,返回的结果是match对象,拿数据要.group()
- match:从头开始匹配
- 预加载正则表达式
import re#search:找到一个结果就返回,返回的结果是match对象,拿数据要.group() s = re.search(r"\d+","我的学号是20250102,他的学号是20240105") print(s.group())#match:从头开始匹配 m = re.search(r"\d+","20250102,他的学号是20240105") print(s.group())#预加载正则表达式 obj = re.compile(r"\d+") #相对于把头写好,后面直接补上字符串 ret = obj.finditer("我的学号是20250102,他的学号是20240105") for i in ret:print(i.group())
- ?P<起的别名>正则表达式:给提取的内容起别名,例如?P<name>.*?,给.*?匹配到的内容起别名name
s = """ <div class='cat'><span id='1'>凯蒂猫</span></div> <div class='dog'><span id='2'>史努比</span></div> <div class='mouse'><span id='3'>杰瑞</span></div> <div class='fish'><span id='4'>小鲤鱼</span></div> """obj = re.compile(r"<div class='(?P<class>.*?)'><span id='(?P<id>.*?)'>(?P<name>.*?)</span></div>",re.S) #re.S:让.能匹配换行符 result = obj.finditer(s) for it in result:print(it.group("id") +" "+ it.group("class") +" "+ it.group("name"))
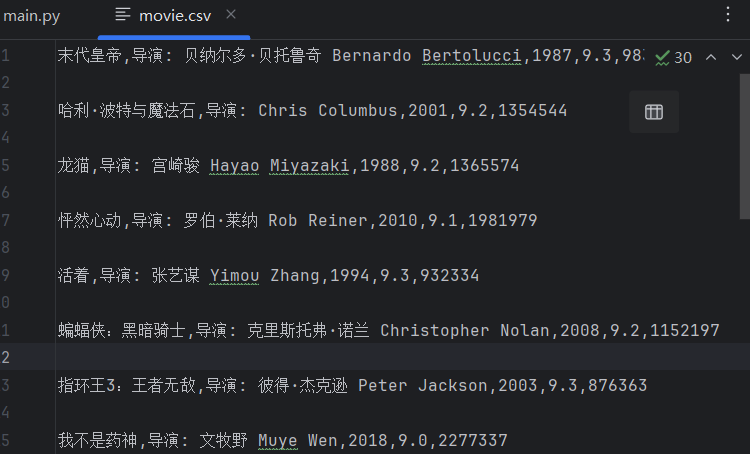
(5)re实战1:自定义爬取豆瓣排行榜
通过request拿到页面源代码,用re正则匹配提取数据

import re
import csv
import requests#request获取页面源代码
url = "https://movie.douban.com/top250?start=%d&filter="
num = int(input("请问您想要查询豆瓣电影Top榜单前多少页的信息:"))for i in range(0,num): #第1页=0*25,第二页=1*25…… range范围[a,b)i=i*25
new_url = format(url%i) #用值i替换url中的变量,形成新的urldic = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.2081 SLBChan/103 SLBVPV/64-bit"
}
resp = requests.get(url=new_url,headers=dic)
page_content = resp.text#re提取数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>'r'.*?<p>(?P<daoyan>.*?) .*?<br>(?P<year>.*?) .*?'r'<span class="rating_num" property="v:average">(?P<score>.*?)</span>'r'.*?<span>(?P<people>.*?)人评价</span>',re.S)res = obj.finditer(page_content)
f = open("movie.csv","a",encoding="utf-8")
csvWriter = csv.writer(f) #将文件转为csv写入
for item in res:dic = item.groupdict() #把获取的数据转换成字典dic['year'] = dic['year'].strip() #去除字符串首尾的指定字符dic['daoyan'] = dic['daoyan'].strip()csvWriter.writerow(dic.values())f.close()
resp.close()
print("over!")
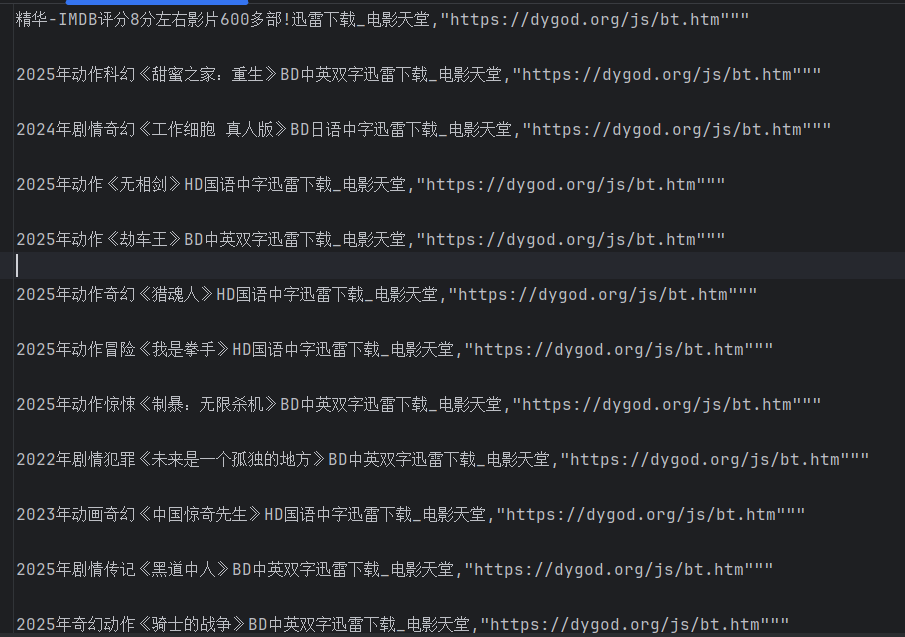
(6)re实战2:爬取电影天堂


import re
import csv
from urllib.parse import urljoinimport requests#request获取页面源代码
domain_url = "https://dydytt.net/index.htm"dic = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.2081 SLBChan/103 SLBVPV/64-bit"
}
resp = requests.get(url=domain_url,headers=dic,verify=False)
resp.encoding = "gb2312"
main_page_ct = resp.text#re匹配数据
obj1 = re.compile(r"最新电影更新.*?<ul>(?P<url>.*?)</ul>",re.S)
obj2 = re.compile(r"<a href='(?P<href>.*?)'>",re.S)
obj3 = re.compile(r'<title>(?P<name>.*?)</title>'r'.*?磁力链下载器:<a href="(?P<down>.*?) target="_blank" title="qBittorrent">',re.S)res1 = obj2.finditer(main_page_ct)f = open("dyttmovie.csv","a",encoding="utf-8")
csvWriter = csv.writer(f) #将文件转为csv写入#1.提取页面子链接
res2 = obj2.finditer(main_page_ct)
child_href_list = []
for i in res2:#拼接子页面连接child_url = urljoin(domain_url,i.group('href'))child_href_list.append(child_url)#2.提取子页面内容
for i in child_href_list:child_resp = requests.get(url=i,headers=dic,verify=False) #获取子页面urlchild_resp.encoding = 'gb2312'res3 = obj3.search(child_resp.text) #提取子页面数据tdic = res3.groupdict()csvWriter.writerow(tdic.values()) #存入文件f.close()
resp.close()
print("over!")