AI专题(一)----NLP2SQL探索以及解决方案
前面写了很多编码、算法、底层计算机原理等相关的技术专题,由于工作方向调整的缘故,今天开始切入AI人工智能相关介绍。本来按照规划,应该先从大模型的原理开始介绍会比较合适,但是计划赶不上变化,前面通用大模型的工作处于高度紧张状态,没来得及写;这段时间在准备启动AI+大数据的工作,跟NLP2SQL强相关,做了些调研,谨以此文章记录相关的技术以及想法。
NLP2SQL(Natural Language Processing to Structured Query Language)是将自然语言问题自动转化为数据库可执行SQL查询的技术。其核心目标是通过理解人类日常语言,生成对应的数据库操作指令,降低非技术人员对实时生产系统的数据查询门槛。通过字面理解,可能对于有一定的AI技术知识基础的同学来说,感觉没有太多的技术门槛。但是,技术的复杂性往往不在于用一个Demo场景去验证它的可行,而在于提出一个系统的解决方案,它不但能够解决各种复杂、未知的可能,并达到可商业化的成功率。
下面我们由浅入深展开,以一个企业经营情况的问答来展开:2024年公司利润是多少?
从这个问题上来看,我们大模型应对起来应该是毫无压力,只要我们针对公司每个大区的每日/每月的经营报表的表结构丢给大模型,并告诉他要求以及问题,原生的NLP2SQL都可以轻松胜任。我们可以直接应用OpenAI公司在官网给的一个标准模板生成的NLP2SQL的例子:
System/*系统指令*/
你是一个 SQL 生成专家。请参考如下的表格结构,直接输出 SQL 语句,不要多余的解释。/*数据库内表结构*/
CREATE TABLE Orders (UnitID INT, /*大区ID*/UnitName VARCHAR(255) NOT NULL,/*大区名称*/Date datetime NOT NULL,/*日期*/Revenue DECIMAL(15, 2) NOT NULL,/*销售额*/Profit DECIMAL(15, 2) NOT NULL,/*利润*/Cost DECIMAL(15, 2) NOT NULL,/*成本*/TotalAssets DECIMAL(15, 2) NOT NULL/*资产总额*/
);...此处省略其他表.../*问题*/
2024年公司利润是多少?根据这个prompt,以我们现有的大模型的能力,轻松就能给出sql语句,并且准确率100%。但是,这完全是我们站在了理想的角度提出了一个符合我们想要的问题(或者说就是一个Demo),商业环境用户使用过程中,往往是不会跟着技术人员的思路来的,用的人还是公司的领导,不好教育用户,他们往往会简单粗暴的问一句:2024年公司经营情况怎么样?去年ICT业务情况怎样?分析下某某业务在XX时间段异常的原因?
当用户问题开始出现变化的时候,这就开始大大增加系统复杂性了,用户可能会从不同的角度、时间段、业务层面等等去提出问题。我们需要把相关问题的所有的表结构定义,都放入到prompt当中,比如资产负债表、投资项目表、支出项目表、业务经营表等等,那么我们的这一类的问题,在生产环境中就会膨胀出十几张甚至几十张表结构,我们还得想办法告诉大模型这些表结构之间的关联关系等等,这时候我们上面的prompt就会急剧膨胀,膨胀到超出上下文大小,大模型也无法理解的地步,成功率就开始急剧下降。(设计得非常合理的大宽表解决方案,能缓解不能完全解决)
第二个问题就是,每个用户关注的重点,也不一样,同样的问题“2024年公司经营情况”,董事长关注营收,CEO关注利润,总会计师关注支出,甚至可能还跟公司背景有联系(公司考核营收比较重或者利润比较重等),纯靠大模型推理,有时候会出现答案好像是对的,但却并不是我们想要的。
行业三种技术解决方案
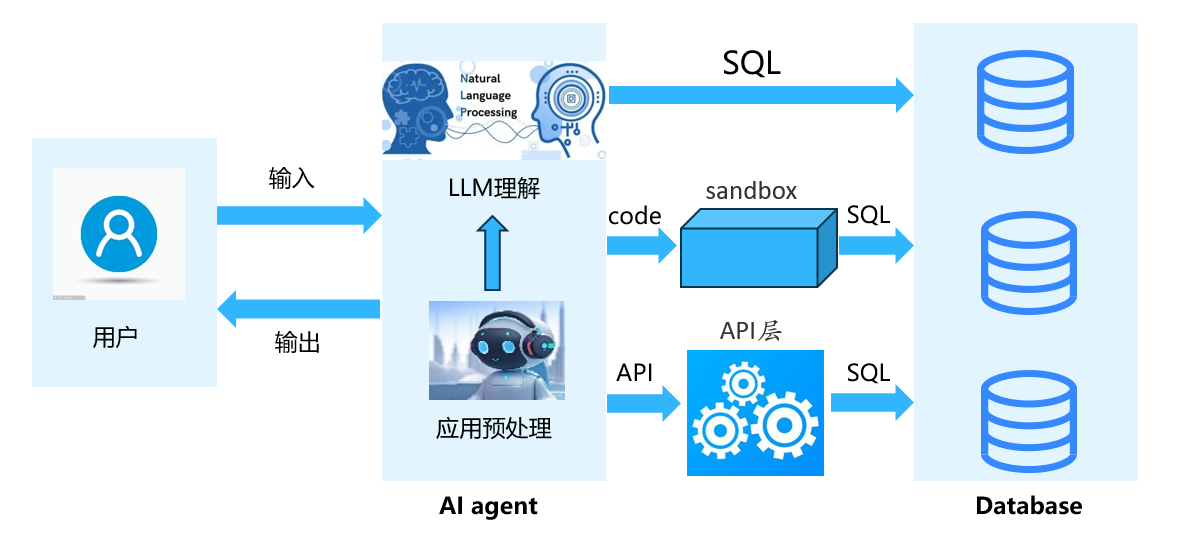
方案一:text2SQL
该方案简单粗暴,具体例子和实践在上面已经描述过了,不再赘述。该方案最重要的点在于设计合理的大宽表,尽量避免让大模块跨表查询,否则多表联表查询的时候会出现各种不可预知的错误,如LLM把关联字段理解错误,导致查不到数据,或者数据错误。
即使设计合理,由于不同企业背景和企业特点,大模型在没有这些背景知识支撑下,成功率也不会很高,同时大宽表还会带来性能的缺陷。
方案二:text2Code
方案二同样是需要将表结构等信息放在Prompt里面灌给大模型让它去推理学习,但是不同的是大模型生成的是代码&&SQL,利用代码在自定义的沙箱中执行,利用Code执行业务逻辑处理,利用SQL获取数据库的数据,最后得到用户的答案。
方案三:text2API
该方案是我认为解决NLP2SQL诸多挑战的最优解,通过在AI agent和数据库中间,架一个中间的API层,该层需要能够归纳、涵盖所有底层数据库指标,并通过API暴露给AI agent进行调用。用户通过AI agent进行提问的时候,AI agent把具体的场景问题,拆成多个可能的指标,并发的去API层拿到所有的指标,然后把所有的这些指标数据交给大模型去总结。
这种做法,能够把prompt大小限制、SQL生成的随机性、问数背景的各种不确定性,最大可能的消灭在API层的指标建设上,得到一个较为清晰、明确的结果。
最终方案
在方案三的基础上,我进一步设计了在AI agent上利用LLM的function call做一次场景(意图)识别,然后根据场景去知识库/数据库拿定义好的,每个场景对应的指标,即可得出前后互相对应的完整解决方案了,完整流程如下:
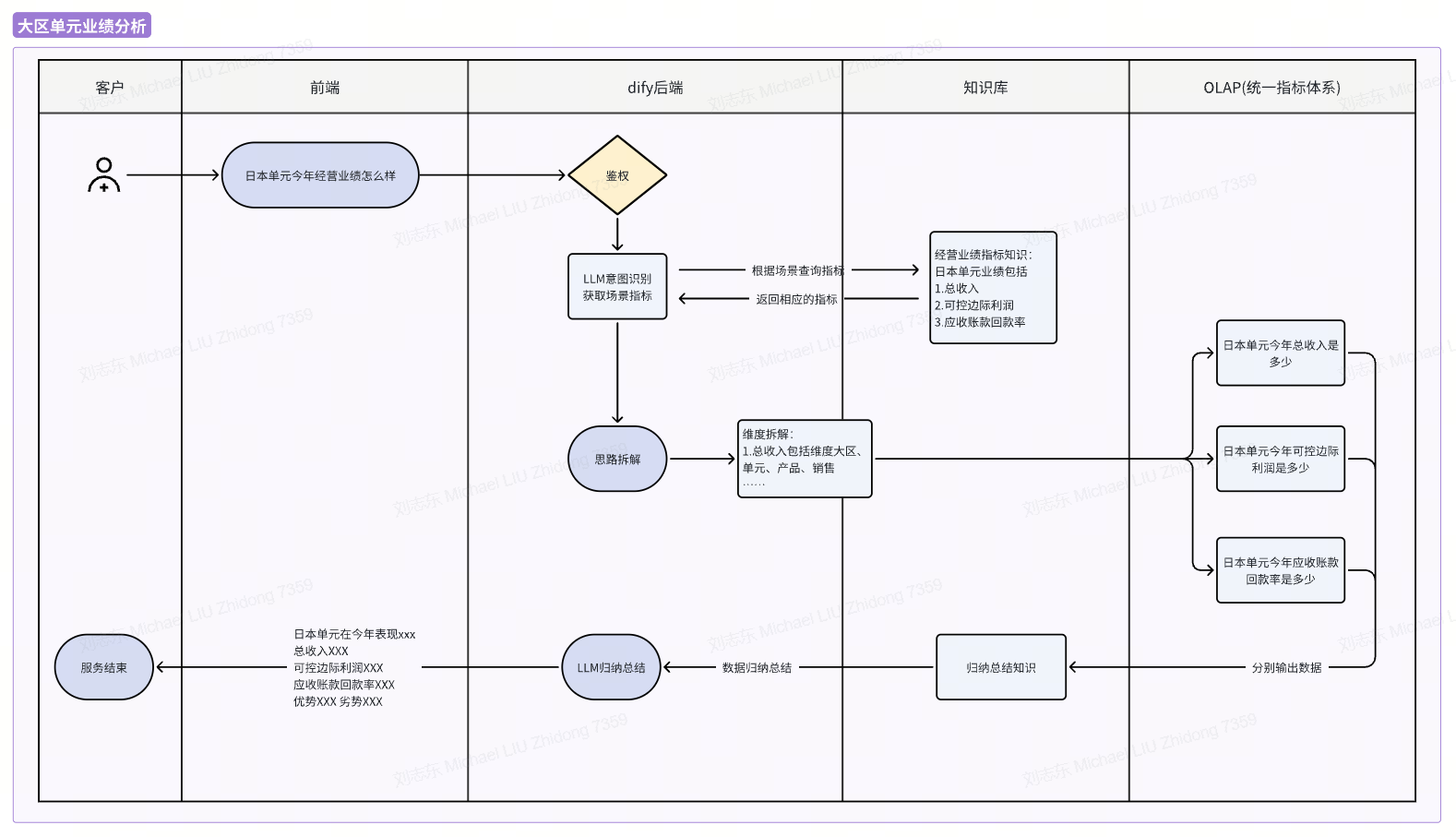
所有的人工智能,最后都是“人工”智能。