本地部署Qwen-7B实战 vLLM加速推理
项目整体框架预览
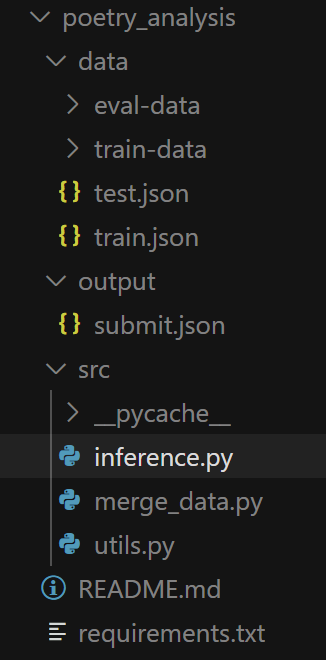
1. 数据准备
创建一个新的项目目录结构,并设置所需的文件。首先让我们创建一个项目目录:
mkdir poetry_analysiscd poetry_analysis现在我们来创建项目所需的文件poetry_analysis/README.md:
# 古诗词理解与推理评测系统这是一个基于vllm部署Qwen模型的古诗词理解与推理评测系统。系统能够解析古诗词,提供关键词解释、句子含义分析以及情感分类。## 环境要求- Python 3.8+
- CUDA 支持(用于GPU加速)
- 足够的GPU显存(建议至少16GB)## 安装依赖```bash
pip install -r requirements.txt
```## 项目结构```
poetry_analysis/
├── README.md
├── requirements.txt
├── data/
│ ├── train.json # 训练数据
│ └── test.json # 测试数据
├── src/
│ ├── inference.py # 主推理代码
│ └── utils.py # 工具函数
└── output/ # 输出结果目录
```## 使用方法1. 准备数据- 将训练数据放在 `data/train.json`- 将测试数据放在 `data/test.json`2. 运行评测```bashpython src/inference.py```3. 查看结果- 结果将保存在 `output/submit.json` 文件中## 输出格式输出文件为JSON格式,包含以下字段:
- idx: 数据索引
- ans_qa_words: 关键词解释
- ans_qa_sents: 句子解释
- choose_id: 情感分类结果## 注意事项1. 首次运行时会自动下载Qwen模型,请确保网络连接正常
2. 建议使用GPU进行推理,CPU推理速度会较慢
3. 可以在inference.py中调整模型参数和推理设置创建项目目录结构:
mkdir -p poetry_analysis/{data,src,output}创建poetry_analysis/requirements.txt:
vllm>=0.2.0
transformers>=4.30.0
torch>=2.0.0
numpy>=1.20.0
tqdm>=4.65.0
accelerate>=0.20.0
sentencepiece>=0.1.99创建工具函数文件poetry_analysis/src/utils.py:
import json
import re
from typing import Dict, List, Anydef load_json_file(file_path: str) -> List[Dict[str, Any]]:"""加载JSON文件"""with open(file_path, 'r', encoding='utf-8') as f:return json.load(f)def save_json_file(data: List[Dict[str, Any]], file_path: str) -> None:"""保存JSON文件"""with open(file_path, 'w', encoding='utf-8') as f:json.dump(data, f, ensure_ascii=False, indent=4)def extract_word_explanation(response: str, word: str) -> str:"""从模型响应中提取关键词解释"""pattern = f"{word}[::](.*?)(?=\n|$)"match = re.search(pattern, response)if match:return match.group(1).strip()return ""def extract_sentence_explanation(response: str, sentence: str) -> str:"""从模型响应中提取句子解释"""# 处理可能的特殊字符sentence = re.escape(sentence)pattern = f"{sentence}[::](.*?)(?=\n|$)"match = re.search(pattern, response)if match:return match.group(1).strip()return ""def extract_emotion_choice(response: str) -> int:"""从模型响应中提取情感选择返回选项的索引(0-3对应A-D)"""pattern = r"情感选择[::]\s*([A-D])"match = re.search(pattern, response)if match:choice = match.group(1)return ord(choice) - ord('A')return -1 # 返回-1表示未找到有效选择创建改进版的推理代码poetry_analysis/src/inference.py:
from vllm import LLM, SamplingParams
import os
from tqdm import tqdm
from utils import (load_json_file,save_json_file,extract_word_explanation,extract_sentence_explanation,extract_emotion_choice
)class PoetryAnalyzer:def __init__(self, model_name="Qwen/Qwen-7B-Chat"):"""初始化诗词分析器"""self.model_name = model_nameself.llm = Noneself.sampling_params = SamplingParams(temperature=0.7,top_p=0.95,max_tokens=1024,stop=None)def load_model(self):"""加载模型"""print(f"正在加载模型 {self.model_name}...")self.llm = LLM(model=self.model_name)print("模型加载完成!")def generate_prompt(self, data):"""生成提示词"""prompt = f"""作为一位古诗词专家,请分析以下古诗词:标题:{data['title']}
作者:{data['author']}
内容:{data['content']}请完成以下三个任务:1. 解释下列关键词的含义(每个词给出简明扼要的解释):
{', '.join(data['qa_words'])}2. 解释下列句子的含义(每句话给出完整的解释):
{', '.join(data['qa_sents'])}3. 这首诗表达的情感是:{data['choose']}中的哪一个?请按照以下格式回答:关键词解释:
{data['qa_words'][0]}:[解释]
{' '.join([word + ':[解释]' for word in data['qa_words'][1:]])}句子解释:
{data['qa_sents'][0]}:[解释]
{' '.join([sent + ':[解释]' for sent in data['qa_sents'][1:]])}情感选择:[选项字母]注意:
1. 解释要准确、简洁
2. 每个关键词和句子都必须给出解释
3. 情感选择必须是选项中的一个字母
"""return promptdef parse_response(self, response, data):"""解析模型输出的回答"""result = {"ans_qa_words": {},"ans_qa_sents": {},"choose_id": -1}# 解析关键词解释for word in data['qa_words']:explanation = extract_word_explanation(response, word)result["ans_qa_words"][word] = explanation# 解析句子解释for sent in data['qa_sents']:explanation = extract_sentence_explanation(response, sent)result["ans_qa_sents"][sent] = explanation# 解析情感选择result["choose_id"] = extract_emotion_choice(response)return resultdef process_single_poem(self, data):"""处理单个诗词"""prompt = self.generate_prompt(data)outputs = self.llm.generate([prompt], self.sampling_params)response = outputs[0].outputs[0].textreturn self.parse_response(response, data)def run_analysis(self, test_file, output_file):"""运行分析"""if self.llm is None:self.load_model()print(f"正在读取测试数据: {test_file}")test_data = load_json_file(test_file)results = []print("开始处理诗词...")for idx, data in enumerate(tqdm(test_data)):try:result = self.process_single_poem(data)result["idx"] = idxresults.append(result)except Exception as e:print(f"处理第{idx}首诗词时出错: {str(e)}")# 添加空结果以保持索引对应results.append({"idx": idx,"ans_qa_words": {word: "" for word in data['qa_words']},"ans_qa_sents": {sent: "" for sent in data['qa_sents']},"choose_id": -1})print(f"正在保存结果到: {output_file}")save_json_file(results, output_file)print("处理完成!")def main():# 设置文件路径base_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))test_file = os.path.join(base_dir, "data", "test.json")output_file = os.path.join(base_dir, "output", "submit.json")# 创建分析器实例analyzer = PoetryAnalyzer()# 运行分析analyzer.run_analysis(test_file, output_file)if __name__ == "__main__":main()现在我已经为您创建了一个完整的项目结构,包括:
项目目录结构:
poetry_analysis/
├── README.md # 项目说明文档
├── requirements.txt # 项目依赖
├── data/ # 数据目录
│ ├── train.json # 训练数据
│ └── test.json # 测试数据
├── src/ # 源代码目录
│ ├── inference.py # 主推理代码
│ └── utils.py # 工具函数
└── output/ # 输出结果目录使用方法:
- 首先安装依赖
cd poetry_analysis pip install -r requirements.txt - 运行推理:
python src/inference.py - 结果将保存在 output/submit.json
2. few-shot Prompt设计
目标:在每个测试样本的prompt前插入若干训练样例,提升模型表现。
poetry_analysis/src/inference.py
from vllm import LLM, SamplingParams
import os
from tqdm import tqdm
from utils import (load_json_file,save_json_file,extract_word_explanation,extract_sentence_explanation,extract_emotion_choice
)
import randomclass PoetryAnalyzer:def __init__(self, model_name="/hy-tmp/Qwen-7B-Chat", train_data_path=None, num_shots=3):"""初始化诗词分析器"""self.model_name = model_nameself.llm = Noneself.sampling_params = SamplingParams(temperature=0.7,top_p=0.95,max_tokens=1024,stop=None)self.num_shots = num_shotsself.train_data = []if train_data_path and os.path.exists(train_data_path):self.train_data = load_json_file(train_data_path)def load_model(self):"""加载模型"""print(f"正在加载模型 {self.model_name}...")self.llm = LLM(model=self.model_name, trust_remote_code=True)print("模型加载完成!")def generate_few_shot_examples(self):"""随机选取few-shot训练样例,格式化为prompt片段"""if not self.train_data or self.num_shots == 0:return ""examples = random.sample(self.train_data, min(self.num_shots, len(self.train_data)))shots = []for ex in examples:shot = (f"【示例】\n"f"标题:{ex['title']}\n"f"作者:{ex.get('author', '')}\n"f"内容:{ex['content']}\n"f"关键词解释:\n")for k, v in ex['keywords'].items():shot += f"{k}: {v}\n"shot += f"白话文:{ex.get('trans', '')}\n"shot += f"情感:{ex.get('emotion', '')}\n"shots.append(shot)return "\n".join(shots)def generate_prompt(self, data):"""生成带few-shot的提示词"""few_shot = self.generate_few_shot_examples()prompt = f"""{few_shot}\n【待分析】\n标题:{data['title']}\n作者:{data.get('author', '')}\n内容:{data['content']}\n\n请完成以下三个任务:\n\n1. 解释下列关键词的含义(每个词给出简明扼要的解释):\n{', '.join(data['qa_words'])}\n\n2. 解释下列句子的含义(每句话给出完整的解释):\n{', '.join(data['qa_sents'])}\n\n3. 这首诗表达的情感是:{data['choose']}中的哪一个?\n\n请按照以下格式回答:\n\n关键词解释:\n{data['qa_words'][0]}:[解释]\n{' '.join([word + ':[解释]' for word in data['qa_words'][1:]])}\n\n句子解释:\n{data['qa_sents'][0]}:[解释]\n{' '.join([sent + ':[解释]' for sent in data['qa_sents'][1:]])}\n\n情感选择:[选项字母]\n\n注意:\n1. 解释要准确、简洁\n2. 每个关键词和句子都必须给出解释\n3. 情感选择必须是选项中的一个字母\n"""return promptdef parse_response(self, response, data):"""解析模型输出的回答"""result = {"ans_qa_words": {},"ans_qa_sents": {},"choose_id": -1}# 解析关键词解释for word in data['qa_words']:explanation = extract_word_explanation(response, word)result["ans_qa_words"][word] = explanation# 解析句子解释for sent in data['qa_sents']:explanation = extract_sentence_explanation(response, sent)result["ans_qa_sents"][sent] = explanation# 解析情感选择result["choose_id"] = extract_emotion_choice(response)return resultdef process_single_poem(self, data):"""处理单个诗词"""prompt = self.generate_prompt(data)outputs = self.llm.generate([prompt], self.sampling_params)response = outputs[0].outputs[0].textreturn self.parse_response(response, data)def run_analysis(self, test_file, output_file):"""运行分析"""if self.llm is None:self.load_model()print(f"正在读取测试数据: {test_file}")test_data = load_json_file(test_file)results = []print("开始处理诗词...")for idx, data in enumerate(tqdm(test_data)):try:result = self.process_single_poem(data)result["idx"] = idxresults.append(result)except Exception as e:print(f"处理第{idx}首诗词时出错: {str(e)}")# 添加空结果以保持索引对应results.append({"idx": idx,"ans_qa_words": {word: "" for word in data['qa_words']},"ans_qa_sents": {sent: "" for sent in data['qa_sents']},"choose_id": -1})print(f"正在保存结果到: {output_file}")save_json_file(results, output_file)print("处理完成!")def main():# 设置文件路径test_file = "data/test.json"output_file = "output/submit.json"train_file = "data/train.json"# 创建分析器实例,传入训练集路径analyzer = PoetryAnalyzer(train_data_path=train_file, num_shots=3)# 运行分析analyzer.run_analysis(test_file, output_file)if __name__ == "__main__":main() 如需调整few-shot数量,只需修改num_shots参数即可。例如:PoetryAnalyzer(train_data_path=train_file, num_shots=5)。
3. 模型推理
目标:用vllm+Qwen-7B批量推理。
部署vllm
安装环境依赖
pip install -r requirements.txt安装完成后,可以用以下命令检查 vllm 是否安装成功:
python -c "import vllm; print(vllm.__version__)"使用Modelscope将模型下载到服务器
pip install modelscopemodelscope download qwen/Qwen-7B-Chat将模型移动到数据盘 /hy-tmp/Qwen-7B-Chat 下,
mv ~/.cache/modelscope/hub/models/qwen/Qwen-7B-Chat /hy-tmp/
由于我们将Qwen模型移动到了数据盘下,需要在代码poetry_analysis/src/inference.py中指定新的本地模型路径
analyzer = PoetryAnalyzer(model_name="/hy-tmp/Qwen-7B-Chat", train_data_path=train_file, num_shots=3)src/inference.py已实现批量推理。只需运行:
python src/inference.py预测输出如下
[{"ans_qa_words": {"衰草": "","故关": "","风尘": ""},"ans_qa_sents": {"故关衰草遍,离别自堪悲": "","掩泪空相向,风尘何处期。": ""},"choose_id": -1,"idx": 0},{"ans_qa_words": {"窥": "","牧马": "至今,指从现在起;窥,偷看;牧马,放牧马匹;临洮,古代地名,位于今甘肃省临洮县。","临洮": ""},"ans_qa_sents": {"至今窥牧马": "至今,指从现在起;窥,偷看;牧马,放牧马匹;临洮,古代地名,位于今甘肃省临洮县。","不敢过临洮": ""},"choose_id": -1,"idx": 1},{"ans_qa_words": {"回合": "","阑": "","离人": ""},"ans_qa_sents": {"别梦依依到谢家": "","犹为离人照落花": ""},"choose_id": -1,"idx": 2},{"ans_qa_words": {"涕": "眼泪。","却看": "回头看。","纵酒": "尽情饮酒。"},"ans_qa_sents": {"剑外忽传收蓟北,初闻涕泪满衣裳。": "忽然听说收复了蓟北,(杜甫)听闻这个消息后悲喜交加,泪流满面。","白日放歌须纵酒,青春作伴好还乡。": "在晴朗的日子里放声高歌,尽情饮酒,年轻的朋友们作伴一起回到故乡。"},"choose_id": 3,"idx": 3},{"ans_qa_words": {"一日程": "","估客": "","鼓鼙": ""},"ans_qa_sents": {"估客昼眠知浪静,舟人夜语觉潮生。": "","三湘衰鬓逢秋色,万里归心对月明。": ""},"choose_id": -1,"idx": 4},{"ans_qa_words": {"长乐宫": "","宫莺": ""},"ans_qa_sents": {"长乐宫连上苑春": "","君门一入无由出": ""},"choose_id": -1,"idx": 5},{"ans_qa_words": {"鸿雁": "大型候鸟,秋天南飞,春天北归,常常被视为传递消息的使者。","江湖": "古代泛指广大无边的水域,后来也用来形容人情世故。","魑魅": "传说中的怪物,这里指阴险、邪恶的人或事。"},"ans_qa_sents": {"鸿雁几时到": "请问鸿雁什么时候能飞到?","应共冤魂语,投诗赠汨罗": "应该和冤屈的魂魄一起说话,把诗投赠到汨罗江。"},"choose_id": 0,"idx": 6},{"ans_qa_words": {"浩然": "形容人的气势盛大,有磅礴之感。","荒戍": "荒废的戍楼。","孤棹": "孤零零的船只。"},"ans_qa_sents": {"荒戍落黄叶,浩然离故关。": "","何当重相见,樽酒慰离颜。": ""},"choose_id": 2,"idx": 7}打印代码运行过程中的详细调试信息
处理结果并不理想,我们在 inference.py 的关键位置增加原始模型输出打印和解析异常打印。这样可以看到每条样本的 prompt、模型 response 以及解析结果。
from vllm import LLM, SamplingParams
import os
from tqdm import tqdm
from utils import (load_json_file,save_json_file,extract_word_explanation,extract_sentence_explanation,extract_emotion_choice
)
import randomclass PoetryAnalyzer:def __init__(self, model_name="/hy-tmp/Qwen-7B-Chat", train_data_path=None, num_shots=3):"""初始化诗词分析器"""self.model_name = model_nameself.llm = Noneself.sampling_params = SamplingParams(temperature=0.7,top_p=0.95,max_tokens=1024,stop=None)self.num_shots = num_shotsself.train_data = []if train_data_path and os.path.exists(train_data_path):self.train_data = load_json_file(train_data_path)def load_model(self):"""加载模型"""print(f"正在加载模型 {self.model_name}...")self.llm = LLM(model=self.model_name, trust_remote_code=True)print("模型加载完成!")def generate_few_shot_examples(self):"""随机选取few-shot训练样例,格式化为prompt片段"""if not self.train_data or self.num_shots == 0:return ""examples = random.sample(self.train_data, min(self.num_shots, len(self.train_data)))shots = []for ex in examples:shot = (f"【示例】\n"f"标题:{ex['title']}\n"f"作者:{ex.get('author', '')}\n"f"内容:{ex['content']}\n"f"关键词解释:\n")for k, v in ex['keywords'].items():shot += f"{k}: {v}\n"shot += f"白话文:{ex.get('trans', '')}\n"shot += f"情感:{ex.get('emotion', '')}\n"shots.append(shot)return "\n".join(shots)def generate_prompt(self, data):"""生成带few-shot的提示词"""few_shot = self.generate_few_shot_examples()prompt = f"""{few_shot}\n【待分析】\n标题:{data['title']}\n作者:{data.get('author', '')}\n内容:{data['content']}\n\n请完成以下三个任务:\n\n1. 解释下列关键词的含义(每个词给出简明扼要的解释):\n{', '.join(data['qa_words'])}\n\n2. 解释下列句子的含义(每句话给出完整的解释):\n{', '.join(data['qa_sents'])}\n\n3. 这首诗表达的情感是:{data['choose']}中的哪一个?\n\n请按照以下格式回答:\n\n关键词解释:\n{data['qa_words'][0]}:[解释]\n{' '.join([word + ':[解释]' for word in data['qa_words'][1:]])}\n\n句子解释:\n{data['qa_sents'][0]}:[解释]\n{' '.join([sent + ':[解释]' for sent in data['qa_sents'][1:]])}\n\n情感选择:[选项字母]\n\n注意:\n1. 解释要准确、简洁\n2. 每个关键词和句子都必须给出解释\n3. 情感选择必须是选项中的一个字母\n"""return promptdef parse_response(self, response, data, idx=None):result = {"ans_qa_words": {},"ans_qa_sents": {},"choose_id": -1}try:if not response or not isinstance(response, str):print(f"[调试] idx={idx}, response为空或格式异常")return resultfor word in data['qa_words']:explanation = extract_word_explanation(response, word)result["ans_qa_words"][word] = explanationfor sent in data['qa_sents']:explanation = extract_sentence_explanation(response, sent)result["ans_qa_sents"][sent] = explanationresult["choose_id"] = extract_emotion_choice(response)except Exception as e:print(f"[调试] idx={idx}, 解析response时出错: {e}")return resultdef process_single_poem(self, data, idx=None):prompt = self.generate_prompt(data)print(f"\n[调试] idx={idx}, prompt=\n{prompt}\n{'='*40}")outputs = self.llm.generate([prompt], self.sampling_params)response = outputs[0].outputs[0].textprint(f"\n[调试] idx={idx}, response=\n{response}\n{'='*40}")return self.parse_response(response, data, idx=idx)def run_analysis(self, test_file, output_file):if self.llm is None:self.load_model()print(f"正在读取测试数据: {test_file}")test_data = load_json_file(test_file)results = []print("开始处理诗词...")for idx, data in enumerate(tqdm(test_data)):try:result = self.process_single_poem(data, idx=idx)result["idx"] = idxresults.append(result)except Exception as e:print(f"处理第{idx}首诗词时出错: {str(e)}")results.append({"idx": idx,"ans_qa_words": {word: "" for word in data['qa_words']},"ans_qa_sents": {sent: "" for sent in data['qa_sents']},"choose_id": -1})print(f"正在保存结果到: {output_file}")save_json_file(results, output_file)print("处理完成!")def main():# 设置文件路径test_file = "data/test.json"output_file = "output/submit.json"train_file = "data/train.json"# 创建分析器实例,传入训练集路径analyzer = PoetryAnalyzer(train_data_path=train_file, num_shots=3)# 运行分析analyzer.run_analysis(test_file, output_file)if __name__ == "__main__":main() 运行后如何分析
- 终端会输出每条样本的 prompt、response 及解析情况。
- 如果 response 为空、格式异常或解析出错,会有详细提示。
- 这样可以定位是模型没生成、生成内容不对,还是解析正则有问题。
调试信息样例输出如下:
18%|██████████▋ | 59/327 [04:06<14:12, 3.18s/it]
[调试] idx=59, prompt=
【示例】
标题:汉江临泛
作者:
内容:楚塞三湘接,荆门九派通。江流天地外,山色有无中。郡邑浮前浦,波澜动远空。襄阳好风日,留醉与山翁。
关键词解释:
汉江: 即汉水,流经陕西汉中、安康,湖北十堰、襄阳、荆门、潜江、仙桃、孝感,到汉口流入长江
楚塞: 楚国边境地带,这里指汉水流域
三湘: 湖南有湘潭、湘阴、湘乡,合称三湘
荆门: 山名,荆门山,在今湖北宜都县西北的长江南岸
九派: 九条支流,长江至浔阳分为九支,指江西九江
郡邑: 指汉水两岸的城镇
浦: 水边
好风日: 一作‘风日好’,风景天气好
山翁: 一作‘山公’,指山简,晋代竹林七贤之一山涛的幼子,西晋将领,镇守襄阳
白话文:汉江流经楚塞又折入三湘,西起荆门往东与九江相通。江水滔滔远去,好像一直涌流到天地之外,两岸山色时隐时现,若有若无。远处的城郭好像在水面上飘动,波翻浪涌,辽远的天空也仿佛为之摇荡。襄阳的风景天气好,我愿在此地酣饮陪伴山翁。
情感:追求美好境界,寄情山水,豪情壮志,陶醉于自然之美【示例】
标题:凤箫吟·锁离愁
作者:
内容:锁离愁,连绵无际,来时陌上初熏。绣帏人念远,暗垂珠泪,泣送征轮。长亭长在眼,更重重、远水孤云。但望极楼高,尽日目断王孙。 消魂。池塘别后,曾行处、绿妒轻裙。恁时携素手,乱花飞絮里,缓步香茵。朱颜空自改,向年年、芳意长新。遍绿野,嬉游醉眠,莫负青春。
关键词解释:
凤箫吟: 词牌名
陌上初熏: 路上散发着草的香气
绣帏: 绣房、闺阁
暗垂珠泪: 暗暗落下一串串珠露般的眼泪
王孙: 送行之人
绿妒轻裙: 轻柔的罗裙和芳草争绿
恁: 那
素手: 女子洁白如玉的手
香茵: 芳草地
白话文:离愁萦绕,看着眼前连绵无际的春草,想起与心上人同游时它们还刚在路边吐出香馨。闺中人想到心上人要远行,暗暗地流下泪珠,哽咽着目送远去的车轮。人已远去她还痴痴地张望,可见到的已是重重远水、片片孤云。她又登楼极目远望,但望穿秋水也难见游子踪影。伤心啊伤心,自从池塘分别后无日不黯然销魂。想当年同游的地方连绿草都妒忌她的罗裙。那时候他携着她的手,在花丛柳絮之中,在翠绿香茵上信步徜徉。如今她的容颜虽已渐渐老去,但心中情意仍像芳草一样年年常新。她要再游遍绿野,忘情嬉戏酣饮,不辜负这珍贵的年少青春。
情感:伤感与怀念【示例】
标题:竹里馆
作者:
内容:独坐幽篁里,弹琴复长啸。
深林人不知,明月来相照。
关键词解释:
竹里馆: 辋川别墅胜景之一,房屋周围有竹林,故名。
幽篁(huáng): 幽深的竹林。
啸(xiào): 撮口发出长而清脆的声音,类似于打口哨。
深林: 指‘幽篁’。
相照: 与‘独坐’相应,意思是说,左右无人相伴,唯有明月似解人意,偏来相照。
长啸: 撮口而呼,这里指吟咏、歌唱。古代一些超逸之士常用来抒发感情。魏晋名士称吹口哨为啸。
白话文:独自闲坐在幽静竹林,一边弹琴一边高歌长啸。
深深的山林中无人知晓,只有一轮明月静静与我相伴。
情感:宁静、孤独、悠闲【待分析】
标题:和晋陵陆丞早春游望
作者:杜审言
内容:独有宦游人,偏惊物候新。云霞出海曙,梅柳渡江春。淑气催黄鸟,晴光转绿蘋。忽闻歌古调,归思欲沾巾。请完成以下三个任务:1. 解释下列关键词的含义(每个词给出简明扼要的解释):
宦游人, 物候, 淑气2. 解释下列句子的含义(每句话给出完整的解释):
独有宦游人, 归思欲沾巾3. 这首诗表达的情感是:{'A': '思乡之情', 'B': '欢快愉悦', 'C': '孤独寂寞', 'D': '春天的喜悦'}中的哪一个?请按照以下格式回答:关键词解释:
宦游人:[解释]
物候:[解释] 淑气:[解释]句子解释:
独有宦游人:[解释]
归思欲沾巾:[解释]情感选择:[选项字母]注意:
1. 解释要准确、简洁
2. 每个关键词和句子都必须给出解释
3. 情感选择必须是选项中的一个字母