从零到一MCP详细教程——入门
如今AI发展非常迅猛,AI技术的爆发式增长正从“实验室创新”转向“产业级落地”,而智能体与MCP协议的协同进化,标志着人机协作进入“无缝集成”的新纪元。未来,技术突破需与伦理框架、可持续发展并重,方能实现“效率提升”与“社会价值”的双赢。

一、AI发展状况
2025年将是人工智能(尤其是大语言模型LLM、智能体Agent)发展的关键节点,技术迭代、应用场景和产业格局将呈现显著变化。
2025年,AI领域呈现“大模型生态化、智能体场景化”的双轨并行发展格局,国内外在技术路径、应用场景和产业生态上形成差异化竞争。

1.1 LLM大模型

首先我们要了解一下什么是LLM大模型以及它的发展历程。
如今LLM大模型在自然语言生成(例如:自动撰写文章、代码、营销文案等)、智能交互、医疗、教育、金融、跨模态任务等方面发挥了重要的作用,因此我们就有必要了解清楚LLM。

大语言模型(Large Language Model, LLM)是一种基于深度学习的自然语言处理技术,通过海量文本数据训练,具备生成自然语言文本、理解语义及完成复杂语言任务的能力。
LLM的特点如下所示:
- 模型架构:基于Transformer架构,利用自注意力机制(Self-Attention)捕捉长距离文本依赖关系,支持并行化训练。
- 训练数据规模:参数数量通常达数十亿至数千亿级别(如GPT-3的1750亿参数、Grok-1的3140亿参数),训练数据覆盖书籍、网页、代码等多领域文本。
- 涌现能力:当模型规模超过阈值时,会涌现出小模型不具备的能力,如上下文学习(Few-shot Learning)、逻辑推理等。
现在我们知道了什么是LLM,下面我们继续了解LLM的的发展历程,对于LLM的发展历程,主要分为四个阶段即技术奠基阶段、Transformer&预训练阶段、对话与多模态融合阶段、推理优化与专业化发展阶段。
【技术奠基阶段:2017年以前】
早期探索(1950s-2010s)
- 规则系统与统计方法主导:基于人工编写规则(如机器翻译系统)和统计模型(如n-gram语言模型),但受限于上下文理解能力。
- 神经网络初步应用:引入RNN、LSTM处理序列数据,但存在梯度消失和计算效率低的问题。
词嵌入与深度学习(2010s)
- Word2Vec(2013):将词语映射为向量,捕捉语义关联。
- Seq2Seq(2014):基于RNN的编码器-解码器架构,推动机器翻译发展。
【Transformer&预训练阶段:2017年至2020年】
Transformer架构(2017)
- 核心突破:自注意力机制(Self-Attention)实现并行计算和长程依赖捕捉,奠定LLM技术基础。
- 影响:替代RNN/LSTM,成为后续模型的核心架构。
第一代预训练模型(2018-2019)
- BERT(2018):双向Transformer,通过MLM任务提升上下文理解能力。
- GPT-1(2018):自回归模型,开启生成式预训练范式。
- 技术范式:预训练+微调(Pre-train & Fine-tune)成为主流。
规模扩张与少样本学习(2020)
- GPT-3(2020):1750亿参数,展示少样本/零样本学习能力,突破传统任务边界。
- PaLM(2020):5400亿参数,验证规模对性能的推动作用。
【对话与多模态融合阶段:2021年至2023年】
对话式AI突破(2022)
- ChatGPT(2022):基于RLHF对齐人类偏好,成为首个现象级对话模型。
- Claude/Gemini(2023):优化安全性与多轮交互能力。
多模态能力扩展(2023-2024)
- GPT-4(2023):整合文本、图像输入,支持复杂跨模态任务。
- Gemini 1.5 Pro(2024):支持百万级上下文长度与视频处理。
【推理优化与专业化发展阶段:2024年到现在】
推理能力突破
- DeepSeek-R1(2025):采用混合专家(MoE)与多阶段强化学习,显著提升数学与逻辑推理能力,降低50倍运营成本。
- 思维链(CoT):通过分步推理解决复杂问题,接近人类“系统2思维”。
专业化与开源趋势
- 领域模型:如医疗领域的Med-PaLM、代码生成模型DeepSeek Coder,在特定任务超越通用模型。
- 开源生态:Meta的Llama 3、DeepSeek-R1开源推动技术普惠。
下面我们简单了解一下LLM大模型训练流程。

【预训练阶段】
- 目标:通过无监督学习(如掩码语言建模、自回归预测)从海量文本中学习语言模式。
- 数据预处理:清洗、分词(Tokenization)、构建输入序列(如512-4096个Token的上下文窗口)。
【微调阶段】
- 监督学习:在特定任务(如问答、翻译)的标注数据上优化模型参数。
- 强化学习(RLHF):通过人类反馈调整生成内容的质量与安全性(如ChatGPT)。
【推理生成】
- 解码策略:采用束搜索(Beam Search)、核采样(Nucleus Sampling)等技术平衡生成结果的多样性与准确性。
- 增强技术:检索增强生成(RAG)结合外部知识库提升事实性。
现在我们对LLM已经有了清晰的认识,下面我们继续了解一下2025年LLM发展状况。
首先我们要了解一下当下AI技术突破与架构革新。
【模型架构创新】
- 混合架构主导:MoE(混合专家)架构成为主流,如DeepSeek R1模型总参数达671B(激活参数37B),训练成本仅557万美元。同时,Transformer架构逐步被Mamba等混合架构替代,支持更高效率的长序列处理。
- 多模态融合:Google Gemini 2.5 Pro支持200万token上下文窗口,原生整合文本、图像、视频数据,应用于医疗影像分析(如Med-LVLMs模型提升疾病筛查准确率22%)。OpenAI与Figure AI合作的具身智能机器人,通过多模态交互实现物理环境操作。
- 端侧轻量化:微软Phi-3、字节Seed-Thinking等轻量模型(200B参数)支持移动端离线部署,Google Gecko模型可在旗舰手机运行实时语音交互。
【训练与推理优化】
- 合成数据驱动:2025年合成数据市场规模增长30%,联邦学习技术降低数据依赖,训练能耗较前代降低40%。DeepSeek R1采用纯强化学习范式,无需监督数据即可实现数学推理能力比肩GPT-4o。
- 推理能力扩展:通过“等待标记”插入、回溯机制(StepBack)等技术,长推理链稳定性提升,吞吐量最高增加4倍。OpenAI O3模型支持自主工具调用,实现复杂任务自动化。
下面我们来看下常见AI大模型性能对比。
| 模型名称 | 上下文长度 | 多模态支持 | 训练成本 | 能效比(TOPS/W) | 典型场景 |
|---|---|---|---|---|---|
| OpenAI GPT-4.5 | 100万token | 是 | 1.2亿美元 | 12.5 | 科研、法律咨询 |
| DeepSeek R1 | 128k token | 否 | 557万美元 | 18.3 | 数学竞赛、量化交易 |
| 阿里Qwen 2.5-Max | 128k token | 是 | 3000万美元 | 15.0 | 电商客服、多语言翻译 |
| Google Gemini 2.5 Pro | 200万token | 是 | 未披露 | 10.8 | 医疗影像分析、智能体生态 |
| 华为盘古工业版 | 64k token | 是 | 2000万美元 | 20.1 | 工业流程优化、能源管理 |
1.2 智能体
AI智能体(AI Agent)是一种能够自主感知环境、规划任务并执行决策的智能程序,其核心突破在于理解复杂指令、调用工具链、动态学习反馈的能力。
相较于传统AI模型,智能体具备:
- 自主性:无需人工干预即可完成端到端任务(如自动订餐、生成报告);
- 多模态交互:支持文本、图像、语音等多形式输入输出(如谷歌Gemini 2.0);
- 工具调用:集成API、数据库、硬件设备等资源,实现跨平台操作。
2025年被普遍认为是“智能体元年”,其爆发性增长源于以下核心驱动因素:
-
技术成熟度提升:大语言模型(LLM)的推理、规划和工具调用能力显著增强,例如GPT-4o的视觉理解能力和智谱AutoGLM的多步跨APP操作技术。
-
行业需求激增:企业面临降本增效压力,AI智能体在客服、数据分析、流程自动化等领域替代重复性人力,如京东内部已部署超7000个智能体,效率提升50%。
-
生态标准化加速:国内成立“IIFAA智能体可信互连工作组”,推动跨平台服务调用与数据互通;国际巨头如微软、OpenAI推出企业级Agent产品,形成技术-商业闭环。
-
开发门槛降低:零代码平台(如字节跳动扣子、机智云Gokit5)和开源模型(DeepSeek-R1)普及,使个人开发者也能快速构建智能体。
总的来说,2025年,AI智能体正从技术概念转化为生产力工具,其应用已深入医疗、教育、工业等核心领域。开发者可通过低代码平台快速入局,但需注重场景聚焦与业务理解。未来,随着技术迭代与生态完善,AI智能体将成为推动社会智能化的核心引擎。
现在很多公司都推出了自己公司的AI智能体,例如文心一言的阅读助手、AI面试官、学术检索专家等。

现在我们大概知道了智能体的概念,那么作为一个开发者我们如何去看法属于自己的AI智能体呢?
【需求定义与模型选择】
- 明确应用场景(如客服、数据分析)并选择适配的LLM。闭源模型(GPT-4o、Claude 3.5)适合复杂任务,开源模型(Llama 3.2、Qwen 2.5)更灵活。
- 评估模型性能:通过MMLU(推理能力)、HumanEval(编码能力)等基准测试筛选。
【架构设计与工具集成】
- 控制逻辑:采用ReAct(推理-行动循环)或“计划后执行”模式,通过提示词工程定义行为规则。
- 工具链:集成API(如支付、导航)、RAG(检索增强生成)工作流,例如调用外卖APP完成咖啡订购。
【记忆与优化策略】
- 短期记忆(滑动窗口)与长期记忆(向量数据库)结合,提升多轮对话连贯性。
- 通过超参数调优(如学习率、正则化)和用户反馈迭代模型。
二、MCP简介
2.1 核心概念
MCP(Model Context Protocol,模型上下文协议)是由人工智能公司Anthropic于2024年11月推出的开放标准协议。其核心目标是解决AI工具与外部系统间的数据孤岛问题,通过标准化接口实现大型语言模型(LLM)与数据源、工具的无缝交互,类似于为AI世界提供“USB-C接口”。
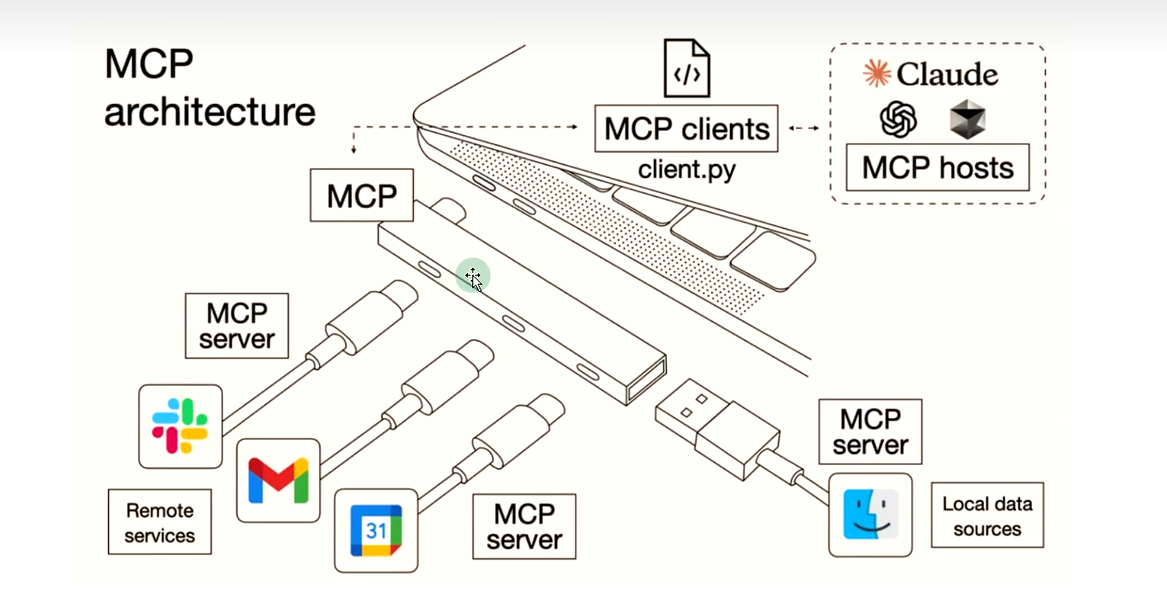
MCP作为一种标准化协议,极大的简化了大预言模型和外部世界之间的交互方式,使得开发者能够以统一的方式为AI应用添加各种能力。
接着我们了解了MCP的技术特性。
【双向通信架构】
采用客户端-服务器模型,支持JSON-RPC 2.0协议,允许AI模型与工具双向请求与响应(如模型可主动调用工具,工具也可反向请求模型生成内容)。
【动态工具发现】
服务器可向客户端动态注册可用工具,无需预先硬编码集成。
【模块化设计】
将功能拆分为三类组件:
- 资源(Resources):静态数据(如文件、数据库记录)
- 工具(Tools):可执行函数(如发送邮件、API调用)
- 提示(Prompts):预定义交互模板。
【安全机制】
通过会话ID加密、权限分级和本地化部署保障数据隐私。
2.2 发展历史
- 2022年11月:OpenAI发布ChatGPT,展示大模型潜力,但缺乏外部工具交互能力。
- 2023年6月:OpenAI推出Function Calling功能,允许通过API调用外部工具,但存在接口碎片化问。
- 2024年11月:Anthropic开源MCP协议,首次提出标准化连接层、上下文管理和安全控制三位一体的架构。
- 2024年末:社区开发者贡献超1000个连接器(如Git仓库、数据库适配器),初步形成生态网络效应。
- 2025年3月:OpenAI宣布全面支持MCP,集成至Agents SDK及ChatGPT桌面应用,标志主流厂商认可。
- 2025年4月:百度地图通过MCP接入千帆大模型,实现“语音指令→路径规划→实时导航”全链路服务,响应速度提升40%。
2.3 传统智能体开发&MCP协议开发智能体
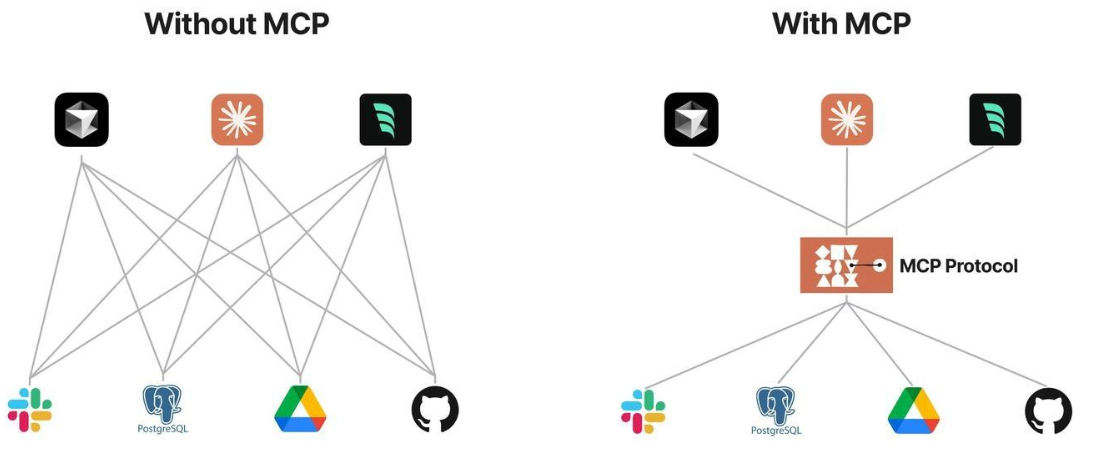
通过上图我们可以看出传统AI智能体集成为每个数据源构建独立的连接方式,这就会造成架构碎片化,难以扩展,限制了AI获取必要上下文信息的能力。相对而言,MCP提供统一且可靠的方式来访问所需要数据,克服了以往集成方法的局限性。
| 对比维度 | 传统智能体开发 | MCP开发智能体 |
|---|---|---|
| 架构设计 | 去中心化架构,智能体间直接通信 | 集中式架构,通过中央编排器统一管理 |
| 集成复杂度 | 需要为每个工具/数据源编写独立适配代码,复杂度为N×M | 标准化接口统一接入,复杂度降为N+M |
| 开发成本 | 高成本(需处理多种API对接、错误处理等) | 降低90%开发成本(通过协议自动适配) |
| 工具调用方式 | 需要预先编程定义调用规则 | 动态发现并调用工具,支持实时工具扩展 |
| 扩展性 | 新增工具需重新设计交互逻辑 | 通过统一模式快速接入新工具 |
| 维护工作量 | 高(需维护多个独立接口) | 低(集中式协议管理) |
| 通信机制 | 自定义通信协议(如HTTP/RPC) | 标准化语义描述调用(JSON/Protobuf) 2 10 |
| 自主性 | 依赖预编程指令 7 | 支持动态决策(编排器可调整执行策略) |
| 典型使用场景 | 单一任务处理(如独立客服机器人) | 复杂协作场景(如跨系统自动化、多智能体协作) |
| 典型开发流程 | 需经历需求分析→数据准备→模型训练→接口开发→部署监控等全流程 | 聚焦业务逻辑设计,工具调用通过协议自动完成 |
| 安全治理 | 分散在各子系统实现 | 集中式安全控制(统一认证/审计) |
| 学习成本 | 高(需掌握多种技术栈) | 低(只需遵循协议规范) |
| 典型应用案例 | 独立运行的聊天机器人、单任务自动化工具 | 企业级ERP自动化、跨平台视频创作助手 |
如果想要更好的了解MCP协议,我们可以参考官方文档:Introduction - Model Context Protocol。
2.4 MCP查询平台
MCP查询平台是一个专为特定行业或组织设计的数据管理与查询系统,通常用于整合、存储和快速检索关键业务数据。
下面我们将了解常见的一些MCP查询平台。
2.4.1 Smithery
全球最大的MCP服务器注册表,收录超过3000个MCP Server,支持一键复制安装命令,适合快速集成到开发环境。
使用方式:
- 访问官网:https://smithery.ai/
- 筛选服务:通过标签(如GitHub、Slack)或关键词搜索所需服务。
- 获取命令:点击服务卡片,复制对应的安装命令(如
curl或npm指令),粘贴到客户端工具(如Cursor、Cline)中运行即可完成配置。 - 社区审核:用户可查看社区贡献的服务评价,确保服务可靠性。
2.4.2 阿里云百炼MCP平台
企业级全托管服务,支持一键开通预置MCP服务(如高德地图、Notion),无需本地配置。
使用方式:
- 进入控制台:登录阿里云百炼平台(百炼控制台),访问“MCP广场”。
- 开通服务:选择预置服务(如Amap Maps),点击“立即开通”完成云端部署。
- 集成应用:在智能体或工作流应用中拖拽添加服务,通过自然语言指令触发调用(如查询天气、路径规划)。
- 监控管理:通过函数计算(FC)查看服务调用日志及计费详情。
2.4.3 PulseMCP
活跃的社区资源平台,收录超3200个服务,整合新闻动态和客户端工具。
使用方式:
- 访问官网:https://pulsemcp.com/
- 资源检索:在“Servers”页面按类别(如代码管理、生产力工具)筛选,或通过关键词搜索。
- 客户端整合:直接下载配套工具(如Claude桌面端、Fleur插件)并导入服务配置。
- 社区互动:通过“News”板块跟踪MCP生态更新,参与技术论坛讨论。
2.4.4 Awesome MCP Servers
GitHub开源项目,分类清晰且支持中文,适合开发者学习源码和实现逻辑。
使用方式:
- 访问官网:Awesome MCP Servers
- 选择对应MCP服务
- 点击进入对应的MCP服务的GitHub
2.4.5 mcp.so
分类详尽,覆盖4600+服务,支持客户端工具推荐,适合跟踪新趋势。
使用方式:
- 访问官网:https://mcp.so/
- 分类浏览:在“Servers”中按工具类型(如GitHub、Google Calendar)查找服务;在“Clients”中获取兼容的客户端工具(如Portkey、Cline)。
- 动态订阅:通过“Feed”栏目订阅新服务上线通知,实时获取更新。
- 快速集成:直接复制服务ID或API端点,嵌入开发环境配置文件中。
2.4.6 Cursor Directory
专为Cursor编辑器定制的资源库,支持规则引擎联动自动化流程。
使用方式:
- 访问官网:https://cursor.directory/mcp
- 安装服务:在Cursor编辑器内输入
/mcp install [服务ID],自动加载配置。 - 规则配置:结合Cursor的自动化规则(如代码提交触发GitHub Action),实现MCP服务与开发流程的深度集成。
2.5 MCP用途
通过前面的内容,我们已经知道MCP(Model Context Protocol)是由Anthropic推出的开放协议,旨在为大型语言模型(LLM)与外部数据源及工具提供标准化交互桥梁。
2.5.1 标准化数据访问与集成
-
动态连接多源数据:MCP允许AI模型通过统一接口接入数据库、文件系统、API等资源。例如,开发者无需为每个数据源单独开发接口,只需通过JSON-RPC 2.0协议,即可实现“即插即用”式数据访问。例如,用户查询数据库时,MCP可自动检索并返回结构化数据。
-
混合存储架构支持:支持整合本地资源(如本地文件)和远程资源(如云API),并通过上下文感知索引算法快速定位数据。实验显示,MCP在百万级数据量的知识库中检索准确率达92.3%,存储开销降低30%。
2.5.2 统一工具调用与功能扩展
-
标准化工具调用流程:MCP通过JSON Schema定义工具输入输出格式,支持同步/异步调用模式。例如,开发者可定义天气查询工具,通过MCP服务器实现动态注册和调用。工具调用需用户授权,确保操作透明可控。
-
解决传统接口碎片化问题:相比OpenAI等平台的Function Call(需重写代码切换模型),MCP提供跨平台标准化协议。例如,AI编程助手可调用代码搜索工具检索项目代码,或查询数据库获取表结构,无需依赖特定LLM提供商。
2.5.3 动态上下文管理与优化
-
多轮对话上下文管理:MCP通过语义感知压缩技术处理长上下文,采用动态量化编码(如高频交互段落保留FP16精度,背景知识用4-bit压缩),使模型能处理更长的上下文窗口,压缩率高达5.8倍,仅使困惑度上升2.3%。
-
分层缓存架构:引入L1-L3三级缓存:L1缓存当前对话窗口(5-10轮),L2缓存高频外部知识(更新周期1小时),L3持久化存储核心业务数据(支持版本回滚)。例如,电商客服系统通过该架构实现90%的本地命中率。
2.5.4 多场景应用支持
- AI编程助手:在Cursor等IDE中,MCP可动态获取代码库、文档或运行环境信息。例如,当用户询问函数定义时,AI通过MCP调用代码搜索工具检索项目文件,生成精准建议。
- 企业自动化与智能客服:集成CRM、邮件系统等工具,AI可自动处理任务(如读取Excel生成报告、发送Slack消息)。数据全程本地处理,避免外泄。
- 医疗:集成患者病史和实验室数据,辅助生成诊断建议。
- 教育:调用知识库生成多语言学习材料。
- 金融:分析实时市场数据生成投资报告。
2.6 MCP通信机制
MCP(Model Context Protocol)的通信机制是其实现AI模型与外部资源交互的核心。
2.6.1 传输层协议
MCP支持两种通信方式以适应不同场景:
-
本地通信(stdio):客户端通过标准输入输出(stdin/stdout)与本地服务器子进程交互,采用同步阻塞模式。例如在IDE插件中调用本地文件系统时,客户端直接启动服务器程序,通过管道传递JSON-RPC消息。
-
远程通信(HTTP SSE):基于HTTP协议的Server-Sent Events(SSE)实现长连接,支持异步事件驱动。客户端通过POST发送请求,服务器持续推送数据流,适用于分布式系统或高并发场景,如远程数据库查询。
2.6.2 消息格式与类型
采用JSON-RPC 2.0标准定义消息结构,包含四类消息:
- 请求(Request):客户端发起的操作指令,如
callTool工具调用请求,包含唯一ID标识。 - 结果(Result):服务器成功处理后的响应数据,例如返回数据库查询结果。
- 错误(Error):包含错误代码和描述,如参数校验失败时返回
{"code":-32602, "message":"Invalid params"}。 - 通知(Notification):单向事件推送(如资源更新),无需响应,用于实时同步数据变化。
2.6.3 双向交互机制
突破传统API的单向限制:
- 服务器主动交互:在执行敏感操作(如文件删除)时,服务器可向客户端发送权限确认请求,用户授权后继续流程。
- 动态上下文更新:服务器通过通知机制推送新数据,触发AI模型的实时响应,例如监控系统中的异常警报。
2.6.4 能力协商机制
连接初始化时进行能力声明交换:
- 服务器声明支持的功能(如资源类型、工具列表、提示模板)。
- 客户端声明处理能力(如支持的采样率、通知接收方式)。
- 双方后续交互必须遵守声明限制,例如服务器不可调用未声明的工具。
2.6.5 安全设计
- 会话级加密:通过
Mcp-Session-ID实现通信加密,防止中间人攻击。 - 沙箱隔离:限制工具访问范围,如文件工具仅能读写指定目录。
- 细粒度授权:每次工具调用需用户显式批准,避免越权操作。
2.7 Function Calling
2.7.1 定义
Function Calling是一种结构化调用技术,允许AI大模型(如GPT、Claude)在生成文本时输出预定义函数的名称和参数(通常以JSON格式),由外部系统执行具体操作并返回结果。
例如:
【天气查询场景】
用户提问“上海明天的温度?”,模型生成{"name": "get_weather", "arguments": {"city": "上海"}},开发者调用对应API获取数据后反馈给模型生成最终回答。
实现步骤:
- 函数定义:声明函数名称、参数类型及描述(如Spring AI通过
@Bean注册函数); - 模型交互:在Prompt中明确要求模型使用结构化输出;
- 参数解析:验证JSON参数格式(如通过JSON Schema);
- 结果处理:将执行结果返回模型生成自然语言响应。
2.7.2 技术特点
- 精准性:需严格定义参数类型(如枚举值
unit: ["C", "F"])以减少歧义; - 依赖模型训练:需模型具备识别调用意图的能力,部分模型(如Coze的某些版本)不支持此功能;
- 单向流程:通常为同步单任务调用,扩展性较弱。
2.7.3 Function Calling & MCP
MCP将Function Calling作为其工具调用的一种实现方式,但功能更全面。例如,MCP可同时调用多个函数,并自动管理上下文和历史交互。
| 维度 | Function Calling | MCP |
|---|---|---|
| 调用方式 | 预定义函数的JSON调用 | 动态发现工具+标准化协议交互 |
| 数据格式 | 固定参数结构(如OpenAI的tools字段) | 兼容多种格式(JSON、自然语言) |
| 适用场景 | 单一API任务(如天气查询) | 复杂业务流程(如数据分析+邮件通知) |
| 开发复杂度 | 需手动解析参数与错误处理 | 通过SDK自动封装调用流程 |
| 生态系统 | 依赖厂商API(如OpenAI) | 开源协议,支持跨平台工具集成 |
MCP中包含Functing Calling,它们在开发设计的时候可以搭配起来使用。
