Node Exporter 介绍
Node Exporter 是一个开源的 Prometheus 指标收集器,它提供了大量关于宿主机系统的关键指标,如 CPU、内存、磁盘和网络使用情况。在 Kubernetes 环境中,Node Exporter 对于监控集群节点的健康状况至关重要。本文将介绍如何在 Kubernetes 环境中部署 Node Exporter,并通过 DataKit 采集器将指标通过观测云进行监控和展示。
主要功能:
- 系统监控:Node Exporter 能够采集主机包括 CPU 使用情况、内存使用量、磁盘 I/O 统计、网络流量等关键系统指标。
- 低依赖性:Node Exporter 用 Go 语言编写,无需第三方依赖,易于部署和运行。
- 配置灵活性:提供多种启动参数,允许用户自定义监听端口、数据路径、日志级别等设置。
- 数据格式兼容:输出的数据格式遵循 Prometheus 标准,确保与 Prometheus 服务器的兼容性。
- 多种部署方式:支持二进制直接部署和 Docker 容器部署,适应不同的生产环境。
观测云
观测云是一款功能强大的统一可观测平台,它提供了对多云环境、云原生应用、中间件以及各类应用程序的实时监控和分析能力。
部署在 Kubernetes 集群中的 Node Exporter 会暴露一个 metrics 端点,DataKit 通过这个端点拉取指标数据。DataKit 通过 ConfigMap挂载额外的配置文件,或者通过环境变量直接在 Kubernetes 的 DaemonSet 配置中设置。这样,DataKit 就可以根据用户的配置,定期从 Node Exporter 收集指标数据,并将其发送到观测云平台。下面介绍在主机部署 Node Exporter 组件,采集主机指标并通过 DataKit 进行收集、存储,最后通过观测云用于数据的可视化展示。
操作步骤
安装 Node Exporter
在 k8s 环境中创建 DaemonSet 配置文件 node-exporter.yaml。
apiVersion: apps/v1
kind: DaemonSet
metadata:name: node-exporternamespace: monitor-salabels:name: node-exporter
spec:selector:matchLabels:name: node-exportertemplate:metadata:labels:name: node-exporterspec:hostPID: true # 使用主机的PIDhostIPC: true # 使用主机的IPChostNetwork: true # 使用主机的网络containers:- name: node-exporterimage: quay.io/prometheus/node-exporter:v0.18.1ports:- containerPort: 9100resources:requests:cpu: 0.15securityContext:privileged: trueargs:- --path.procfs- /host/proc- --path.sysfs- /host/sys- --collector.filesystem.ignored-mount-points- '"^/(sys|proc|dev|host|etc)($|/)"'volumeMounts:- name: devmountPath: /host/dev- name: procmountPath: /host/proc- name: sysmountPath: /host/sys- name: rootfsmountPath: /rootfstolerations:- key: "node-role.kubernetes.io/master"operator: "Exists"effect: "NoSchedule"volumes:- name: prochostPath:path: /proc- name: devhostPath:path: /dev- name: syshostPath:path: /sys- name: rootfshostPath:path: /---apiVersion: v1
kind: Service
metadata:name: node-exporternamespace: monitor-sa
spec:type: ClusterIPports:- name: httpport: 9100protocol: TCPtargetPort: 31672selector:name: node-exporter
然后执行以下命令:
kubectl create ns monitor-sa
kubectl apply -f node-exporter.yaml
执行完毕后,可通过 http://主机ip:31672/metrics 查看当前主机获取到的所有监控数据。
部署 DataKit
登录观测云控制台,点击「集成」 -「DataKit」 - 「Kubernetes」,下载 datakit.yaml ,拷贝第 3 步中的 token 。
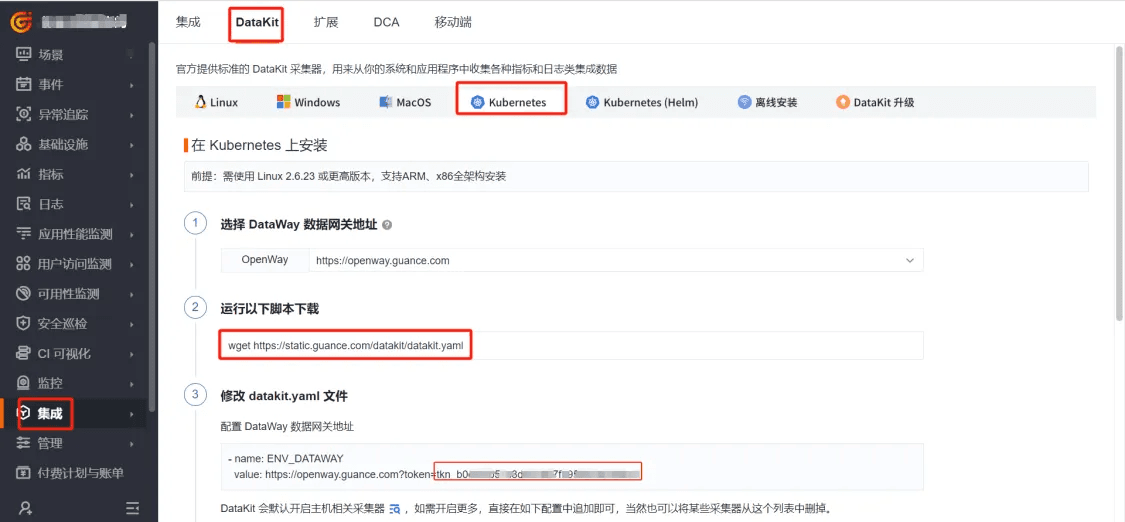
编辑 datakit.yaml ,把 token 粘贴到 ENV_DATAWAY 环境变量值中“token=”后面,设置环境变量 ENV_CLUSTER_NAME_K8S 的值并增加环境变量 ENV_NAMESPACE ,这两个环境变量的值一般和集群名称对应,一个工作空间集群名称要唯一。
- name: ENV_NAMESPACEvalue: xxxx
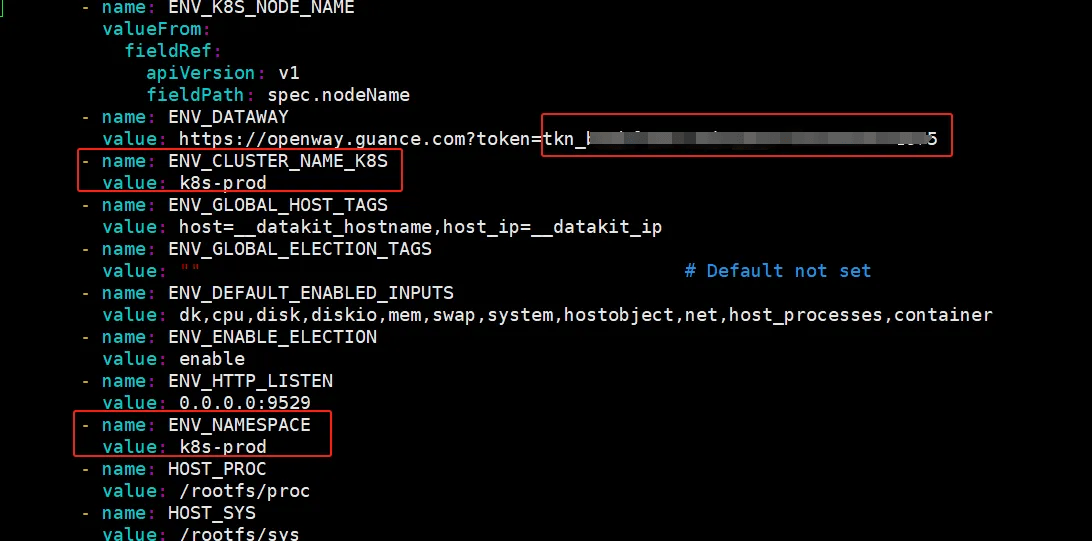
把 datakit.yaml 上传到可以连接到 Kubernetes 集群的主机上,执行如下命令:
kubectl apply -f datakit.yaml
kubectl get pod -n datakit
在 datakit.yaml 中配置 ConfigMap 资源来收集 Node Exporter 的指标数据。
apiVersion: v1
kind: ConfigMap
metadata:name: datakit-confnamespace: datakit
data:kubernetesprometheus.conf: |-[inputs.kubernetesprometheus]node_local = true # 是否开启 NodeLocal 模式,将采集分散到各个节点[[inputs.kubernetesprometheus.instances]]role = "service" # 必填 可以配置为 service、pod、endpoints、nodenamespaces = ["monitor-sa"] # 非必填,支持配置多个,以逗号隔开,为空会匹配所有selector = "" # 非必填,被采集资源的labels,用来匹配选择需要采集的对象 ,为空会匹配所有scrape = "true" # 非必需 采集开关,默认true,scheme = "http" port = "__kubernetes_service_port_%s_port " path = "/metrics" # 非必填 大部分prometheus采集路径都为/metrics,具体以被采集服务实际指标地址为准params = "" # 非必填 http 访问参数,是一个字符串,例如 name=nginx&package=middleware,非必需interval = "30s" # 非必填 采集频率,默认30s[inputs.kubernetesprometheus.instances.custom]measurement = "kube_NodeExporter" #非必填 观测云指标名,默认使用指标下划线第一个字母job_as_measurement = false #非必填 是否使用数据中的 job 标签值当做指标集名[inputs.kubernetesprometheus.instances.custom.tags]instance = "__kubernetes_mate_instance" #可选 指标taghost = "__kubernetes_mate_host" #可选 指标tagpod_name = "__kubernetes_pod_name" #可选 指标tagpod_namespace = "__kubernetes_pod_namespace" #可选 指标tag,可以继续新增,这里不继承全局tag和选举tag
然后在 datakit.yaml 中的 volumeMounts 下挂载 kubernetesprometheus.conf 。
- mountPath: /usr/local/datakit/conf.d/kubernetesprometheus/kubernetesprometheus.confname: datakit-confsubPath: kubernetesprometheus.confreadOnly: true
最后,执行以下命令重启 datakit 。
kubectl delete -f datakit.yaml
kubectl apply -f datakit.yaml
关键指标
登录观测云控制台,点击「指标」 -「指标管理」,输入“NodeExporter”,就能查询采集到的指标。

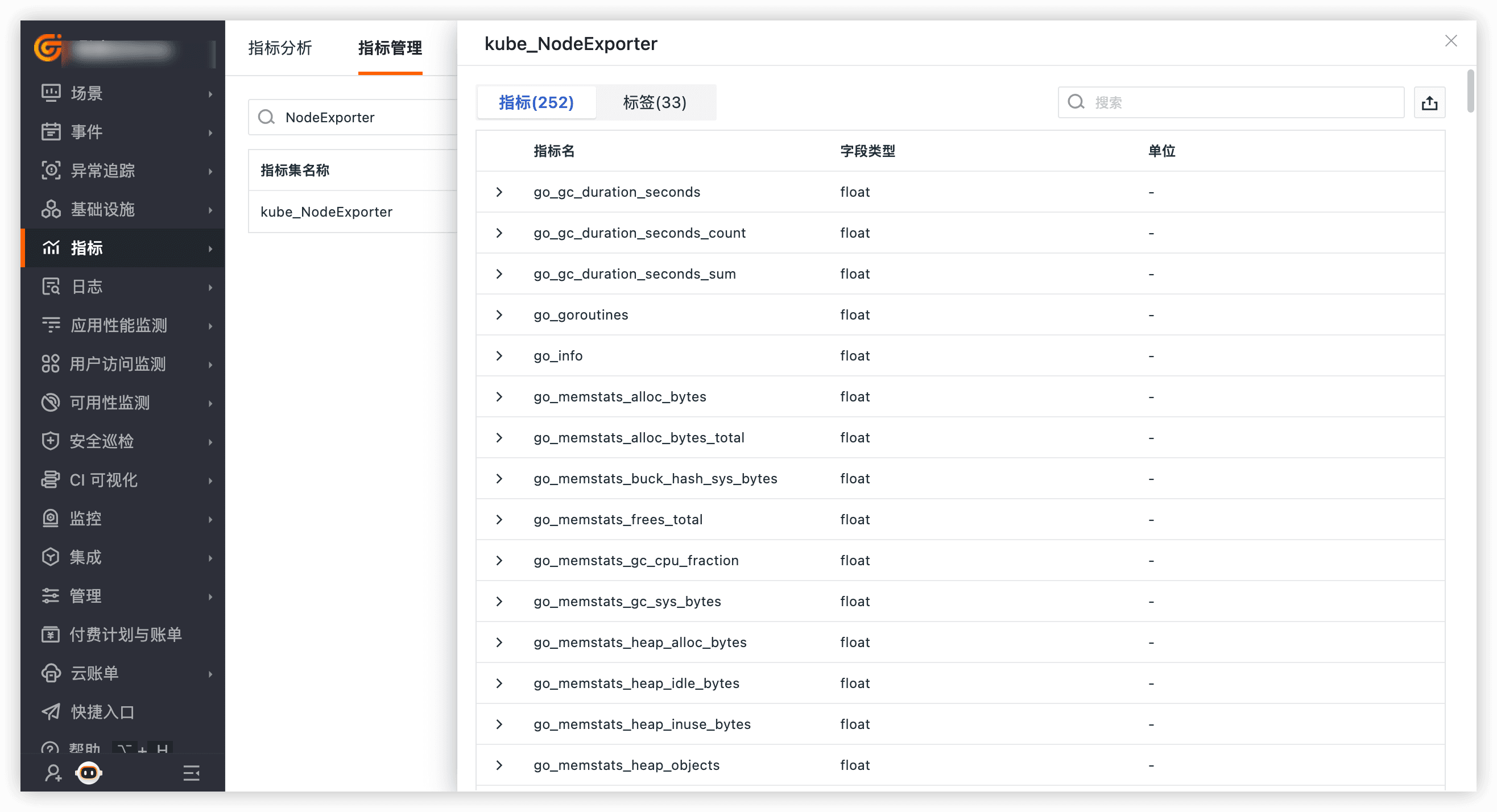
监控 Node Exporter 采集的主机指标时,主要需要从以下维度进行,通过综合监控这些维度,可以确保主机的高效运行和稳定性:
- 系统运行情况:包括 CPU、内存、磁盘以及网络相关信息。
- 系统资源使用:监控系统资源的使用情况,以优化资源分配并避免瓶颈。
- 硬件状态:监控硬件健康状态,预防硬件故障
- 服务健康度:监控系统服务的状态,确保服务的连续可用性。
以下是 Node Exporter 采集主机指标的关键指标目录:
| 指标 | 描述 | 单位 |
|---|---|---|
| node_network_receive_bytes_total | 网络接收的总字节数 | Bytes |
| node_network_transmit_bytes_total | 网络传输的总字节数 | Bytes |
| node_network_receive_errs_total | 网络接收时发生的错误总数 | count |
| node_network_transmit_errs_total | 网络传输时发生的错误总数 | count |
| node_network_transmit_drop_total | 网络传输时丢弃的包总数 | count |
| node_memory_Active_bytes | 活跃内存的使用量,包括主动使用和缓存的内存 | Bytes |
| node_memory_Inactive_bytes | 非活跃内存的使用量,包括非活跃使用的内存 | Bytes |
| node_memory_Buffers_bytes | 用于缓存磁盘数据的内存量 | Bytes |
| node_memory_Cached_bytes | 用于缓存文件系统的内存量 | Bytes |
| node_memory_SwapTotal_bytes | 总的交换空间大小 | Bytes |
| node_disk_io_now | 当前正在进行的I/O操作数量 | count |
| node_disk_io_time_seconds_total | 磁盘I/O操作的总耗时 | Seconds |
| node_disk_read_bytes_total | 从磁盘读取的总字节数 | Bytes |
| node_disk_written_bytes_total | 写入磁盘的总字节数 | Bytes |
| node_cpu_seconds_total | CPU使用的总时间 | Seconds |
| node_context_switches_total | 上下文切换的总次数 | count |
| node_filesystem_size_bytes | 文件系统的总大小 | Bytes |
| node_filesystem_free_bytes | 文件系统的可用大小 | Bytes |
| node_filesystem_avail_bytes | 文件系统对于非超级用户可用的大小 | Bytes |
重点指标说明
node_network_receive_bytes_total和node_network_transmit_bytes_total:这两个指标反映了主机的网络流量情况,对于监控网络性能和排查网络问题至关重要。node_memory_Active_bytes和node_memory_Inactive_bytes:这两个指标帮助监控内存的使用情况,区分活跃和非活跃内存,对于内存优化和故障排查很有帮助。node_disk_io_now和node_disk_io_time_seconds_total:这两个指标反映了磁盘 I/O 的负载和性能,高 I/O 负载可能影响系统性能。node_cpu_seconds_total:这个指标反映了 CPU 的使用情况,对于监控 CPU 性能和负载非常重要。node_filesystem_size_bytes、node_filesystem_free_bytes和node_filesystem_avail_bytes:这些指标反映了文件系统的使用情况,对于容量规划和性能优化至关重要。
通过监控这些关键指标,可以确保主机系统的稳定运行,及时发现并解决潜在的性能问题。
监控视图
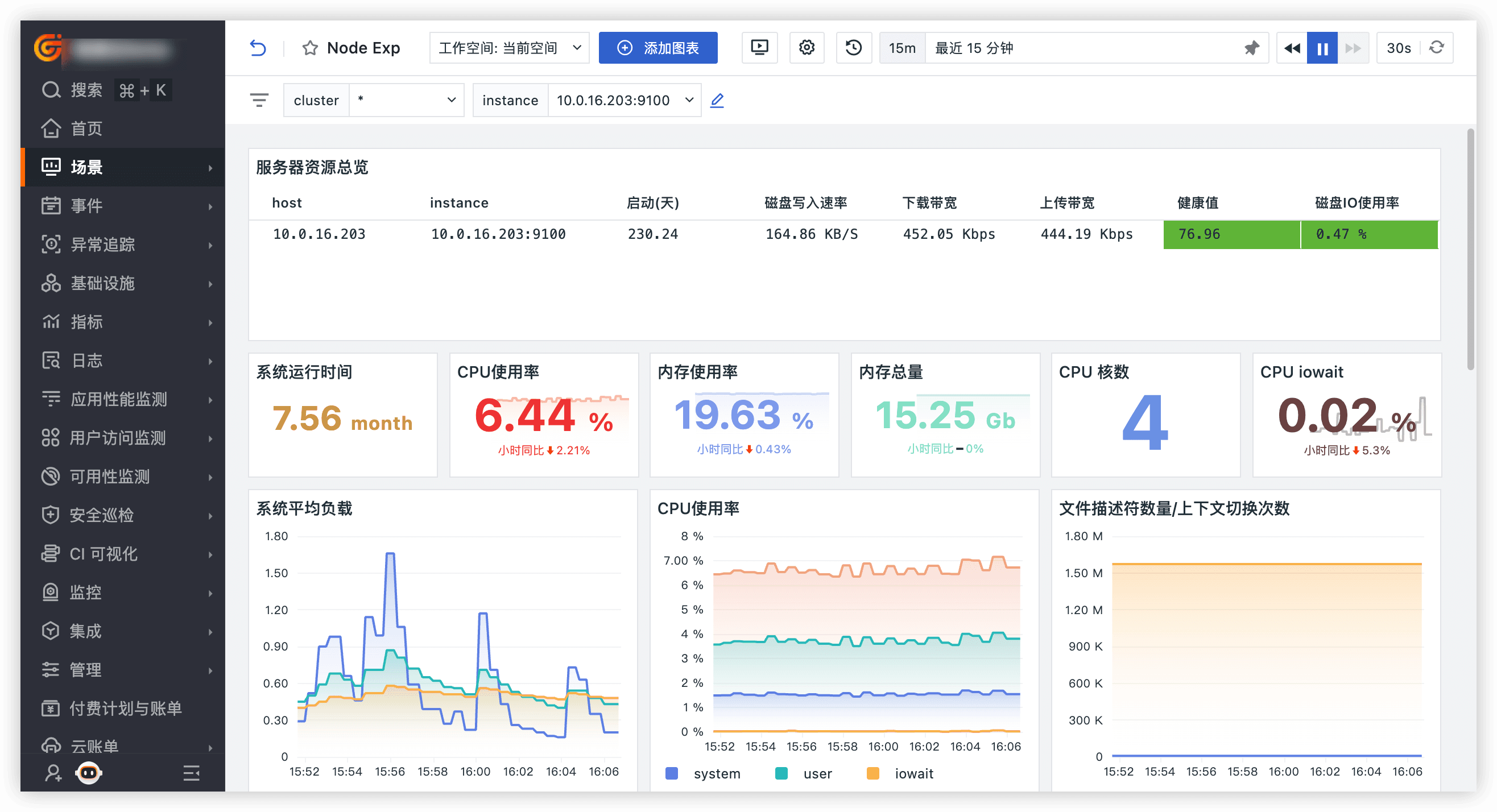
登录观测云控制台,点击「场景」 -「新建仪表板」,输入 “Node Exporter ”, 选择 “Node Exporter 监控视图”,点击 “确定” 即可添加内置视图:
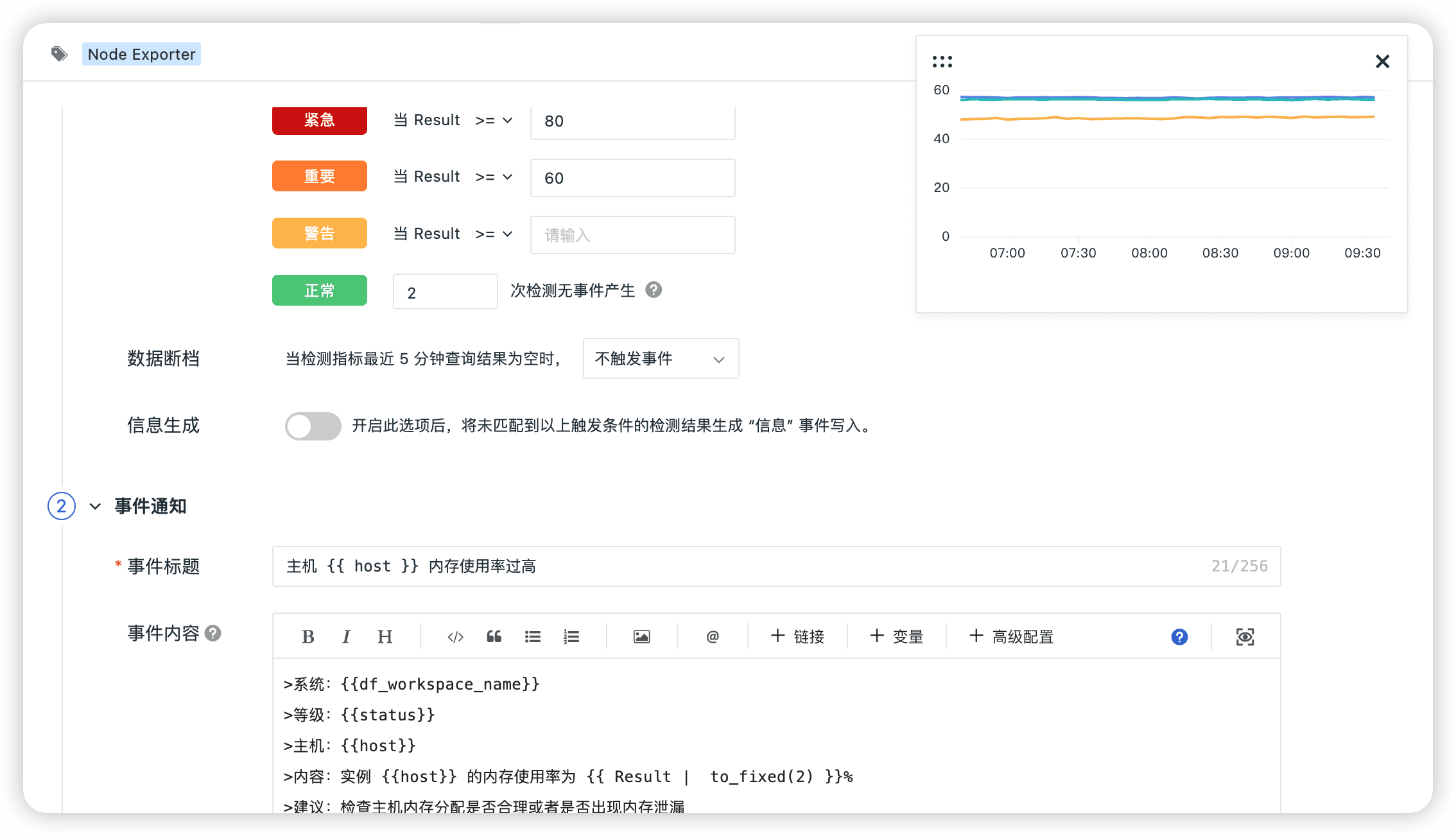
监控器(告警)
- 主机内存使用率过高

- 主机磁盘使用率过高
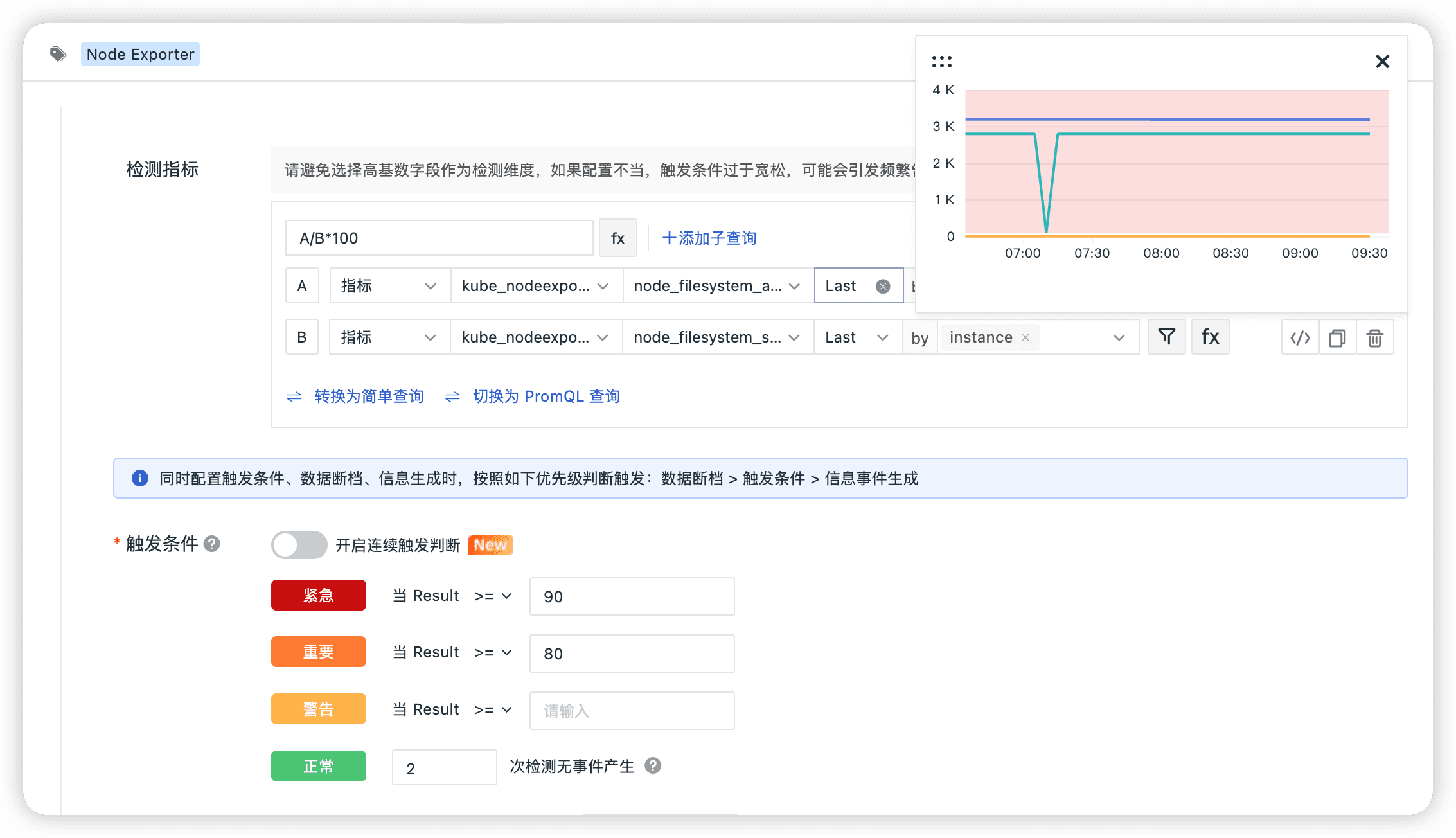
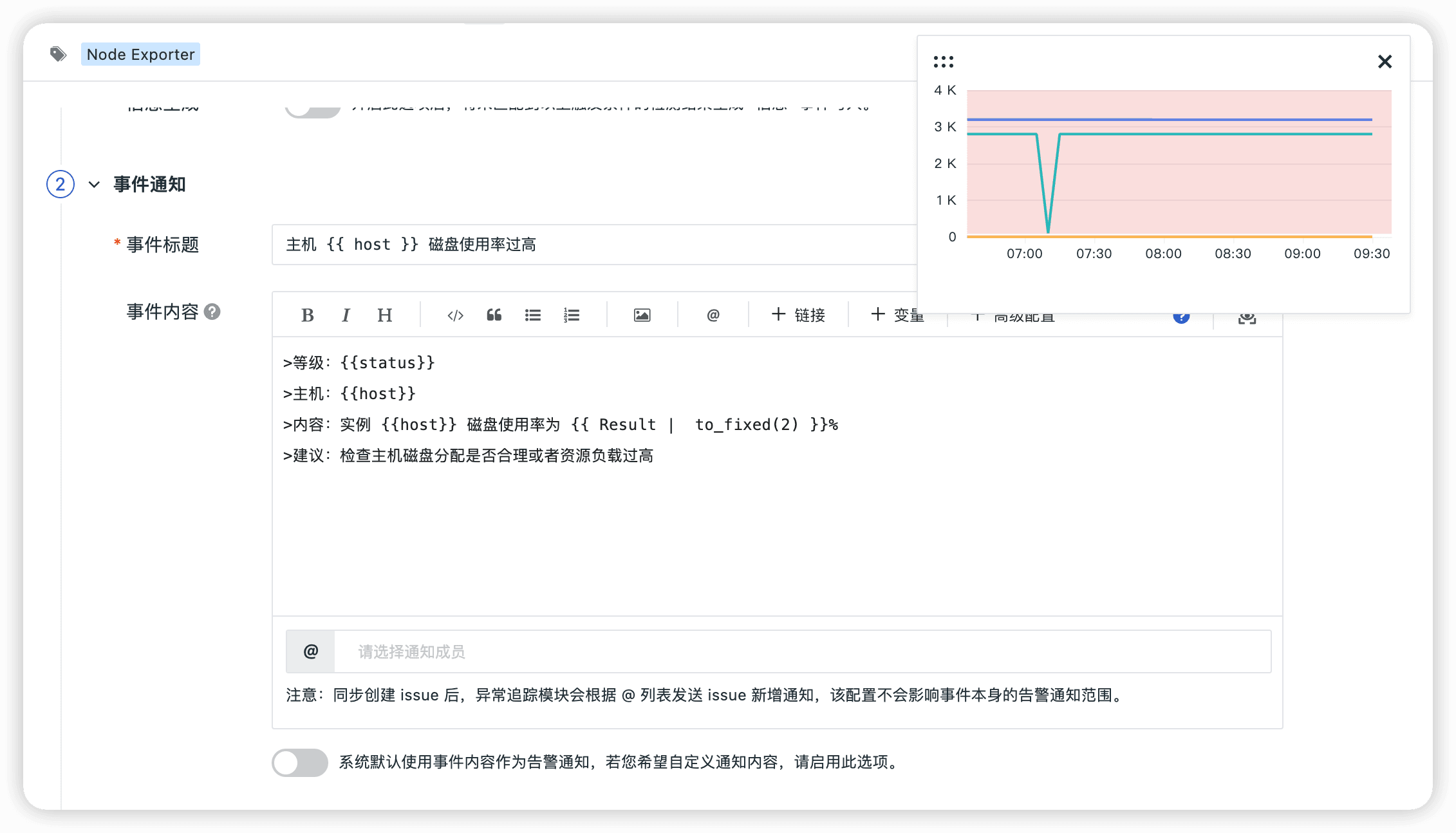
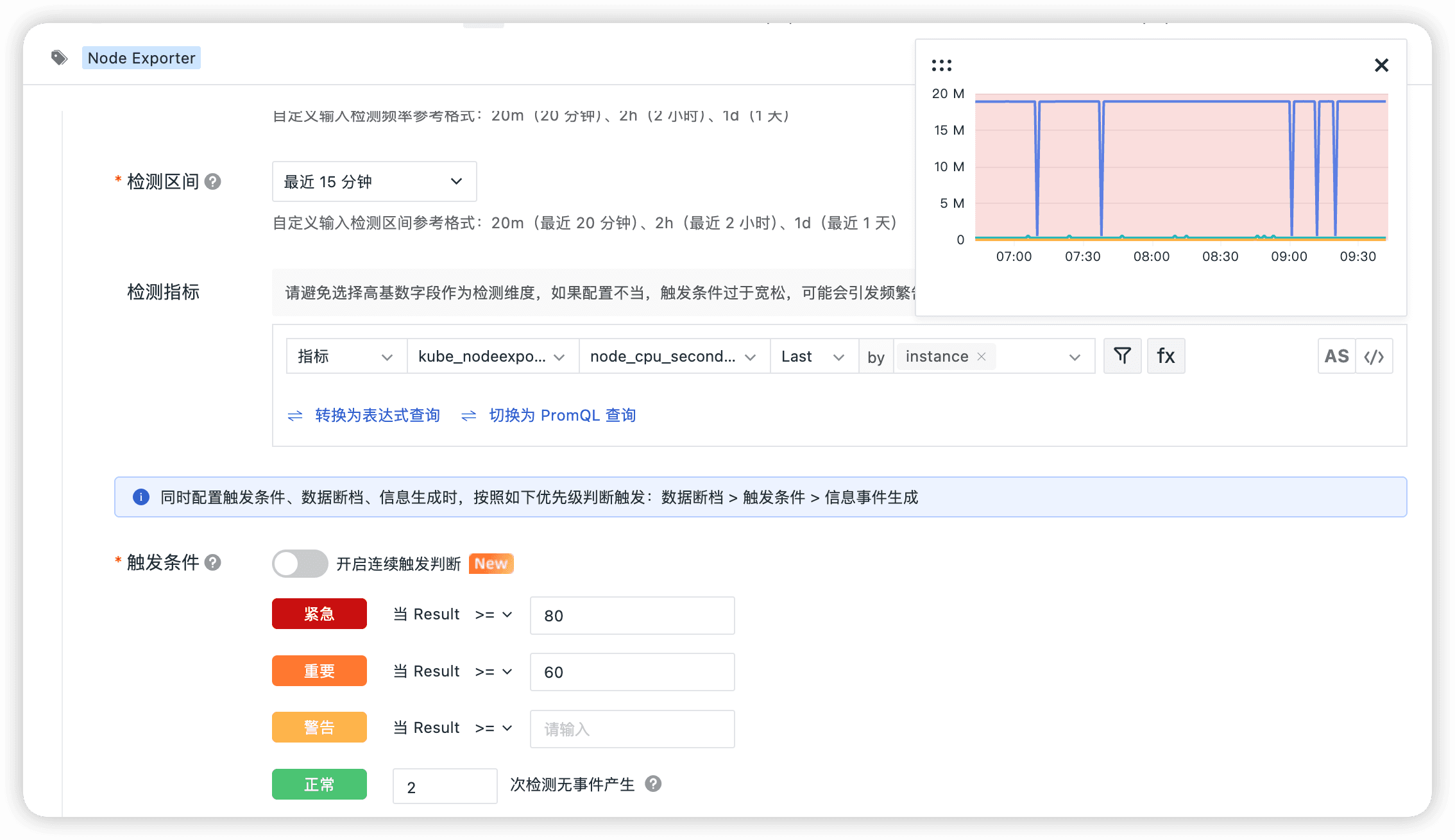
- 主机 CPU 使用率过高

总结
通过监控 Node Exporter 采集的主机关键指标,比如 CPU 使用率、内存和磁盘的 I/O 性能、网络流量和错误率、以及系统服务状态等,我们能够深入理解服务器的运行状况。这些指标覆盖了系统资源的使用情况、硬件健康状态、服务可用性以及网络效率,为我们提供了全面的系统性能视图。通过综合监控这些关键指标,可以及时发现并解决潜在的性能问题和故障,从而确保主机的高效运行和稳定性。这种持续的监控和分析对于维护服务器的最优性能和进行有效的容量规划至关重要。