Redis最佳实践
文章目录
- Redis的键值设计
- key的设计
- BigKey
- 选择最适合的数据结构
- 2. 批处理优化
- 2.1 Pipeline
- 集群下的批处理
- 持久化配置
Redis的键值设计
key的设计
Redis的key设置遵从的几个规则
- 遵循基本格式:
[业务名]:[数据名]:[数据id] - 长度不超过44字节
- 不包含特殊字符
如:登录业务保存用户数据 key可以设置为 login:user:10
分层的key结构设计优点
- 1.可读性强
- 2.避免key冲突
- 3.方便管理
为什么不超过44字节?
:key结构默认为string,但是其底层编码有三种,根据不同情况
- 1.当全是数字的时候存储为int,消耗内存最低
- 2.有字符,但是不超过44字节,按照embstr编码方式存储,该存储方式使用连续内存空间,内存占用更小
- 3.有字符超过44字节,采用raw存储方式,采用指针指向真正存储字符串的地方,空间不连续,访问时性能会收到一定的影响,有可能产生内存碎片。
注:key和value(string类型时)都遵循这种规则
BigKey
BigKey是什么?
BigKey通常以Key的大小和Key中成员的数量来综合判定(如果没有成员只看大小即可),例如:
- Key本身的数据量过大:一个String类型的Key,它的值为5 MB
String是单值的,最大存储为512M,达到5M就是一个非常大的k了。 - Key中的成员数过多:一个ZSET类型的Key,它的成员数量为10,000个
集合类型的key,比如list,set,成员数量达到1万个就会认为是BigKey。 - Key中成员的数据量过大:一个Hash类型的Key,它的成员数量虽然只有1,000个但这些成员的Value(值)总大小为100 MB
- 还有一些集合元素数量并不算多,但是每个成员都非常的大,最后合起来达到了100M,也会被称为BigKey。
推荐值:单个key的value值小于10KB,元素数量小于1000
BigKey的危害

如何发现BigKey
单个key分析
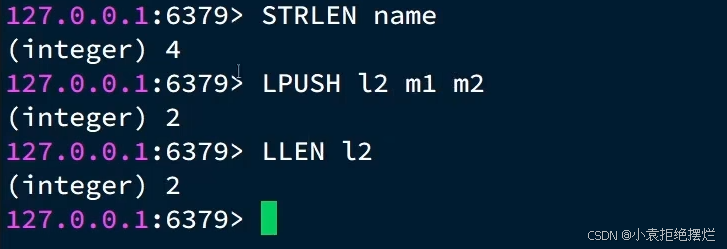
我们可以通过如下两个命令判断是否为bigkey
- STRLEN key:查看String类型的value的字节长度/字符长度(一个字符占一个字节)
- LLEN key:查看list集合的长度
全盘扫描
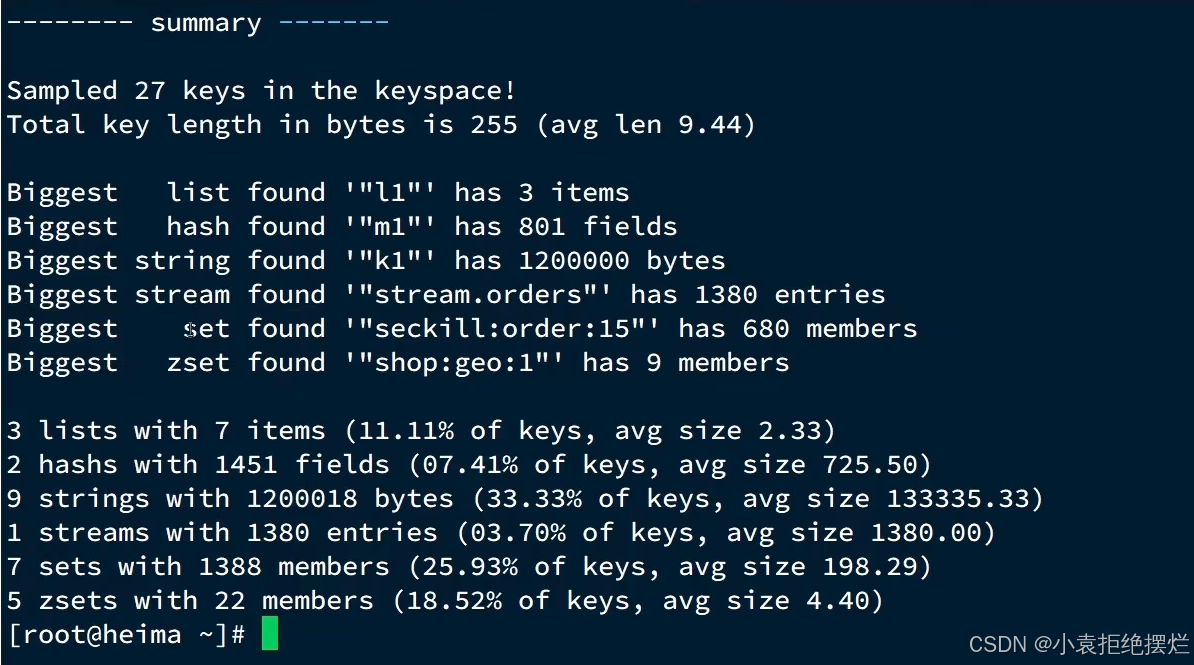
①redis-cli --bigkeys
利用redis-cli提供的–bigkeys参数,可以遍历分析所有key,并返回Key的整体统计信息与每个数据的Top1的big key
命令:redis-cli -a 密码 --bigkeys
注意:
-
不要在redis的控制台运行,而是在黑窗口运行。
-
得到的是每一种数据类型占用内存最多的那一个,排名第一的不一定是bigkey,即使第一个是bigkey那排名第二的也可能是bigkey,只显示排名第一可能就把排名第二的bigkey错过了。
-
这种方式的统计不够完整只能看到第一名,因此只做一个参考。
这种方式只能看到每种元素对应最大,而且他list是以元素计的,不是字节数,所以可能第二个比第一个占用字节还要大
第三方工具
利用第三方工具,如 Redis-Rdb-Tools 分析RDB快照文件,全面分析内存使用情况
https://github.com/sripathikrishnan/redis-rdb-tools
好处:对redis无侵入
缺点:它是离线方式,所以时效性比较差。
②第三方工具
- 利用第三方工具,如 Redis-Rdb-Tools 分析RDB快照文件,全面分析内存使用情况
- https://github.com/sripathikrishnan/redis-rdb-tools
好处:对redis无侵入
缺点:它是离线方式,所以时效性比较差。
③网络监控
- 自定义工具,监控进出Redis的网络数据,超出预警值时主动告警
- 一般阿里云搭建的云服务器就有相关监控页面(阿里云上部署redis)
如何删除BigKey?
找到BigKey后该怎么办呢?
首先:删除BigKey,但是不是说这部分数据不要了,而是把这份数据拆分后重新储存,这样就把BigKey打散了。
其次:选择合适的数据类型,分别存储,这样BigKey就变为小的key了。
BigKey内存占用较多,即便时删除这样的key也需要耗费很长时间,导致Redis主线程阻塞,引发一系列问题。
redis 3.0 及以下版本
如果是集合类型,则遍历BigKey的元素,先逐个删除子元素,最后删除BigKey
这里具体实现不说了,可以自己查一下
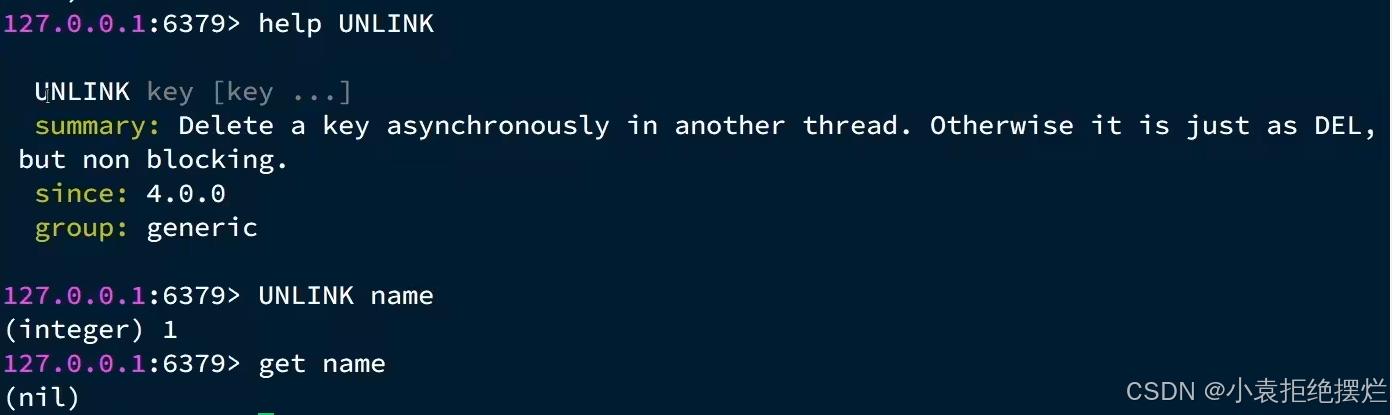
Redis 4.0以后
Redis在4.0后提供了异步删除的命令:unlink key(异步的删除key)
选择最适合的数据结构
例1:比如存储一个User对象,我们有三种存储方式
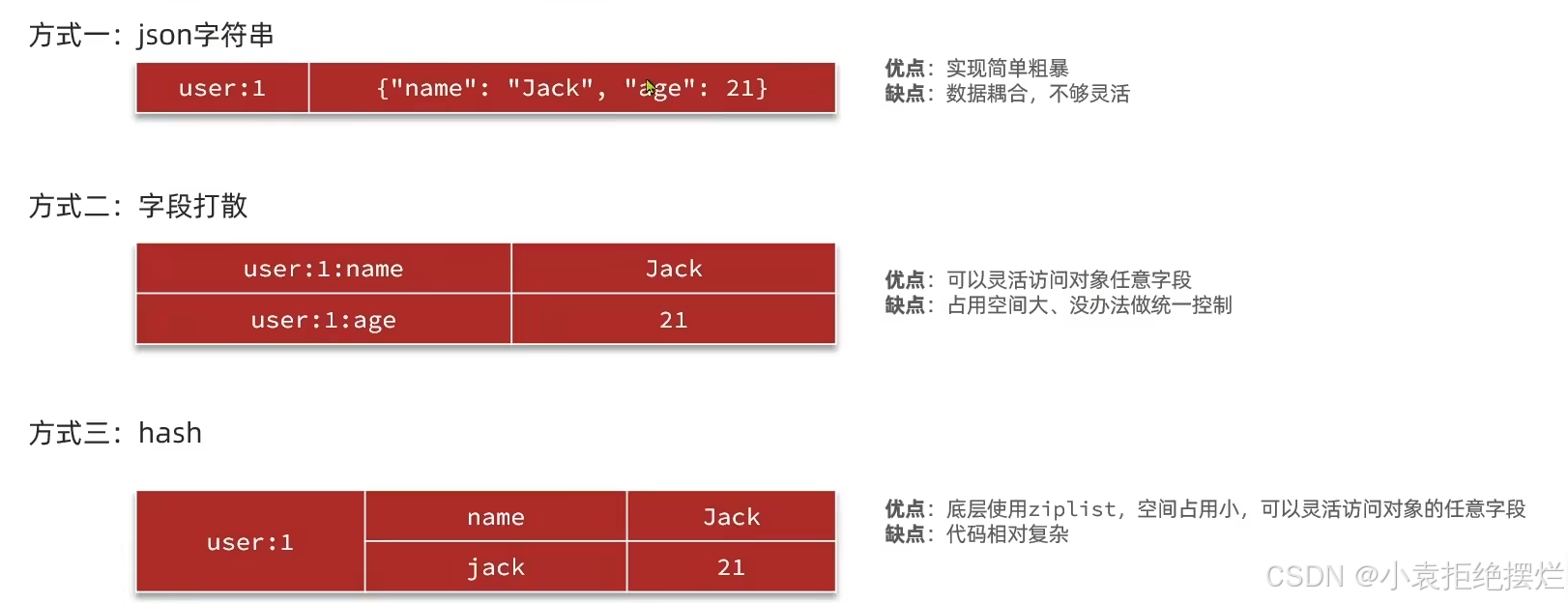
方式一:json字符串
挺平常的,如果是我的话我会用这种,来应对,读多写少的场景,因为json可以直接返回给前端不需要麻烦的处理
方式二:字段打散
原来一个key就能保存现在需要多个key,虽然从数据上看没有增多,但是每一次存储k-v结构在redis内部都是有很多原信息要保存的,key越多现在想要存储的元信息也越多。
现在想要获取user的所有信息,只能是一条条的获取。
方式三:hash(推荐)
v是一个hash结构
使用hash结构的时候,需要把user对象转化为hashmap的形式去存储,转化的时候考虑到对象的数据类型的转换,相较于json麻烦。
而json因为相对比较成熟,对象与json的序列化和反序列化都有非常成熟的解决方案了,不用考虑太多数据类型的问题。
不过市面上应该已经有成熟的工具类去帮我们做这个转换操作了,所以还是推荐这种方式
例2:假如有hash类型的key,其中有100万对field和value,field是自增id,这个key存在什么问题?如何优化?
| key | field | value |
|---|---|---|
| someKey | id:0 | value0 |
| … | … | |
| id:999999 | value999999 |
问题:
内存占用大
- 上面学写过hash结构底层使用ziplist,空间占用小。但是当hash的entry数量超过500时,会使用哈希表而不是ZipList,内存占用较多
- entry:一对k-v
解决方案
拆分为小的hash,将 id / 100 作为key, 将id % 100 作为field,这样每100个元素为一个Hash
解释:
- 将 id / 100 作为key:id是0~999999的100万条数据,100万除以100为1万条数据,也就是说将来会有1万个key,把一个hash拆分成了一万个hash,100万条数据放到1万个hash里每个hash有100条数据,没有超过500,底层用的还是ziplist。
- 将id % 100 作为field:
0~99一共100条id,这些id除以100结果都是0作为key,这些id取模的结果恰好是0到99,刚好形成一个hash。
100~199这些元素,除以100结果都是1作为key,取余是0到99。
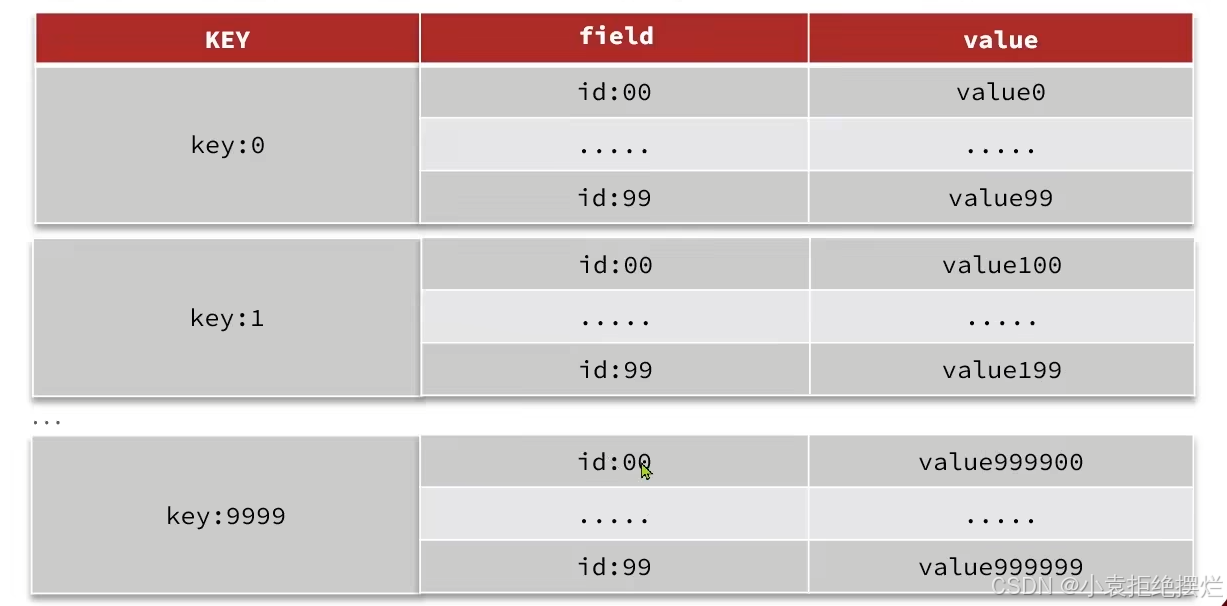
这个方法需要自己编程实现
2. 批处理优化
2.1 Pipeline
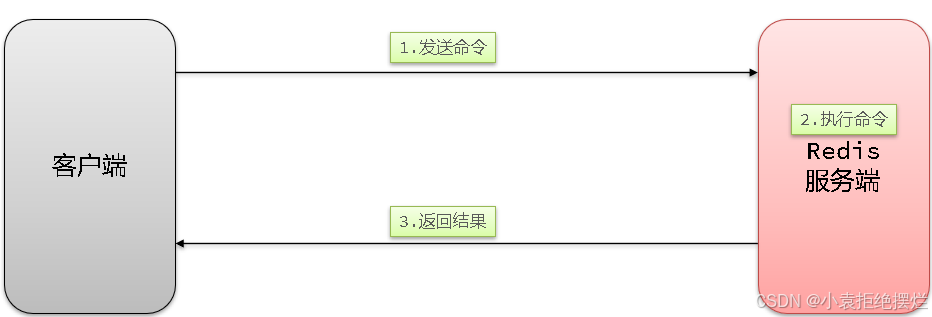
2.1.1 单个命令的执行流程
一次命令的响应时间 = 1次往返的网络传输耗时 + 1次Redis执行命令耗时
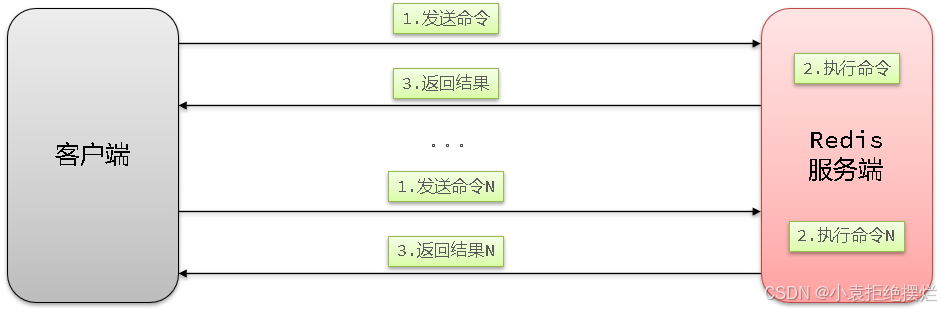
2.1.2 N条命令依次执行
N次命令的响应时间 = N次往返的网络传输耗时 + N次Redis执行命令耗时
2.1.3 N条命令批量执行
N次命令的响应时间 = 1次往返的网络传输耗时 + N次Redis执行命令耗时
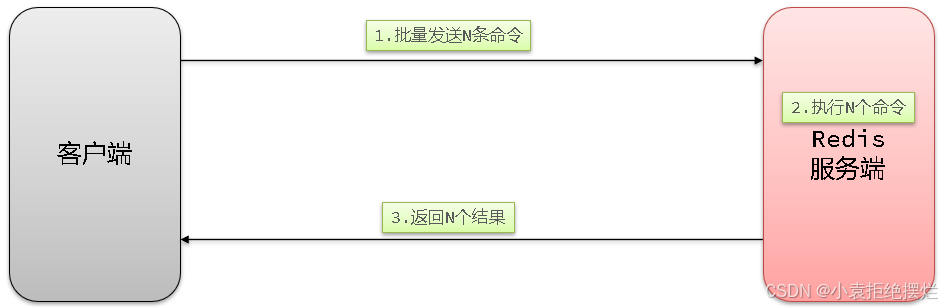
2.1.4 MSET和Pipeline
Redis提供了很多Mxxx这样的命令,可以实现批量插入数据,如:mset、hmset。
原生的批处理命令(相同结构的v可以一起批处理)
// 定义要设置的key-value对
Map<String, String> keyValueMap = new HashMap<>();
keyValueMap.put("key1", "value1");
keyValueMap.put("key2", "value2");// 使用mset方法设置key-value对
redisTemplate.opsForValue().multiSet(keyValueMap);
MSET虽然可以批处理,但是却只能操作部分数据类型,因此如果有对复杂数据类型的批处理需要,建议使用Pipeline功能:
pipeline 一次性可以插入不同的k-v(v结构不同也可以批处理)
List<Object> results = redisTemplate.executePipelined(new RedisCallback<Object>() {public Object doInRedis(RedisConnection connection) throws DataAccessException {connection.set("key1".getBytes(), "value1".getBytes());connection.get("key1".getBytes());connection.set("key2".getBytes(), "value2".getBytes());connection.get("key2".getBytes());return null;}
});for (Object result : results) {System.out.println(result);
}注意:
批处理时不建议一次携带太多命令
Pipeline的多个命令之间不具备原子性
集群下的批处理
如MSET或Pipeline这样的批处理需要在一次请求中携带多条命令,而此时如果Redis是一个集群,那批处理命令的多个key必须落在一个插槽中,否则就会导致执行失败。
| 串行命令 | 串行slot | 并行slot | hash_tag | |
|---|---|---|---|---|
| 实现思路 | for循环遍历,依次执行每个命令 | 在客户端计算每个key的slot,将slot一致分为一组,每组都利用Pipeline批处理。 | 串行执行各组命令 在客户端计算每个key的slot,将slot一致分为一组,每组都利用Pipeline批处理。 | 将所有key设置相同的hash_tag,则所有key的slot一定相同 |
| 耗时 | N次网络耗时 + N次命令耗时 | m次网络耗时 + N次命令耗时 m = key的slot个数 | 1次网络耗时 + N次命令耗时 | 1次网络耗时 + N次命令耗时 |
| 优点 | 实现简单 | 耗时较短 | 耗时非常短 | 耗时非常短、实现简单 |
| 缺点 | 耗时非常久 | 实现稍复杂 slot越多,耗时越久 | 实现复杂 | 容易出现数据倾斜 |
注:spring环境下默认使用第三种并行slot(spring配置集群信息后使用mset会自动使用并行slot方式,不用我们自己实现)
持久化配置
3.1 持久化配置
Redis的持久化虽然可以保证数据安全,但也会带来很多额外的开销,因此持久化要遵循以下建议:
- 用来做缓存的Redis实例尽量不要开启持久化功能
- 建议关闭RDB持久化功能,使用AOF持久化
- 利用脚本定期在slave节点做RDB,实现数据备份
- 设置合理的rewrite阈值,避免频繁的bgrewrite
- 配置no-appendfsync-on-rewrite = yes,禁止在rewrite期间做aof,避免因AOF引起的阻塞
部署有关建议:
- Redis实例的物理机要预存足够内存,应对fork和rewrite
- 单个Redis实例内存上限不要太大,例如4G或8G.可以加快fork的速度,减少主从同步、数据迁移压力
- 不要和CPU密集型应用部署在一起(例如ES)
- 不要与高硬盘负载应用一起部署(数据库,消息队列),单独部署得了。