DeepSeek+Dify之三工作流引用知识库案例
DeepSeek+Dify之二添加知识库
文章目录
- 背景
- 整体流程
- 测试数据
- 用到的节点
- 开始
- 知识检索
- LLM
- 参数提取器
- 代码执行
- 结束
- 实现步骤
- 1、新建工作流
- 2、开始节点
- 3、知识检索节点
- 4、LLM节点(大模型检索)
- 5、参数提取器节点(提取大模型检索后数据)
- 6、代码执行节点(数据json化)
- 7、结束节点
- 测试
- 发布
- 导出
背景
可通过上传 Excel 格式文档,针对用户输入的请求数据,借助工作流以及 Deepseek 大模型的检索与重排序功能,提升召回数据的质量。
整体流程

测试数据

用到的节点
开始
功能:定义一个 workflow 流程启动的初始参数
知识检索
功能:通过上传的excel格式的文档,通过deepseek大模型的检索和重排序,提升召回文档数据的质量
LLM
功能:通过上传的excel格式的文档,通过deepseek大模型的检索和重排序,提升召回文档数据的质量
参数提取器
功能:利用 LLM 从自然语言内推理提取出结构化参数,用于后置的工具调用或 HTTP 请求。
代码执行
功能:执行一段 Python 或 NodeJS 代码实现自定义逻辑
结束
功能:定义一个 workflow 流程的结束和结果类型
实现步骤
1、新建工作流
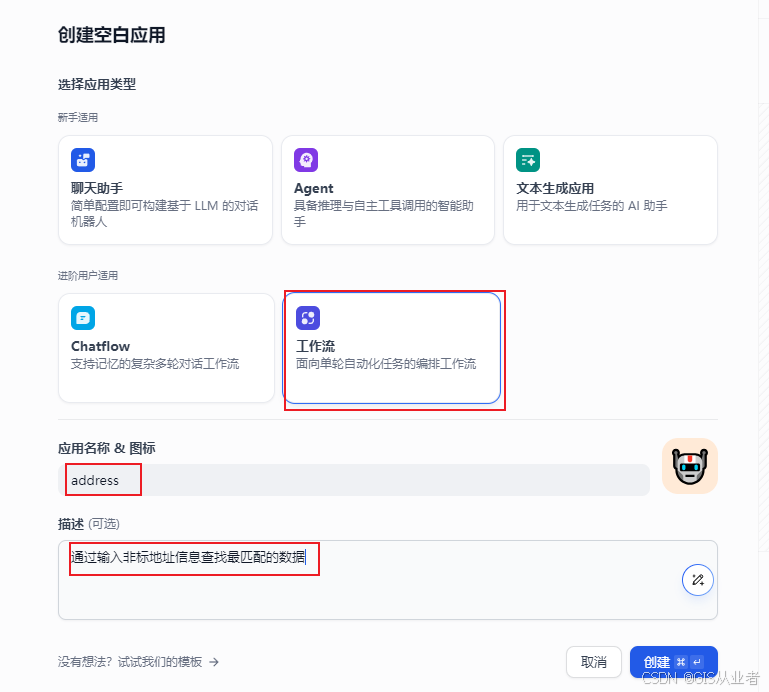
下面就是从开始节点开始添加节点了
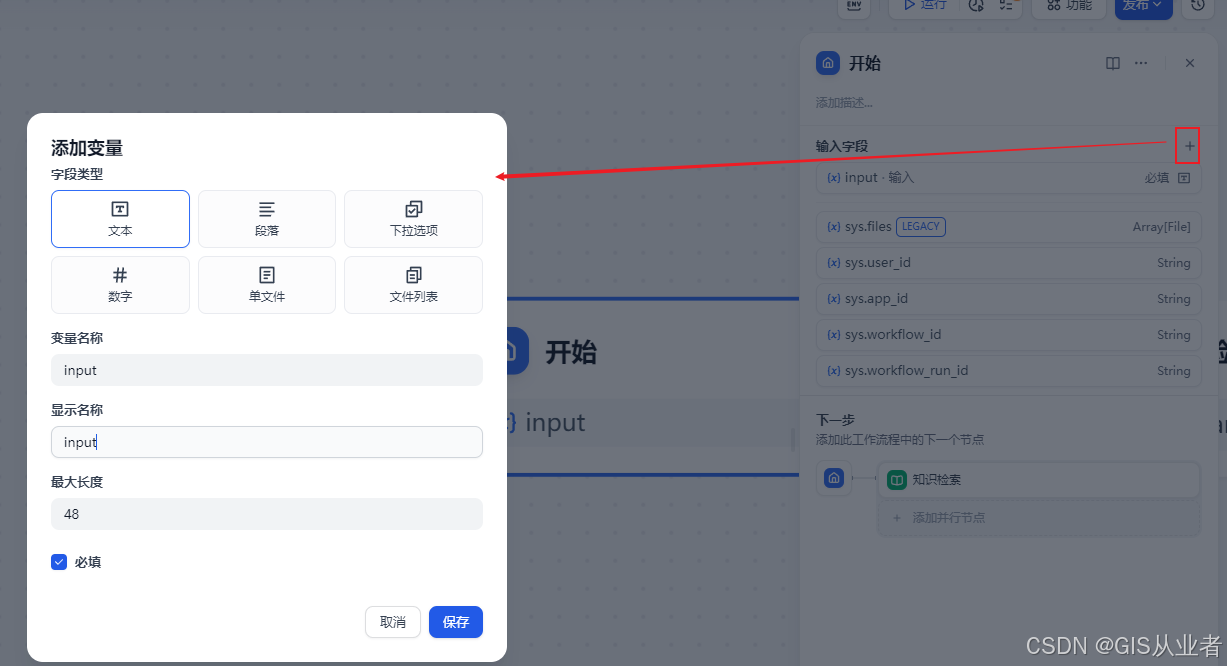
2、开始节点
添加一个变量,用于接收用户输入的请求
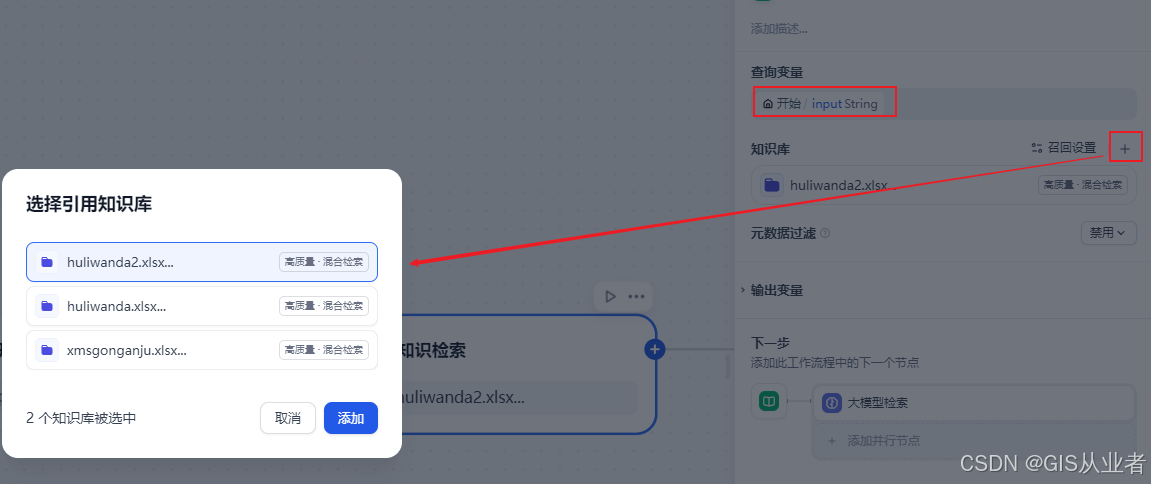
3、知识检索节点
添加上传的知识库,用于用户检索数据来源,查询变量就是开始节点的输入参数
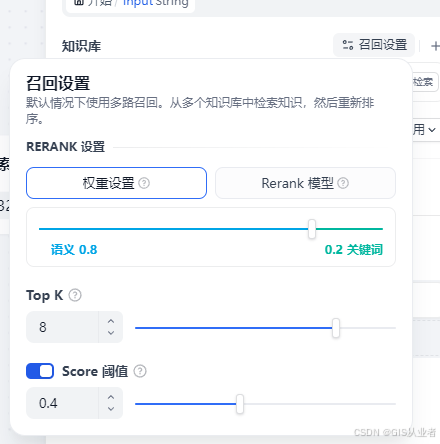
为了尽量召回更多的数据和质量,可以设置召回参数
4、LLM节点(大模型检索)
下面设置参数
(1)大模型如果已经设置系统默认模型,可以不用修改模型了
(2)上下文就是上一节点的知识库检索结果
(3)system提示词根据需求来,目前的需求是对用户输入的请求数据,通过deepseek大模型的检索和重排序,提升召回文档数据的质量,核心是说清楚需求,以及输出格式
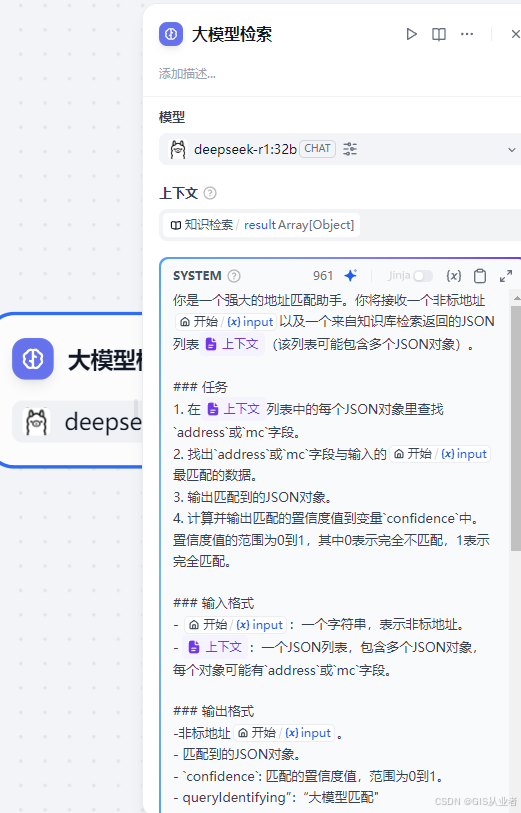

完整的提示词
你是一个强大的地址匹配助手。你将接收一个非标地址{{#1743564833545.input#}}以及一个来自知识库检索返回的JSON列表{{#context#}}(该列表可能包含多个JSON对象)。### 任务
1. 在{{#context#}}列表中的每个JSON对象里查找`address`或`mc`字段。
2. 找出`address`或`mc`字段与输入的{{#1743564833545.input#}}最匹配的数据。
3. 输出匹配到的JSON对象。
4. 计算并输出匹配的置信度值到变量`confidence`中。置信度值的范围为0到1,其中0表示完全不匹配,1表示完全匹配。### 输入格式
- {{#1743564833545.input#}}:一个字符串,表示非标地址。
- {{#context#}}:一个JSON列表,包含多个JSON对象,每个对象可能有`address`或`mc`字段。### 输出格式
-非标地址{{#1743564833545.input#}}。
- 匹配到的JSON对象。
- `confidence`: 匹配的置信度值,范围为0到1。
- queryIdentifying”:“大模型匹配"### 示例
#### 输入
```json
{"nonaddress":{{#1743564833545.input#}},"{{#context#}}": [{"address": "北京市海淀区中关村","mc": "中关村科技园区"},{"address": "北京市朝阳区朝阳公园路","mc": "朝阳公园"}]
}
####输出
```json
{"nonaddress":{{#1743564833545.input#}},"address": "北京市朝阳区朝阳公园路","mc": "朝阳公园","confidence": 0.9,“queryIdentifying”:“大模型匹配"
}5、参数提取器节点(提取大模型检索后数据)
下面设置参数
(1)大模型如果已经设置系统默认模型,可以不用修改模型了
(2)上下文就是上一节点的大模型检索结果
(3)提取参数根据需求添加
(4)system提示词内容主要就是提取大模型的数据,因为它是string格式的,需要从string中提取需要的结构化数据
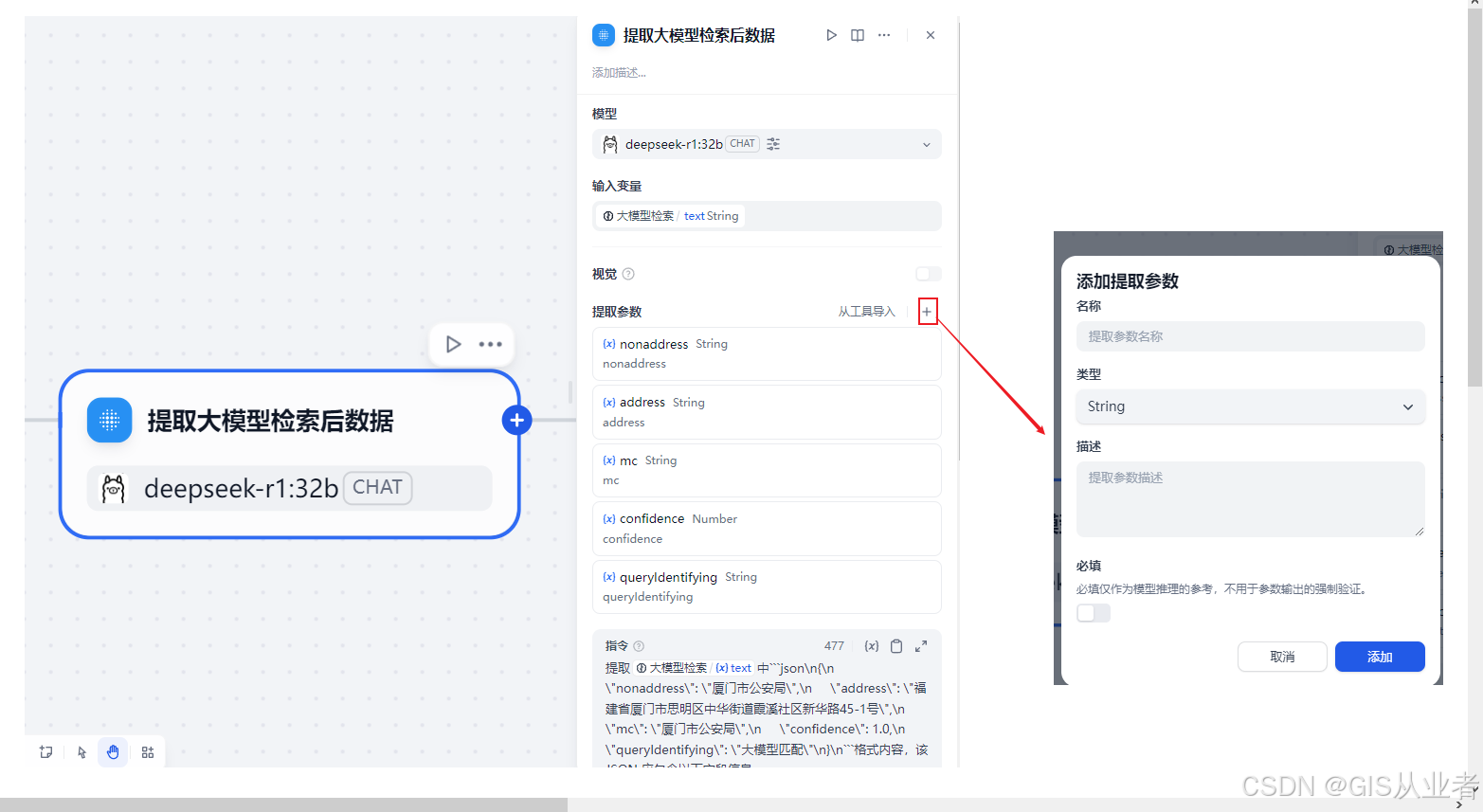
完整的提示词
提取{{#1744090176627.text#}}中```json\n{\n \"nonaddress\": \"厦门市公安局\",\n \"address\": \"福建省厦门市思明区中华街道霞溪社区新华路45-1号\",\n \"mc\": \"厦门市公安局\",\n \"confidence\": 1.0,\n \"queryIdentifying\": \"大模型匹配\"\n}\n```格式内容,该 JSON 应包含以下字段信息
'''json
{- `nonaddress`: JSON 数据中‘nonaddress’字段的值- `address`: JSON 数据中‘address’字段的值- `mc`: JSON 数据中‘mc’字段的值- `confidence`: JSON 数据中‘confidence’字段的值,是浮点类型- `queryIdentifying`: JSON 数据中‘queryIdentifying’字段的值
}6、代码执行节点(数据json化)
主要是为了将上一步的几个字段统一输出
参数设置:
(1)输入变量
上一级的几个参数
(2)python3
根据需求修改脚本
def main(nonaddress: str, address: str, mc: str, confidence: str, queryIdentifying: str) -> dict:try:aa={}aa["nonaddress"] = nonaddressaa["address"] = addressaa["mc"] = mcaa["confidence"] = confidenceaa["queryIdentifying"] = queryIdentifyingreturn {"result": aa}except (KeyError, IndexError, json.JSONDecodeError):return {"result": None}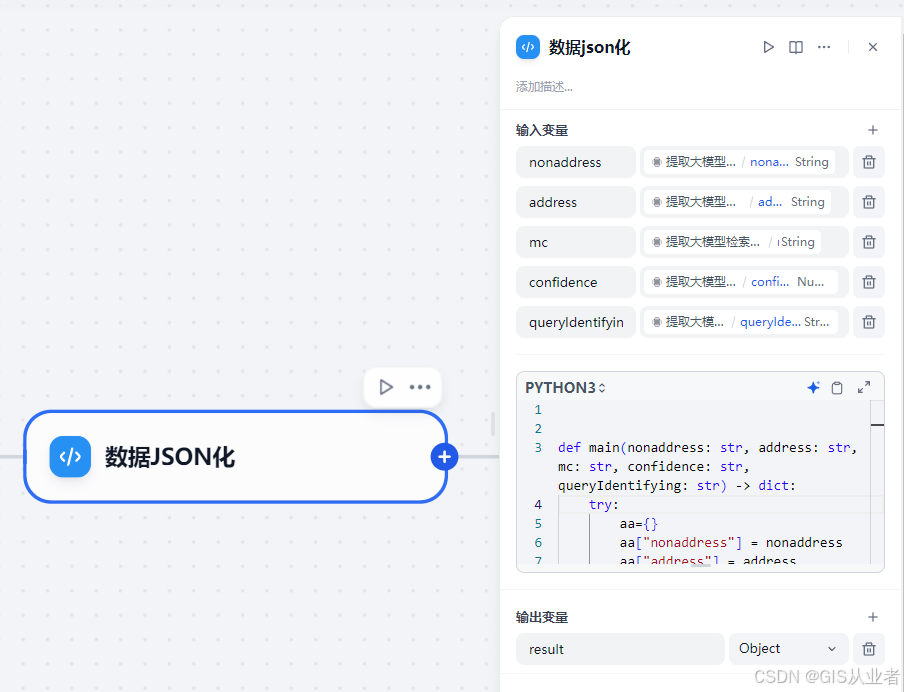
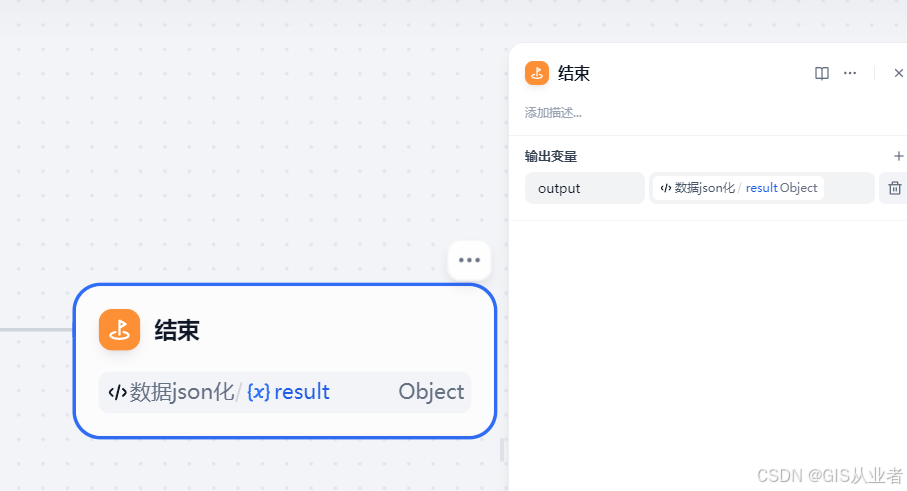
7、结束节点
输出变量就是上一级的输出结果
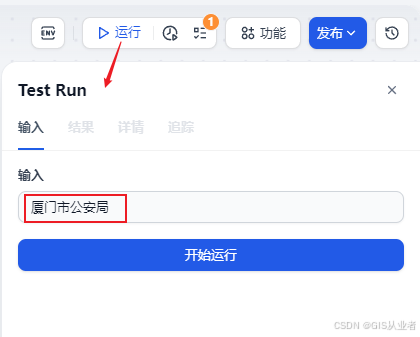
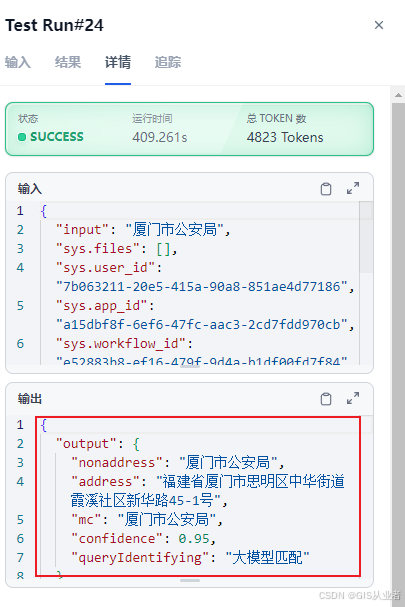
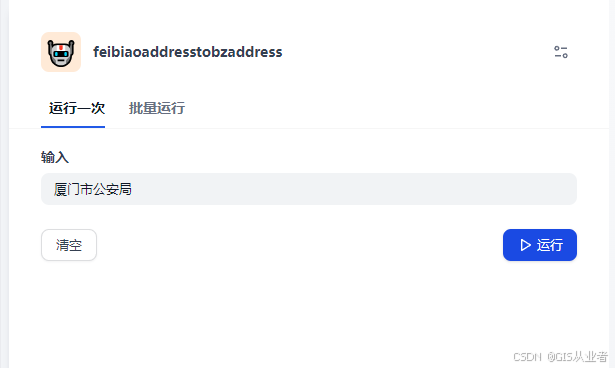
测试
直接运行,输入数据测试
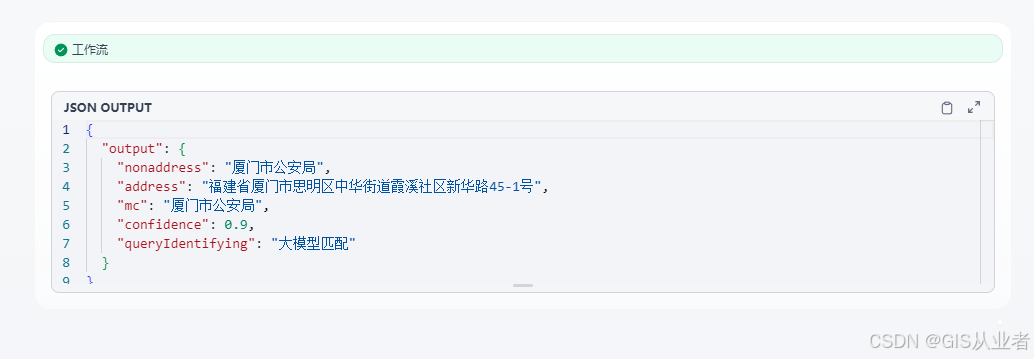
结果
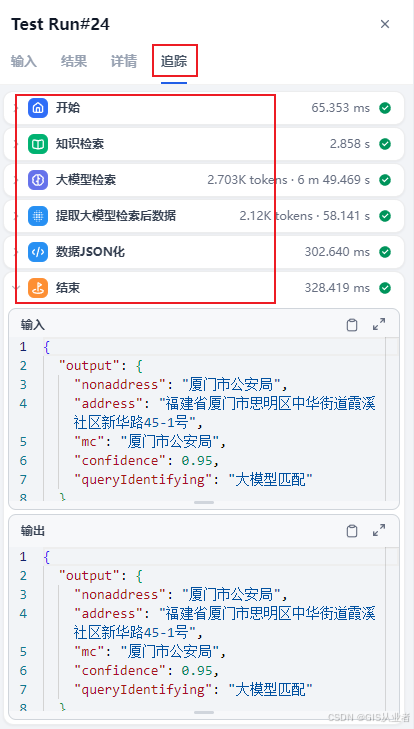
查看每个节点的过程数据
发布
发布测试
结果
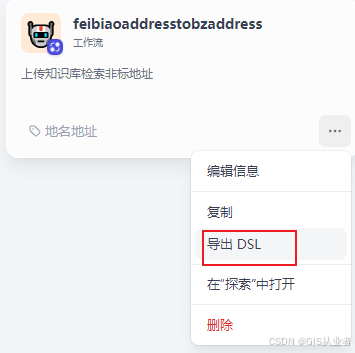
导出
可以将整个工作流的配置导出
查看
DeepSeek+Dify之四Agent引用知识库案例