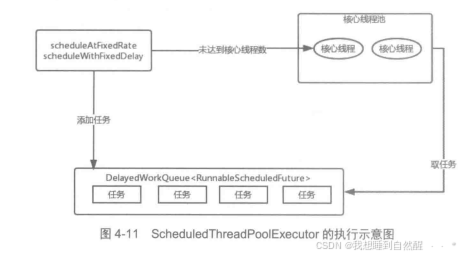
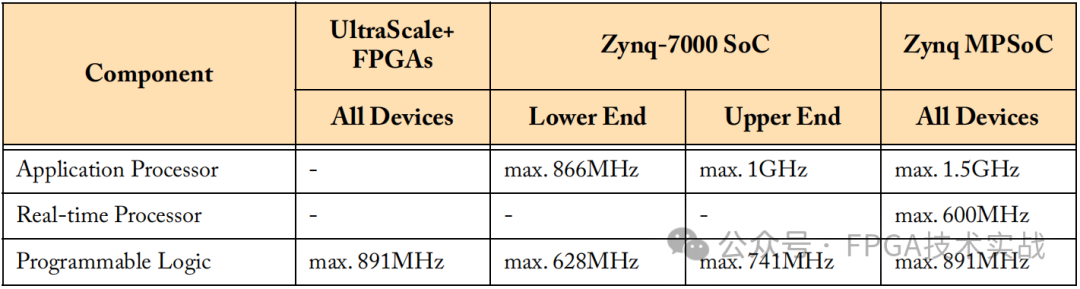
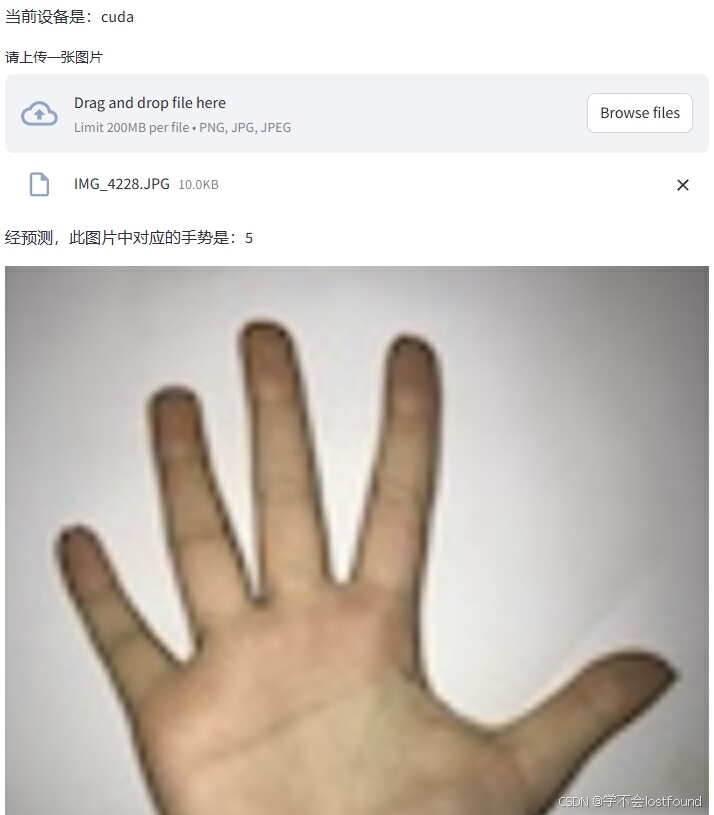
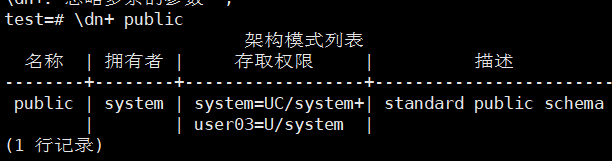
正则表达式
- 基础正则(使用四剑客命令时无需加任何参数即可使用)
^ # 匹配以某一内容开头 如:'^grep'匹配所有以grep开头的行。
$ # 匹配以某一内容结尾 如:'grep$' 匹配所有以grep结尾的行。
^$ # 匹配空行。
. # 匹配任意单个字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
* # 前一个字符出现0次及0次以上 如:'a*'匹配所有有a的行。
.* # 表示文件中所有内容。
[] # 匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] # 匹配一个不在指定范围内的字符,如:'[^A-Z]rep' 匹配不包含 A-Z 中的字母开头的行注意:在[]中,除位置在第一个字符的^外,其余任何带含义的特殊符号都会被还原。
-
扩展正则
- 使用方法
grep命令:grep -E …… 或egrep …… sed命令:sed -r …… awk命令:awk -E ……- 表达式
+ #匹配前一个字符连续出现1次或1次以上 如:'a+' 匹配字符a连续出现1次或多次的行。注:通常与[]配合使用,过滤连续的内容。 {n,m} #匹配前一个字符至少n次,最多m次,优先匹配后面的数字例:'[0-9]{18}' 匹配连续的18个数字 | #或者例:'^$|^#' 匹配文件的空行或以井号开头的 () #表示一个整体;反向引用/后向引用 -
单词边界符
\b # 单词锁定符,如: '\bgrep\b'只匹配grep;'\b[0-9]{18}\b'只匹配连续的18位数字
\< # 锚定单词的开始,如:'\<grep'匹配包含以grep开头的单词的行。
\> # 锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
\<……\> # 相当于\b...\b
\w # 匹配文字和数字字符,也就是[A-Za-z0-9];
\W # \w的反置形式,匹配一个或多个非单词字符,相当于[^A-Za-z0-9]
四剑客
find 在指定目录下查找文件
语法形式
find [参数] [选项] #单条件查找
find [参数] [选项] [or/and] [选项] #多条件查找
or/and
#使用find命令可以多条件查找;
-a #需要同时满足两个、多个条件时(and可以省略);
-o #只需满足其中之一条件时;
选项
-type f/d/l/b/c #按照文件类型查找;
-name "NAME" #按照文件名字查找;
-iname "NAME" #按照文件名字查找(忽略大小写);
-inum "INUM" #按照文件iNode号查找;
-maxdepth n #按照深度等级查找(向下遍历);
-size +n/-n/n #按照文件大小查找;
-mtime +n/-n/n #按照文件修改时间查找;当n=0,代表24小时内被修改过的文件;
示例
#查找/目录下文件名为dezyan.txt的文件(不区分大小写)
[root@Dezyan ~]# find / -iname "dezyan.txt"
/proc/kcore
#查找/目录下文件大小大于1M的目录
[root@Dezyan ~]# find / -size +1M -type d
注意:当一个目录大小大于1M,说明该目录中存在非常多的小文件
#查找/目录下的字符设备或块设备文件
[root@Dezyan ~]# find / -type c -o -type b
或 find / -type c,b
#以深度等级为1查找/目录下以.log结尾的文件
[root@Dezyan ~]# find / -maxdepth 1 -name "*.log" -type f
#查找24小时内被修改过的文件
[root@Dezyan ~]# find ./ -mtime 0
xargs 给其他命令传递参数的一个过滤器
注意:在xargs后别名失效
语法形式
find ………… | xargs [文件操作,命令]
#可以理解为将|前执行的结果甩到末尾,再执行|后的命令
相关使用方法
-n1 #按照第一列方式输出内容
ls -l/cat #查看找到的文件;
rm [选项] #将查找的文件删除;
-i cp/mv {} [参数] #将查找到的文件复制/移动到[参数位置];
cp/mv -t [参数] #将查找到的文件复制/移动到[参数位置];
示例
#将/etc/下大于9M的文件复制到~目录下
[root@Dezyan ~]# find /etc/ -size +9M | xargs cp -t ~
[root@Dezyan ~]# ls ~ | grep 'hwd'
hwdb.bin
#查找出所有大写的.TXT结尾的文件 然后打包成test.tar.gz
[root@Dezyan ~]# find ./ -name "*.TXT"|xargs tar zcvf a.tar.gz
exec 调用并执行指定的命令
注意:使用exec将多个文件压缩成一个压缩包是不可取的,因为按照exec的逻辑,是将前一命令的每一次执行结果依次放入{},进行压缩时,会不断覆盖文件;
语法形式
find ………… -exec [命令] {} [参数] \;
注意:其中==;==为shell中命令的分隔符,可将多个命令同时执行:mkdir test;touch 1.txt。
相关使用方法
rm [选项] {} \; #将查找的文件删除;
cp/mv {} [参数] \; #将查找到的文件复制/移动到[参数位置];
示例
#将/etc/下大于9M的文件复制到~目录下
[root@Dezyan ~]# find /etc/ -size +9M -exec cp {} ~ \;
使用``和$()
语法形式
[命令+选项] `find ……………`
[命令+选项] `find ……………` [参数]
$()效果与``相同
注意:如果一段命令被添加上了``,那么在整体命令中,需要先执行``中的命令,类似于运算法则中的加减乘除先算()。
相关使用方法
cp/mv `find ……` [参数]
ls/rm……
示例
#将/etc/下大于9M的文件复制到~目录下
[root@Dezyan ~]# cp -a `find /etc/ -size +9M` ~
grep 强大的文本搜索工具
语法形式
grep [选项] '[word]' [参数]
选项
-v #反转查找;
-r #当指定要查找的是<目录>而非文件时,必须使用这项参数;
-E #识别扩展正则进行过滤;等同于egrep;
-o #展示匹配过程;
------------------------------------------------------------
--color #对筛选出的WORD加颜色显示;建议设置永久别名;
-i #搜索时不区分大小写;
-n #搜索出的结果显示行号;
-w #过滤的内容两边必须是空格(类似于边界符)
-c #统计单词出现的次数;
-A #过滤到内容往下2行;
-B #过滤到内容往上2行;
-C #过滤到内容上下各2行;
示例
#在/etc/passwd文件中过滤出root的行
[root@Dezyan ~]# grep 'root' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
#不区分大小写过滤出 /etc/ssh/sshd_config 文件中包含`port 22`的行并输出行号
[root@Dezyan ~]# grep -i -n 'port 22' /etc/ssh/sshd_config
17:#Port 22
#排除(取反)/etc/selinux/config文件中的#和注释
[root@Dezyan ~]# grep -v '^#|^$' /etc/ssh/sshd_config
#统计word.txt文件中shutdown单词的个数
[root@Dezyan ~]# grep -c 'shutdown' word.txt
2
#显示文件word.txt中config的上下各两行
[root@Dezyan ~]# grep -C 2 'config' word.txt
test 测试
server 服务
configure 配置 config conf cfg
continue 继续
next 下一个
sed 功能强大的流式文本编辑器
- 语法形式
sed [选项] '[模式][动作]' [参数]
- 选项
-n #取消内存空间默认输出;不添加时sed命令会默认输出文件所有内容及匹配到的内容;
-r #使模式中的正则表达式支持扩展正则;
-i #对源文件进行修改;不添加时不会修改;
- 模式
number #按行查找,查找第n行
number或正则符号,number或正则符号 #查找n到m行
/字符串或正则表达式/ #模糊查询,查询包含此字符串的行
/字符串/,/字符串/ #匹配区间:查询两个字符串之间的内容(也可用正则)
n[动作];m[动作] #指定第n行和第m行进行操作
- 动作
p #输出打印过滤出的内容
d #删除过滤出的内容
a 字符串 #add 在……后追加xxx
i 字符串 #insert 在……前插入xxx
c 字符串 #replace 将……替换为xxx
w 文件 #将过滤到的内容写入到文件中
--------------------------------------------------
s###g #1.其中,g代表全局替换#2.s///g、s@@@g等与s###g效果相同
注意:
-
动作中有p,模式中必有n
-
在使用匹配区间( /开头字符串/,/结尾字符串/ )时,尽量使用文件内容中唯一的、不重复的字符串;
- 若只有一个开头,有两个甚至多个结尾时:输出的内容只会是开头到第一个结尾字符串之间的内容;
- 若只有开头,结尾字符串没有:输出的内容为开头字符串到文件末尾;
-
sed的后向引用
sed 's#(正则)(数字)(字符串)#\1\3#g' #\n获取第n个()中的内容
实例
#获取IP地址
[root@Dezyan ~]# ip add show ens33 | sed -rn '3s#.*et (.*)/24 .*$#\1#gp'
10.0.0.101#批量创建用户test01..test03
[root@Dezyan ~]# echo test{01..03} | xargs -n1 | sed -r 's#(.*)#useradd \1#g' | bash##批量创建用户test01..test03并设置密码为dingzhiyan1016
echo test{01..03} | xargs -n1 | sed -r 's#(.*)#useradd \1 ; echo dingzhiyan1016 | passwd --stdin \1#g' | bash
或
[root@Dezyan ~]# echo test11{01..03} | xargs -n1 | sed -r 's#(.*)#useradd \1 ; echo \1:dingzhiyan1016 | chpasswd #g' | bash#批量删除用户
[root@Dezyan ~]# echo user{1..20} | xargs -n1 | sed -r 's#(.*)#userdel -r \1#g' | bash
- 示例
1.a.txt文件
[root@Dezyan ~]# cat -n a.txt 1 The first snow came. 2 How beautiful it was, falling so silently all day long,3 all night long.4 on the mountains, on the meadows, 5 on the roofs of the living, on the graves of the dead! A2.查看a.txt文件第三行的内容
[root@Dezyan ~]# sed -n '3p' a.txt
all night long.3.查看a.txt文件中第三行到结尾的内容
[root@Dezyan ~]# sed -n '3,$p' a.txt
all night long.
on the mountains, on the meadows,
on the roofs of the living, on the graves of the dead! A4.查看a.txt中以o开头或以T开头的行
[root@Dezyan ~]# sed -rn '/^o|^T/p' a.txt
The first snow came.
on the mountains, on the meadows,
on the roofs of the living, on the graves of the dead! A5.查看a.txt文件中包含so与meadows行之间的内容
[root@Dezyan ~]# sed -n '/so/,/meadows/p' a.txt
How beautiful it was, falling so silently all day long,
all night long.
on the mountains, on the meadows,6.在a.txt文件1到3行后都添加一行Dezyan
[root@Dezyan ~]# sed '1,3i Dezyan' a.txt
Dezyan
The first snow came.
Dezyan
How beautiful it was, falling so silently all day long,
Dezyan
all night long.
on the mountains, on the meadows,
on the roofs of the living, on the graves of the dead! A7.将a.txt文件中所有的(第一个)on替换为under
[root@Dezyan ~]# sed 's#on#under#g' a.txt (只替换第一个只需将g去掉即可)
The first snow came.
How beautiful it was, falling so silently all day lunderg,
all night lunderg.
under the mountains, under the meadows,
under the roofs of the living, under the graves of the dead! A8.查找roofs所在行,并将其替换为floor,并且只显示替换行
[root@Dezyan ~]# sed -n '/roofs/s#roofs#floor#gp' a.txt
on the floor of the living, on the graves of the dead! A9.删除文件amount.txt中的所有字母
[root@Dezyan testdir]# sed -r 's#[a-Z]##g' amount.txt
awk 文本和数据进行处理的编程语言
- 语法形式
awk [选项] '哪一行{print 哪一列}' [file]
#逻辑:按行取列,先将符合条件的行尽数找出,再对其中的某一列进行选取;
#awk本质上其实是一种编程语言,其中可以进行运算;
- 选项
-F "" #指定分隔符;
- 取行
#当语法形式中的`{print 哪一列}`为空即为取行
1.指定某行或某几行
语法形式:awk 'NR[运算符]n' file
使用awk内置变量:NR --> 存储每行的行号
运算符:== 等于> 大于>= 大于等于< 小于<= 小于等于!= 不等于&& 且|| 或
#可使用内置函数取出文件内容的最后一行awk 'END{print}' file
2.模糊过滤取行
语法形式:awk '模式' file
模式'可以使用正则符号':// #模糊查找文件中的字符串//,// #模糊查找两字符串之间的内容
- 字符比对查取行
语法形式:awk [选项] '[取列内置变量] [模式匹配符] "[表达式]"' file
模式匹配符:== #某列等于……!= #某列不等于……~ #使用正则匹配字符串!~ #使用正则匹配字符串并取反
表达式:任意字符正则表达式
- 数字比对查取行
语法形式:awk [选项] '[取列内置变量] [模式匹配符][运算符]n' file
- 取列
#当语法形式中的`哪一行`为空即为取列
语法形式:awk '{print [内置变量]}' file
awk内置变量:$0 # 表示整行$n # 表示文件的第n列 , # 逗号表示空格NF # 表示每一行最后一列的列号$NF # 表示最后一列;`$(NF-1)`表示倒数倒数第二列 --> 也体现了awk支持运算的特性
- 指定分隔符取列
语法形式:awk -F "[表达式]" '{print [内置变量]}' file
表达式:任意字符正则表达式
- 指定分隔符按行取列
awk -F "[表达式]" '取行方式+取列方式' file
- BEGIN的用法
#BEGIN 是一个特殊的模式,它在处理任何输入行之前执行一次。
awk -F "[表达式]" 'BEGIN{print 任意内容}' file
- 示例
#过滤文件的选择:/etc/passwd文件的前10行,存储到了~/passwd.txt中
#即:head /etc/passwd >> ~/passwd.txt
#在未明确说明分隔符时,默认指定分隔符为":"
1.指定取行
#取出文件最后一行
[root@Dezyan ~]# awk 'END{print}' passwd.txt
#取出第7行和第9行以及两行之间的内容
[root@Dezyan ~]# awk 'NR>=7&&NR<=9' passwd.txt2.模糊取行
#取出文件中以root开头和以adm开头以及两行之间的内容
[root@Dezyan ~]# awk '/^root/,/^adm/' passwd.txt3.字符比对取行
#取出文件中用户名为root的行
[root@Dezyan ~]# awk -F: '$1=="root"' passwd.txt
#取出文件中以nologin结尾的行
[root@Dezyan ~]# awk -F: '$NF~"nologin$"' passwd.txt4.数字比对取行
#取出用户uid大于6的行
[root@Dezyan ~]# awk -F: '$3>6' passwd.txt5.取列
#输出文件每一行最后一列的序号(以:或\或:\为分隔符)
[root@Dezyan ~]# awk -F "[:/]+" '{print NF}' passwd.txt
#输出文件的第一列和最后一列(以:或\或:\为分隔符)
[root@Dezyan ~]# awk -F "[:/]+" '{print $1,$NF}' passwd.txt6.BEGIN用法示例
#在输出文件第一列内容前,先输出“用户名”
[root@Dezyan ~]# awk -F: 'BEGIN{print "用户名"}{print $1}' passwd.txt
#让输出的第一列内容前,都有“用户名:”几个字
[root@Dezyan ~]# awk -F: '{print "用户名:" $1}' passwd.txt7.综合运用
#输出文件最后一行的最后一列
[root@Dezyan ~]# awk -F: 'END{print $NF}' passwd.txt
#输出大于第5行到结尾的内容,并取出第3列
[root@Dezyan ~]# awk -F: 'NR>5{print $3}' passwd.txt
#输出用户uid大于6的行并输出用户名
[root@Dezyan ~]# awk -F: '$3>6{print $1}' passwd.txt
#将系统重不能登录的用户输出到nologin.txt文件中,并在文件的开头显示“不能登录的用户有:”##注:使用awk命令;不能使用管道符
[root@Dezyan ~/testdir]# awk -F: 'BEGIN{print "不能登录的用户有:"} $NF~"nologin$"{print $1}' /etc/passwd >> nologin.txt
不能登录的用户有:
bin
daemon
……………………