MAGI-1: Autoregressive Video Generation at Scale
TL;DR
- 2025 年 sand AI 发布的视频生成工作,提出了 MAGI-1:一种基于扩散的大规模生成模型,通过自回归地生成按时间分块的视频,每个块包含一段固定长度的连续帧
Paper name
MAGI-1: Autoregressive Video Generation at Scale
Paper Reading Note
Paper URL:
- https://static.magi.world/static/files/MAGI_1.pdf
Project URL:
- https://sand.ai/
Introduction
背景
- 大多数大规模视频扩散模型仍依赖于对完整时间序列同时处理的全局条件去噪架构。这类模型通常使用统一的噪声水平,并且推理时需要访问完整序列,忽略了时间数据中固有的因果结构,因此在需要流式、实时交互或自回归生成的场景中表现不佳。
本文方案
- 提出了 MAGI-1:一种基于扩散的大规模生成模型,通过自回归地生成按时间分块的视频,每个块包含一段固定长度的连续帧。这种按块处理的方法在因果建模与时间抽象之间提供了系统性的权衡,使模型能够捕捉中程的时间依赖关系,同时严格保持从左到右的时间一致性。训练在块级别进行,并使用时间递增的噪声水平,从而得到既具有自回归结构又能灵活进行条件生成的模型。
- 分布式注意力机制(MagiAttention):专为双向空间处理与因果时间去噪设计
Methods
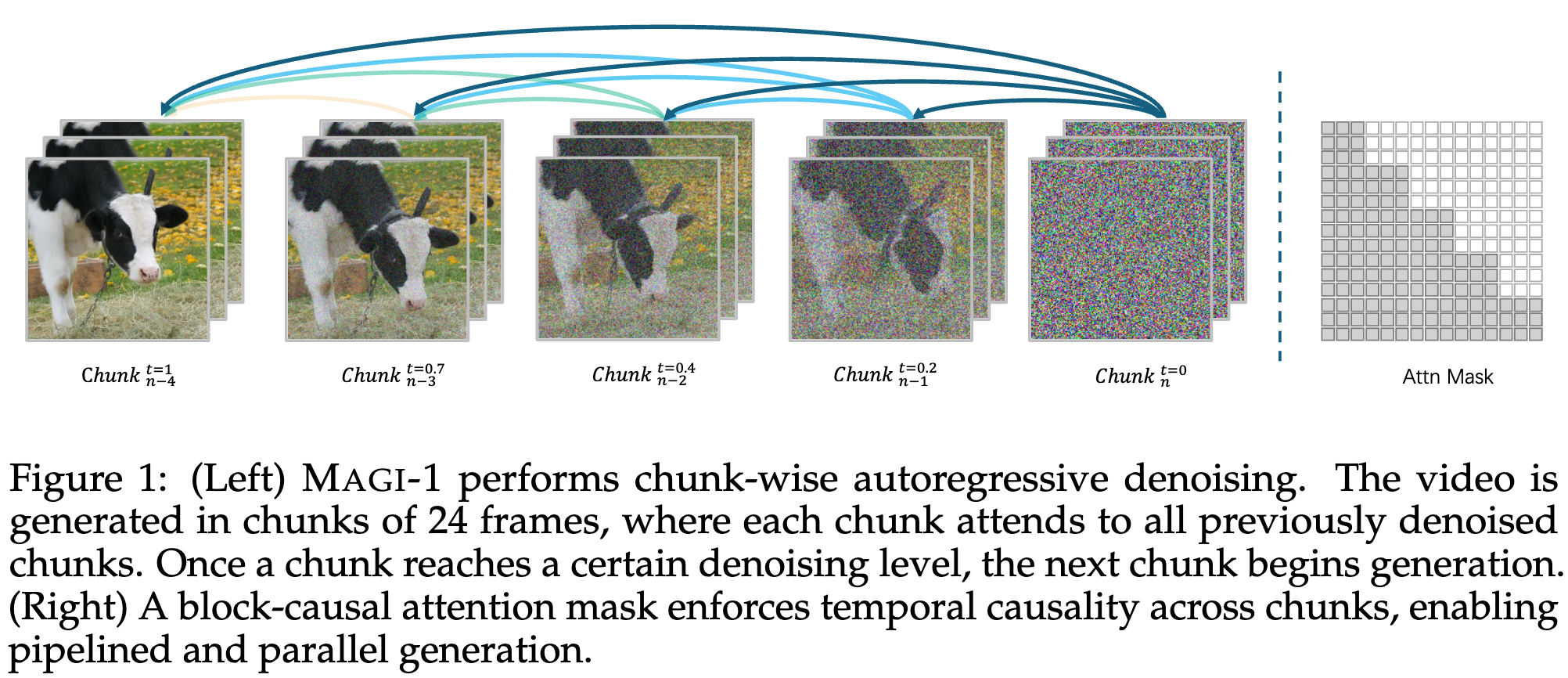
- MAGI-1 以流水线方式逐块生成视频。具体来说,每个块包含多个帧,这些帧被整体去噪。当一个块去噪到一定程度(不必完全干净)后,下一个块便开始生成,并以此前所有块为条件。此设计允许多个块并行处理。在我们的实现中,每个块包含 24 帧原始画面(相当于 24 FPS 下的一秒视频片段),最多可同时推理四个块。相比于完全去噪一个块后再生成后续块的方法,我们的方法通过并行性更好地利用了计算资源,降低了获得后续干净块的延迟,实现了实时流式视频生成。
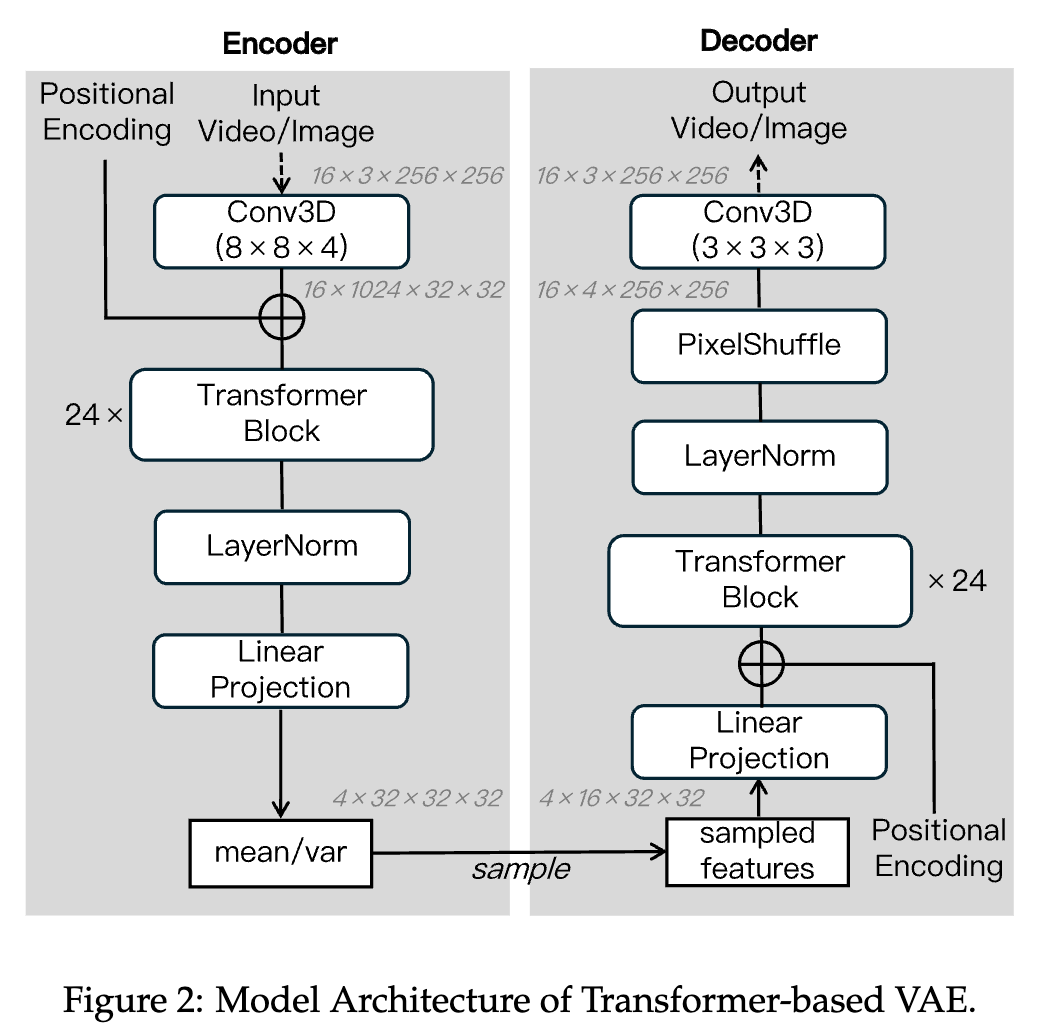
基于 Transformer 的变分自编码器(VAE)
- 考虑到卷积架构在现代 GPU 上的推理速度远低于 transformer 架构,基于 Transformer 设计了新的 VAE 架构
-
模型架构
- 在编码器中,输入首先经过一个基于 3D 卷积(核大小 8×8×4,步幅 8×8×4)的嵌入模块处理,输出 1024 个通道。随后加入绝对位置嵌入,丰富时空表达。基于此,堆叠了 24 个 Transformer 块,通过对查询、键、值进行归一化来提升训练稳定性。最终输出经过 LayerNorm 归一化,并通过线性层投影到 32 通道,其中前 16 通道表示预测均值,后 16 通道表示预测对数方差。与原始输入视频相比,编码特征在空间维度上下采样了 8 倍,在时间维度上下采样了 4 倍。
- 解码器采用与编码器对称的架构。为了恢复原始的时空分辨率,先对最终 Transformer 块的输出应用像素重排(pixel shuffle)操作,然后进行 3×3×3 的 3D 卷积并输出 3 通道生成最终像素空间图像。
- 图片输入;单帧的图像输入,我们在时间维度上将该帧复制四次,这比用三帧空白填充效果更好。
-
VAE 的训练分为两个阶段
- 第一阶段使用固定输入分辨率(16 帧短片,空间分辨率 256×256 像素)
- 第二阶段
- 同时使用图像数据(单帧)和视频数据(16 帧短片)
- 每个训练步骤随机采样空间分辨率和宽高比,从而增强泛化能力。总像素数(高×宽)约为 256² 或 384²,宽高比在 [0.25, 4.0] 范围内均匀采样
-
推理
- 推理时,我们采用滑动窗口方法支持任意分辨率。空间维度窗口大小为 256×256 像素,步幅为 192 像素,相邻块有 25% 重叠;时间维度则无重叠。
-
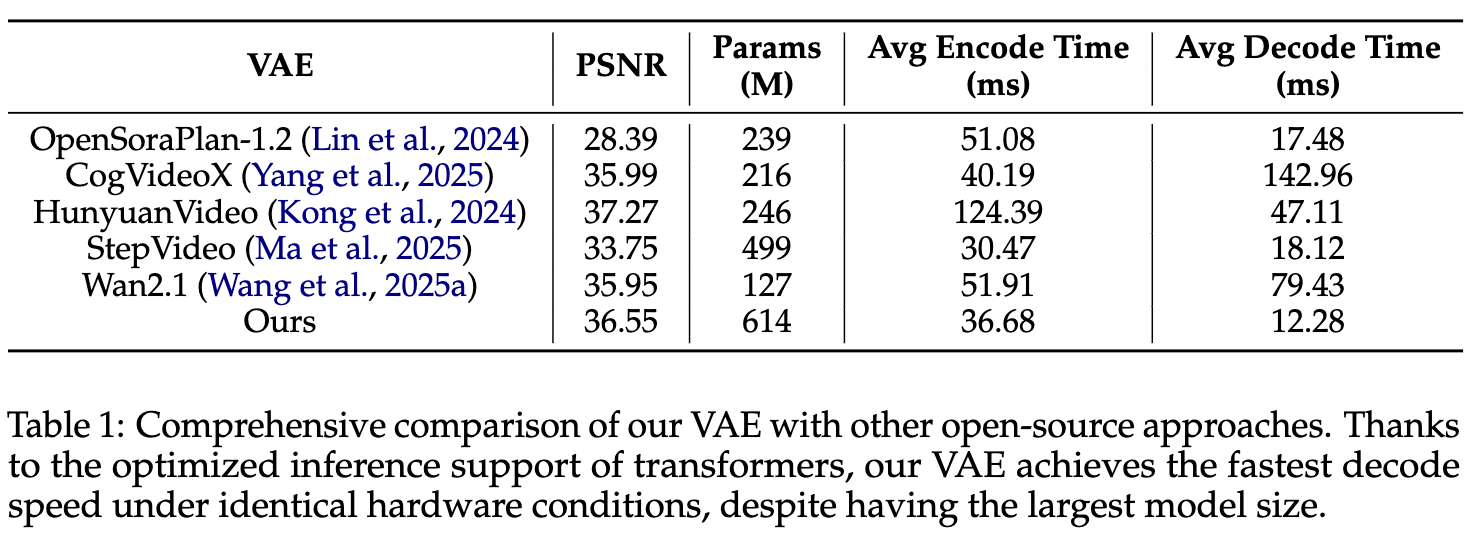
VAE 和其他模型对比,模型参数量最大,但是推理速度最快。重建的指标也排名较高
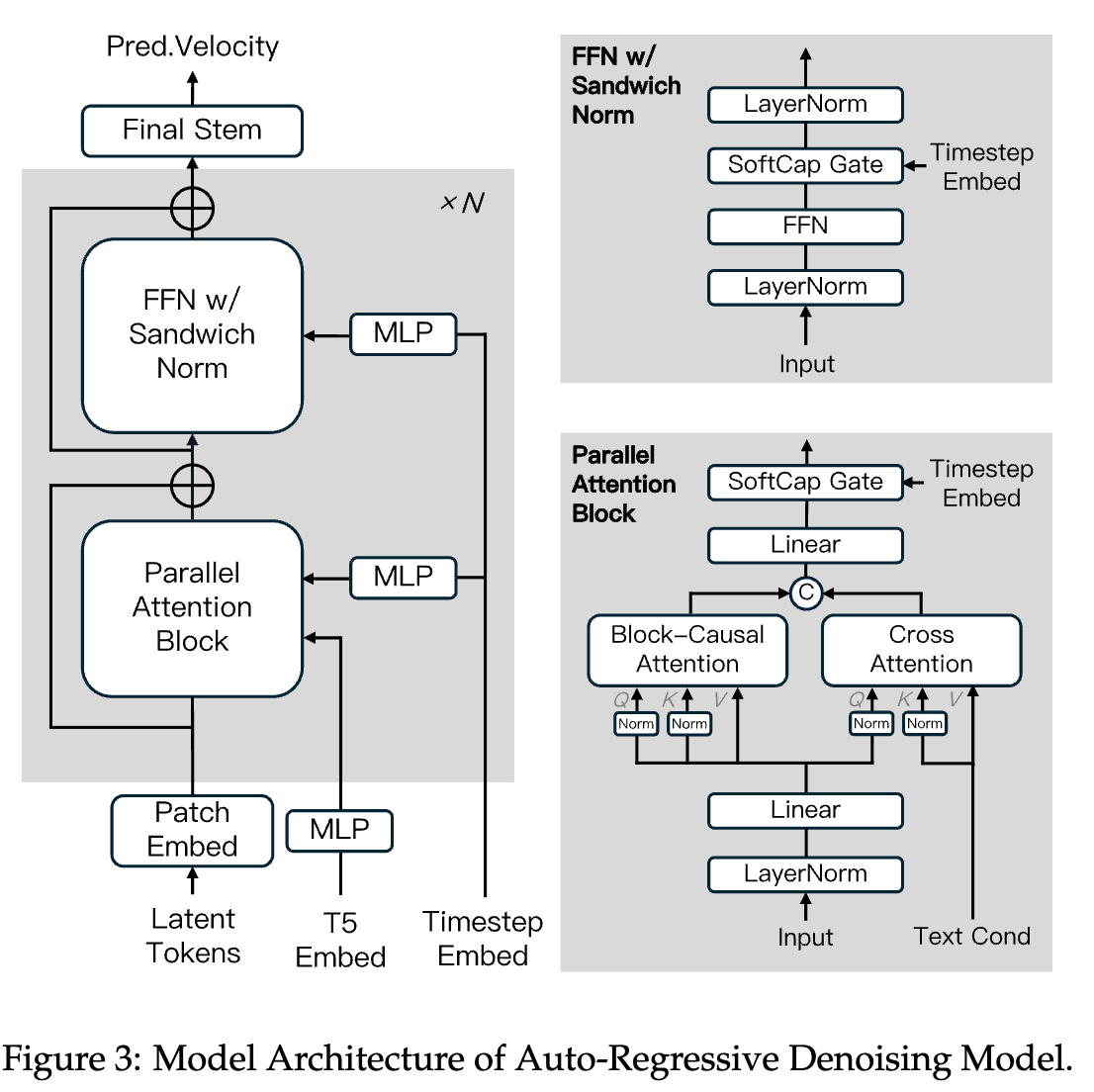
自回归的降噪模型
-
采用 flow-matching 训练目标
-
FFN 用 sandwich norm
-
并行的 attention block 提升计算效率
- Block-Causal Attention:
- 每个 chunk 内是 full attention,chunk 间是 causal attention
- 3D RoPE,base frequency is learnable
- 基于 FlashAttention-3 实现了一个 Flexible-Flash-Attention kernel
- GQA
- QK-Norm
- condition 输入使用的 cross attention
- Block-Causal Attention:
-
模型参数配置
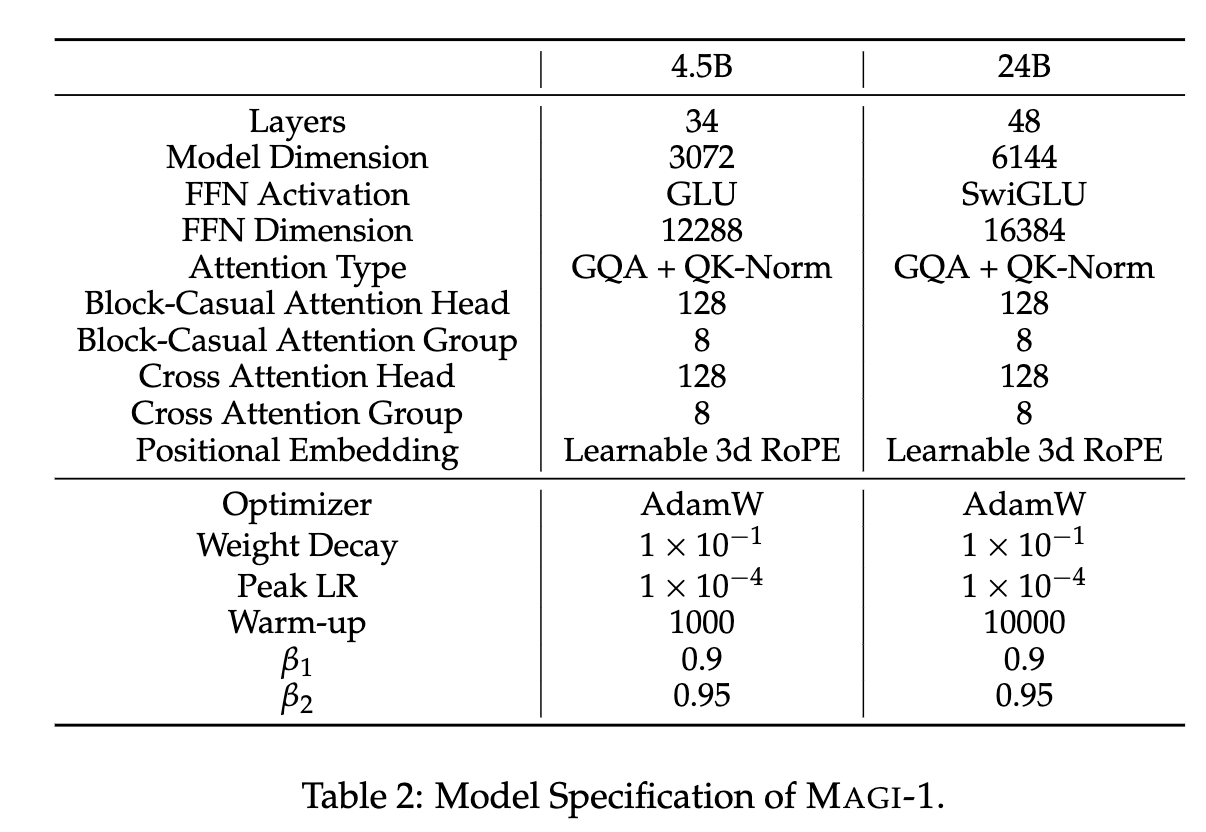
-
training timestep 采样:在 t<0.3 部分用了 70% 的算力
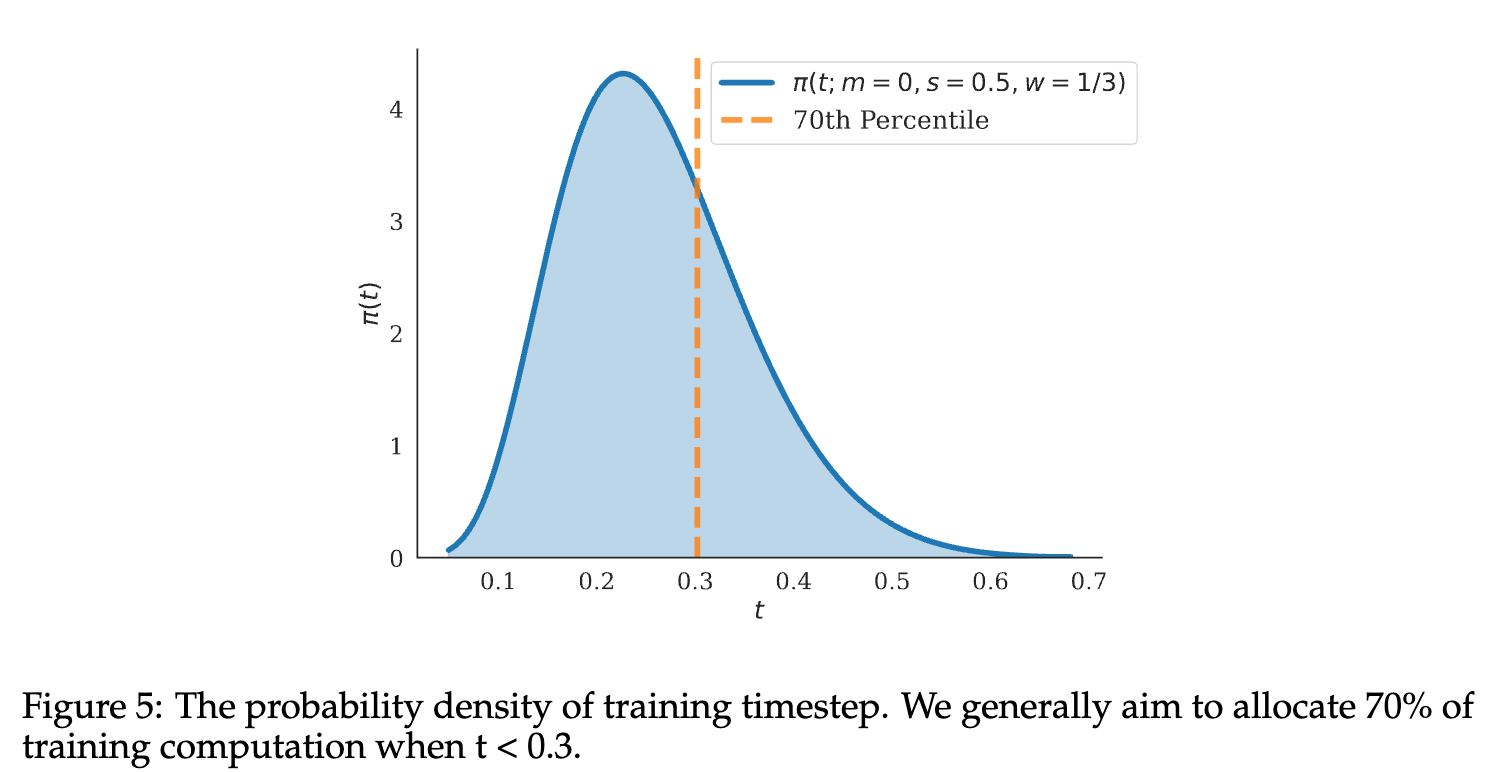
原因是发现 t=0.3 时模型能生成合理的清晰视频

Conclusion
- MAGI-1 报告写得非常详尽,模型架构还是和目前主流架构有较大区别,能看出是希望走出一定差异化路线的。Causal 的 chunk 设计对于长视频的生成确实比较友好
- VAE 采用 transformer 架构还是比较少见的,高分辨下需要分块处理可能需要有一定优化工作量