langchain安装:pip install langchain-openai https://python.langchain.com/v0.2/docs/integrations/platforms/openai/
注意:安装后,我们需要在环境变量中配置OPENAI_API_KEY,langchain会自动获取
1.模型的封装
- 指令生成式模型
from langchain_openai import OpenAIllm = OpenAI(model_name="gpt-3.5-turbo-instruct")
res = llm.invoke("你好,欢迎")
print(res)
- 对话式生成模型
from langchain_openai import ChatOpenAIchatModel = ChatOpenAI(model="gpt-3.5-turbo")
res = chatModel.invoke("你好,欢迎")
print(res)
from langchain_openai import ChatOpenAI
from langchain.schema import (AIMessage,HumanMessage,SystemMessage
)messages = [SystemMessage(content="你是AIGC课程的助理"),HumanMessage(content="我来上课了")
]chatModel = ChatOpenAI(model="gpt-3.5-turbo")
res = chatModel.invoke(messages) #chat_models默认input参数是一个prompt列表
print(res)
可以看到,无论是指令生成还是对话生成,都是统一调用invoke,不同模型是传递字符串还是列表,框架内部进行了处理。相比较教程里面之前的框架,现在使用起来更加简单,尤其在导入各个模块上表现更好。但是迭代太快,文档不太够用
2.I/O封装
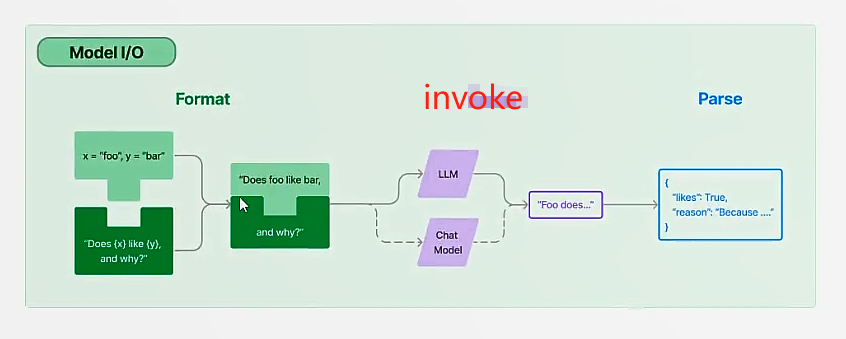
- 输入封装:PromptTemplate https://blog.imkasen.com/langchain-prompt-templates/
指令生成prompt模板
from langchain.prompts import PromptTemplatetemplate = PromptTemplate.from_template("给我讲个关于{title}的笑话")
print(template.input_variables)
print(template.format(title="小米"))
对话生成prompt模板
from langchain.prompts import ChatPromptTemplatetemplate = ChatPromptTemplate.from_messages([("system","你是一个{subject}课程助手"),("human","{user_input}"),
])prompt_value = template.invoke({"subject":"AIGC","user_input":"我请假一次"
})print(prompt_value)
- 输出封装:OutputParser,可以按照自定义格式进行解析
import json
from typing import List,Dict #用于泛型
from pydantic import BaseModel,Field,field_validator #Pydantic是一个用于数据建模/解析的Python库,具有高效的错误处理和自定义验证机制。
from langchain_openai import OpenAI
from langchain.prompts import PromptTemplate
from langchain.output_parsers import PydanticOutputParserdef chinses_friendly(string):lines = string.split("\n")for i,line in enumerate(lines):if line.startswith("{") and line.endswith("}"):try:lines[i] = json.dumps(json.loads(line),ensure_ascii=False)except:passreturn '\n'.join(lines)#定义输出格式
class Command(BaseModel):command: str = Field(description="linux shell命令字")arguments: Dict[str,str] = Field(description="命令字后面的参数(name:value)")#开始对参数添加自定义校验机制@field_validator("command")def no_space(cls,info):if " " in info or "\t" in info or "\n" in info:raise ValueError("命令名不能包含特殊字符")return infoparser = PydanticOutputParser(pydantic_object=Command)query = "将系统日设置为2024-07-01"
prompt = PromptTemplate(template="将用户的指令转化为linux命令.\n{format_instructions}\n{query}",input_variables=["query"],partial_variables={"format_instructions":parser.get_format_instructions()} #也可以直接赋值
)model_input = prompt.format_prompt(query=query) #format()返回的是字符串,format_prompt返回的是promptValueprint("---------------prompt----------------")
print(model_input)
print(model_input.to_string())
print(chinses_friendly(model_input.to_string()))model_name = "gpt-3.5-turbo-instruct"
temperature = 0.0
model = OpenAI(model_name=model_name,temperature=temperature) #可以看到,指令生成式也可以得到答案,根据前文prompt得到
output = model.invoke(model_input)print("---------------output----------------")
print(output)
print("---------------parser----------------")
cmd = parser.parse(output)
print(cmd)prompt查看
print("---------------prompt----------------")
print(model_input)
print(model_input.to_string())
print(chinses_friendly(model_input.to_string()))
上面是给大模型看的,压缩后乱,转string如下
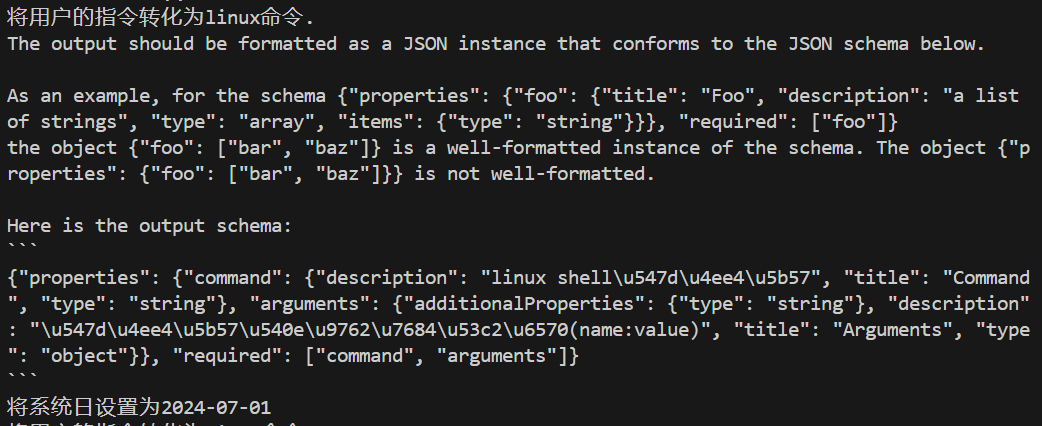
但是内部的字符串中文被转换为ascii码,通过json解析,转换成中文

注意上面的输出解析Command类里面的description也是作为prompt一部分传递的。如果写的不好,那么解析就不对
正确输出:description是命令字后面的参数

错误输出:description是命令的参数

(二)数据连接封装:
load加载后成纯文本--->transform文本处理(可选)--->embed向量化处理--->store存储--->retrieve检索;最后将检索的结果放入prompt交由大模型处理

1.文档加载器(Document Loaders):各种格式文件的加载器(pdf、html、word...),当使用loader加载器读取到数据源后,数据源需要转换成 Document 对象后,后续才能进行使用。
pdf加载,pip install pypdf
from langchain.document_loaders import PyPDFLoaderloader = PyPDFLoader("./application.pdf")
pages = loader.load_and_split()print(pages[0].page_content) #有些特殊的东西解析不出来,比如里面的图片2.文档处理器(Document transformers): 对文档的常用操作,如:split, filter, translate, extract metadata等等,比如文档分割或者下面的向量化可以在一定程度上解决token长度限制
文档分割,textSplitter,在一定程度上还可以过滤掉一些无用的数据(分割完,找到相关联的部分传递给大模型,而不用全部传递过去)
#pip install langchain_community
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitterloader = PyPDFLoader("./application.pdf")
pages = loader.load_and_split()text_splitter = RecursiveCharacterTextSplitter(chunk_size = 200,chunk_overlap = 50, #重叠字符串(0,200),(150,350),(300,500) ... 保证语义连续,每一部分的信息可以完整保留,不会因为截断丢失信息length_function=len,add_start_index = True,
)paragraphs = text_splitter.create_documents([pages[0].page_content]) #注意传递数组过来,直接传递字符串会被转成多个字符串数组
print(paragraphs)
for para in paragraphs[:5]:print(para.page_content)print("------------------------")3.文档向量化(Text Embedding Models):将目标物体(词、句子、文章)表示成向量的方法。
向量化便于判断两个物体的相似度,比如判断词距(快乐、高兴),词相关性(男人->国王,女人->王后)
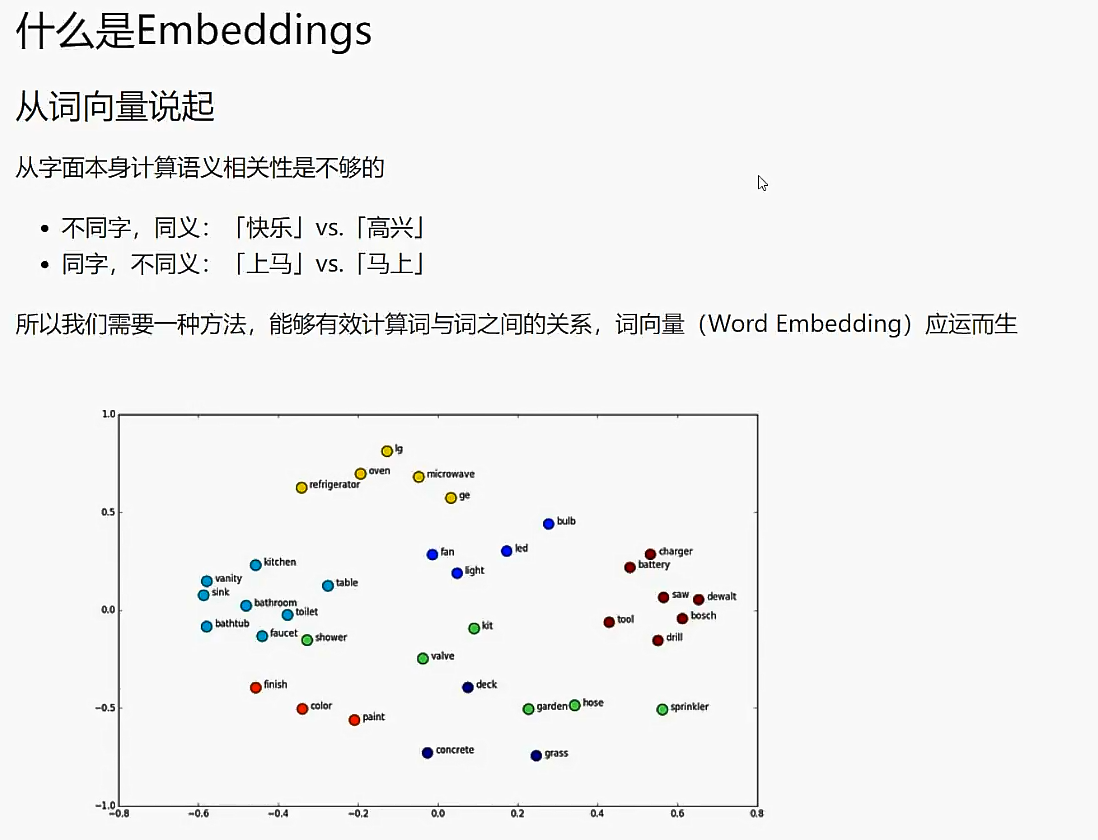
- 词向量:基于单个词的向量化操作https://www.cnblogs.com/pinard/p/7160330.html
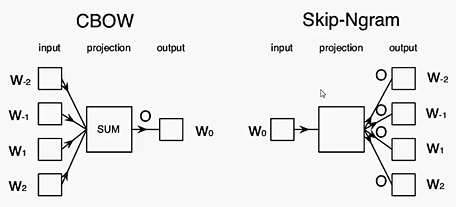
词向量的原理:用一个词的上下文窗口表示它自身;两种典型方法,CBOW模型通过上下文预测中心词,而Skip-gram模型则通过中心词预测上下文词;Word2Vec模型具有简单、高效、易于理解的特点,而且在大规模文本数据上表现出了良好的性能。它能够将语义相近的词语映射到相近的向量空间中,从而实现词语之间的语义关联。
词向量的不足:同一个词在不同上下文语意不同,我马上下来和我从马上下来;忽略了词语之间的上下文关系,无法捕捉到更复杂的语义信息。其次,Word2Vec模型无法处理词语的多义性,即一个词语可能有多个不同的含义,而Word2Vec只能将其映射到一个固定的向量表示
- 基于语句的向量化操作,根据语句去确定词的向量,同时也表示了整个语句https://www.sohu.com/a/731628300_121719205 BERT能够同时利用上下文信息和双向上下文信息,从而更好地捕捉词语之间的语义关系。https://www.cnblogs.com/wangxuegang/p/16896515.html ,BERT模型的主要输入是文本中各个字/词的原始词向量,该向量既可以随机初始化,也可以利用Word2Vector等算法进行预训练以作为初始值;输出是文本中各个字/词融合了全文语义信息后的向量
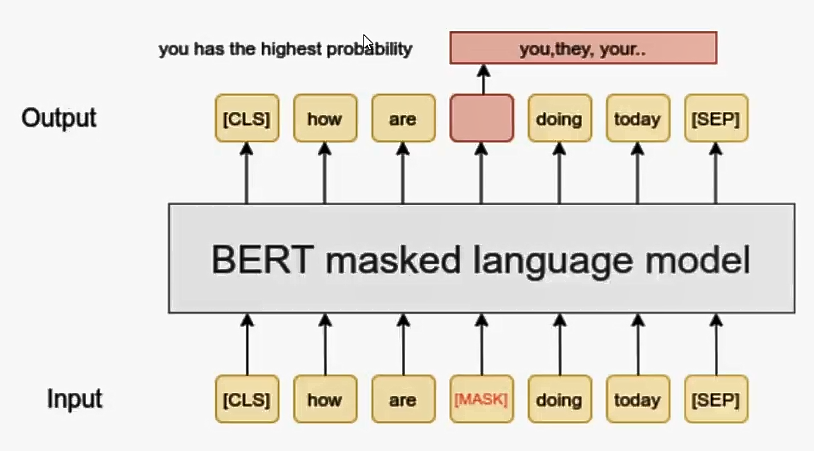
bert的输出是词向量,输出还是对应的词的词向量,但是输出的词向量融合了全文语义信息后的向量
只看这些信息bert模型和cbow似乎没有区别,实际上区别如下:https://blog.csdn.net/A496608119/article/details/129379364


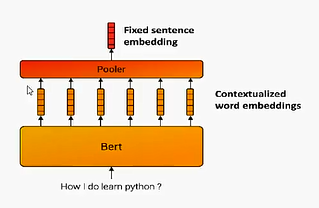
通过bert,我们可以通过cls位符号的词向量作为文本的语义表示;也可以在外层再加一层pooler池化层提取关键信息作为文本语义表示。其中文本不再只包含句子,还可以包括篇章段落长文本输入。可以对句子、段落的相关性进行判断
exp1.根据向量判断相似度
import numpy as np
from numpy import dot
from numpy.linalg import norm
from langchain_openai import OpenAIEmbeddingsdef cosine_similarity(a, b): # 余弦相似度return dot(a,b)/(norm(a)*norm(b))def l2(a,b): #欧式距离x = np.asarray(a)-np.asarray(b)return norm(x) #标准差#也有针对各个语言的模型,只是这个通用性更好;缺点是text-embedding-ada-002的区分度不是很大,需要我们去合理选取阈值
query_embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
doc_embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")query = "国际争端"
documents = ["联合国就苏丹达尔富尔地区大规模暴力事件发出警告","土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判","日本岐阜市陆上自卫队射击场内发生枪击事件3人受伤","国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营","我国首次在空间站开展舱外辐射生物学暴露实验",
]query_vec = query_embeddings.embed_query(query)
doc_vecs = doc_embeddings.embed_documents(documents)print("余弦相似度,越接近1月相似:")
for vec in doc_vecs:print(cosine_similarity(query_vec, vec))print("欧式距离,越小越相似:")
for vec in doc_vecs:print(l2(query_vec, vec))
exp2.基于相似度进行聚类
K-means(距离)和DBSCAN聚类(密度)对比https://blog.csdn.net/weixin_47151388/article/details/137950257
DBSCAN的邻域半径取值:https://blog.csdn.net/Cyrus_May/article/details/113504879
#pip install scikit-learn
from langchain_openai import OpenAIEmbeddings
from sklearn.cluster import KMeans,DBSCANtexts = ["这个多少钱","啥价","给我报个价""我要红色的","不要了","算了","来红的吧","作罢","价格介绍一下","红的这个给我吧"
]model = OpenAIEmbeddings(model="text-embedding-ada-002")
X = [] # 存放文本向量
for text in texts:X.append(model.embed_query(text))#对文本向量进行聚类
KMcluster = KMeans(n_clusters=3,random_state=41,n_init="auto").fit(X) #kmeans聚类
DBcluster = DBSCAN(eps=0.55,min_samples=2).fit(X) #dbscan聚类,这里没有去计算获取eps值,直接给了for i,t in enumerate(texts):print("KMeans: {}\t{}".format(KMcluster.labels_[i],t))for i,t in enumerate(texts):print("DBSCAN: {}\t{}".format(DBcluster.labels_[i],t))
4.向量的存储(与索引):Verctor stores(vector database)核心是索引
为什么需要存储?如果只是上面的几句话,简单循环即可,如果数据量达到上万,甚至更多,循环就不行了。这个时候就需要工具进行向量存储(索引)
向量存储做了什么工作?内部对向量之间的关系,类似于聚类的方式,建立了多级索引。比如内部10w个向量,不可能每次都对所有的数据循环计算余弦值(慢、算力不足),所以将向量按类似于结构化的方式建立多级索引,查询的时候按级查询(n->logn复杂度降低),快速检索到和query向量相关的那些向量
vectorDB核心是索引,还做了其他的工作,哪些数据存在内存、磁盘,怎么检索最快.....,这些都进行了封装
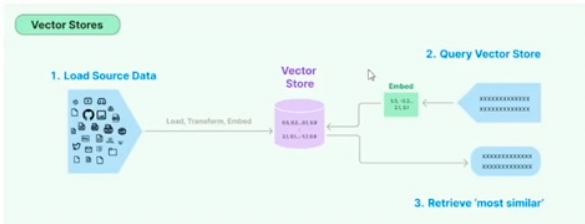
常用的向量检索:FAISS(facebook的开源框架,简单,可本地搭建pip,没有极高性能要求的话可以使用,也比较常用)、Pinecone(付费,云服务,易用,国内不行)、ES(支持向量检索、支持APU芯片加速、可优化、老牌生态好)
- FAISS安装及介绍 https://blog.csdn.net/raelum/article/details/135047797(后续查查基于开源faiss,改造自己的向量数据库的思路?)
- 向量存储使用

from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain.vectorstores import FAISSloader = PyPDFLoader("./test.pdf") #内容来自https://mp.weixin.qq.com/s/lKFenYUYoM_zTGvp6RQ4hw
pages = loader.load_and_split()text_splitter = RecursiveCharacterTextSplitter(chunk_size = 200,chunk_overlap = 50, #重叠字符串(0,200),(150,350),(300,500) ... 保证语义连续,每一部分的信息可以完整保留,不会因为截断丢失信息length_function=len,add_start_index = True,
)paragraphs = text_splitter.create_documents([page.page_content for page in pages]) #注意传递数组过来,直接传递字符串会被转成多个字符串数组embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
db = FAISS.from_documents(paragraphs, embeddings)query = "地址会变化么?"
docs = db.similarity_search(query)print(docs[0].page_content)
可以看到检索到了最相似的段落。(单纯检索)
5.向量Retrievers: 向量的检索
前面的similarity_search是查询,向量检索是对search进行封装。和上面的区别不大,只是提取概念,和传统检索进行对比。
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain.vectorstores import FAISSloader = PyPDFLoader("./test.pdf") #内容来自https://mp.weixin.qq.com/s/lKFenYUYoM_zTGvp6RQ4hw
pages = loader.load_and_split()text_splitter = RecursiveCharacterTextSplitter(chunk_size = 200,chunk_overlap = 50, #重叠字符串(0,200),(150,350),(300,500) ... 保证语义连续,每一部分的信息可以完整保留,不会因为截断丢失信息length_function=len,add_start_index = True,
)paragraphs = text_splitter.create_documents([page.page_content for page in pages]) #注意传递数组过来,直接传递字符串会被转成多个字符串数组embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
db = FAISS.from_documents(paragraphs, embeddings)retriever = db.as_retriever() #获取检索器query = "地址会变化么?"
docs = retriever.get_relevant_documents(query)print(docs[0].page_content)传统检索:关键字加权检索(不用向量检索)
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.retrievers import TFIDFRetrieverloader = PyPDFLoader("./test.pdf") #内容来自https://mp.weixin.qq.com/s/lKFenYUYoM_zTGvp6RQ4hw
pages = loader.load_and_split()text_splitter = RecursiveCharacterTextSplitter(chunk_size = 200,chunk_overlap = 50, #重叠字符串(0,200),(150,350),(300,500) ... 保证语义连续,每一部分的信息可以完整保留,不会因为截断丢失信息length_function=len,add_start_index = True,
)paragraphs = text_splitter.create_documents([page.page_content for page in pages]) #注意传递数组过来,直接传递字符串会被转成多个字符串数组
retriever = TFIDFRetriever.from_documents(paragraphs)query = "地址会变化么?"
docs = retriever.get_relevant_documents(query)print(docs[0].page_content)
可以看到不要向量检索的时候可能会错误,无法检索到对的。向量检索包含文本语义效果优于关键字检索
(三)记忆封装:Memory(多轮对话/任务之间需要上文信息)
1.对话上下文:
- ConversationBufferMemory 保留所有对话上下文
from langchain.memory import ConversationBufferMemoryhistory = ConversationBufferMemory()
history.save_context({"input": "你好啊"}, {"output": "你也好"})
print(history.load_memory_variables({})) #获取上下文 == print({history.memory_key: history.buffer})history.save_context({"input":"你瞅啥"},{"output":"我瞅你咋地"})
print({history.memory_key: history.buffer})![]()
- ConversationBufferWindowMemory 可以设置只保留指定轮数的对话上下文
from langchain.memory import ConversationBufferWindowMemoryhistory = ConversationBufferWindowMemory(k=2)
history.save_context({"input": "你好啊"}, {"output": "你也好"})
print(history.load_memory_variables({})) #获取上下文 == print({history.memory_key: history.buffer})history.save_context({"input":"你瞅啥"},{"output":"我瞅你咋地"})
print({history.memory_key: history.buffer})history.save_context({"input":"信不信我劈你瓜"},{"output":"信你个头儿,你劈个试试"})
print({history.memory_key: history.buffer})
2.自动对历史信息进行摘要,作为上下文
https://blog.csdn.net/dfBeautifulLive/article/details/133350653
from langchain.memory import ConversationSummaryMemory,ConversationSummaryBufferMemory
from langchain_openai import OpenAIhistory = ConversationSummaryMemory(llm=OpenAI(temperature=0), #default gpt-3.5-turbo-instruct temperature减少随机性,0减少随机但是不代表不随机# buffer="以英文表示",buffer="这个对话是基于一个卖瓜商人和暴躁顾客之间的交流",
)history.save_context({"input": "你好啊"}, {"output": "你也好"})
print(history.load_memory_variables({})) #获取上下文 == print({history.memory_key: history.buffer})history.save_context({"input":"你瞅啥"},{"output":"我瞅你咋地"})
print({history.memory_key: history.buffer})history.save_context({"input":"信不信我劈你瓜"},{"output":"信你个头儿,你劈个试试"})
print({history.memory_key: history.buffer})
- 其中ConversationSummaryBufferMemory对比ConversationSummaryMemory,ConversationSummaryBufferMemory的功能就是对token进行限制,当对话的达到max_token_limit长度到多长之后,我们就应该调用 LLM 去把文本内容小结一下
- buffer可以看作chatModel中的system,设置一些背景/任务信息。会在任务中放在前面,提升重要性
(四)架构封装---chain链架构
- chain用于整合各个组件,封装成一个既定的流程(链条)
- chain原理就是设计模式里面的builder模式,用于解藕各种复杂的组件(重写某个组件不影响整体流程)https://www.cnblogs.com/ssyfj/p/9538292.html
1.一个简单的chain:描述使用prompt模板,去调用大语言模型的流程,串成一个chain
from langchain_openai import OpenAI
from langchain.prompts import PromptTemplate
#导入chain,串联上面两个模块
from langchain.chains import LLMChain llm = OpenAI(model_name="gpt-3.5-turbo-instruct")
prompt = PromptTemplate(input_variables=["product"],template = "为生产{product}的公司取一个响亮的中文名字:"
)chain = LLMChain(llm=llm, prompt=prompt)
print(chain.invoke("眼镜"))
但是现在开始废弃了模块导入,变成了下面方式串联流程成为chain(内部实际就是重写or方法,变成按流程执行串联):
from langchain_openai import OpenAI
from langchain.prompts import PromptTemplatellm = OpenAI(model_name="gpt-3.5-turbo-instruct")
prompt = PromptTemplate(input_variables=["product"],template = "为生产{product}的公司取一个响亮的中文名字:"
)chain = prompt | llm
print(chain.invoke("眼镜"))
2.在chain中加入memory,描述先调用history进行处理,再使用prompt模板,去调用大语言模型的流程,串成一个chain
https://python.langchain.com/v0.2/docs/how_to/message_history/
- 简单例子使用history
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate,MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistoryprompt = ChatPromptTemplate.from_messages([("system","你是聊天机器人小瓜,你可以和人类聊天"),MessagesPlaceholder(variable_name="memory"),("human","{human_input}")
])chatHistory = ChatMessageHistory()llm = ChatOpenAI(model="gpt-3.5-turbo")
chain = prompt | llmrunnable_with_history = RunnableWithMessageHistory(chain,lambda session_id: chatHistory,input_messages_key="human_input",history_messages_key="memory",
)def ChatBot(human_input):res = runnable_with_history.invoke({"human_input":human_input},config={"configurable":{"session_id":"1"}})chatHistory.add_user_message(human_input)chatHistory.add_ai_message(res)print("----------------------")print(chatHistory.messages)print("----------------------")ChatBot("我是卢嘉锡,你是谁?")
ChatBot("我是谁?")
主要是使用了RunnableWithMessageHistory方法传递了history,在每次对话中,将对话历史写入history_messages_key占位中
- 使用数据库存储history
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate,MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import SQLChatMessageHistorydef get_session_history(session_id):return SQLChatMessageHistory(session_id, connection="sqlite:///memory.db") #生成message_store这张表,seesion_id相当于一个普通key,一个seesion_id相当于一个单独对话prompt = ChatPromptTemplate.from_messages([("system","你是聊天机器人小瓜,你可以和人类聊天"),MessagesPlaceholder(variable_name="memory"),("human","{human_input}")
])llm = ChatOpenAI(model="gpt-3.5-turbo")
chain = prompt | llm
runnable_with_history = RunnableWithMessageHistory(chain,get_session_history,input_messages_key="human_input",history_messages_key="memory",
)res = runnable_with_history.invoke({"human_input":"我是卢嘉锡,你是谁?"
},config={"configurable":{"session_id":"1"}
})print(res)res = runnable_with_history.invoke({"human_input":"我是谁?"
},config={"configurable":{"session_id":"1"}
})print(res)res = runnable_with_history.invoke({"human_input":"我是谁?"
},config={"configurable":{"session_id":"1a"}
})print(res)
- 如何实现自己的方式存储history(看源码注释)
from typing import List
from langchain_core.messages import BaseMessage
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate,MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.pydantic_v1 import BaseModel,Field
from langchain_core.chat_history import BaseChatMessageHistoryclass InMemoryHistory(BaseChatMessageHistory, BaseModel):messages: List[BaseMessage] = Field(default_factory=list)def add_messages(self, messages: List[BaseMessage]) -> None:self.messages.extend(messages)print("-------------------")print(self.messages)print("-------------------")def clear(self) -> None:self.messages = []# Here we use a global variable to store the chat message history.
# This will make it easier to inspect it to see the underlying results.
store = {}def get_by_session_id(session_id: str) -> BaseChatMessageHistory:if session_id not in store:store[session_id] = InMemoryHistory()return store[session_id]prompt = ChatPromptTemplate.from_messages([("system","你是聊天机器人小瓜,你可以和人类聊天"),MessagesPlaceholder(variable_name="memory"),("human","{human_input}")
])llm = ChatOpenAI(model="gpt-3.5-turbo")
chain = prompt | llm
runnable_with_history = RunnableWithMessageHistory(chain,get_by_session_id,input_messages_key="human_input",history_messages_key="memory",
)#对话同上
可以看到,我们可以定义自己的存储方式,只要是实现了特定的方法,返回了BaseChatMessageHistory对象即可。
- 如何使用上文提到的memory,比如ConversationSummaryMemory、ConversationBufferWindowMemory我们可以看到都是包含了BaseChatMessageHistory对象的,但是没有对应的方法和属性,需要我们去适配


重点是学习思想,参考官方文档,实现自己的summary https://python.langchain.com/v0.2/docs/how_to/chatbots_memory/#summary-memory
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate,MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables import RunnablePassthroughprompt = ChatPromptTemplate.from_messages([("system","你是聊天机器人小瓜,你可以和人类聊天"),MessagesPlaceholder(variable_name="memory"),("human","{human_input}")
])llm = ChatOpenAI(model="gpt-3.5-turbo")
chain = prompt | llmchatHistory = ChatMessageHistory()runnable_with_history = RunnableWithMessageHistory(chain,lambda session_id: chatHistory,input_messages_key="human_input",history_messages_key="memory",
)def summarize(chain_input): #进行小结,清空历史,写入小结。也可以使用封装好的ConversationSummaryMemory直接进行总结messages = chatHistory.messagesif len(messages) == 0:return FalsesummoryPrompt = ChatPromptTemplate.from_messages([("placeholder", "{chat_history}"),("user","Distill the above chat messages into a single summary message. Include as many specific details as you can.",),])summaryChain = summoryPrompt | llmsummary_message = summaryChain.invoke({"chat_history":messages})chatHistory.clear()chatHistory.add_message(summary_message) return Truerunnable_with_summary_history = RunnablePassthrough.assign(messages_summarized=summarize) | runnable_with_historydef ChatBot(human_input):res = runnable_with_summary_history.invoke({"human_input":human_input},config={"configurable":{"session_id":"1"}})chatHistory.add_user_message(human_input)chatHistory.add_ai_message(res)print("----------------------")print(chatHistory.messages)print("----------------------")ChatBot("我是卢嘉锡,你是谁?")
ChatBot("我是谁?")
其中RunnablePassthrough用于透传,将用户输入chain_input往后传递到下一个组件中去,并且可以把自己作为组件在其中执行一些操作https://blog.csdn.net/Attitude93/article/details/136531425
3.一个复杂一点的chain(Retrieval QA Chain):存储、检索、调用大模型生成结果。langchain已经封装了
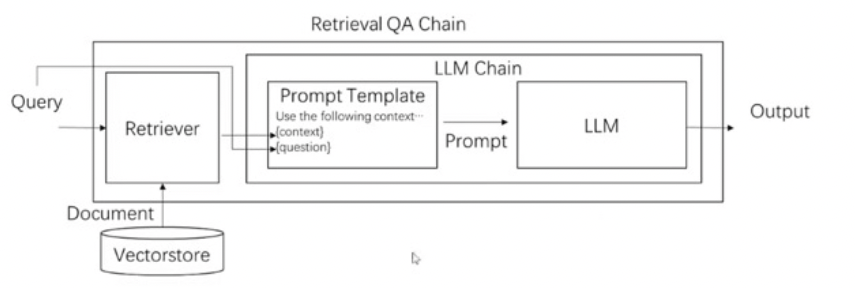
# pip install langchainhub
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings,ChatOpenAI
from langchain.vectorstores import FAISS
from langchain.chains import retrieval
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain import hub #https://blog.csdn.net/qq_41185868/article/details/137847925loader = PyPDFLoader("./test.pdf") #内容来自https://mp.weixin.qq.com/s/lKFenYUYoM_zTGvp6RQ4hw
pages = loader.load_and_split()text_splitter = RecursiveCharacterTextSplitter(chunk_size = 200,chunk_overlap = 50, #重叠字符串(0,200),(150,350),(300,500) ... 保证语义连续,每一部分的信息可以完整保留,不会因为截断丢失信息length_function=len,add_start_index = True,
)paragraphs = text_splitter.create_documents([page.page_content for page in pages]) #注意传递数组过来,直接传递字符串会被转成多个字符串数组embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
db = FAISS.from_documents(paragraphs, embeddings)llm = ChatOpenAI(model="gpt-3.5-turbo")
retrieval_qa_chat_prompt = hub.pull("langchain-ai/retrieval-qa-chat") #qa原语:Answer any use questions based solely on the context below:\n\n<context>\n{context}\n</context>。仅根据以下上下文回答任何使用问题
print(retrieval_qa_chat_prompt)combine_docs_chain = create_stuff_documents_chain(llm, retrieval_qa_chat_prompt
)qaChain = retrieval.create_retrieval_chain(db.as_retriever(),combine_docs_chain)query = "如何解决for range的时候它的地址发生变化"
res=qaChain.invoke({"input":query}) #注意和直接调用大语言模型不同,这里传递字典
print(res)
可以看到,通过embedding后,检索出来的是相关的paragraph,作为上下文,而不是全文上传,可以节省token
4.chain中的组件按顺序,和前面使用一样,代码中每个 "|" 前后的元素都可看作是一个Runnable,通过|将各个组件按顺序串行
from langchain.prompts import PromptTemplate
from langchain_openai import OpenAIllm = OpenAI(temperature=0)
namePrompt = PromptTemplate(input_variables=["product"],template="为生成{product}的公司取一个好听的中文名字:",
)nameChain = namePrompt | llmsloganPrompt = PromptTemplate(input_variables=["company_name"],template="请给名字是{company_name}的公司取一个Slogan,输出格式是 name: slogan",
)sloganChain = sloganPrompt | llmoverallChain = nameChain | sloganChain
print(overallChain.invoke("梳子"))
5.chain中使用预处理、后处理,用于对数据进行处理。这里用transform处理,实际上没必要,和前面用RunnablePassthrough一样即可实现https://python.langchain.com/v0.2/docs/tutorials/chatbot/
import re
from langchain.prompts import PromptTemplate
from langchain_openai import OpenAI
from langchain.chains.transform import TransformChaindef anonymize(inputs: dict) -> dict:text = inputs["text"]t = re.compile(r'1(3\d|4[4-9]|5([0-35-9]|6[67]|7[013-8]|8[0-9]|9[0-9]x)\d{8}])')while True:s = re.search(t, text)if s:text = text.replace(s.group(), "***********")else:breakreturn {"output_text":text}transform_chain = TransformChain( #用于预处理input_variables=["text"],output_variables=["output_text"],transform=anonymize
)prompt = PromptTemplate(template="根据下述橘子,提取候选人的职业和手机号:\n{output_text}\n输出json,以job、phone为key",input_variables=["output_text"]
)llm = OpenAI(temperature=0)
overChain = transform_chain | prompt | llm
print(overChain.invoke({"text":"我叫张三,今年20岁,在北京做程序员。手机号是1334252564623"}))
主要是补充一下如何查找文档:
- 在这里查询函数https://api.python.langchain.com/en/latest/runnables/langchain_core.runnables.passthrough.RunnablePassthrough.html

- 拉到最下面就有案例,点击即可

6.chain如何进行路由(根据上一个组件结果调用对应的下一个组件)
https://python.langchain.com/v0.2/docs/how_to/routing/
from langchain.prompts import PromptTemplate
from langchain_openai import OpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableLambda,RunnableBranchchain = (PromptTemplate.from_template("""根据用户的提问,判断他是关于"windows"、"linux"还是"other" 相关的脚本需求只允许回答上面的分类,只输出分类<question>
{question}
</question>CLassfication""")| OpenAI(temperature=0)| StrOutputParser()
)linux_chain = PromptTemplate.from_template("""
你只会写Linux shell脚本。你不会写其他任何语言的程序,也不会写其他系统的脚本。用户问题:
{question}
"""
) | OpenAI(temperature=0)windows_chain = PromptTemplate.from_template("""
你只会写windows脚本。你不会写其他任何语言的程序,也不会写其他系统的脚本。用户问题:
{question}
"""
) | OpenAI(temperature=0)other_chain = PromptTemplate.from_template("""
根据用户的提问选取合适的脚本语言用户问题:
{question}
"""
) | OpenAI(temperature=0)# 方式1,使用自定义函数实现路由(可以自己在中间做一些事情,灵活性好)
def route(info):print(info)if "windows" in info["topic"].lower():return windows_chainelif "linux" in info["topic"].lower():return linux_chainelse:return other_chain# 将用户的输入传入第一个字典中,里面每一个都相当于回调,都会将输入传递进去
fullChain = {"topic":chain,"question":lambda X:X["question"]} | RunnableLambda(route
)res = fullChain.invoke({"question":"帮我在linux上写一个十分钟后关机的脚本"})
print(res)#方式2:使用RunnableBranch,分支处理(不够灵活)
branchChain = RunnableBranch((lambda X: "linux" in X["topic"].lower(),linux_chain),(lambda X: "windows" in X["topic"].lower(),windows_chain),other_chain
)fullChain = {"topic":chain,"question":lambda X:X["question"]} | branchChain
res = fullChain.invoke({"question":"帮我在linux上写一个十分钟后关机的脚本"})
print(res)
7.封装了API调用:通过封装的文档,结合chain实现调用api获取结果的能力
from langchain.chains.api import open_meteo_docs #文档
from langchain_openai import OpenAI
from langchain.chains.api.base import APIChainchain = APIChain.from_llm_and_api_docs(OpenAI(),open_meteo_docs.OPEN_METEO_DOCS,verbose=True,limit_to_domains=["https://api.open-meteo.com"])
res = chain.invoke("北京今天气温")
print(res)
8.function calling的封装:langchain实现了标准的接口,不再像之前那么复杂
https://python.langchain.com/v0.2/docs/how_to/function_calling/
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage,ToolMessage
from langchain_openai import ChatOpenAI#方式一:装饰器实现对函数的function calling封装,简单
@tool
def add(a: int, b: int) -> int:"""Adds a and b."""return a + b@tool
def multiply(a: int, b: int) -> int:"""Multiplies a and b."""return a * btools = [add, multiply]
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
llmTools = llm.bind_tools(tools)query = "What is 3 * 12? Also, what is 11 + 49?"
messages = [HumanMessage(query)]
tools_msg = llmTools.invoke(messages) #返回要调用的方法
messages.append(tools_msg) #AIMessage
for tool_call in tools_msg.tool_calls:selected_tool = {"add":add,"multiply":multiply}[tool_call["name"].lower()]tool_output = selected_tool.invoke(tool_call["args"]) #本地调用messages.append(ToolMessage(tool_output,tool_call_id=tool_call["id"]))print(messages)
llmTools.invoke(messages)

当然,我们也可以按这种方式定义function calling,通过注释和description表示输出信息
9.基于Document的chains,在前面的3中已经介绍了一种stuff方式,下面补充一下其他方式

- stuff模式:将检索出来的文档全部拼在一起传递(不加工、纯填充),上下文信息更全,并且只调用一次语言模型
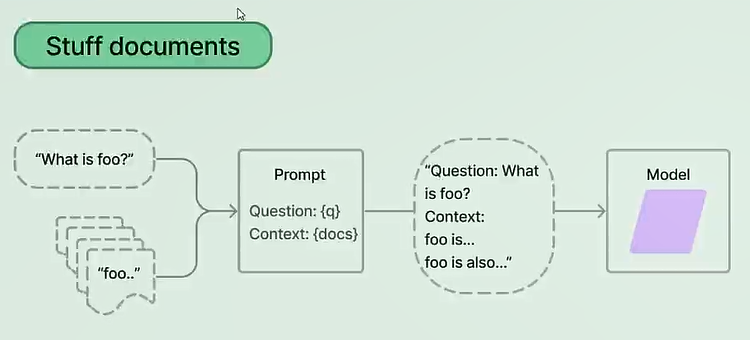
- refine模式,检索出来n个文档,每个文档调用一次语言模型,每次模型返回结果再和下一个文档拼接,然后再得到结果,以此类推得到最后结果。效果不咋地,会弱化前面的答案
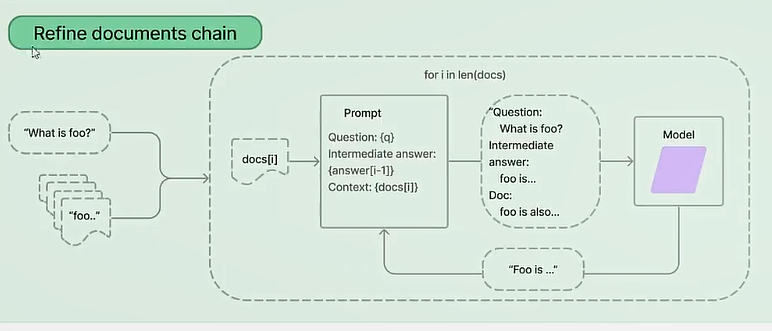
- Map reduce模式:并发得到n个答案,然后拼接答案,最后调用大模型进行回答

- Map re-rank,并发,然后rank获取得分最高的答案回复(信息不足,评分也不足弥补)

(五)架构封装---agent智能体架构
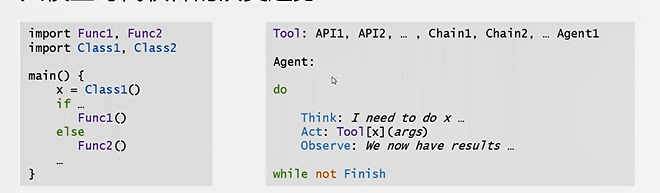
1.什么是智能体(agent)
将大语言模型作为一个推理引擎。给定一个任务之后,智能体自动规划生成完成任务所需的步骤,执行相应动作(例如选择并调用工具),直到任务完成。
和chain的区别在于:chain是封装一个固定的流程,chain可以作为智能体里面的一个tool来使用;agent是对tool、任务的调度流程,可以根据需求判断得到分几步、使用什么工具去完成任务
2.先定义一些工具(tools):函数、三方api、chain或者agent的run()作为tool
#三方api
search = SerpAPIWrapper() #搜索引擎
tools = [ #一组工具,供选择Tool.from_function(func=search.run,name="Search",description="useful for when you need to answer questions about current events" #问一下实时的事情)
]#函数自定义
@tool("weekday")
def weekday(date_str:str) -> str:"""Convert date to weekday name"""d = parser.parser(date_str)return calendar.day_name[d.weekday()]#内部的封装好的
tools = load_tools(["serpapi"]) 3.agent智能体类型:ReAct 想-》执行-》看结果
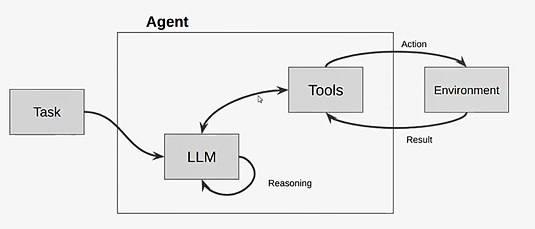
- 提供task任务
- llm自己推理, 先想看如何执行,调用工具执行,结果返回llm,基于这个结果再循环,直到任务完成
# pip install google-search-results
import calendar
import dateutil.parser as parser
from langchain_core.tools import tool
from langchain.agents import load_tools,AgentType,initialize_agent
from langchain_openai import OpenAI#函数自定义
@tool("weekday")
def weekday(date_str:str) -> str:"""Convert date to weekday name"""d = parser.parser(date_str)return calendar.day_name[d.weekday()]#三方api
tools = load_tools(["serpapi"]) #https://serpapi.com/dashboardtools += [weekday]
print(tools)llm = OpenAI()
agent = initialize_agent(tools,llm,agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,verbose=True)
agent.invoke("周星驰生日那天是星期几")4.Function Calling实现的agent,agent会帮你调用,不需要你自己去调用
agent=AgentType.OPENAI_FUNCTIONS5.SelfAskWithSearch智能体。自己拆解信息(每一步先问自己需要什么信息然后获取结果),一步步去搜索结果。适合知识图谱关联搜索
agent=AgentType.SELF_ASK_WITH_SEARCH
6.Plan-and-Excute智能体(类似于autoGpt)
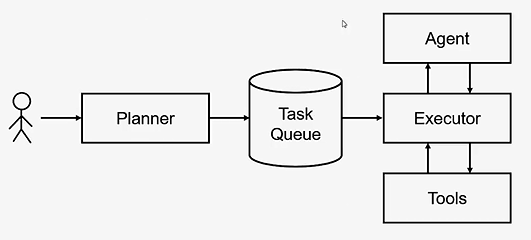
planner:根据输入规划任务,放入任务队列
excuter:每次从任务队列取一个任务执行,会调用agent和tool进行执行交互
(六)Callback回调:用于监测记录调用过程信息

继承基类,实现方法即可,包括各个时机的监控,llm开始,返回单个token、返回全部结果时候...