YOLO目标检测之模型剪枝
最近,博主有一个需求,需要将模型部署到一个边缘设备,此时,便遇到了一个问题,YOLO模型太大,无法部署,此时,我们除了采用量化的操作以外,就需要使用剪枝操作了。
相关介绍
剪枝(Pruning)是一种模型压缩技术,旨在通过移除神经网络中不重要的权重或神经元来减少模型的大小和计算复杂度,同时尽量保持模型的性能。
其步骤如下:
1. 训练基础模型
在开始剪枝之前,首先需要训练一个基础模型,这个模型将作为后续剪枝操作的基础。
设计并初始化你的深度学习模型。
使用标准的训练过程训练模型至收敛或达到满意的性能指标。
2. 确定剪枝策略
选择合适的剪枝策略对于成功实施剪枝至关重要。常见的剪枝策略包括但不限于:
非结构化剪枝(Unstructured Pruning):基于权重值的大小进行剪枝,通常去除那些绝对值较小的权重。
结构化剪枝(Structured Pruning):剪除整个通道、滤波器或者层,这有助于保持计算效率,特别是在硬件实现上。
全局剪枝 vs 局部剪枝:全局剪枝考虑整个模型中的所有权重,并根据设定的阈值一次性修剪;局部剪枝则是针对每个层单独设定剪枝比例。
3. 权重重要性评估
确定哪些权重或神经元可以被安全地移除。常用的评估方法包括:
权重幅度:直接依据权重的绝对值大小决定是否剪枝。
第二导数/梯度信息:考虑参数对损失函数影响的重要性。
神经元输出方差:衡量特定神经元在整个训练集上的激活程度。
4. 实施剪枝
根据选定的标准和策略执行剪枝操作。
非结构化剪枝:可以直接设置某些权重为零。
结构化剪枝:可能涉及到修改网络架构,如删除卷积核或全连接层的部分神经元。
5. 微调(Fine-tuning)
剪枝后,模型可能会出现性能下降的情况,因此需要对剪枝后的模型进行微调以恢复其准确性。
步骤:
使用原始数据集对剪枝后的模型进行再训练。
可能需要调整学习率等超参数以适应新的模型结构。
6. 验证与迭代
检查剪枝后的模型在验证集上的表现,确保它仍然满足应用需求。如果性能未能达到预期,则可能需要调整剪枝策略或增加微调的时间,并重复上述步骤。
那么接下来进入实操:
约束训练
约束训练是为了筛选哪些channel比较重要,哪些channel没有那么重要,约束训练可以使得模型更易于剪枝。在约束训练中,模型会学习到一些通道或者权重系数比较不重要的信息,而这些信息在剪枝过程中得到应用,从而达到模型压缩的效果。而如果直接进行剪枝操作,可能会出现一些问题,比如剪枝后的模型精度大幅下降、剪枝不均匀等。因此,在进行剪枝操作之前,通过稀疏训练的方式,可以更好地准确地确定哪些通道或者权重系数可以被剪掉,从而避免上述问题的发生。
首先,在ultralytics/yolo/engine/trainer.py添加如下代码
# Backward
self.scaler.scale(self.loss).backward()
# ========== 新增代码 ==========
l1_lambda = 1e-2 * (1 - 0.9 * epoch / self.epochs)
for k, m in self.model.named_modules():if isinstance(m, nn.BatchNorm2d):m.weight.grad.data.add_(l1_lambda * torch.sign(m.weight.data))#动态调整正则化强度,这种设计的目的是让正则化在训练初期较强,而在训练后期逐渐减弱,从而避免过度正则化影响模型的最终性能m.bias.grad.data.add_(1e-2 * torch.sign(m.bias.data)) #对偏置施加 L1 正则化
# ========== 新增代码 ==========# Optimize - https://pytorch.org/docs/master/notes/amp_examples.html
if ni - last_opt_step >= self.accumulate:self.optimizer_step()last_opt_step = ni
L1 正则化增强了 BatchNorm2d 层的稀疏性,并通过动态调整正则化强度实现了更好的训练效果,用于模型压缩,防止过拟合。
然后重新训练模型,注意,要加上 amp=False 参数,表示禁用自动混合精度,所有计算使用 FP32。同理,amp=True 表示启用自动混合精度,部分计算使用 FP16,从而加速训练并减少显存占用。当然,这其实是方便我们后续的模型剪枝操作。
from ultralytics import YOLO
model=YOLO("yolov8-obb.yaml").load("yolov8n.pt")
results = model.train(data="tower-seg.yaml", epochs=300,amp=False, imgsz=640)

原效果:

采用约束训练后效果:

剪枝
在剪枝时,我们选择加载last.pt而非best.pt,因为由于迁移学习,模型的泛化性比较好,在第一个epoch时mAP值最大,但这并不是真实的,我们需要稳定下来的一个模型进行prune
from ultralytics import YOLO
import torch
from ultralytics.nn.modules import Bottleneck, Conv, C2f, SPPF, Detect# 加载预训练模型
yolo = YOLO("D:/project_mine/detection/ultralytics/runs/obb/train3/weights/last.pt")
model = yolo.model# 1. 计算 BatchNorm 中 gamma 的阈值
ws = []for _, m in model.named_modules():if isinstance(m, torch.nn.BatchNorm2d):w = m.weight.abs().detach() # 使用 gamma 的绝对值作为重要性指标ws.append(w)factor = 0.7 # 保留 80% 的通道
ws = torch.cat(ws)
threshold = torch.sort(ws, descending=True)[0][int(len(ws) * factor)]
print(f"Threshold for pruning: {threshold}")# 2. 定义结构化剪枝函数
def _prune(c1, c2):"""c1: 当前卷积模块(包含 Conv 和 BatchNorm)c2: 下一个卷积模块(可能是 Conv、C2f 或其他类型)"""bn = c1.bnconv = c1.conv# 获取当前 BatchNorm 的 gamma 值gamma = bn.weight.data.detach()mask = torch.where(gamma.abs() >= threshold)[0] # 筛选出需要保留的通道索引# 更新 BatchNorm 参数bn.weight.data = bn.weight.data[mask]bn.bias.data = bn.bias.data[mask]bn.running_mean.data = bn.running_mean.data[mask]bn.running_var.data = bn.running_var.data[mask]bn.num_features = len(mask)# 更新当前卷积层的参数conv.weight.data = conv.weight.data[mask] # 保留对应的滤波器conv.out_channels = len(mask)if conv.bias is not None:conv.bias.data = conv.bias.data[mask]# 更新下一个卷积层的输入通道数if not isinstance(c2, list):c2 = [c2] # 将 c2 包装成列表for item in c2:if item is not None:if isinstance(item, Conv):next_conv = item.convelse:next_conv = itemnext_conv.in_channels = len(mask)next_conv.weight.data = next_conv.weight.data[:, mask] # 保留对应的输入通道# 3. 遍历模型进行剪枝
def prune(m1, m2):if isinstance(m1, C2f):m1 = m1.cv2# 确保 m2 是一个列表if not isinstance(m2, list):m2 = [m2]for i, item in enumerate(m2):if isinstance(item, C2f) or isinstance(item, SPPF):m2[i] = item.cv1_prune(m1, m2)# 对 Bottleneck 模块进行剪枝
for _, m in model.named_modules():if isinstance(m, Bottleneck):prune(m.cv1, m.cv2)# 4. 设置模型参数为可训练状态
for _, p in yolo.model.named_parameters():p.requires_grad = True# 5. 导出剪枝后的模型
yolo.export(format="onnx") # 导出为 ONNX 文件
torch.save(yolo.ckpt, "pruned_model.pt") # 保存剪枝后的模型
print("Pruning completed and model saved!")
使用https://netron.app/查看一下模型结构:发现里面出现了这种不规则的单数结构,这就说明我们的剪枝成功了。
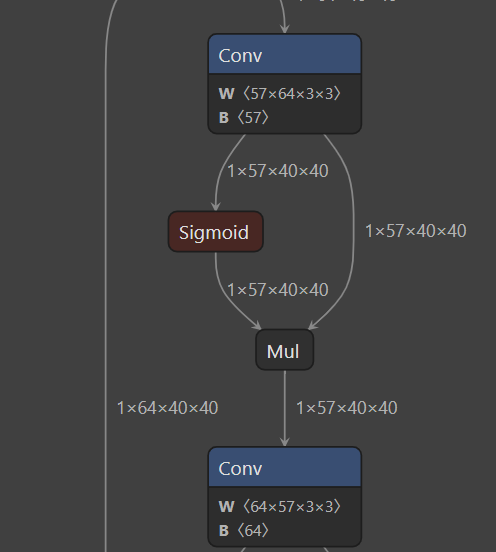
回调训练
首先,把之前在trainer.py中加的代码注释掉,然后依旧在yolo/engine/trainer.py代码中的def setup_model方法中添加如下内容
self.model = self.get_model(cfg=cfg, weights=weights, verbose=RANK == -1) # calls Model(cfg, weights)
# ========== 新增该行代码 ==========
self.model = weights
# ========== 新增该行代码 ==========
return ckpt
修改完成后,开启回调训练:
from ultralytics import YOLO
model=YOLO("yolov8-obb.yaml").load("prune.pt")
results = model.train(data="tower-seg.yaml", epochs=300,imgsz=640)
原始结果:

剪枝后结果:

可以看到,这种剪枝后的精度下降还是较为明显的,不够对于我的任务足够了
至此,我们的模型剪枝操作便完成了。