1、分区表的定义
在OceanBase数据库中,普通的表数据可以根据预设的规则被分割并存储到不同的数据区块中,同一区块的数据是在一个物理存储上。这样被分区块的表被称为分区表,而其中的每一个独立的数据区块则被称为一个分区。
如下图所示,一张表被划分成了 5 个分区,分布在 2 台机器上:

2、分区表的优势与特点
2.1分区表的优势
- 分区表的不同分区可以分散在不同节点上,从而分散压力
- 提高数据的管理
- 增强数据的使用效率
- 不存在磁盘的限制
2.2 分区表的特点
◼ 可多机扩展
◼ 提高可管理性
◼ 提高性能
◼ 自动负载均衡、自动容灾
◼ 对业务透明,可以取代“分库分表”方案
◼ 支持分区间并行
◼ 单表分区个数最大8192
◼ 单机partition支持上限: 8万(推荐不超过3万)
3、业务如何选择适合自己的分区类型

OceanBase 数据库目前支持的分区类型如下:
- Range 分区
- Range Columns 分区
- List 分区
- List Columns 分区
- Hash 分区
- Key 分区
- 组合分区
- 如果是日志类型的大表,根据时间类型的列做 RANGE 分区是最合适的
- 如果是并发访问非常高的表,结合业务特点选择能满足绝大部分核心业务查询的列作为拆分键是最合适的重点说明:
● HASH/LIST/RANGE 分区分区表达式的结果必须是 int 类型,不⽀持向量
● HASH 分区通常能消除热点查询
● KEY/LIST COLUMNS/RANGE COLUMNS 分区不要求是int类型,可以是任意类型,不⽀持表达 式,⽀持向量
● KEY ⽤户通常没有办法⾃⼰通过简单的计算来得知某⼀⾏属于哪个分区
● KEY 分区不写分区键表示使⽤主键列
● RANGE 分区是按⽤户指定的表达式范围将每⼀条记录划分到不同分区,⽀持 ADD DROP 分区
● ⽣成列分区是指将⽣成列作为分区键进⾏分区,该功能能够更好的满⾜期望将某些字段进⾏⼀定处 理后作为分区键的需求(⽐如提取⼀个字段的⼀部分,作为分区键)
3.1 Range 分区
# 定义:
Range 分区是最常见的分区类型,通常与日期一起使用。在进行 Range 分区时,数据库根据分区键的值范围将行映射到分区。# 特点:
- Range 分区的分区键只支持一列,并且只支持 INT 类型
- 如果要支持多列的分区键,或者其他数据类型,可以使用 Range Columns 分区。
- RANGE分区可以新增、删除分区。如果最后一个 RANGE 分区指定了 MAXVALUE ,则不能新增分区。#当使用 RANGE 分区时,需要遵守如下几个规则:
- PARTITION BY RANGE ( expr ) 里的 expr 表达式的结果必须为整形。
- 每个分区都有一个 VALUES LESS THAN 子句,它为分区指定一个非包含的上限值。分区键的任何值等于或大于这个值时将被映射到下一个分区中。
- 除第一个分区外,所有分区都隐含一个下限值,即上一个分区的上限值。
- 允许且只允许最后一个分区上限定义为 MAXVALUE ,这个值没有具体的数值,比其他所有分区的上限都要大,也包含空值。
- RANGE分区可以新增、删除分区。如果最后一个 RANGE 分区指定了 MAXVALUE ,则不能新增分区。
- RANGE 分区要求表拆分键表达式的结果必须为整型,如果要按时间类型列做 RANGE 分区,则必须使用 timestamp 类型,并且使用函数 UNIX_TIMESTAMP 将时间类型转换为数值。这个需求也可以使用 RANGE COLUMNS 分区实现,就没有整型这个要求。
3.2 RANGE COLUMNS 分区
# Range Columns 分区作用跟 Range 分区基本类似,不同点如下:
- Range Columns 拆分列结果不要求是整型,可以是任意类型。
- Range Columns 拆分列不能使用表达式。
- Range Columns 拆分列可以写多个列(即列向量)。
3.3 Hash 分区
#定义
- 行的目标分区是由内部 Hash 函数计算出一个 Hash 值,再根据 Hash 分区个数来确定的。当分区数量为 2 的幂次方时,哈希算法会创建所有分区中大致均匀的行分布。
- 哈希算法在分区之间均匀分布行,使分区的大小大致相同。# 使用场景&特点
- 分区的数据不是历史数据或没有明显的分区键
- 数据不能指定数据的分区键的列表特征。
- 不同范围内的数据大小相差非常大,并且很难手动调整均衡。
- 使用 RANGE 分区后数据聚集严重
- - Hash 分区键的表达式必须返回 INT 类型。# 特点
- Hash 分区键的表达式必须返回 INT 类型
- HASH 分区不支持做删除操作#优势:
- 解决OLTP系统中的更新冲突 --(Hash 分区将一个表分成几个分区,将一个表的修改分解到不同的分区修改,而不是修改整个表。)
3.4 Key分区
# Key 分区和 Hash 分区类似。主要区别如下:
- Hash 分区的分区键可以是用户自定义的表达式,而 Key 分区的分区键只能是列,或者不指定。
- key 分区的分区键不限于 INT 类型。#特点:
- key 分区可以指定或不指定列,也可以指定多个列作为分区键
- 如果表上有主键,那么这些列必须是表的主键的一部分,或者全部。
- 如果 Key 分区不指定分区键,那么分区键就是主键列。如果没有主键,有UNIQUE键,那么分区键就是UNIQUE键。
- 支持除 TEXT 和 BLOB 之外的所有数据类型的分区
- Key分区不允许使用用于自定义的表达式,需要使用 MySQL服务器提供的 Hash 函数。
3.5 List 分区
#定义
数据库某个字段是离散值,为了显式的控制记录行如何映射到分区,此时可以采用LIST分区。优点是可以方便的对无序或无关的数据集进行分区。#特点
- list分区键可以由一个或多个列组成
- 分区键可以是一列,也可以是一个表达式
- 分区键的数据类型仅支持 INT 类型。
- LIST分区可以新增分区,指定新的不重复的列表。也可以删除分区。#当使用列表分区时,需要遵守以下规则:
- 分区表达式结果必须是整型。
- 分区表达式只能引用一列,不能有多列(即列向量)。
3.6 List Columns 分区
List Columns 分区是 List 分区的一个扩展,支持多个分区键,并且支持 INT 数据、DATE 类型和 DATETIME 类型。# LIST COLUMNS 分区作用跟 LIST 分区基本相同,不同之处在于:
- LIST COLUMNS 的拆分列不能是表达式。
- LIST COLUMNS 的拆分列可以是多列(即列向量)
3.7 生成列分区
◼ 一级分区
◼ 生成列是指这一列是由其他列计算而得
◼ 生成列分区是指将生成列作为分区键进行分区,该功能能够更好的满足期望将某些字段进行一定处理后作为分区键
的需求(比如提取一个字段的一部分,作为分区键)# 示例
CREATE TABLE gc_part_t(t_key varchar(10) PRIMARY KEY, gc_user_id VARCHAR(4) GENERATED ALWAYS AS (SUBSTRING(t_key, 1, 4)) VIRTUAL, c3 INT)
PARTITION BY KEY(gc_user_id) PARTITIONS 10;
3.8 组合分区
Range、List、Hash都可以作为组合分区表的二级分区策略
#定义
在进行组合分区时,表通过一种数据分配方法进行分区,然后使用第二种数据分配方法将每个分区进一步细分为二级分区。因此,组合分区结合了基本的数据分发方法。指定分区的所有二级分区代表数据的逻辑子集。# 组合分区有如下优点:
- 根据 SQL 语句,在一维或二维上进行分区修剪可能会提高性能。
- 查询可以在任一维度上使用全分区或部分分区连接。
- 可以对单个表执行并行备份和恢复。
- 分区的数量大于单层分区,这可能有利于并行执行。
- 可以实现一个滚动窗口来支持历史数据,如果许多语句可以从分区修剪或分区连接中受益,则仍然可以在另一个维度上进行分区。
- 可以根据分区键的标识以不同方式存储数据。例如,您可能决定以只读的压缩格式存储特定产品类型的数据,并保持其他产品类型的数据不压缩。
4、如何创建&修改分区表
4.1 一级分区
4.1.1 创建分区
####(1)Range 分区
#示例
CREATE TABLE dba_test_range (id bigint NOT NULL AUTO_INCREMENT COMMENT '主键',name varchar(50),start_time timestamp NOT NULL,
PRIMARY KEY (id,start_time)
) PARTITION BY RANGE(UNIX_TIMESTAMP(start_time))(PARTITION M202207 VALUES LESS THAN(UNIX_TIMESTAMP('2022-08-01')),PARTITION M202208 VALUES LESS THAN(UNIX_TIMESTAMP('2022-09-01')),PARTITION MMAX VALUES LESS THAN MAXVALUE);
(2)RANGE COLUMNS 分区
#示例:
CREATE TABLE dba_test_range_cloumns (id bigint NOT NULL AUTO_INCREMENT COMMENT '主键',name varchar(50),start_time datetime NOT NULL,
PRIMARY KEY (id,start_time)
) PARTITION BY RANGE COLUMNS(start_time)(PARTITION M202207 VALUES LESS THAN('2022-08-01'),PARTITION M202208 VALUES LESS THAN('2022-09-01'),PARTITION MMAX VALUES LESS THAN MAXVALUE
);
(3)Hash 分区
#示例:
CREATE TABLE dba_test_hash (id bigint NOT NULL AUTO_INCREMENT COMMENT '主键',name varchar(50),hid int NOT NULL,
PRIMARY KEY (id,hid)
) PARTITION BY HASH (hid) partitions 128;
(4)Key 分区
# 示例:
CREATE TABLE dba_test_hash (id bigint NOT NULL AUTO_INCREMENT COMMENT '主键',name varchar(50),hid int NOT NULL,
PRIMARY KEY (id,name)
) PARTITION BY KEY(name) partitions 128;
(5)List 分区
#示例:
CREATE TABLE dba_test_list (id bigint NOT NULL AUTO_INCREMENT COMMENT '主键',name varchar(50),hid int NOT NULL,
PRIMARY KEY (id,hid)
) PARTITION BY list(hid) (PARTITION p0 VALUES IN (1, 2, 3),PARTITION p1 VALUES IN (5, 6),PARTITION p2 VALUES IN (DEFAULT)
);
(6)List Columns 分区
#示例:
CREATE TABLE dba_test_list_columns (id bigint NOT NULL AUTO_INCREMENT COMMENT '主键',name varchar(50),hid int NOT NULL,
PRIMARY KEY (id,name)
) PARTITION BY list COLUMNS(name) (PARTITION p0 VALUES IN ('00', '01'),PARTITION p1 VALUES IN ('02', '03'),PARTITION p2 VALUES IN (DEFAULT)
);
4.1.2 增加删除分区
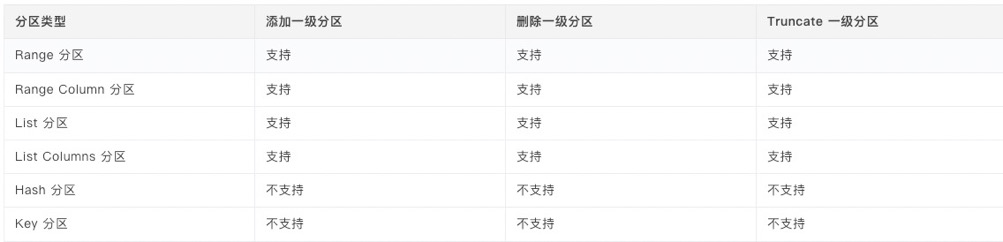
分区表创建成功后,您可以对一级分区表进行添加、删除或 Truncate 分区操作。
#注意事项
(1)对于 Range/Range Columns 分区,只能在最大的分区之后添加一个分区,不可以在中间或者开始的地方添加。如果当前的分区中有 MAXVALUE 的分区,则不能继续添加分区。
(2)List/List Columns 分区添加一级分区时,要求添加的分区不与之前的分区冲突即可。
如果一个 List/List Columns 分区有默认分区即 Default Partition,则不能添加任何分区。
(3)在 Range/Range Columns/List/List Columns 分区中添加一级分区不会影响全局索引和局部索引的使用。#查看已创建的分区
show create table tablename\G# 查看数据落入的分区
SELECT * FROM tablename partition(M202208);
(1)添加一级分区
#添加一级分区
(1)向Range中添加一级分区M1202501
ALTER TABLE tablename ADD PARTITION (PARTITION M1202501 VALUES LESS THAN(UNIX_TIMESTAMP('2025/02/01')));
(2)向List中添加一级分区 p2 和 p3
ALTER TABLE tablename ADD PARTITION (PARTITION p2 VALUES IN (7,8),PARTITION p3 VALUES IN (DEFAULT));
(2)删除一级分区
# 删除一级分区
(1)删除一级分区表 table1 中的 M202207 和 M202208。
ALTER TABLE table1 DROP PARTITION M202207,M202208;# Truncate 一级分区
--Truncate 一级分区时,可以将一个或多个分区中的数据清空。
--在 Truncate 一级分区时,请尽量避免该分区上存在活动的事务或查询,否则可能会导致 SQL 语句报错,或者出现一些异常情况。
(1)清除一级分区表 table1 中 M202209 和 M202208 分区的数据。
ALTER TABLE table1 TRUNCATE PARTITION M202208,M202209;
4.2 二级分区
OceanBase 数据库目前 MySQL 模式支持 HASH、RANGE、 LIST、KEY、RANGE COLUMNS 和 LIST COLUMNS 六种分区方式,二级分区为任意两种分区方式的组合。
#定义:
在进行二级分区时,表首先通过一种数据分配方法进行分区,然后使用第二种数据分配方法将每个分区进一步划分为二级分区。
-- 例如,一个表中包含 create_time列和 user_id列,您可以在 create_time列上使用 Range 分区,然后在 user_id 列上使用 Hash 进行二级分区 。#类型
- 模板化二级分区表
- 非模板化二级分区表#模板化二级分区表说明:
- 每个一级分区下的二级分区定义均相同
- 二级分区的命名规则为 ($part_name)s($subpart_name)
4.2.1 创建二级分区
####(1)创建模板化二级分区表
#示例1:Hash + Range Column
#先按o_w_id在hash分区,分区数为16,再按o_entry_d按月做二级分区
CREATE TABLE t_ordr_part_by_hash_range (o_w_id int,o_d_id int,o_id int,o_c_id int,o_carrier_id int,o_ol_cnt int,o_all_local int,o_entry_d TIMESTAMP NOT NULL,index idx_ordr(o_w_id, o_d_id, o_c_id, o_id) LOCAL,primary key (o_w_id, o_d_id, o_id, o_entry_d)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY hash(o_w_id)
SUBPARTITION BY RANGE(UNIX_TIMESTAMP(o_entry_d)) SUBPARTITION template
(SUBPARTITION M197001 VALUES LESS THAN(UNIX_TIMESTAMP('1970/02/01')),SUBPARTITION M197002 VALUES LESS THAN(UNIX_TIMESTAMP('1970/03/01')),SUBPARTITION MMAX VALUES LESS THAN MAXVALUE
) partitions 16;#示例2:Range Columns + Key
#先按时间start_time按月做一级分区,再对test_name做key二级分区(分区数量为4)
CREATE TABLE `job_ob_test_log` (`id` bigint(19) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',`test_name` varchar(100) NOT NULL default '' comment '名称',`task_id` varchar(255) NOT NULL default '',`is_success` int(11) NOT NULL COMMENT '是否成功',`stop_time` timestamp NULL DEFAULT NULL,`start_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,`sche_id` varchar(40) DEFAULT NULL COMMENT 'sche_id'PRIMARY KEY (`id`,test_name,start_time)KEY `uniq_sche_id` (`sche_id`, `start_time`) LOCAL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY RANGE columns(start_time)
SUBPARTITION BY key(test_name) SUBPARTITIONS 4
(
PARTITION M202207 VALUES LESS THAN ('2022/07/01'),
PARTITION M202207 VALUES LESS THAN ('2022/08/01'),
PARTITION M202208 VALUES LESS THAN ('2022/09/01'),
PARTITION M202209 VALUES LESS THAN ('2022/10/01'),
PARTITION M202209 VALUES LESS THAN ('2022/11/01'),
PARTITION M202209 VALUES LESS THAN ('2022/12/01')
);#示例3:Range Columns + Range Columns
CREATE TABLE t_m_rcrc(col1 INT,col2 INT) PARTITION BY RANGE COLUMNS(col1)SUBPARTITION BY RANGE COLUMNS(col2)SUBPARTITION TEMPLATE (SUBPARTITION mp0 VALUES LESS THAN(1000),SUBPARTITION mp1 VALUES LESS THAN(2000),SUBPARTITION mp2 VALUES LESS THAN(3000))(PARTITION p0 VALUES LESS THAN(100),PARTITION p1 VALUES LESS THAN(200),PARTITION p2 VALUES LESS THAN(300));
(2)创建非模板化二级分区表
#示例1:
#(1)创建非模板化 Range + Range 分区表
CREATE TABLE t2_f_rr(col1 INT,col2 TIMESTAMP) PARTITION BY RANGE(col1)SUBPARTITION BY RANGE(UNIX_TIMESTAMP(col2))(PARTITION p0 VALUES LESS THAN(100)(SUBPARTITION sp0 VALUES LESS THAN(UNIX_TIMESTAMP('1971/04/01')),SUBPARTITION sp1 VALUES LESS THAN(UNIX_TIMESTAMP('1971/07/01')),SUBPARTITION sp2 VALUES LESS THAN(UNIX_TIMESTAMP('1971/10/01')),SUBPARTITION sp3 VALUES LESS THAN(UNIX_TIMESTAMP('1972/01/01'))),PARTITION p1 VALUES LESS THAN(200)(SUBPARTITION sp4 VALUES LESS THAN(UNIX_TIMESTAMP('1971/04/01')),SUBPARTITION sp5 VALUES LESS THAN(UNIX_TIMESTAMP('1971/07/01')),SUBPARTITION sp6 VALUES LESS THAN(UNIX_TIMESTAMP('1971/10/01')),SUBPARTITION sp7 VALUES LESS THAN(UNIX_TIMESTAMP('1972/01/01'))));#示例2:
#(2)创建非模板化 Hash + Range 分区表
CREATE TABLE t2_f_hr (col1 INT,col2 INT) PARTITION BY KEY(col1) SUBPARTITION BY RANGE(col2)(PARTITION p1(SUBPARTITION sp0 VALUES LESS THAN (1970),SUBPARTITION sp1 VALUES LESS THAN (1971),SUBPARTITION sp2 VALUES LESS THAN (1972),SUBPARTITION sp3 VALUES LESS THAN (1973)),PARTITION p2(SUBPARTITION sp4 VALUES LESS THAN (1970),SUBPARTITION sp5 VALUES LESS THAN (1971),SUBPARTITION sp6 VALUES LESS THAN (1972),SUBPARTITION sp7 VALUES LESS THAN (1973)));
4.2.2 新增删除二级分区
(1)二级分区表添加分区
#二级分区表添加一级分区
(1)向 Range Columns + Range Columns 模板化分区表 t_m_rcrc 中添加一级分区 p3 和 p4
ALTER TABLE t_m_rcrc ADD PARTITION(PARTITION p3 VALUES LESS THAN(400),PARTITION p4 VALUES LESS THAN(500));
(2)向 Range + Range 非模板化分区表 t2_f_rclc 中添加一级分区 p2
ALTER TABLE t2_f_rclc ADD PARTITION(PARTITION p2 VALUES LESS THAN(300)(SUBPARTITION sp6 VALUES IN(1,3),SUBPARTITION sp7 VALUES IN(4,6),SUBPARTITION sp8 VALUES IN(7,9)));# 添加二级分区:当前 MySQL 模式暂不支持向表中添加二级分区。
(2)二级分区表删除分区
**说明:**
- drop/truncate 二级分区表中的一/二级分区时,请尽量避免该分区上存在活动的事务或查询,否则可能会导致 SQL 语句报错,或者出现一些异常情况。
- drop一级分区会同时删除该一级分区的定义和其对应的二级分区及数据。
- drop二级分区会同时删除该分区的定义和其中的数据。
- 当drop多个二级分区时,这些二级分区必须属于同一个一级分区。
- 支持对 Range/List [Columns] 类型(组合)的二级分区表中的一、二级分区执行 Truncate 操作,将一个或多个一级分区中对应的二级分区中的数据全部移除或者一个或多个二级分区中的数据全部移除。
# 删除一级分区
(1)删除 t_m_rcrc 中的一级分区 p3 和 p4
ALTER TABLE t_m_rcrc DROP PARTITION p3,p4;
(2)删除Range+Range非模板化分区表 t2_f_rr中的一级分区 p2,即:该分区下的二级分区也会删除
ALTER TABLE t2_f_rr DROP PARTITION P2;# 删除二级分区
(1)删除 Range + Range 非模板化分区表 t2_f_rr 中的二级分区 sp6 和 sp7
ALTER TABLE t2_f_rr DROP SUBPARTITION sp6,sp7;# Truncate 一级分区
ALTER TABLE t2_f_rclc TRUNCATE PARTITION p0;#Truncate 二级分区
ALTER TABLE t2_f_rr TRUNCATE SUBPARTITION sp1,sp2;
5、分区路由
分区表的查询 SQL 跟普通表是一样的,OceanBase 的 OBProxy 或 OBServer 会自动将用户 SQL 路由到相应节点内,因此,分区表的分区细节对业务是透明的。
默认情况下,除非表定义了分区名,分区名都是按一定规则编号,例如:
一级分区名为:p0 , p1 , p2 , ...
二级分区名为:p0sp0 , p0sp1 , p0sp2 , ... ; p1sp0 , p1sp1 , p1sp2 , ...# 查询一级分区p0
select * from t_log partition(p0);#查询二级分区 p0sp1
select * from t_log partition(p0sp1);
6、使用分区表注意事项
1. 分区表适用于:表的数据量非常大,大表SQL查询性能慢的表
2. 要选择合适的拆分键以及拆分策略
3. 分区表中的全局唯一性需求可以通过主键约束和唯一约束实现。OceanBase 数据库的分区表的主键约束和局部
OceanBase 云数据库现已支持免费试用,现在申请,体验分布式数据库带来全新体验吧 ~